
文字生成视频(Text-to-Video, TTV)是一项融合自然语言处理(NLP)、计算机视觉(CV)、多媒体检索与生成技术 的复杂任务,其核心目标是通过代码逻辑将文本语义转化为高质量、高相关性的视频内容。以下从技术链路拆解、关键模块设计、精度优化策略、典型代码框架四个维度展开深度分析,揭示"精准"背后的代码设定逻辑。
一、技术链路拆解:从文本到视频的核心流程
一个完整的TTV系统需经历「文本理解→语义映射→素材检索/生成→时序编排→渲染输出」五大环节,每个环节的代码设定直接影响最终视频与文本的匹配精度。以下是各环节的关键作用及代码设计要点:
1. 文本理解层:构建可计算的语义表征
- 目标:将非结构化的自然语言文本转化为机器可理解的结构化语义向量或标签集合。
- 核心技术 :
✅ 预训练语言模型(LM) :使用BERT、RoBERTa、CLIP文本编码器等提取上下文感知的句向量;
✅ 实体识别(NER) :通过Spacy/Stanford NER标注人名、地名、组织机构、时间、动作等关键实体;
✅ 依存句法分析:利用Stanford CoreNLP或LTP解析句子语法树,明确主谓宾关系以捕捉动作主体与客体。 - 代码示例(PyTorch + HuggingFace Transformers):

2. 语义映射层:建立文本-视觉的跨模态关联
- 目标:将文本语义映射到具体的视觉元素(图像/视频帧、镜头类型、色彩风格等)。
- 两类主流路径 :
🔹 检索式(Retrieval-Based) :从现有库存中匹配最接近文本描述的视频片段(适用于新闻、短视频剪辑);
🔹 生成式(Generative):直接生成新视频(依赖扩散模型、GANs等,适用于创意场景)。 - 代码设计核心 :
✅ 跨模态哈希/相似度计算 :若采用检索式,需预先为库内视频的每一帧提取特征(如ResNet+LSTM时序特征),并与文本嵌入做余弦相似度排序;
✅ 属性标签体系 :定义标准化的视觉属性字典(如[主体:猫, 动作:奔跑, 背景:草地, 光照:白天]),将文本解析后的实体映射到该字典。 - 示例:基于CLIP的跨模态匹配(CLIP天然支持文本-图像对齐):
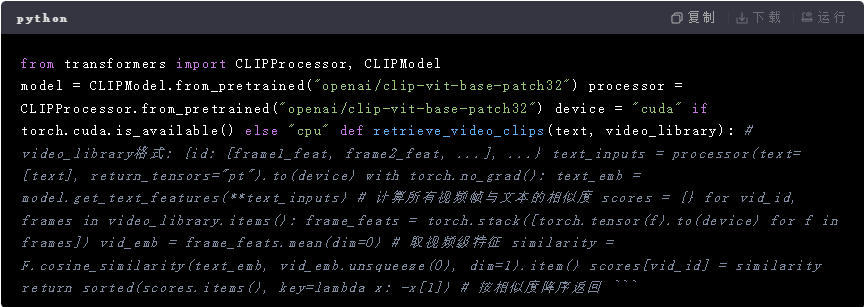
- 精度瓶颈:"一词多义"(如"苹果"既可指水果也可指品牌)需结合上下文消歧;抽象概念(如"快乐")难以直接映射,需引入情感分析辅助。
3. 素材加工层:动态调整与补全
- 目标:解决检索/生成素材与文本的细节偏差(如主体位置、动作幅度、时长不足)。
- 关键技术 :
✅ 关键帧插值 :对缺失的动作过渡帧,使用光流法(Farneback算法)或基于深度学习的运动估计模型(RAFT)生成中间帧;
✅ 前景替换 :通过Mask R-CNN分割视频中的前景/背景,用GANs(如pix2pixHD)将文本指定的新主体合成到场景中;
✅ 文本叠加:在视频顶部添加字幕时,需根据文本重要性动态调整字体大小、停留时间(如主标题保留3秒,副标题1秒)。 - 代码示例:基于OpenCV的关键帧插值:

- 精度控制:设置阈值过滤低置信度的插值结果(如光流误差超过δ则放弃该帧)。
4. 时序编排层:构建符合叙事逻辑的时间线
- 目标:确定各视频片段的顺序、时长、转场效果,使整体节奏与文本语义流畅衔接。
- 核心规则引擎 :
✅ 显式时序信号 :文本中的时间副词("首先""然后""最后")直接决定片段顺序;
✅ 隐式逻辑推理 :无明确时序时,按"背景铺垫→主体出现→动作发展→结果呈现"默认顺序排列;
✅ 节奏适配:根据文本情感强度调整片段时长(如激动场景缩短单帧时长加快节奏)。 - 代码示例:基于规则的时间线生成:

- 难点:多片段交叉淡入淡出时的透明度曲线需平滑过渡,避免画面跳跃。
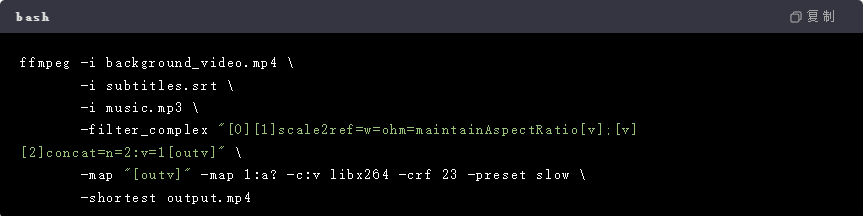
5. 渲染输出层:多轨合成与压缩
- 目标:将视频片段、字幕、背景音乐合并为最终MP4文件,同时控制文件大小。
- 关键参数 :
✅ 分辨率适配 :根据文本复杂度选择分辨率(如简单文字描述用720p,复杂场景用1080p);
✅ 码率控制 :使用FFmpeg的CRF(Constant Rate Factor)参数平衡画质与文件大小(通常18-28,越小画质越好);
✅ 音画同步:通过PTS(Presentation Time Stamp)校准音频与视频的时间戳。 - 代码示例:FFmpeg多轨合成:
二、精准度提升的关键策略
为实现"文字-视频"的高保真映射,需在以下方面进行针对性优化:
1. 细粒度语义建模
- 解决方案 :放弃单一的全局文本向量,改用多粒度特征组合 (字符级+词级+句级+文档级),例如:
- 字符级:识别特殊符号(!表示强调,...表示悬念);
- 词级:提取动词的核心论元(施事者、受事者、工具);
- 句级:判断句子类型(陈述/疑问/感叹);
- 文档级:捕捉段落间的逻辑关系(因果、并列)。
- 代码改进:在BERT基础上增加注意力机制提取关键词汇的特征:

2. 领域自适应训练
- 问题:通用模型在垂直领域(如医疗、教育)表现差,因专业术语与日常用语分布差异大。
- 解决方法 :收集领域内的文本-视频配对数据,对预训练模型进行微调(Fine-tuning):
- 损失函数设计:结合对比损失(Contrastive Loss)拉近正例(匹配的文本-视频)距离,推远负例;
- 数据增强:对文本进行同义词替换(如"医生"→"医师"),对视频进行随机裁剪、翻转,扩充数据集。
- 代码示例:领域适应微调:

3. 用户反馈闭环
- 意义:通过人工标注的错误案例持续修正模型偏差(如"夕阳下的跑步者"被错误生成夜间场景)。
- 实现方式 :
🔹 建立纠错数据库,记录失败案例的文本、期望视频、实际生成视频;
🔹 定期用纠错数据重新训练模型,重点关注高频错误类型(如时间错误、主体错误);
🔹 前端提供"不满意重试"按钮,收集用户点击行为作为隐式反馈。

三、典型代码框架与工具选型建议
根据业务需求(实时性/质量优先),可选择以下两种主流方案:
| 方案 | 适用场景 | 核心组件 | 优势 | 劣势 |
|---|---|---|---|---|
| 检索式TTV | 短视频剪辑、新闻报道生成 | CLIP/ViLBERT(跨模态检索)、FFmpeg | 速度快(秒级生成)、成本低 | 依赖现有素材库,灵活性低 |
| 生成式TTV | 广告创意、故事片预览 | Stable Diffusion v2/Imagen Video、Deformable DETR | 完全原创,创意度高 | 耗时久(分钟级)、算力消耗大 |
推荐工具链:
| 环节 | 工具/库 | 备注 |
|---|---|---|
| 文本处理 | SpaCy、HuggingFace NLP | 实体识别、句法分析 |
| 跨模态检索 | CLIP、ALIGN | 开源且效果好 |
| 视频生成 | Imagen Video、Make-A-Video | 基于扩散模型的长视频生成 |
| 视频编辑 | MoviePy、OpenCV | 关键帧操作、特效添加 |
| 部署 | ONNX、TensorRT | 加速推理速度 |
四、总结:精准代码的核心原则
文字生视频的"精准"本质是最小化文本语义与视频内容的KL散度,其代码设定需遵循以下原则:
- 分层递进:从粗粒度的全局语义到细粒度的元素级特征逐步细化;
- 动态适配:根据文本类型(叙述型/描写型/抒情型)切换生成策略;
- 数据驱动:持续积累领域数据优化模型,结合规则引擎弥补数据缺口;
- 用户体验导向:允许用户干预关键步骤(如手动调整片段顺序),降低黑盒感。
最终,一套优秀的TTV代码不仅是技术的堆叠,更是对"人类如何理解语言并转化为视觉叙事"这一认知过程的模拟与优化。