💡 学习目标
- 向量数据库概述及核心原理
- Chroma向量数据库核心操作
- Milvus向量数据库扩展学习
1. 向量数据库
1.1. 什么是向量数据库?
向量数据库,是专门为向量检索设计的中间件!
高效存储、快速检索和管理高纬度向量数据的系统称为向量数据库
一种专门用于存储和检索高维向量数据的数据库。它将数据(如文本、图像、音频等)通过嵌入模型转换为向量形式,并通过高效的索引和搜索算法实现快速检索。
向量数据库的核心作用是实现相似性搜索,即通过计算向量之间的距离(如欧几里得距离、余弦相似度等)来找到与目标向量最相似的其他向量。它特别适合处理非结构化数据,支持语义搜索、内容推荐等场景。
核心功能:
- 向量存储
- 相似性度量
- 相似性搜索
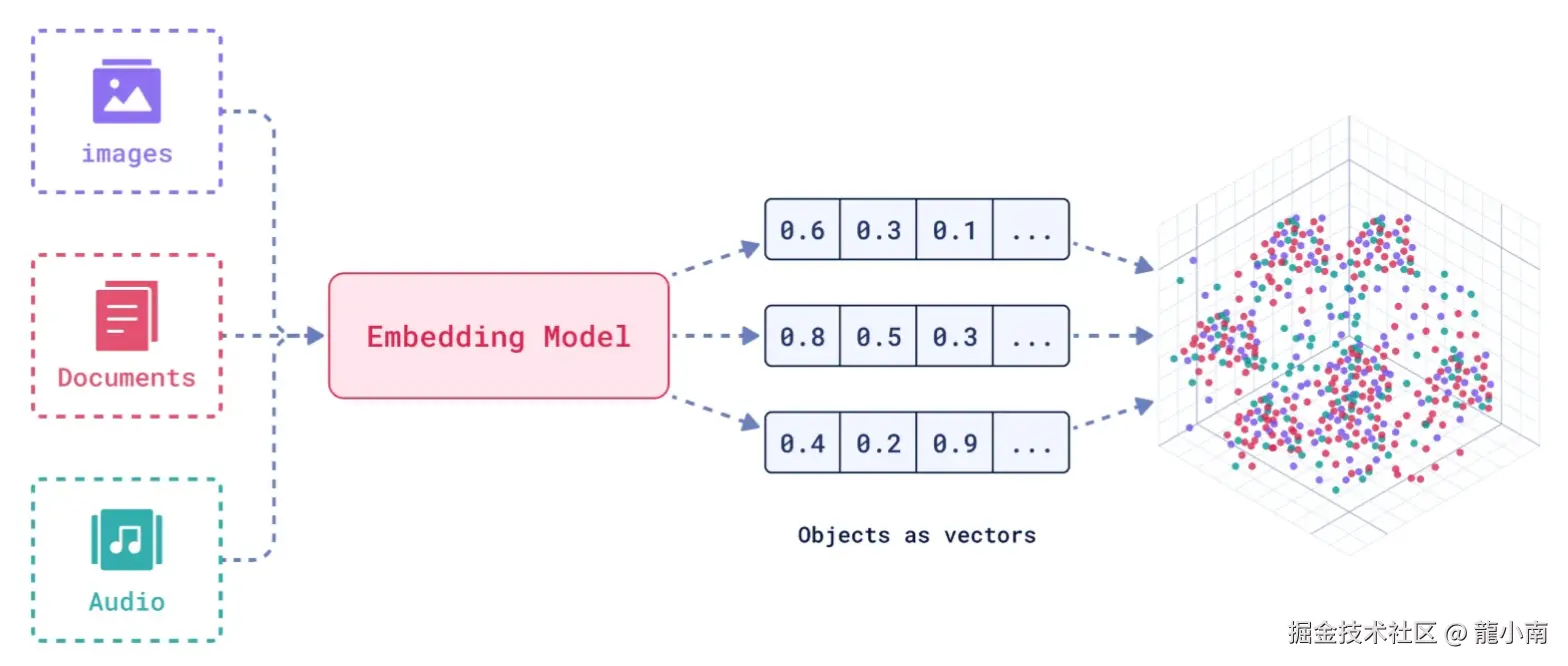
1.2. 如何存储和检索嵌入向量?
- 存储:向量数据库将嵌入向量存储为高维空间中的点,并为每个向量分配唯一标识符(ID),同时支持存储元数据。
- 检索:通过近似最近邻(ANN)算法(如PQ等)对向量进行索引和快速搜索。比如,FAISS和Milvus等数据库通过高效的索引结构加速检索。
1.3. 向量数据库与传统数据库对比
- 数据类型
- 传统数据库:存储结构化数据(如表格、行、列)。
- 向量数据库:存储高维向量数据,适合非结构化数据。
- 查询方式
- 传统数据库:依赖精确匹配(如=、<、>)。
- 向量数据库:基于相似度或距离度量(如欧几里得距离、余弦相似度)。
- 应用场景
- 传统数据库:适合事务记录和结构化信息管理。
- 向量数据库:适合语义搜索、内容推荐等需要相似性计算的场景。
澄清几个关键概念:
- 向量数据库的意义是快速的检索;
- 向量数据库本身不生成向量,向量是由 Embedding 模型产生的;
- 向量数据库与传统的关系型数据库是互补的,不是替代关系,在实际应用中根据实际需求经常同时使用。
1.4. 主流向量数据库功能对比
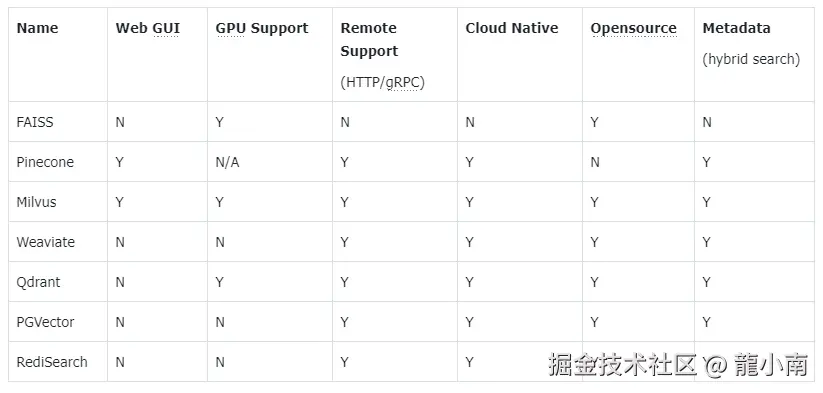
- FAISS : Meta 开源的向量检索引擎 github.com/facebookres...
- Pinecone: 商用向量数据库,只有云服务 www.pinecone.io/
- Milvus : 开源向量数据库,同时有云服务 milvus.io/
- Weaviate: 开源向量数据库,同时有云服务 weaviate.io/
- Qdrant : 开源向量数据库,同时有云服务 qdrant.tech/
- PGVector: Postgres 的开源向量检索引擎 github.com/pgvector/pg...
- RediSearch: Redis 的开源向量检索引擎 github.com/RediSearch/...
- ElasticSearch 也支持向量检索 www.elastic.co/enterprise-...
扩展阅读:guangzhengli.com/blog/zh/vec...
2. Chroma 向量数据库
官方文档:docs.trychroma.com/docs/overvi...
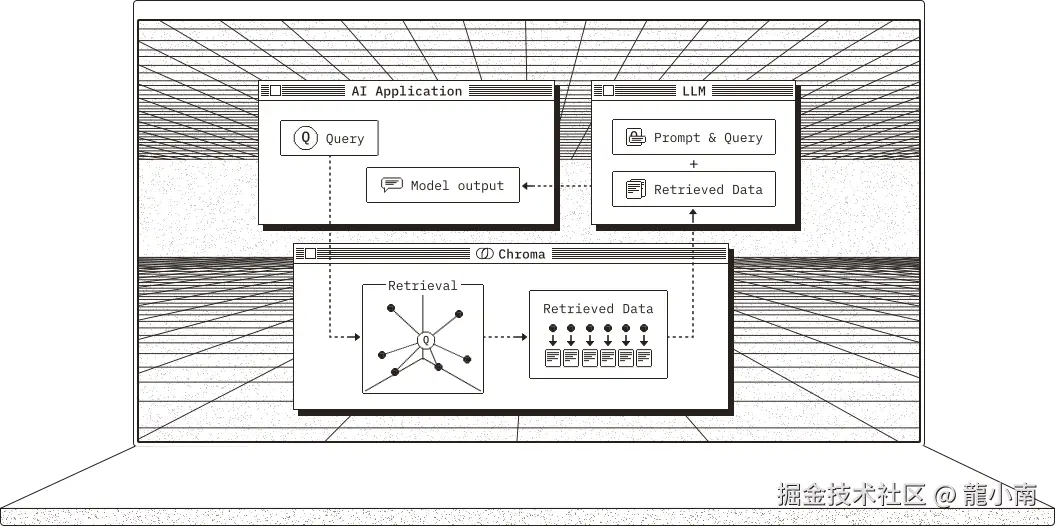
1. 什么是 Chroma?
Chroma 是一款开源的向量数据库,专为高效存储和检索高维向量数据设计。其核心能力在于语义相似性搜索,支持文本、图像等嵌入向量的快速匹配,广泛应用于大模型上下文增强(RAG)、推荐系统、多模态检索等场景。与传统数据库不同,Chroma 基于向量距离(如余弦相似度、欧氏距离)衡量数据关联性,而非关键词匹配。
2. 核心优势
- 轻量易用:以 Python/JS 包形式嵌入代码,无需独立部署,适合快速原型开发。
- 灵活集成:支持自定义嵌入模型(如 OpenAI、HuggingFace),兼容 LangChain 等框架。
- 高性能检索:采用 HNSW 算法优化索引,支持百万级向量毫秒级响应。
- 多模式存储:内存模式用于开发调试,持久化模式支持生产环境数据落地。
2.1. Chroma 安装与基础配置
1. 安装
通过 Python 包管理器安装 ChromaDB:
python
# 安装 Chroma 向量数据库完成功能
# !pip install chromadb2. 初始化客户端
- 内存模式(一般不建议使用):
python
import chromadb
client = chromadb.Client()- 持久化模式:
python
# 数据保存至本地目录
client = chromadb.PersistentClient(path="./chroma")2.2. Chroma 核心操作流程
1. 集合(Collection)
集合是 Chroma 中管理数据的基本单元,类似关系数据库的表:
(1)创建集合
python
from chromadb.utils import embedding_functions
# 默认情况下,Chroma 使用 DefaultEmbeddingFunction,它是基于 Sentence Transformers 的 MiniLM-L6-v2 模型
default_ef = embedding_functions.DefaultEmbeddingFunction()
# 使用 OpenAI 的嵌入模型,默认使用 text-embedding-ada-002 模型
# openai_ef = embedding_functions.OpenAIEmbeddingFunction(
# api_key="YOUR_API_KEY",
# model_name="text-embedding-3-small"
# )
python
# 自定义 Embedding Functions
from chromadb import Documents, EmbeddingFunction, Embeddings
class MyEmbeddingFunction(EmbeddingFunction):
def __call__(self, texts: Documents) -> Embeddings:
# embed the documents somehow
return embeddings
python
collection = client.create_collection(
name = "my_collection",
configuration = {
# HNSW 索引算法,基于图的近似最近邻搜索算法(Approximate Nearest Neighbor,ANN)
"hnsw": {
"space": "cosine", # 指定余弦相似度计算
"ef_search": 100,
"ef_construction": 100,
"max_neighbors": 16,
"num_threads": 4
},
# 指定向量模型
"embedding_function": default_ef
}
)(2)查询集合
python
collection = client.get_collection(name="my_collection")- peek() - returns a list of the first 10 items in the collection.
- count() - returns the number of items in the collection.
- modify() - rename the collection
python
print(collection.peek())
print(collection.count())
# print(collection.modify(name="new_name"))
python
{'ids': ['id1', 'id2'], 'embeddings': array([[ 1.60079654e-02, 1.02847122e-01, 1.15382075e-02,
-3.34708579e-02, 1.14530073e-02, 6.35105297e-02,
7.69377127e-02, 2.63175592e-02, 3.02551482e-02,
5.60058244e-02, 1.71475381e-01, -5.42212315e-02,
-1.58406403e-02, -6.51467144e-02, -1.57864839e-02,
2.83155753e-03, -3.26167569e-02, 2.66733784e-02,
-7.15856552e-02, 8.44806433e-03, -2.99695563e-02,
-2.17505582e-02, 5.32626212e-02, 3.43727171e-02,
-9.07171890e-02, 1.21168364e-02, -2.69576702e-02,
4.59876433e-02, 1.01122260e-01, -1.81238037e-02,
...
1.05566178e-02, -2.98974402e-02, -2.70893704e-02,
3.89399305e-02, -9.87977441e-03, 2.00460758e-02,
-5.35070635e-02, 5.25764190e-02, 5.20156361e-02,
7.13807791e-02, 7.88660273e-02, 2.02222038e-02]]), 'documents': ['RAG是一种检索增强生成技术,在智能客服系统中大量使用', '向量数据库存储文档的嵌入表示'], 'uris': None, 'included': ['metadatas', 'documents', 'embeddings'], 'data': None, 'metadatas': [{'source': 'RAG'}, {'source': '向量数据库'}]}
2(3)删除集合
python
client.delete_collection(name="my_collection")2. 添加数据
支持自动生成或手动指定嵌入向量:
python
# 方式1:自动生成向量(使用集合指定的嵌入模型)
collection.add(
# 文档的集合
documents = ["RAG是一种检索增强生成技术", "向量数据库存储文档的嵌入表示", "在机器学习领域,智能体(Agent)通常指能够感知环境、做出决策并采取行动以实现特定目标的实体"],
# 文档元数据信息
metadatas = [{"source": "RAG"}, {"source": "向量数据库"}, {"source": "Agent"}],
# id
ids = ["id1", "id2", "id3"]
)
# 方式2:手动传入预计算向量(实际开发中推荐使用)
# collection.add(
# embeddings = get_embeddings("RAG是什么?")
# documents = ["文本1", "文本2"],
# ids = ["id3", "id4"]
# )
python
C:\Users\Administrator.cache\chroma\onnx_models\all-MiniLM-L6-v2\onnx.tar.gz: 100%|█| 79.3M/79.3M [00:06<00:00, 13.8Mi3. 查询数据
- 文本查询(自动向量化):
python
results = collection.query(
query_texts = ["RAG是什么?"],
n_results = 3,
where = {"source": "RAG"}, # 按元数据过滤
# where_document = {"$contains": "检索增强生成"} # 按文档内容过滤
)
print(results)
python
{'ids': [['id1']], 'embeddings': None, 'documents': [['RAG是一种检索增强生成技术,在智能客服系统中大量使用']], 'uris': None, 'included': ['metadatas', 'documents', 'distances'], 'data': None, 'metadatas': [[{'source': 'RAG'}]], 'distances': [[0.3491383194923401]]}- 向量查询(自定义输入):
python
# results = collection.query(
# query_embeddings = [[0.5, 0.6, ...]],
# n_results = 3
# )4. 数据管理
更新集合中的数据:
python
collection.update(ids=["id1"], documents=["RAG是一种检索增强生成技术,在智能客服系统中大量使用"])删除集合中的数据:
python
collection.delete(ids=["id3"])2.3. 4.8. Chroma Client-Server Mode
- Server 端
默认端口 8000
python
chroma run --path /db_path修改端口:--port 端口号
python
chroma run --port 8001 --path /db_path- Client 端
python
import chromadb
# 远程连接 Chroma Server
chroma_client = chromadb.HttpClient(host='localhost', port=8000)
python
# 测试
collection = chroma_client.create_collection(name = "my_collection")
collection = chroma_client.get_collection(name="my_collection")
print(collection.count())03. Qdrant 向量数据库
3.1. win10安装Qdrant
下载:
解压:
添加到环境变量:
将上面解压后的目录添加到环境变量
3.2. 启动
在通过 npm 全局安装 Qdrant 后,可按照以下步骤启动服务:
3.3. 启动 Qdrant 服务
输入以下命令启动 Qdrant 服务:
qdrant
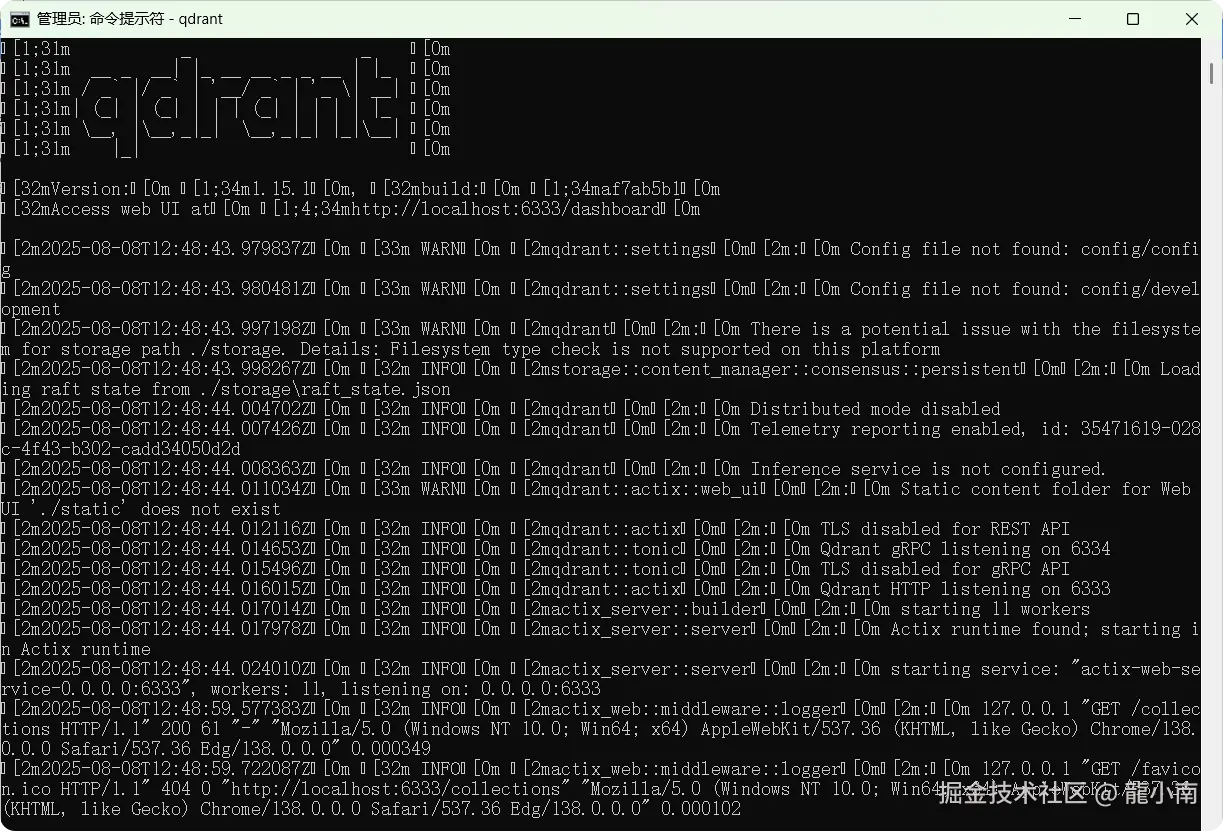
3.3.1. 验证服务运行
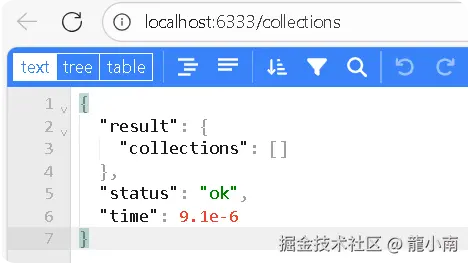
打开浏览器访问:
http://localhost:6333/collections
如果看到 JSON 格式的响应(如空的集合列表),说明服务已成功启动。
4. Milvus 向量数据库(扩展学习)
中文官网:milvus.io/zh
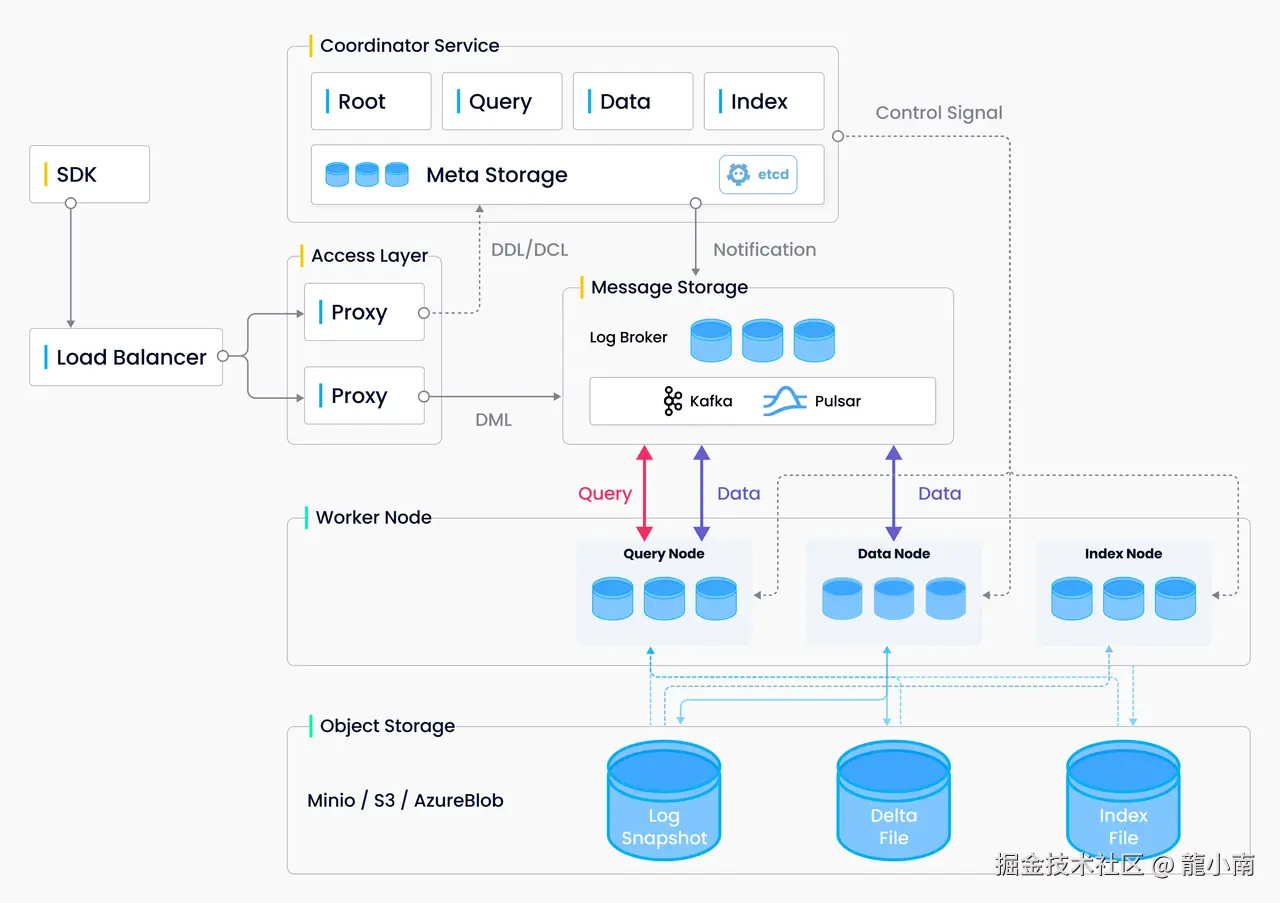
Milvus 架构图