机器人领域似乎很久没有过这样激动人心的时刻了。我们习惯了机器人在宣传片里流畅优雅,在现实中却磕磕绊绊。我们习惯了它们需要海量数据和漫长调教才能学会一项新技能,换个环境就得从头再来。这些困境,就像一堵无形的墙,阻碍着具身智能真正走进我们的生活。
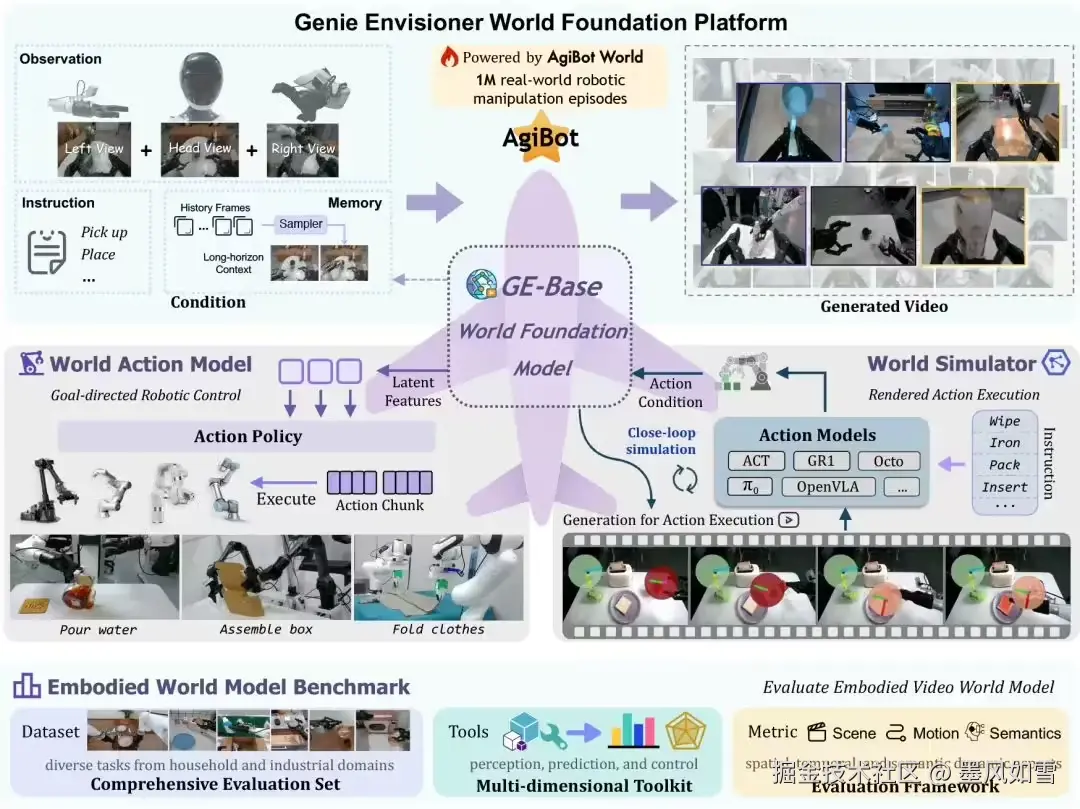
直到智元机器人(Agibot)将 Genie Envisioner (GE) 这个名字,连同它背后的开源平台,一起推到了聚光灯下。这不仅仅是一次技术更新,更像是一场范式革命。GE的核心思想听起来有些科幻:它要让机器人先"想象"出任务完成的画面,再动手去做。
从"听指令干活"到"脑内预演"
过去,机器人学习任务更像一个翻译工作。工程师告诉它"拿起杯子",模型(比如主流的VLA模型)把这句话翻译成一系列动作代码。这个过程问题很多,语言是抽象的,一杯水是满是半?杯子是玻璃还是纸质?这些"言外之意"在翻译过程中极易丢失,导致机器人动作僵硬,失误频频。
Genie Envisioner彻底绕开了这条老路。它构建了一个统一世界模型,其核心是一个强大的视频生成器。你可以把它理解成一个为机器人打造的"梦境引擎"。
这个引擎由三个协同工作的"器官"组成:
-
世界基础模型 (GE-Base):这是机器人的"想象力源泉"。它看过超过3000小时的真实机器人操作视频,学习了物理世界的规律。当你下达指令,它不是去翻译文字,而是在"脑海"中直接生成一段未来即将发生的、关于任务如何完成的视频。比如"叠好纸盒",GE-Base会"脑补"出纸板被一步步折叠、压平、最终成型的完整动态画面。
-
世界行动模型 (GE-Act):这是机器人的"神经中枢"。它极其轻巧,却能精准地将GE-Base"想象"出的视觉画面,实时翻译成机械臂需要执行的每一步动作指令。这个过程快得惊人,在200毫秒内就能生成54步的动作序列,完全满足了真实世界的控制需求。
-
世界模拟器 (GE-Sim):这是机器人的"内在沙盘"。在真正行动之前,机器人可以在这个虚拟的神经物理引擎里,进行数千次低成本的"思想实验",验证哪种动作序列能最完美地复现它想象中的画面,从而选出最优解。
这套"看→想→动"的闭环系统,让机器人第一次拥有了类似人类的直觉与规划能力。它不再是被动执行指令的傀儡,而是一个能够主动思考、预判和验证的智能体。

惊人的天赋:举一反三与化繁为简
这套新范式带来的效果是颠覆性的。
最令人惊叹的是它的泛化能力。传统的机器人模型换一个新的平台,往往需要数周甚至数月的重新训练。而GE-Act,仅需要大约1小时的新平台遥操作数据,就能在新机器人上完美复现复杂任务。这几乎抹平了不同机器人本体之间的鸿沟,让算法的迁移成本降到了前所未有的低点。
更重要的是,它真正攻克了长时序任务 的难关。对于"折叠纸盒"这种需要十几个连贯步骤的复杂任务,GE的成功率高达76%,而行业内其他顶尖模型,要么成功率不到50%,要么干脆就是0。因为它能在视觉空间里连贯地"想象"整个过程,避免了误差的层层累积。

开源,点燃整个行业的火把
智元机器人做出了一个更具魄力的决定:将GE平台的全部代码、预训练模型和评测工具彻底开源。
这意味着,无论是高校实验室的研究者,还是初创公司的工程师,都可以站在这个巨人的肩膀上,去构建自己的机器人应用。这无疑会极大地加速整个具身智能生态的繁荣,让那个"机器人在家做饭、在工厂自主装配"的未来,加速到来。
可以说,Genie Envisioner的诞生,是具身智能领域的"GPT-3时刻"。它不仅展示了一种更优雅、更高效的技术路径,更用开源的方式,邀请全世界的开发者共同书写机器人的下一个时代。
那个只会笨拙模仿的机器人时代,或许真的要结束了。一个拥有"想象力"的机器人新纪元,正拉开序幕。
如果你也对最新的AI信息感兴趣或者有疑问 都可以加入我的大家庭 第一时间分享最新AI资讯、工具、教程、文档 欢迎你的加入!!!😉😉😉
公众号:墨风如雪小站