LLM 与传统解析技术的融合:网页数据提取的演进与最佳实践
张子彪 | 郑州数能软件技术有限公司 | 中国
一、传统解析技术:规则与统计的时代
1.1 核心方法演进
| 时期 | 技术代表 | 工作原理 | 典型工具 |
|---|---|---|---|
| 规则方法 | 正则表达式/XPath/CSS选择器 | 人工编写模式匹配规则 | BeautifulSoup, Scrapy |
| 统计方法 | CRF/HMM 序列标注 | 从标注数据学习实体识别概率模型 | Stanford NER, CRF++ |
| 视觉解析 | OCR+坐标定位 | 渲染页面截图后识别文字位置 | Selenium+Tesseract |
1.2 传统解析的缺点
python
# 示例:css 提取网站来源信息 - 网站改版即崩溃
price = response.xpath('//span[@class="source"]/text()').get()- 泛化性差:页面结构微调导致规则失效
- 语义理解缺失:只能提取显性字段(如价格),无法总结产品描述
- **人工配置:**需要根据每个网站栏目的结构进行人工配置
- **属性提取复杂:**部分特殊属性,如来源、发文字号等结构性不强,通过配置难以准确提取出来
1.3 传统解析优点以及适合的场景
-
处理效率高:传统解析原理为本地结构化字符解析,效率很高
-
适合结构性强的内容:如标题、列表页列表解析、正文片段的提取通过简单的配置可以很好的提取
-
**解析优化:**通过对css表达式进行合理的配置可以适应网页微小结构变化。例如:
java//这里 span > li 限制太死,如果 span 和 li 之间插了个别的标签(比如 <div>、<em> 等),就匹配不到了。 div[class="zsy_conlist"] > ul > span > li > a //换成后代选择器(空格) div[class="zsy_conlist"] > ul > span li a //这样无论 span 和 li 之间插了多少层标签,都能匹配到。适应了网页结构的微小变化
二、LLM 解析:语义理解革命
2.1 LLM 的核心优势
markdown
[输入] HTML 代码(含广告/无关标签)
[LLM 指令] 提取联系人邮箱并总结主营业务
[输出]
{
"email": "contact@realestate.com",
"business": "专注互联网信息采集,数据处理解决方案"
}- 突破结构依赖:直接理解网页语义
- 复杂任务处理:实体提取 + 摘要生成 + 话术定制一站式完成
- 抗干扰能力:忽略前端混淆代码(如动态 class 名)
2.2 LLM 的四大准确性问题
| 问题类型 | 案例 | 根源 |
|---|---|---|
| 概率性偏差 | 电话 138-0013-8000 → 13800138000 |
追求语义合理而非精确匹配 |
| 上下文截断 | 长页面尾部信息丢失 | 窗口限制(如 DeepSeek 64K) |
| 对抗干扰失效 | 图片电话无法识别 | 纯文本模型局限 |
| 处理速度较慢 | 特定内容提取速度较慢 | 网络和模型性能局限 |
三、混合解析架构:平衡准确率与泛化性
3.1 技术融合设计方案
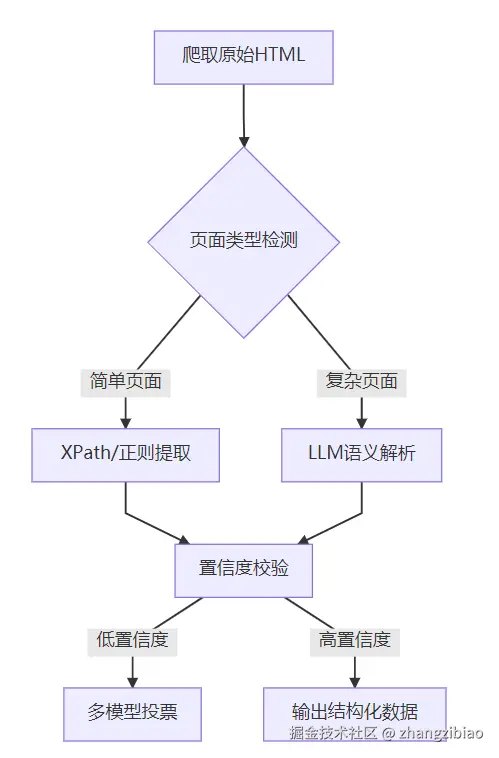
3.2 关键实施策略
策略 1:LLM 输出强约束
prompt
严格按 JSON 输出:
{
"name": "字符串或null",
"phone": "必须符合 ^\\d{3}-\\d{4}-\\d{4}$ 格式",
"business": "不超过20字的摘要"
}
禁止编造不存在的信息!策略 2:传统规则兜底
python
def validate_phone(phone):
import re
pattern = r'^\d{3}-\d{4}-\d{4}$' # 强格式校验
return bool(re.match(pattern, phone)) if phone else False策略 3:动态分块处理
python
# 解决长页面上下文溢出
from bs4 import BeautifulSoup
def chunk_html(html, max_tokens=2000):
soup = BeautifulSoup(html, 'html.parser')
chunks = []
current_chunk = ""
for section in soup.find_all('section'): # 按语义区块分割
if len(current_chunk) + len(section.text) > max_tokens:
chunks.append(current_chunk)
current_chunk = section.text
else:
current_chunk += section.text
return chunks3.3 效能对比(政策法规资讯解析场景)
| 方案 | 政策特有属性准确率 | 正文准确率 | 成本/千页 | 改版适应力 |
|---|---|---|---|---|
| 纯传统规则 | 68% | 95% | $0.01 | ❌ |
| 纯 LLM (DeepSeek) | 96% | 83% | $0.15 | ✅ |
| 混合架构 | 98% | 97% | $0.08 | ✅ |
四、实战案例:通用网页信息采集系统
4.1 技术栈组成
| 组件 | 推荐工具 | 作用 |
|---|---|---|
| 爬虫框架 | Crawl-for-AI / selenium | 网页抓取 |
| 动态渲染 | chrome-driver | 处理 JS 加载内容 |
| LLM 解析 | DeepSeek-V3 + glm:GLM-4-Flash | 摘要生成与属性提取 |
| 规则引擎 | 自定义 Python 校验库 | 关键字段格式验证 |
| 代理服务 | Bright Data | IP 轮换防封禁 |
4.2 工作流
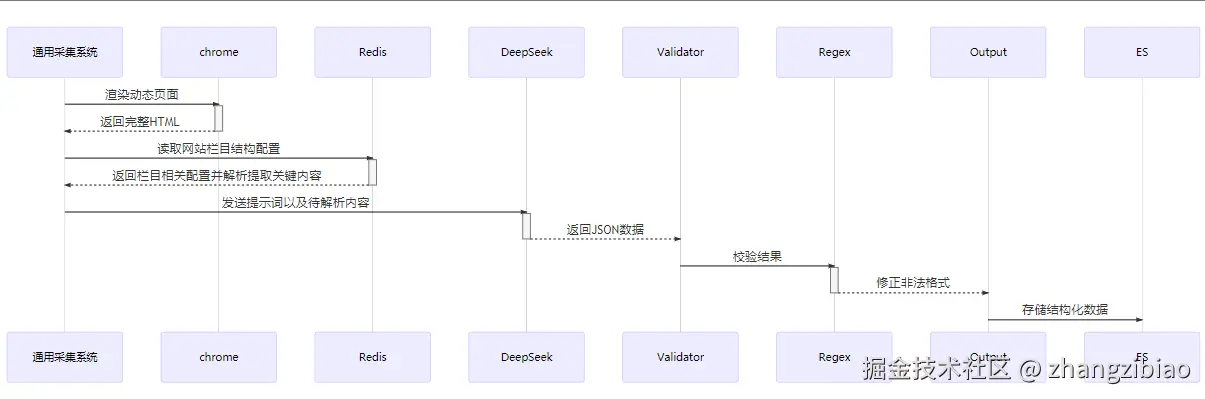
4.3 效益分析
- 采集效率和准确率:通过对特定网站的简单配置,无需关心后续流程;自动化采集 -> 执行业务逻辑
- 语义理解与处理:LLM 生成总结和提取特定内容属性
- 成本控制:混合方案比纯 LLM 解析降低 47% 费用
五、结论:技术选型指南
5.1 推荐方案矩阵
| 场景 | 推荐方案 | 原因 |
|---|---|---|
| 政府公报/API 数据 | 纯规则解析 (XPath、css) | 结构稳定,成本近乎为零 |
| 电商价格监控 | 规则+LLM 摘要 | 需高精度数字提取+活动描述理解 |
| 企业黄页获客 | LLM 为主+规则校验 | 适应多样式页面,保障关键字段准确 |
| 动态渲染SPA 应用 | Playwright+LLM 分块处理 | 需先执行 JS,长页面分段解析 |
5.2 未来方向
- 多模态解析突破:LLM+Vision 识别图片电话/验证码
- 自迭代包装器:LLM 自动生成维护 XPath 规则
- 轻量化部署:7B 级模型本地化运行(如 Llama 3 + ONNX)
终极法则:
- 关键字段(电话/邮箱)必须规则校验
- 语义任务(摘要/话术)交给 LLM 发挥
- 动态内容预先渲染
- 长页面分块处理+去重合并
通过 LLM 的语义泛化能力 + 传统规则的确定性保障,现代数据提取系统正实现准确率与适应性的双重突破。