今天(8 月 16 日),我的心跳随着地铁的每一次加速而加快,目的地------北京大钟寺的字节工区!不是来面试,也不是来参观,而是为了一个让我期待已久的盛会:TRAE Meetup!作为一名对 AI 编程和前沿技术充满无限好奇的开发者,我早就对 TRAE 这个名字不陌生,它代表着 AI 辅助编程的未来方向。这次能亲临字节的线下活动,与众多技术大咖和同好们面对面交流,简直是激动到模糊,感觉自己像个追星族,终于见到了"爱豆"!

一踏入字节工区,那种独特的科技感和活力扑面而来。宽敞明亮的活动大厅里,已经聚集了近四百位来自五湖四海的开发者。空气中弥漫着一种独特的、属于技术人的兴奋与专注。我看到有人背包里鼓鼓囊囊,笔记本、各种接口线、甚至还有人带着路上写到一半的代码,那份对技术的热爱简直要溢出来了。入口处,老朋友们一见面就热情地拥抱、击掌,新面孔们则带着几分腼腆又充满期待地交换着微信,轻声讨论着各自的项目和想法,仿佛下一秒就能碰撞出火花。这种生动、真实、充满活力的技术社区氛围,瞬间就让我感受到了技术人的温度和凝聚力,也让我对今天的活动充满了更高的期待!

简短的互动环节后,主持人宣布活动正式开始,全场灯光聚焦,重头戏来了!四位来自 TRAE 核心团队及行业知名开发者的嘉宾轮番上阵,他们将从 TRAE 的幕后故事到 AI 编程的实战技巧,为我们带来一场知识的狂轰滥炸!我赶紧拿出小本本,生怕漏掉任何一个知识点,毕竟,这可是近距离学习顶尖技术和实践经验的绝佳机会!

💡 嘉宾分享,干货连连,脑洞大开!
- 天猪(TRAE 架构师)------《AI Coding 的构建与演进》
第一位登场的是 TRAE IDE 的核心开发者、TRAE 架构师天猪老师。他一登场,就自带一种架构师的沉稳与洞察力。他从系统架构与迭代历程入手,为我们梳理并回顾了 TRAE IDE 的发展里程碑。从 2024 年 TRAE 上线,到 2025 年国内外版本发布,再到月活跃用户突破 100 万的关键节点,这些不仅仅是冰冷的数字,更是 TRAE 团队无数个日夜的智慧结晶和辛勤付出。听着这些成就,我内心充满了敬佩,也更期待 TRAE 未来的发展。

最让我印象深刻的是,天猪老师深入阐述了 AI Coding 的三个阶段:辅助编程、结对编程、自主编程。这三个阶段的划分,让我对 AI 在编程领域的未来有了更清晰的认知,不再是模糊的概念,而是触手可及的演进路径。他详细介绍了 TRAE Agent 的架构演进和 SOLO 模式的协作创新,这不仅仅是技术上的创新,更是对未来协作模式的深刻思考。想象一下,AI 不再仅仅是工具,而是能与我们并肩作战的"队友",甚至能独立完成任务,这简直是科幻电影里的场景正在变为现实!天猪老师最后强调,在 AI 能力飞速发展的今天,如何与 AI 更好地协作,发挥出"人机合一"的最大效能,也是我们每一位开发者未来需要深入思考和实践的重要课题。

- 江波(TRAE cue 功能技术负责人)------《TRAE cue 背后的挑战与思考》
接着是 TRAE Cue 功能的技术负责人江波老师。他将我们带入了 TRAE 的"大脑"------智能编程工具 Cue(Context Understanding Engine)的深层世界。他详细介绍了 Cue 的核心功能,如代码补全、多点编辑和智能导入。这些功能听起来简单,但在实际开发中,它们能极大地提升我们的编码效率和准确性,简直是程序员的"贴心小棉袄"!
然而,这些强大功能背后,也隐藏着巨大的技术挑战。江波老师坦诚地分析了 Cue 面临的三大挑战:用户意图理解 (尤其是非线性编辑历史导致的意图偏差,这简直是 AI 编程中最"玄学"的部分,如何让 AI 真正理解我们的所思所想,太难了!)、修改位置确定 (如何在兼顾可扩展性的同时保证速度,这背后是无数次的算法优化和工程实践)、以及编辑执行(如何支持复杂编辑并感知整个仓库的上下文,确保修改的准确性和兼容性)。听着这些挑战,我深感 AI 编程的复杂性,也对 TRAE 团队攻克这些难题的毅力感到由衷的敬佩。
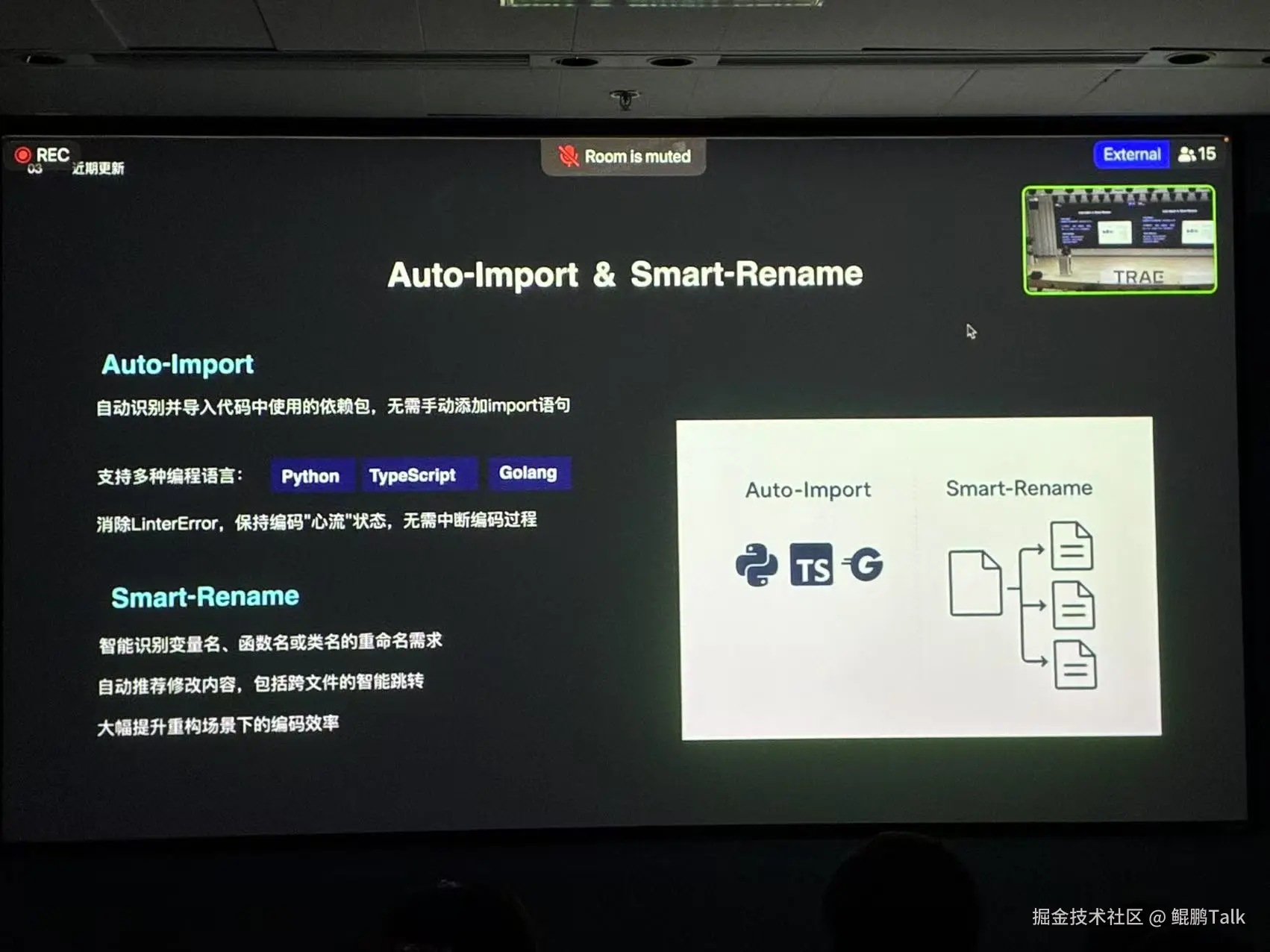
更令人振奋的是,江波老师分享了近期 Cue 的优化成果:时延从 1 秒降至 500 毫秒,这对于追求极致效率的开发者来说,简直是质的飞跃,我几乎要拍手叫好!此外,融合模型升级和支持多语言自动导入,更是让 Cue 的实用性大大增强。他透露,未来还有支持基于模型的仓库级跳转预测以及更多语言扩展的计划,这简直是代码导航的终极梦想,让我对 TRAE 的未来充满了无限期待!
- 唐飞虎(月之暗面 Kimi 开发者关系负责人)------《VibeCoding 案例分享和 Debug 技巧》
月之暗面 Kimi 的开发者关系负责人唐飞虎老师的分享,则从一个更宏观的视角,为我们描绘了"Vibe Coding 时代"的图景。他指出,通用大模型自主完成任务的能力正以惊人的速度提升,TRAE Solo、Claude Code 等工具的出现,正在改变我们传统的编码方式,让编程变得更加"随心所欲"。
他剖析了 AI 工具的双面性:研究显示,使用 AI 可能使开发时间增加 19%------这个数据一开始让我有些意外,甚至有些担忧。但唐老师紧接着的解释,让我豁然开朗:虽然对某些特定任务可能如此,但 AI 能显著提升非工程师的效率和整个团队的协作能力,让更多人能够参与到创造中来。这让我意识到,AI 并非要取代我们,而是要赋能我们,让我们能做更多、做得更好。
接着,唐飞虎老师更是慷慨地分享了在 AI 深度融入开发流程的今天,如何用好大模型、写好代码的四大提效技巧,这简直是提升 AI 协作效率的"武林秘籍"!

四大提效技巧:让 AI 编程又快又省
大模型调用成本高、响应慢?掌握这四大技巧,既能省 TOKEN,又能提效率。
- 缓存技术:重复场景的"省钱利器" 唐老师举了一个生动的例子:如果同一天要对一份合同反复提问 100 次,每次只有 1 行问题不同,难道每次都要让模型重新读取几百行合同吗?当然不!这正是缓存技术的用武之地。将不变的材料(如合同全文)缓存下来,每次仅传入变化的问题部分,能大幅减少重复计算,从而节省 TOKEN。这就像我们日常生活中,把常用的资料放在手边,而不是每次都去图书馆重新查找。更惊喜的是,缓存不仅能省 TOKEN,还能提升首 TOKEN 响应速度:原本需要几十秒的短提问,可能压缩到几秒内完成。这种速度的提升,在实际开发中意味着更流畅的交互体验和更高的工作效率。唐老师还自豪地提到,团队近期凭借这项大模型缓存技术,还拿下了 Fast R5 年度最佳论文奖,足见其技术价值和前瞻性。听得我茅塞顿开,感觉我的 Prompt 要立刻升级,让 AI 助手变得更聪明、更高效!
- 压缩与减脂:给代码"瘦个身" 代码太臃肿、上下文太长?试试"压缩减脂法"。唐老师分享了一个团队处理多轮工具调用的案例:他们不再丢弃前几十轮记录,而是巧妙地压缩重复的工具询问内容,既保留了关键信息,又减少了冗余。这就像我们整理文件,把重复的、不重要的内容归档或删除,只留下核心要点。对于安装库、环境配置等与主线任务无关的操作,还可以用"剪枝"设计单独剥离,让模型聚焦核心任务,避免被无关信息干扰。此外,借助知识库将资料"回喂"给模型,或用标准化 SDK 压缩 Web 信息,都能让模型接收的内容更精炼,避免"信息过载",从而提升处理效率和准确性。这种"瘦身"策略,不仅能节省 TOKEN,更能让 AI 的"思考"更聚焦、更高效。

- 并行方法:多任务处理的"加速器" 遇到需要同时查地图和天气、或并行生成多个方案的场景?别让模型"单线程工作"!唐老师指出,像 OpenAI 的 Function Call 原生支持并行调用,部分工具还能一次调用生成多轮回复。这意味着我们不再需要等待一个任务完成后再开始下一个,而是可以同时进行多个任务,大大缩短了等待时间。更进阶的玩法是用"多智能体":比如让 3 个独立子智能体同时 brainstorm 创意,最后汇总选择最优解。这就像一个高效的团队,每个人负责一部分,最后汇总成果,效率远超单打独斗。甚至可以用"多账号轮用额度""多窗口并行操作"等"暴力方法",适合多项目同步推进的场景,让模型"多线程工作",效率倍增!这种并行处理的思维,将彻底改变我们与 AI 协作的方式。
- 结构化 Prompt:让输出更精准 模糊的指令容易让模型"跑偏",结构化 Prompt 能帮你避免歧义。唐老师建议,可以用 JSON、XML 等格式约束输出,或用"填空式"模板(如
{问题}:{答案}),让模型生成的结果更可控、更符合预期。这就像给 AI 一个明确的"答题卡",它就知道该如何组织答案。对于代码规范检查这类场景,不必把冗长的规范塞进上下文,而是将其封装成工具,让模型主动调用------既省空间,又保准确。这种方式不仅能节省 TOKEN,还能确保 AI 输出的质量和一致性,避免了"鸡同鸭讲"的尴尬。这真是提升 AI 协作效率的"武林秘籍"!
- karminski-牙医(KCORES 开源项目联合创始人)------《顺畅编码,远离屎山------VibeCoding 怎样才能避免沦为环卫岗》
最后一位嘉宾,KCORES 开源项目联合创始人 karminski-牙医老师,一出场就以其幽默犀利、直击痛点的风格,瞬间点燃了全场气氛。他以"远离屎山"为主题,深入剖析了 Vibe Coding 中常见的"代码屎山"问题,简直是程序员的"噩梦清单"!他列举了 13 类典型陷阱及其后果,听得我频频点头,仿佛看到了自己代码库里那些"熟悉的陌生人",真是痛并快乐着!
避坑指南:AI 生成代码的 13 个"雷区"
AI 生成代码虽快,但也可能埋下隐患。资深开发者"牙医"总结了 13 种常见问题及应对方案,帮你避开"代码屎山"。
- 代码过长:一个文件塞 9300 行?别这么干! 牙医老师提到,有的项目为了"简洁",把所有代码塞进一个文件,甚至一个函数里(比如某开源项目的 9300 行单文件)。这不仅人难维护,模型也会因上下文超长导致召回率骤降------4K 上下文的模型,性能可能跌破 60%。想象一下,让 AI 去理解一个 9300 行的文件,就像让它在浩瀚的字典里找一个词,效率可想而知。解法:单个文件控制在 800 行内(约 4K TOKEN),函数不超过 200 行,让模型和人都"看得懂",这既是代码规范,也是 AI 友好的实践。
- 全局变量满天飞:小心"牵一发而动全身" AI 生成 JS 代码时,常爱用
let定义全局变量,或挂在window上。结果是:改一处变量,整个项目都可能出问题,生命周期更是难以追踪。这就像在家里到处乱放东西,最后自己都找不到,更别提别人来收拾了。解法:提示词明确要求"少用全局变量",用 OOP 思想封装逻辑,让代码结构更清晰;借助 ESLint 等工具检测冗余变量,早发现早重构,防患于未然。 - 重复代码堆积:改了新的,旧的还在? 有开发者让 AI 生成时间转换函数,改了 4 次生成 4 个函数,旧函数却没删除。别人接手时根本不知道该用哪个,甚至可能调用有问题的旧版本。这就像你买了一件新衣服,旧的却不扔,衣柜里堆满了相似却不同的款式,让人无从选择。解法:提示词要求"重写时删除旧代码",提交前用 Pre-commit 工具检查未使用的函数/变量,确保代码库的整洁和一致性。
- 注释"骗人":代码改了,注释没改? 把 16 像素改成 24 像素,注释却还写着"16px";函数逻辑变了,说明文档纹丝不动。这种"注释不同步"的问题,会让人和模型都 confusion。这就像地图上的标记和实际路况不符,不仅误导了自己,也误导了后来者。解法:要么让 AI 同步改注释,要么自己改代码时顺手更新------别让注释成"误导",保持代码和文档的同步性至关重要。
- 资源不释放:内存泄露的"隐形杀手" 某 AI 生成的 PGP 代码,初始化第三方库后没释放资源,每次调用都新增一份内存占用,最终导致程序被 Linux kill。这就像一个水龙头一直开着,水池迟早会溢出。解法:对涉及 IO、内存的代码,用多模型交叉检查(比如让 GPT-4 再审一遍 Llama 的输出),利用不同模型的优势互补;上线前做压力测试,排查泄露风险,确保程序的健壮性。
- 参数太"松":什么都能传,等于什么都不能传 函数
storeUserInfo(data)接收interface类型,不管 data 是啥都直接序列化存数据库。结果是:前端随便传数据,后端不校验,脏数据直接污染数据库。这就像一个没有安检的机场,什么人都能进来,安全隐患巨大。解法 :参数必须用固定结构(如明确{name:string, age:number}),拒绝"万能接口",从源头挡住脏数据,确保数据的完整性和安全性。
不过,karminski-牙医老师并非只揭露问题,他更提出了针对性极强的解决方案,字字珠玑,句句是金!他幽默地提醒我们,Vibe Coding 虽然能提升效率,但如果使用不当,也可能让我们沦为"环卫岗",疲于清理 AI 生成的"垃圾代码"。这让我深刻认识到,AI 是工具,但最终的质量把控和架构设计,依然离不开我们人类的智慧和经验。
能猜到哪个是博主本人么?😄

🤝 交流互动,温度满满,收获满满!
嘉宾分享结束后,TRAE 团队还介绍了激动人心的**"TRAE Fellow 计划"**。这个计划面向技术热忱者,邀请我们成为连接本地开发者与 TRAE 生态的桥梁,推动更多落地创新。这不仅仅是一个荣誉,更是一个深度参与 TRAE 生态建设、共同成长的绝佳机会,让我跃跃欲试!感觉自己有机会成为 AI 编程领域的"先行者"!