掌握Map集合相当于同时掌握了Set集合。
Set集合底层实现--委派成员变量Map集合完成具体实现。
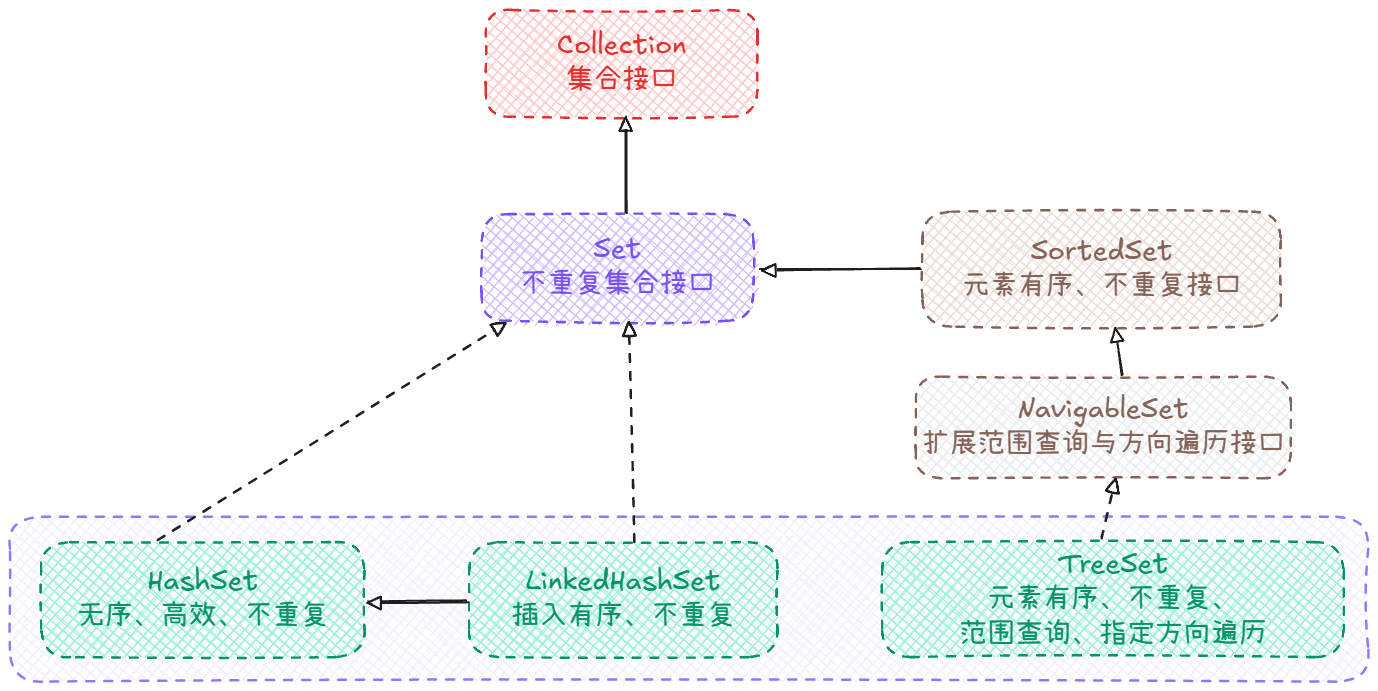
Set 集合概览
在 Java 集合框架中,Set 表示不包含重复元素的集合类型。
本文讲解三种常用实现:HashSet、LinkedHashSet 和 TreeSet。
1. Set 接口概述
定义 :java.util.Set<E> 继承自 Collection<E>,用于存储无重复元素的集合。
核心特性:元素唯一性。
常见操作:
add(E e)、remove(Object o)、contains(Object o)- 批量操作:
addAll、removeAll、retainAll - 遍历:增强 for、迭代器
2. 基本实现对比
Set类的这三种实现类的实现逻辑,都是通过委派给内部的Map集合对象 来实现具体处理逻辑,完全屏蔽了调用者对Set集合细节的感知。
类似于可重入锁 ,在 ReentrantLock(或 ReentrantReadWriteLock)中,所有对外的方法(lock()、unlock()......)都是简单地委派给内部的 Sync sync(FairSync 或 NonfairSync)来执行 ,完全屏蔽了调用者对 AQS 细节的感知。
HashSet、LinkedHashSet 和 TreeSet三者对比:
| Set类 | 底层结构 | 特性 | 允许 null | 迭代顺序 |
|---|---|---|---|---|
| HashSet | HashMap<E,Object> | 无序、高效 | 是 | 不确定(受 hash 冲突和容量影响) |
| LinkedHashSet | LinkedHashMap<E,Object> | 插入顺序(无访问顺序) | 是 | 插入顺序(无访问顺序) |
| TreeSet | TreeMap<E,Object> | 有序、排序、范围操作 | 否 | 元素排序顺序 |
2 HashSet 集合
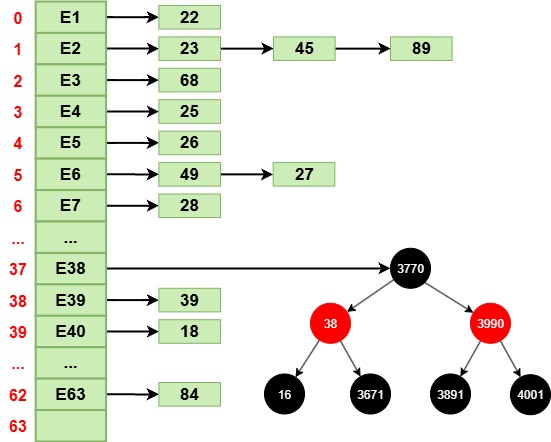
2.1. 底层数据结构
底层维护一个 HashMap<E, Object>,实际的value值为静态常量 PRESENT,这样Set集合的所有key指向同一个静态常量PRESENT,避免浪费内存空间。
java
private transient HashMap<E,Object> map;
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}HashSet委派成员变量HashMap 来完成底层实现,在整个类的实现中,只需要关注HashMap的key如何处理即可。
比如,Set集合迭代的过程只需要迭代key即可
java
public Iterator<E> iterator() {
return map.keySet().iterator();
}2.2. 应用与注意
适用场景:快速去重、大量元素的快速查找。
注意点 :集合元素的类需要实现hashCode和equals方法,这跟HashMap的key对象特性一致。
学习HashSet前,可以先掌握HashMap。往期文章可视化的讲过了HashMap集合。
3 LinkedHashSet 详解
LinkedHashSet 继承于HashSet,LinkedHashSet所有构造方法都是使用父类来完成对象创建,源码如下:
java
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
...
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
...
}
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable{
...
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
...
}细心的会发现,构成方法中有个参数boolean dummy,是没有被使用到的!!这很重要!!
然而LinkedHashSet 所有构造方法都是调用HashSet(int initialCapacity, float loadFactor, boolean dummy) 来完成对象实例化的,也就是说LinkedHashSet无法通过构造方法使用LinkedHashMap集合的访问顺序 ,也无法直接实现LRU缓存,因为默认accessOrder始终为false,并且也无法指定accessOrder为true。
java
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}但是LinkedHashSet构造方法默认都给了个true,有点迷惑人的设计和默认值 。尽管他在方法上做了说明:@param dummy被忽略(区分这一点)。
为什么不需要访问顺序特性?
Set集合并不需要这种"最近用过"的跟踪------它们只需要保证不重复,或者按插入顺序迭代就够了。并且Set集合没有提供get方法访问元素,不存咋访问这个概念,也就不需要访问顺序这个特性。Set集合不像List集合那样可以根据下标进行随机访问方法,只能通过遍历的方式进行节点访问。
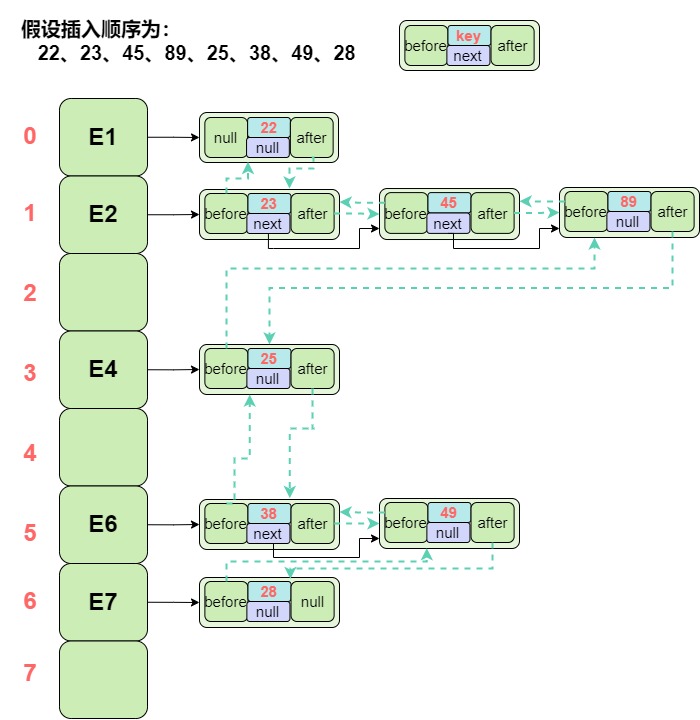
3.1. 底层数据结构
LinkedHashSet本质基于 LinkedHashMap,内部每个节点有 before/after 双向链指针,维护插入顺序。
LinkedHashSet 的构造器只接受初始容量和加载因子 ,它内部使用的是默认的插入顺序的 LinkedHashMap,并不提供切换到访问顺序 的选项,构造时不可指定 accessOrder 为 true。
每个节点的内部结构为:
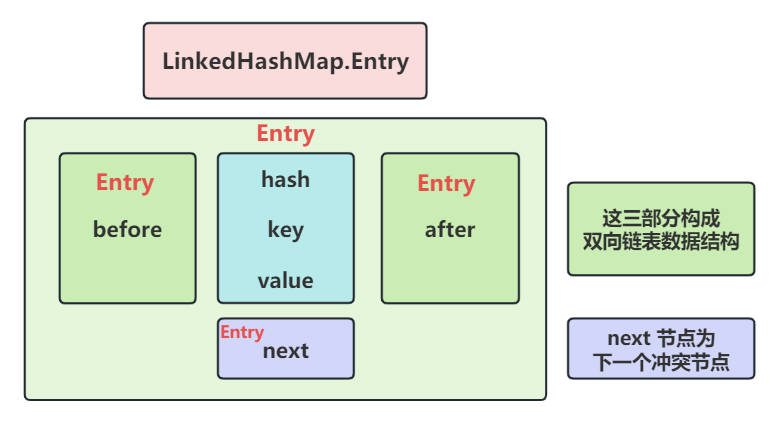
3.2. 如何实现LinkedHashSet集合的LRU 缓存?
构造时不可指定 accessOrder 为 true,默认只有插入顺序。那只能"曲线救国",使用Collections.newSetFromMap来创建Set集合。
如果需要"按访问顺序"并自动淘汰最老元素(LRU),可以基于 LinkedHashMap+Collections.newSetFromMap(...) 来实现一个带缓存特性的 Set。
以下是通过LinkedHashMap集合实现的自定义LRU 缓存:
java
// 按访问顺序
Set<String> lruSet = Collections.newSetFromMap(
new LinkedHashMap<String, Boolean>(16, 0.75f, true) { // accessOrder = true
@Override
protected boolean removeEldestEntry(Map.Entry<String, Boolean> eldest) {
return size() > 4;
}
}
);
lruSet.add("A");
lruSet.add("B");
lruSet.add("C");
lruSet.add("D");
lruSet.add("E"); // A 会被移除
System.out.println(lruSet); // 执行结果:[B, C, D, E]3.3. 场景与性能
适用场景:需要既去重,又按插入顺序遍历
性能开销 :比 HashSet 多维护链表指针,插入/删除略慢
注意点:
- 集合元素的类需要实现
hashCode和equals方法,这跟LinkedHashMap的key对象特性一致; - 构造时不可指定
accessOrder为true,默认只有插入顺序。
4 TreeSet 详解
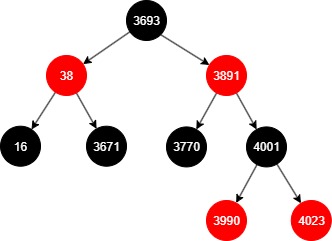
4.1 底层结构与红黑树特性
TreeSet本质基于 TreeMap<E, Object>,红黑树保证插入/删除后的平衡性。
TreeSet的特性与红黑树特性一致,
每个红黑树节点的内部结构为:
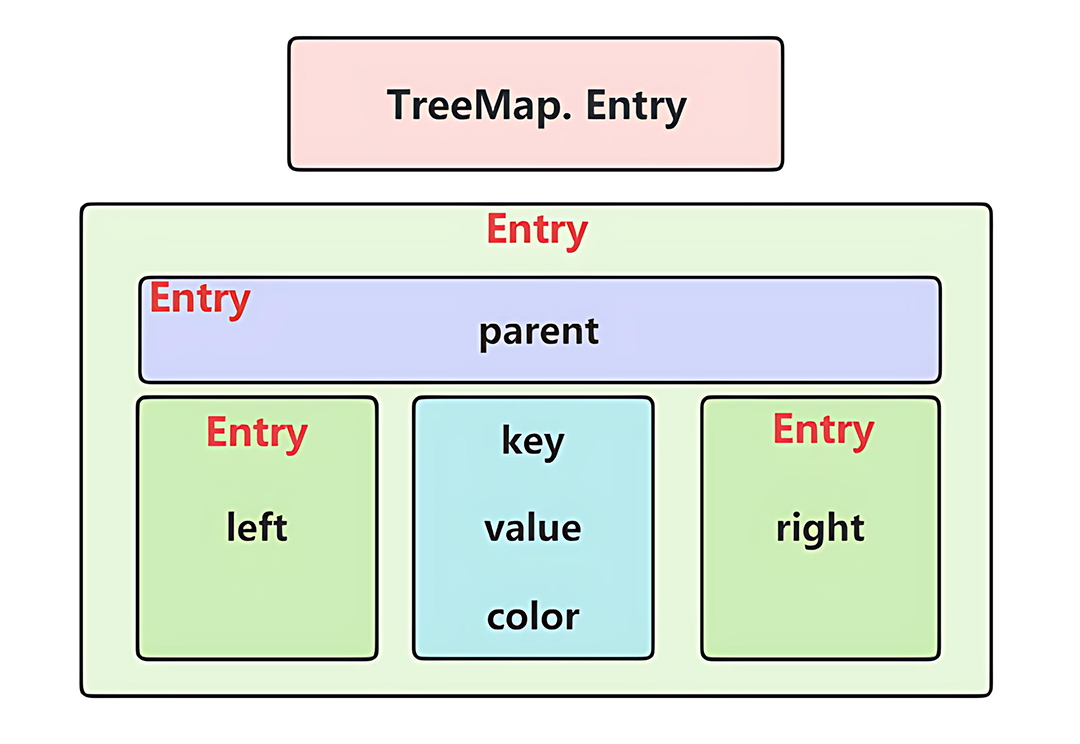
4.2 排序与范围操作示例
java
TreeSet<String> tree = new TreeSet<>(Arrays.asList("C", "A", "B", "D"));
System.out.println(tree);// 自然排序:[A, B, C, D]
TreeSet<String> desc = new TreeSet<>(Comparator.reverseOrder());
desc.addAll(tree);
System.out.println(desc);// 反序:[D, C, B, A]
// 范围视图
SortedSet<String> range = tree.subSet("B", true, "D", false);
System.out.println(range);// 包含 B,不包含 D:结果 [B, C]4.3 场景与注意
适用场景:需要有序集合、区间查询、按顺序访问元素。
注意点:
-
元素类型必须实现
Comparable或通过构造方法提供自定义比较器Comparator。 -
不支持
null,否则抛NullPointerException。
4. 三者详细对比
下面从底层数据结构、迭代顺序、主要操作性能、内存开销、空元素支持、典型场景等维度,对比 HashSet、LinkedHashSet 和 TreeSet 三种常用 Set 实现:
| 特性 | HashSet | LinkedHashSet | TreeSet |
|---|---|---|---|
| 底层结构 | 哈希表(数组 + 链表/红黑树) | 哈希表 + 双向链表 | 红黑树(Self‑balancing BST) |
| 迭代顺序 | 无序 | 插入顺序 | 排序顺序(自然顺序或自定义 Comparator) |
| add / remove / contains | 平均 O(1),最坏 O(n) | 平均 O(1),最坏 O(n) | O(log n) |
| iteration(遍历) | O(n),顺序不确定 | O(n),按照插入顺序 | O(n),按照排序顺序 |
| 内存开销 | 最小(仅哈希桶 + 链表/树节点) | 略高(每个节点多维护前后指针) | 最高(树节点需维护父/左右子指针及颜色信息) |
| null 支持 | 支持一个 null |
支持一个 null |
不支持 null(会抛 NPE) |
| 线程安全 | 非线程安全 | 非线程安全 | 非线程安全 |
| 适用场景 | 需要最快速的无序去重 | 需要去重,并保持元素插入顺序 | 需要去重,并有序访问或范围查询(如子集、headSet、tailSet) |
| 访问顺序(LRU) | 不支持 | 不支持(只能保持插入顺序) | 不支持 |
| 子集/范围操作 | 不提供 | 不提供 | 支持 subSet、headSet、tailSet 等导航方法 |
总结
这三者同属 Set 家族,共享"无重复元素 "、高效去重的核心特性,又各司其职、在"顺序"与"性能"上做出不同取舍。Set集合底层通过委派成员变量Map集合完成具体实现,但特性稍有差异,使用时需要注意。如果没有掌握Map集合的,建议先把Map集合的HashMap,LinkedHashMap和TreeMap都学习一遍,关于这块的知识,之前已经通过可视化的方式分享过,感兴趣的可以前往学习。
往期推荐
| 分类 | 往期文章 |
|---|---|
| Java集合底层原理可视化 | ArrayDeque双端队列--底层原理可视化 "子弹弹夹"装弹和出弹的抽象原理实战:掌握栈的原理与实战 TreeMap集合--底层原理、源码阅读及它在Java集合框架中扮演什么角色? LinkedHashMap集合--原理可视化 HashMap集合--基本操作流程的源码可视化 Java集合--HashMap底层原理可视化,秒懂扩容、链化、树化 Java集合--从本质出发理解HashMap Java集合--LinkedList源码可视化 Java集合源码--ArrayList的可视化操作过程 |
| 设计模式秘籍 (已全部开源) | 掌握设计模式的两个秘籍 往期设计模式文章的:设计模式 |
| 软件设计师 | 软考中级--软件设计师毫无保留的备考分享 通过软考后却领取不到实体证书? 2023年下半年软考考试重磅消息 |
| Java学习路线 和相应资源 | Java全栈学习路线、学习资源和面试题一条龙 |
原创不易,觉得还不错的,三连支持:点赞、分享、推荐↓