备注 :回顾看过的论文,对目前看过的Qwen1.5进行整理在此总结。为了保证系列的完整性此篇笔者根据已有的信息进行汇总,因为该系列的细节较少,对于没有的部分不做推测(注:笔者水平有限,若有描述不当之处,欢迎大家留言。后期会继续更新LLM系列,文生图系列,VLM系列,agent系列等。如果看完有收获,可以【点赞】【收藏】【加粉】)
备注:后续为机器翻译
Qwen1.5:
摘要
Qwen1.5 是 Qwen 系列的新一代开源语言模型版本。本次发布包括多个不同规模的 Base 与 Chat 模型(从 0.5B 到 110B 参数),并且提供量化模型 (Int4, Int8, AWQ, GGUF) 以适配资源受限环境。Qwen1.5 系列统一支持长上下文 (最大 32768 tokens),并整合进入主流开源生态 (如 Hugging Face transformers、vLLM、llama.cpp 等),为开发者提供更便捷、灵活、实用的大语言模型解决方案。该版本在基础语言理解、编码、推理、多语言、多任务、对齐 (alignment)、多模态/工具调用 (agent/RAG) 等方面均进行了综合评估,展现出较强的通用能力和适用性。
一 介绍
为了构建一个真正"良好 (good)"的模型,并改善开发者使用体验,Qwen 团队 发布了 Qwen1.5 作为系列迭代版本。
Qwen1.5 开源了 Base 与 Chat 模型,覆盖八种不同参数规模(0.5B、1.8B、4B、7B、14B、72B、110B)1 ,32B**2** ,以及一个 MoE**3**版本。
同时提供了多种量化 (quantized) 模型形式:除了传统 Int4/Int8 的 GPTQ,还包含 AWQ、GGUF 格式,以便在低资源或部署受限场景使用。
为提升开发者使用便利性,Qwen1.5 的代码已合并入 Hugging Face transformers (≥ 4.37.0),使用时无需额外设置 trust_remote_code。
Qwen1.5 与多种开源推理 /部署 /微调框架兼容 (如 vLLM、SGLang、AutoGPTQ / AutoAWQ、llama.cpp、Axolotl、LLaMA‑Factory 等),并支持在 Ollama、LMStudio 等平台以及全球 API 服务 (DashScope、together.ai) 上使用。
相较于早期版本,本次更新改进了 Chat 模型对人类偏好的对齐 (alignment),增强了多语言处理能力 (multilingual capability);所有规模模型均支持更长上下文 (32 K tokens),基础模型质量也有优化,有利于后续微调 (fine‑tune) 和应用。
二 架构与标记器
官方博客中并没有非常详细地公开 Qwen1.5 的底层架构设计(例如 Transformer 层数、注意力机制细节等)作为"架构"节单独说明。但从历史资料与社区讨论中可以推断,Qwen 系列沿用了标准 decoder‑only Transformer 架构,支持 group‑query attention (GQA)、并为量化与 MoE 做了兼容 / 支持 (尤其是 MoE 版本) 。


三 预训练
博客没有专门展示 Qwen1.5 的预训练细节 (如训练语料量、训练步骤、超参数配置等),因此本节内容较少。
根据官方介绍,Qwen1.5 的基础 (Base) 模型在预训练之后被发布为 base‑L M;但对于具体预训练过程 (数据规模、混合语料、训练 compute 预算等) 未公开详述。
因此,本节简略 ------ 官方主要强调的是结果(基础能力 +兼容性 + 长上下文支持),而非预训练细节。
四 后训练
Qwen1.5 在 Chat 模型中强调对人类偏好的对齐 (alignment),使用了诸如 Direct Policy Optimization (DPO) 和 Proximal Policy Optimization (PPO) 等技术,以使 Chat 模型生成更符合人类偏好的回答。
这种对齐 (alignment) 旨在增强模型的 instruction‑following 能力 (指令跟随能力) 和对话生成质量。
对齐后的 Chat 模型 (Qwen1.5‑Chat) 被作为用户可直接使用 /部署 /微调的版本发布。
五 评估
5.1 基础能力
官方对 Qwen1.5 的 Base 和 Chat 模型在多维度、多任务上进行了全面评估,涵盖基础能力 (语言理解、推理、编码 等)、多语言、多任务、对齐 (human preference)、智能体能力 (agent / 工具调用 / RAG / 长上下文生成) 等。
5.1 基础能力
关于模型基础能力的评测,我们在 MMLU(5-shot)、C-Eval、Humaneval、GS8K、BBH 等基准数据集上对 Qwen1.5 进行了评估。

在不同模型尺寸下,Qwen1.5 都在评估基准中表现出强劲的性能。特别是,Qwen1.5-72B 在所有基准测试中都远远超越了Llama2-70B,展示了其在语言理解、推理和数学方面的卓越能力。
最近小型模型的构建也成为了热点之一,我们将模型参数小于 70 亿的 Qwen1.5 模型与社区中最杰出的小型模型进行了比较。结果如下:
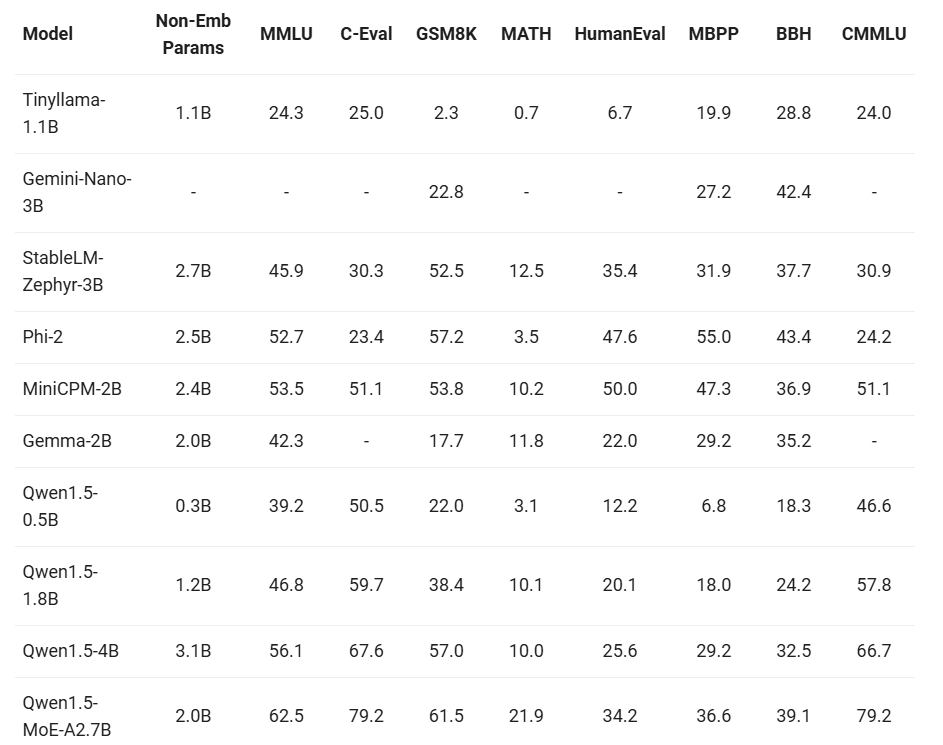
我们可以自信地说,参数规模低于 70 亿的 Qwen1.5 base 模型,与业界领先的小型模型相比具有很强的竞争力。未来,我们将继续提高小模型的整体效果,并探索如何将大模型的能力有效迁移到小模型之中。
5.2 对齐 / 人类偏好对齐
对齐的目的是增强语言的指令跟随能力,生成和人类偏好相近的回复。我们认识到将人类偏好融入学习过程的重要性,因此在对齐最新的 Qwen1.5 系列时有效地采用了直接策略优化(DPO)和近端策略优化(PPO)等技术。
但是,评估此类聊天模型的质量是一项重大挑战。虽然全面的人工评估是最佳方法,但它在可扩展性和可重复性方面面临着巨大挑战。因此我们借助更先进的大模型作为评委,在两个广泛使用的基准上对 Qwen1.5 进行了初步评估: MT-Bench 和 Alpaca-Eval。评估结果如下:
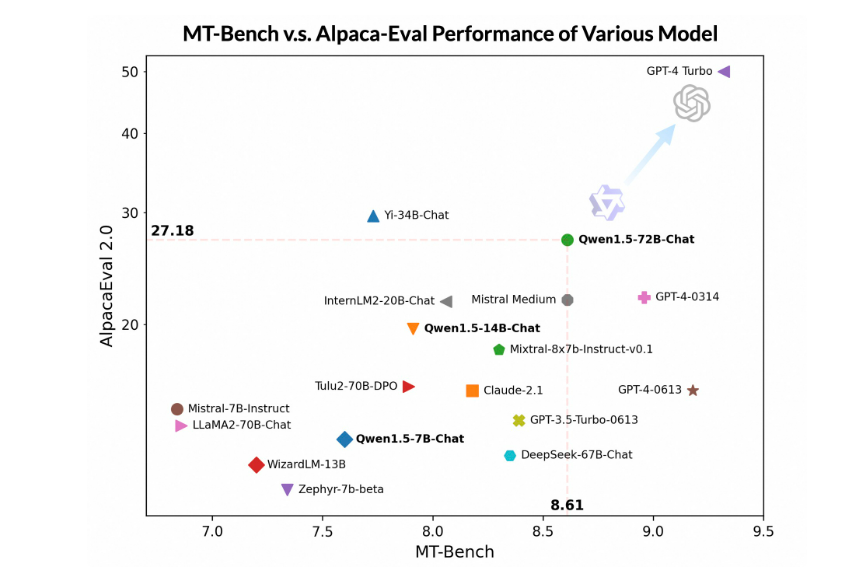
我们在评测MT-Bench榜单时发现在这个榜单上模型分数有较大的方差,因此我们进行了三轮评测并汇报平均分数和标准差。
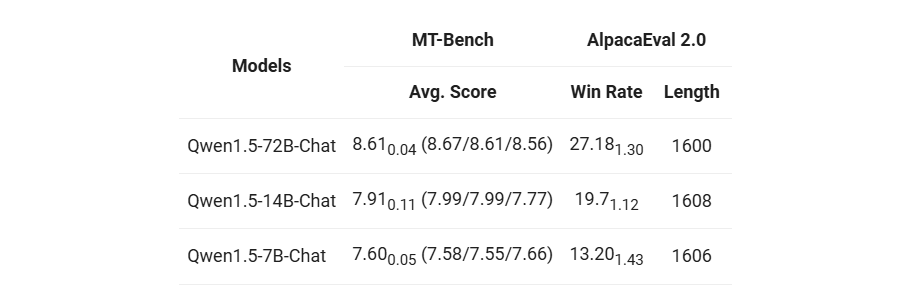
尽管落后于 GPT-4-Turbo,但最大的 Qwen1.5 模型 Qwen1.5-72B-Chat 在 MT-Bench 和 Alpaca-Eval v2 上都表现出不俗的效果,超过了 Claude-2.1、GPT-3.5-Turbo-0613、Mixtral-8x7b-instruct 和 TULU 2 DPO 70B,与 Mistral Medium 不相上下。
此外,虽然大模型裁判的评分似乎与回答的长度有关,但我们的观察结果表明 Qwen1.5 并没有产生过长的回答来操纵大模型裁判的偏差。AlpacaEval 2.0 上 Qwen1.5-Chat 的平均长度仅为 1618,与 GPT-4 的长度一致,比 GPT-4-Turbo 短。从通义千问网页端和APP的反馈看,用户更加喜爱新版本模型的回复。
5.3 多语言能力
我们挑选了来自欧洲、东亚和东南亚的12种不同语言,全面评估Base模型的多语言能力。从开源社区的公开数据集中,我们构建了如下表所示的评测集合,共涵盖四个不同的维度:考试、理解、翻译、数学。下表提供了每个测试集的详细信息,包括其评测配置、评价指标以及所涉及的具体语言种类。
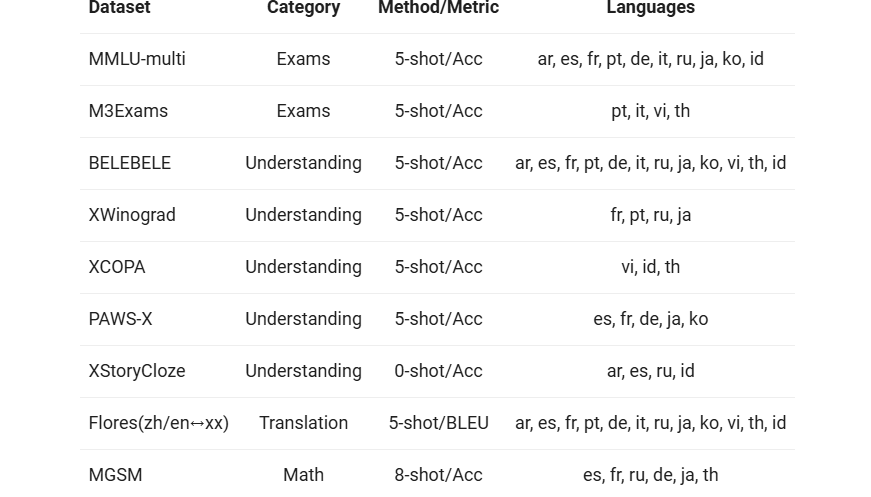
详细的结果如下:
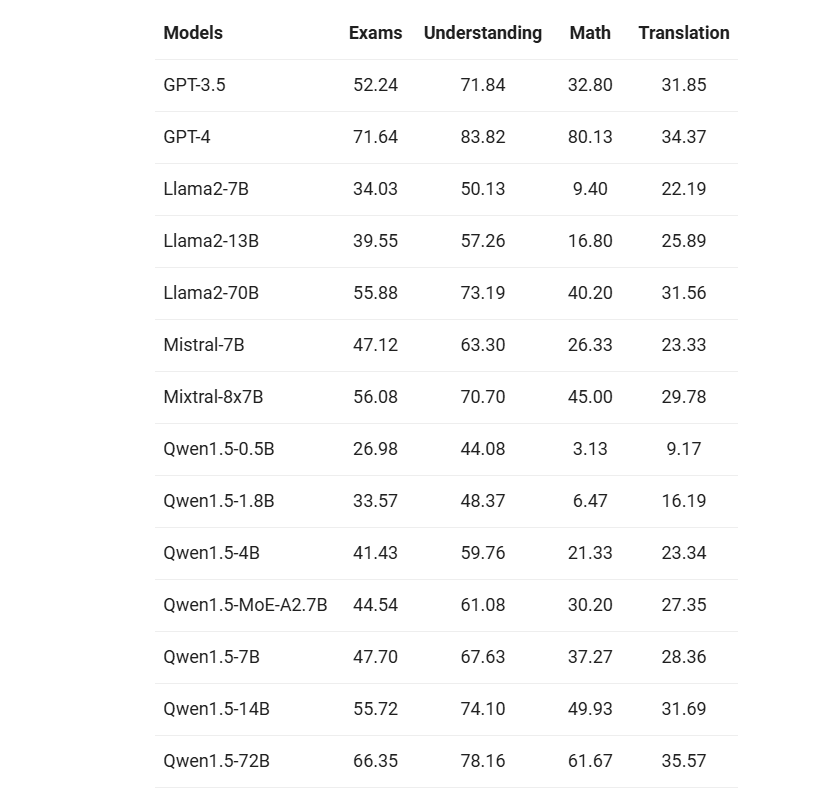
上述结果表明,Qwen1.5 Base模型在12种不同语言的多语言能力方面表现出色,在考试、理解、翻译和数学等各个维度的评估中,均展现优异结果。不论阿拉伯语、西班牙语、法语、日语,还是韩语、泰语,Qwen1.5均展示了在不同语言环境中理解和生成高质量内容的能力。更进一步地,我们也评估了Chat模型的多语言能力,结果如下所示: 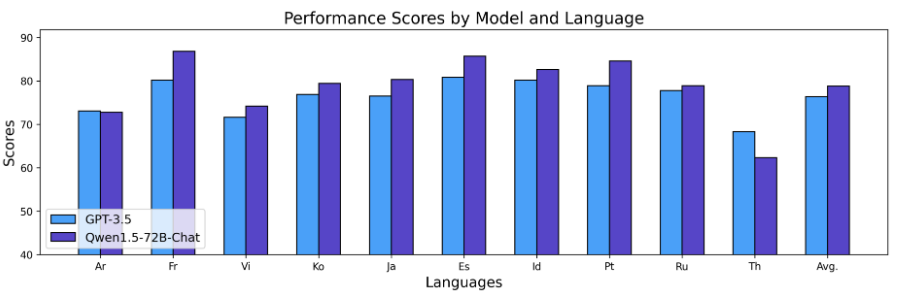
上述结果展示了Qwen1.5 Chat模型强大的多语言能力,可用于翻译、语言理解和多语言聊天等下游应用。我们相信多语言能力的提升,对于其整体通用能力也具有正向的作用。
5.4 长序列能力
随着长序列理解的需求不断增加,我们这次推出的 Qwen1.5 模型全系列支持 32K tokens 的上下文。我们在L-Eval 基准上评估了 Qwen1.5 模型的性能,该基准衡量了模型根据长输入生成答案的能力。结果如下:
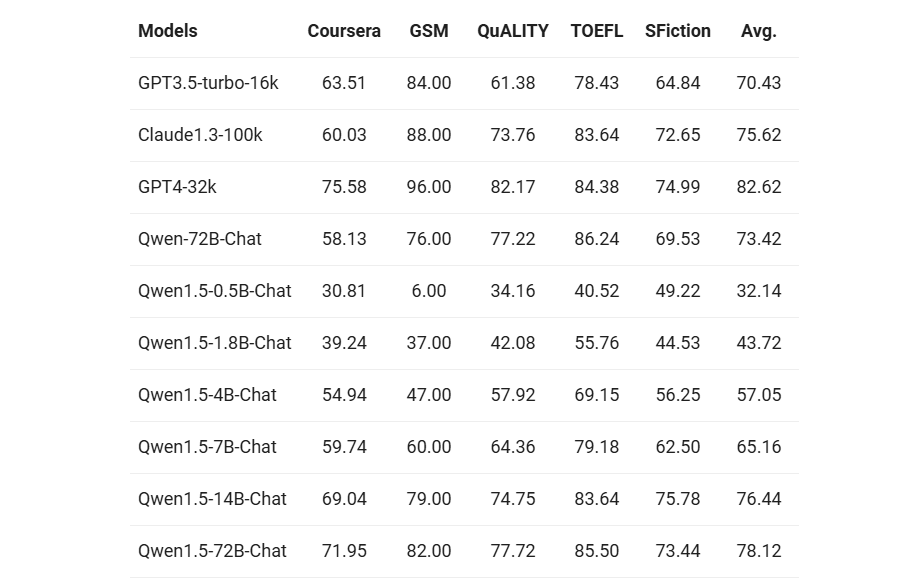
从结果来看,即使像 Qwen1.5-7B-Chat 这样的小规模模型,在上面大5个任务中的4个表现出与 GPT3.5-turbo-16k 类似的性能。而我们最好的模型 Qwen1.5-72B-Chat,仅略微落后于 GPT4-32k。尽管上述结果仅突显了我们在处理 32K tokens 长度时所展现的卓越性能,但这并不代表模型的最大支持长度仅限于 32K。您可以在 config.json 中,将 max_position_embedding 和 sliding_window 尝试修改为更大的值,观察模型在更长上下文理解场景下,是否可以达到您满意的效果。
5.5 链接外部系统
如今,通用语言模型的一大魅力在于其与外部系统对接的潜能。具体而言,RAG作为一种在社区中快速兴起并广受青睐的任务,有效应对了大语言模型面临的一些典型挑战,比如幻觉、无法获取实时更新或私有数据等问题。此外,语言模型在使用API和根据指令及示例编写代码方面,展现出强大的能力。这使得LLM能够作为代码解释器或AI智能体,发挥更广阔的价值。
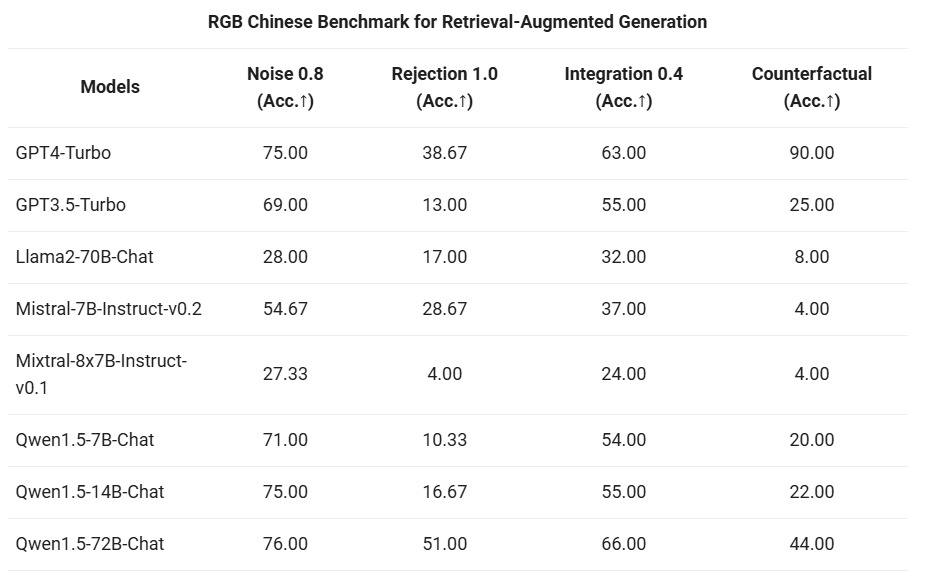
我们首先对 Qwen1.5 系列 Chat 模型,在 RAG 任务上的端到端效果进行了评估。评测基于 RGB 测试集,是一个用于中英文 RAG 评估的集合:
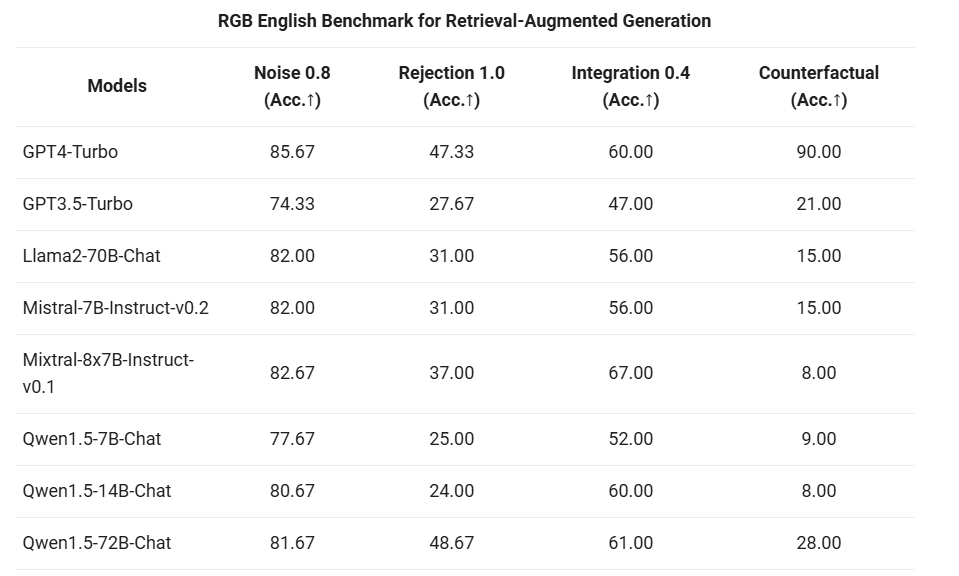
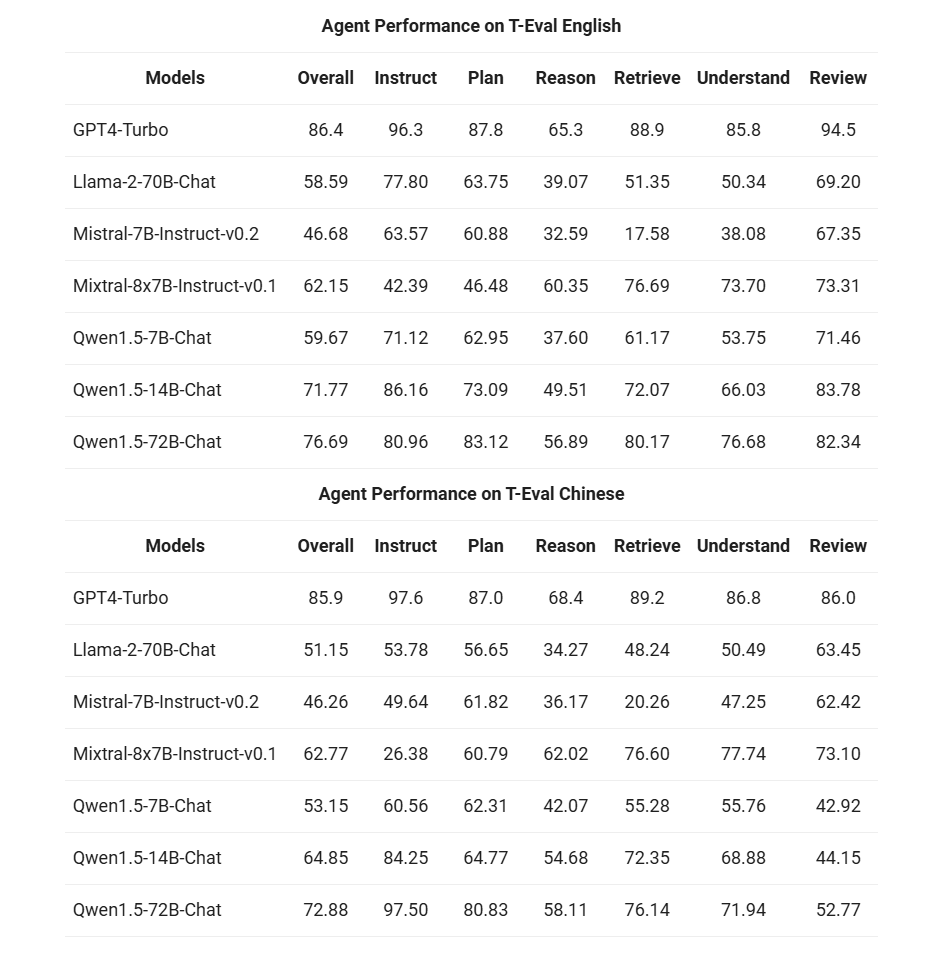
然后,我们在T-Eval 基准测试中评估了 Qwen1.5 作为通用代理运行的能力。所有 Qwen1.5 模型都没有经过专门针对该基准的优化:
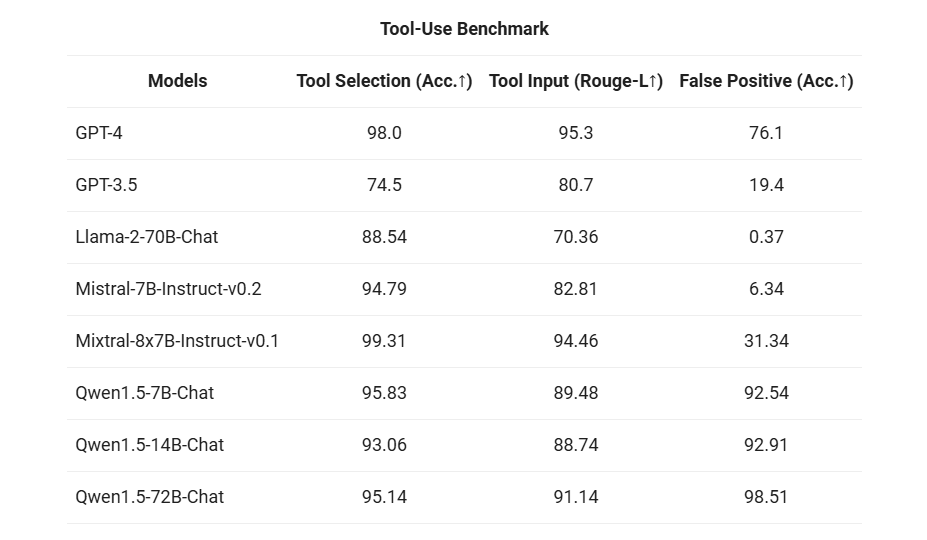
为了测试工具调用能力,我们遵循之前做法,使用我们自己开源的 评估基准 ,测试模型正确选择、调用工具的能力,结果如下:
最后,由于 Python 代码解释器已成为高级 LLM 越来越强大的工具,我们还在之前开源的 评估基准 上评估了我们的模型利用这一工具的能力:
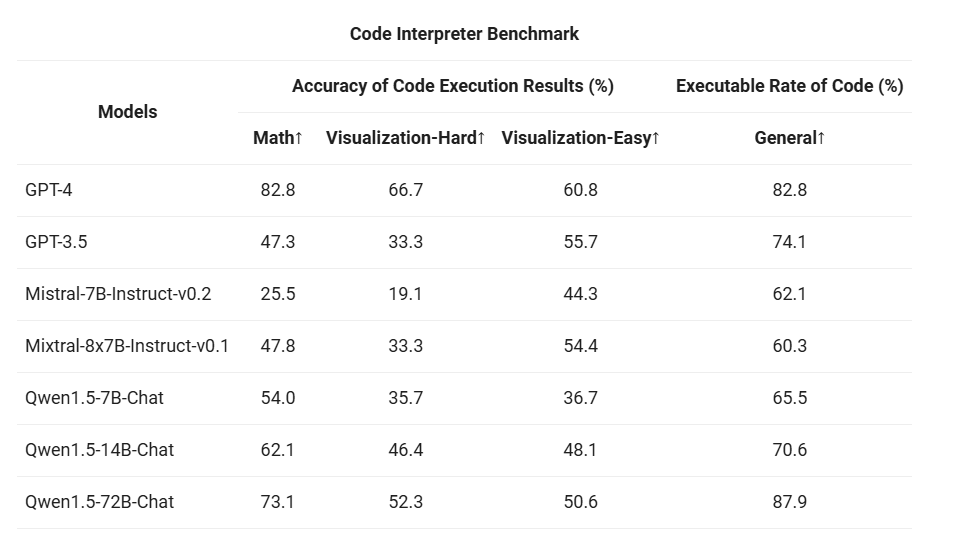
较大的 Qwen1.5-Chat 模型通常优于较小的模型,接近 GPT-4 的工具使用性能。不过,在数学解题和可视化等代码解释器任务中,即使是最大的 Qwen1.5-72B-Chat 模型,也会因编码能力而明显落后于 GPT-4。我们的目标是在未来的版本中,在预训练和对齐过程中提高所有 Qwen 模型的编码能力。
六 结论
Qwen1.5 是 Qwen 系列重要里程碑,通过开源多规模 (0.5B--110B)、提供量化 / MoE 版本、支持长上下文 (32K)、兼容主流开源生态 (transformers, 推理/部署框架)、提供 Chat 模型 (对齐人类偏好) ------ 极大地提升了模型的通用性、易用性与开发者体验。
Qwen1.5-MoE:
摘要
Qwen1.5‑MoE 发布了一个稀疏 (Mixture‑of‑Experts, MoE) 版本模型 Qwen1.5‑MoE‑A2.7B。该模型在运行时仅激活约 27 亿 参数 (activated parameters),但其性能可与当前最先进的 7B 级别模型 (如 Mistral-7B、Qwen1.5-7B) 相媲美。与 Qwen1.5‑7B 相比,Qwen1.5‑MoE‑A2.7B 的 Non‑embedding 参数量约为 其三分之一 (2.0B vs 6.5B),训练成本减少约 75% ,推理速度提升约 1.74 倍。该 MoE 模型展示了稀疏架构在资源利用 (训练 / 推理) 与性能平衡方面的潜力,为开源社区提供了高效率 / 高性价比的大语言模型选项。
一 介绍
随着 MoE (Mixture‑of‑Experts) 模型(如 Mixtral 等)在大模型领域受到关注,研究者和实践者普遍关注如何有效训练 MoE 模型 ,以及 稀疏模型在效率 /性能 /资源利用之间的折中。 Qwen 团队借此契机,推出了 Qwen1.5‑MoE‑A2.7B。
Qwen1.5‑MoE‑A2.7B 在激活参数仅 2.7B 的情况下,实现了与当前主流 7B 模型 (例如 Mistral-7B, Qwen1.5-7B) 相当的性能,证明 MoE + 稀疏激活 + 结构优化 是提升模型效率与降低资源消耗的可行方案。
相比于 dense 模型 (full‑parameter 模型),该 MoE 模型有望大幅降低训练 /推理成本,并在多种任务 (语言理解、数学、编码、多语言、多任务) 上保持竞争力,为开源大模型部署 /使用提供更低门槛、更高资源利用率的选择。
二 架构
Qwen1.5‑MoE‑A2.7B 基于标准 Transformer decoder‑only 架构。其核心亮点在于采用混合专家 (MoE, Mixture‑of‑Experts) 机制。与传统每层少数几个 expert 的 MoE 不同,Qwen1.5‑MoE 使用了 fine‑grained experts 设计 ------ 将原本一个 FFN 分割为多个子部分 (sub‑FFN),每个子部分作为一个独立 expert,从而在不显著增加总参数量 (total params ≈ 14.3B) 的前提下,构建更多 expert。
在 routing (专家选取) 机制方面,Qwen1.5‑MoE 采用了 shared experts + routing experts 的混合策略:模型包含 64 个 expert,其中 4 个共享 expert 总是被激活,其余 60 个为 routing experts,每次激活其中 4 个。这样的设计兼顾了通用性 (shared expert 处理基础通用任务) 与专业性 / 专注性 (routing expert 处理更专门或难度任务)。
这样的设计使得在推理 (inference) 或训练时,仅激活少量 expert,从而减少实际计算 / 激活参数量 (activated parameters),实现稀疏计算 (sparse computation) 的优势,同时保持模型容量与表达能力。
三 预训练
官方博客与文档并未公开 Qwen1.5‑MoE‑A2.7B 的详细预训练过程 (例如使用语料、训练步数、compute 预算、超参数配置等)
Qwen1.5‑MoE 的代码仓库 (Hugging Face) 表示该模型 "pretrained on a large amount of data" (使用大量数据预训练) 。 由于预训练细节未公开,不对未公开内容作推测。
四 后训练 / 微调
据 Hugging Face 模型页面,Qwen1.5‑MoE‑A2.7B 及其 Chat 版本接受了"post-training":即 supervised fine‑tuning (SFT) 和 direct preference optimization (DPO) 等对齐 (alignment) / 微调方法。
这一后训练 / 对齐使得 MoE 模型不仅具有基础能力 (生成 /理解 /编码 /多语言),也具备类似 Chat 模型 (instruction-following / 对话) 的能力,实现从 base → chat 的转化。
由于官方 /博客未就后训练超参数、数据集、训练流程细节公开,本节仅概述对齐 /微调步骤存在,而不深入细节。
五 评估
5.1 表现
为了全面评估并展示我们新开发的模型的性能和优势,我们对基础模型和聊天模型在各种基准数据集上进行了广泛的评估。对于基础模型,我们使用 MMLU、GSM8K 和 HumanEval 这三个基准测试来评估其语言理解、数学和编程能力。此外,为了衡量其多语言能力,我们遵循 Qwen1.5 的评估协议,并在涵盖考试、理解、数学和翻译等多个领域的基准测试中对其进行了测试,并在"多语言"一栏中给出了综合得分。对于聊天模型,我们没有采用传统的基准测试,而是使用 MT-Bench 对其进行了测试。
在本对比分析中,我们将 Qwen1.5-MoE-A2.7B 与性能最佳的 7B 基准模型(例如 Mistral-7B(v0.1 基准模型和 v0.2 指导模型)、Gemma-7B 和 Qwen1.5-7B)进行了比较。此外,我们还将其与参数数量相近的其他 MoE 模型(特别是 DeepSeekMoE 16B)进行了比较。结果汇总如下表:
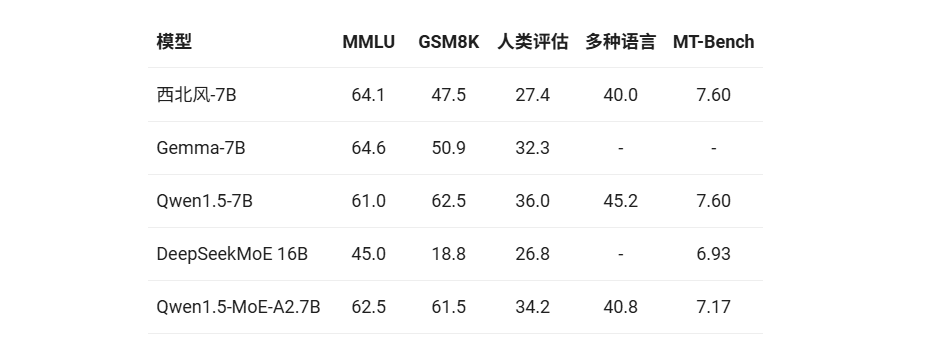
Qwen1.5-MoE-A2.7B 模型在各项评估中展现出了与排名前 7B 的模型相媲美的性能。尽管如此,我们的分析表明,该模型在聊天模型领域仍有巨大的提升空间。因此,我们致力于进一步研究,以完善 MoE 模型的有效微调策略。
5.2 成本与效率
MoE模型的训练成本与其对应的密集模型存在显著差异。尽管参数数量更多,但由于稀疏性,MoE模型的训练成本可以显著降低。为了更好地理解这一点,我们首先深入探讨三个关键组成部分:参数总数、有效参数数和非嵌入参数数,并对模型进行比较:

显然,我们的 MoE 模型中非嵌入参数的数量远少于 7B 模型。在实际应用中,我们观察到,与 Qwen1.5-7B 相比,使用 Qwen1.5-MoE-A2.7B 时训练成本显著降低了 75%。尤其值得注意的是,通过升级再造,无需像原始模型那样训练等量的 token。这在节省训练成本方面带来了显著的提升。
我们部署了搭载 vLLM 的 Qwen1.5-7B 和 Qwen1.5-MoE-A2.7B 两款模型,并使用单块 NVIDIA A100-80G GPU 进行了性能测试。在实验设置下,输入 token 数量和输出 token 数量均设置为 1000,我们从吞吐量(每秒处理的请求数)和每秒 token 数 (TPS) 两个方面测量了性能:
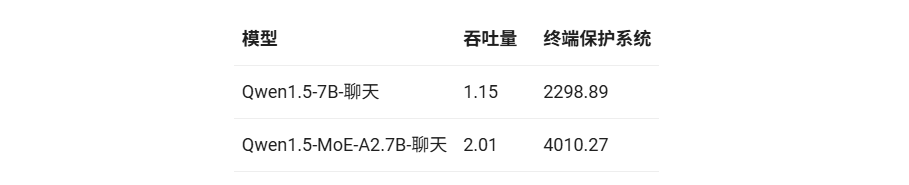
Qwen1.5-MoE-A2.7B 模型的速度显著提升,比 Qwen1.5-7B 模型快约 1.74 倍。这种加速主要归功于 MoE 架构仅激活了其总参数中明显较少的部分,从而降低了计算需求。此外,共享专家的集成也极大地提高了模型的推理效率。因此,尽管 MoE 模型需要更高的内存,但它们在吞吐量和推理速度方面都展现出了明显的优势。
六 结论 (Conclusion)
Qwen1.5‑MoE‑A2.7B 证明了通过 Mixture‑of‑Experts 架构、fine‑grained experts、shared 与 routing expert 混合机制,可以在仅激活 ~2.7B 参数的条件下,达到与主流 7B 模型相当的性能。其训练资源消耗大幅减少 (约 1/4),推理速度显著提升 (约 1.74×),为开源社区和资源受限环境提供了高性价比 / 高效率 / 高灵活度的大模型解决方案。官方也表示将继续研究和优化 MoE 模型。
参考文献
1 Qwen1.5 :https://qwenlm.github.io/zh/blog/qwen1.5/
2 Qwen1.5 -32b:https://qwenlm.github.io/zh/blog/qwen1.5-32b/
2 Qwen1.5 -MoE:https://qwenlm.github.io/blog/qwen-moe/