文章目录
- [安装 pdfminer.six 作为 Python 包](#安装 pdfminer.six 作为 Python 包)
-
- [使用 pip 安装](#使用 pip 安装)
- [测试 pdfminer.six 安装](#测试 pdfminer.six 安装)
- 使用命令行从PDF中提取文本
- 使用Python从PDF提取文本
- [使用Python从PDF提取文本 - 第二部分](#使用Python从PDF提取文本 - 第二部分)
- 使用Python从PDF中提取元素
- 如何从PDF中提取图片
- [如何使用PDFMiner从PDF提取 AcroForm交互式表单字段](#如何使用PDFMiner从PDF提取 AcroForm交互式表单字段)
- 如何解析目录条目的目标页码
- 如何从PDF中提取字体名称和大小
- 将PDF文件转换为文本
- [命令行 API](#命令行 API)
- [高级功能 API](#高级功能 API)
- 可组合API
-
- [LAParams 参数类](#LAParams 参数类)
- 待办事项:
- 常见问题解答
-
- [为什么叫 pdfminer.six?](#为什么叫 pdfminer.six?)
- [pdfminer.six 与其他 pdfminer 分支有何不同?](#pdfminer.six 与其他 pdfminer 分支有何不同?)
- 为什么文本输出中会出现(cid:x)值?
安装 pdfminer.six 作为 Python 包
https://pdfminersix.readthedocs.io/en/latest/tutorial/install.html
首次使用 pdfminer.six 时,您需要在 Python 环境中安装该包。
本教程要求您的系统已安装可用的 Python 和 pip。如果尚未安装或不清楚如何安装,请参考 Python 安装指南。
使用 pip 安装
在命令行中运行以下命令,将 pdfminer.six 安装为 Python 包:
shell
pip install pdfminer.six测试 pdfminer.six 安装
你可以通过在 Python 中导入 pdfminer.six 来测试其安装情况。
从命令行打开一个交互式 Python 会话并导入 pdfminer.six:
python
>>> import pdfminer
>>> print(pdfminer.__version__)
'<installed version>'现在你可以将 pdfminer.six 作为 Python 包使用。
但 pdfminer.six 还附带了一些实用的命令行工具。要测试这些工具是否正确安装,请在命令行中运行以下命令:
shell
$ pdf2txt.py --version
pdfminer.six v20231228
# pdfminer.six <installed version>使用命令行从PDF中提取文本
https://pdfminersix.readthedocs.io/en/latest/tutorial/commandline.html
pdfminer.six提供了多个可通过命令行使用的工具。
这些命令行工具主要面向偶尔需要从PDF中提取文本的用户。
如果您希望以编程方式使用pdfminer.six,请查看其高级接口或组合式接口。
示例
pdf2txt.py
shell
$ pdf2txt.py example.pdf
all the text from the pdf appears on the command linepdf2txt.py 工具可以从 PDF 文件中提取所有文本内容。
它采用智能的默认布局分析算法,以合理的方式对文本进行排序和分组。
dumppdf.py
shell
$ dumppdf.py -a example.pdf
<pdf><object id="1">
...
</object>
...
</pdf>dumppdf.py 工具可用于提取PDF的内部结构。
该工具主要用于调试目的,但对于任何处理PDF文件的人员都可能很有帮助。
使用Python从PDF提取文本
https://pdfminersix.readthedocs.io/en/latest/tutorial/highlevel.html
高级API可用于完成常见任务。
从PDF提取文本的最简单方法是使用 extract_text 函数:
python
>>> from pdfminer.high_level import extract_text
>>> text = extract_text('samples/simple1.pdf')
>>> print(repr(text))
'Hello \n\nWorld\n\nHello \n\nWorld\n\nH e l l o \n\nW o r l d\n\nH e l l o \n\nW o r l d\n\n\x0c'
>>> print(text)
...
Hello
World
Hello
World
H e l l o
W o r l d
H e l l o
W o r l d要从PDF中读取文本并在命令行打印:
python
>>> from io import StringIO
>>> from pdfminer.high_level import extract_text_to_fp
>>> output_string = StringIO()
>>> with open('samples/simple1.pdf', 'rb') as fin:
... extract_text_to_fp(fin, output_string)
>>> print(output_string.getvalue().strip())
Hello WorldHello WorldHello WorldHello World或者将其转换为HTML并使用布局分析:
python
>>> from io import StringIO
>>> from pdfminer.high_level import extract_text_to_fp
>>> from pdfminer.layout import LAParams
>>> output_string = StringIO()
>>> with open('samples/simple1.pdf', 'rb') as fin:
... extract_text_to_fp(fin, output_string, laparams=LAParams(),
... output_type='html', codec=None)使用Python从PDF提取文本 - 第二部分
https://pdfminersix.readthedocs.io/en/latest/tutorial/composable.html
命令行工具和高级API只是pdfminer.six组件常用组合的快捷方式。
您可以使用这些组件根据自身需求定制pdfminer.six。
例如,要从PDF文件中提取文本并保存到Python变量中:
python
from io import StringIO
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfparser import PDFParser
output_string = StringIO()
with open('samples/simple1.pdf', 'rb') as in_file:
parser = PDFParser(in_file)
doc = PDFDocument(parser)
rsrcmgr = PDFResourceManager()
device = TextConverter(rsrcmgr, output_string, laparams=LAParams())
interpreter = PDFPageInterpreter(rsrcmgr, device)
for page in PDFPage.create_pages(doc):
interpreter.process_page(page)
print(output_string.getvalue())使用Python从PDF中提取元素
https://pdfminersix.readthedocs.io/en/latest/tutorial/extract_pages.html
高级函数可用于完成常见任务。在本例中,我们可以使用 extract_pages 函数:
python
from pdfminer.high_level import extract_pages
for page_layout in extract_pages("test.pdf"):
for element in page_layout:
print(element)每个 element 都会是 LTTextBox、LTFigure、LTLine、LTRect 或 LTImage 类型。
其中部分元素可以进一步迭代,例如遍历 LTTextBox 会得到 LTTextLine,而继续遍历这些行又能获取到 LTChar。具体流程可参考此图:布局分析算法。
假设我们需要提取所有文本,可以这样操作:
python
from pdfminer.high_level import extract_pages
from pdfminer.layout import LTTextContainer
for page_layout in extract_pages("test.pdf"):
for element in page_layout:
if isinstance(element, LTTextContainer):
print(element.get_text())或者,我们可以提取每个单独字符的字体名称或大小:
python
from pdfminer.high_level import extract_pages
from pdfminer.layout import LTTextContainer, LTChar
for page_layout in extract_pages("test.pdf"):
for element in page_layout:
if isinstance(element, LTTextContainer):
for text_line in element:
for character in text_line:
if isinstance(character, LTChar):
print(character.fontname)
print(character.size)如何从PDF中提取图片
https://pdfminersix.readthedocs.io/en/latest/howto/images.html
在开始之前,请确保你已经安装了pdfminer.six。
其次,你需要一个包含图片的PDF文件。如果没有现成的文件,可以下载这份研究论文,里面包含猫狗图片,将其保存为example.pdf:
shell
$ curl https://www.robots.ox.ac.uk/~vgg/publications/2012/parkhi12a/parkhi12a.pdf --output example.pdf然后运行 pdf2txt 命令:
shell
$ pdf2txt.py example.pdf --output-dir cats-and-dogs该命令会从PDF中提取所有图片,并保存到cats-and-dogs目录中。
如何使用PDFMiner从PDF提取 AcroForm交互式表单字段
https://pdfminersix.readthedocs.io/en/latest/howto/acro_forms.html
开始之前,请确保您已安装pdfminer.six。
其次,您需要一个包含 AcroForms 的PDF文件(如带有可填写表单或多选题的PDF文件)。
GitHub仓库的 samples/acroform 目录下提供了一些示例文件。
目前仅支持AcroForm交互式表单,不支持 XFA 表单。
python
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdftypes import resolve1
from pdfminer.psparser import PSLiteral, PSKeyword
from pdfminer.utils import decode_text
data = {}
def decode_value(value):
# decode PSLiteral, PSKeyword
if isinstance(value, (PSLiteral, PSKeyword)):
value = value.name
# decode bytes
if isinstance(value, bytes):
value = decode_text(value)
return value
with open(file_path, 'rb') as fp:
parser = PDFParser(fp)
doc = PDFDocument(parser)
res = resolve1(doc.catalog)
if 'AcroForm' not in res:
raise ValueError("No AcroForm Found")
fields = resolve1(doc.catalog['AcroForm'])['Fields'] # may need further resolving
for f in fields:
field = resolve1(f)
name, values = field.get('T'), field.get('V')
# decode name
name = decode_text(name)
# resolve indirect obj
values = resolve1(values)
# decode value(s)
if isinstance(values, list):
values = [decode_value(v) for v in values]
else:
values = decode_value(values)
data.update({name: values})
print(name, values)这段代码片段将打印所有字段名称和值,并将它们保存在"data"字典中。
工作原理:
- 初始化解析器和PDFDocument对象
python
parser = PDFParser(fp)
doc = PDFDocument(parser)- 获取目录
目录包含对定义文档结构的其他对象的引用,详见 PDF 32000-1:2008 规范第 7.7.2 节:https://opensource.adobe.com/dc-acrobat-sdk-docs/pdflsdk/index.html#pdf-reference
res = resolve1(doc.catalog)- 检查目录是否包含 AcroForm 键,若不存在则抛出 ValueError
(若目录中缺少此键,则 PDF 不包含 AcroForm 类型的交互式表单,详见 PDF 32000-1:2008 规范第 12.7.2 节)
python
if 'AcroForm' not in res:
raise ValueError("No AcroForm Found")- 解析目录中的条目以获取字段列表
python
fields = resolve1(doc.catalog['AcroForm'])['Fields']
for f in fields:
field = resolve1(f) 获取字段名称和字段值
python
name, values = field.get('T'), field.get('V') - 解码字段名称。
python
name = decode_text(name)- 解析间接字段值对象
python
values = resolve1(value)- 根据需要调用值解码方法
(单个字段可以包含多个值,例如组合框可以同时保存多个值)
python
if isinstance(values, list):
values = [decode_value(v) for v in values]
else:
values = decode_value(values)(decode_value方法负责解码字段值,返回字符串)
- 解码
PSLiteral和PSKeyword字段值
python
if isinstance(value, (PSLiteral, PSKeyword)):
value = value.name- 解码字节字段值
python
if isinstance(value, bytes):
value = utils.decode_text(value)如何解析目录条目的目标页码
https://pdfminersix.readthedocs.io/en/latest/howto/toc_target_page.html
pdfminer.six 允许通过 PDFDocument.get_outlines() 方法访问文档的目录(在PDF内部结构中称为"Outlines")。
一个最小示例如下:
python
from pathlib import Path
from pdfminer.pdfparser import PDFParser, PDFSyntaxError
from pdfminer.pdfdocument import PDFDocument, PDFNoOutlines
file_name = Path("...")
with open(file_name, "rb") as fp:
try:
parser = PDFParser(fp)
document = PDFDocument(parser)
outlines = document.get_outlines()
for (level, title, dest, a, se) in outlines:
... # do something
except PDFNoOutlines:
print("No outlines found.")
except PDFSyntaxError:
print("Corrupted PDF or non-PDF file.")
finally:
parser.close()但每个大纲条目中的不同字段分别代表什么含义呢?要解答这个问题,我们可以参考PDF参考手册中的12.3.3 文档大纲章节:
-
Level (
int):顾名思义,表示条目所处的层级。顶层条目层级为1,其嵌套子条目(即子节点)层级为2,以此类推。 -
Title (
str):这个字段的含义一目了然,用于存储条目名称。例如:"1. 引言"。 -
Dest (
Union[list, bytes], 可选):从这里开始变得有趣。首先需注意:若存在Dest 条目,则不应存在A 条目。两者都用于指定条目指向的目标对象(可能是页面或其他对象)。目标可以通过多种方式定义。为避免曲解PDF参考手册的原意,建议读者查阅12.3.2 目标章节获取详细信息。 -
A (
pdfminer.pdftypes.PDFObjRef, 可选):作为目标的替代方案,条目指向的对象也可以通过动作(action)来指定。
动作的定义可能较为复杂,因此建议读者参考手册中的12.6 动作章节。
- SE (
pdfminer.pdftypes.PDFObjRef, 可选):该字段包含条目指向的结构元素。更多关于结构元素的信息可查阅14.7.2 结构层级 章节。
值得注意的是,大多数PDF文档不会包含此字段,而是使用Dest 或A 字段;即使包含,可能仍会保留目标(Dest)以确保与1.3版本之前的PDF兼容。
遗憾的是,pdfminer.six并未公开每个条目指向的页码。
不过,只要理解上述字段的含义,我们完全可以自己实现一个目录条目页码解析器:
python
from enum import Enum, auto
from pathlib import Path
from typing import Any, Optional
from pdfminer.pdfdocument import PDFDocument, PDFNoOutlines
from pdfminer.pdfpage import PDFPage, LITERAL_PAGE
from pdfminer.pdfparser import PDFParser, PDFSyntaxError
from pdfminer.pdftypes import PDFObjRef
class PDFRefType(Enum):
"""PDF reference type."""
PDF_OBJ_REF = auto()
DICTIONARY = auto()
LIST = auto()
NAMED_REF = auto()
UNK = auto() # fallback
class RefPageNumberResolver:
"""PDF Reference to page number resolver.
.. note::
Remote Go-To Actions (see 12.6.4.3 in
`https://www.adobe.com/go/pdfreference/`__)
are out of the scope of this resolver.
Attributes:
document (:obj:`pdfminer.pdfdocument.PDFDocument`):
The document that contains the references.
objid_to_pagenum (:obj:`dict[int, int]`):
Mapping from an object id to the number of the page that contains
that object.
"""
def __init__(self, document: PDFDocument):
self.document = document
# obj_id -> page_number
self.objid_to_pagenum: dict[int, int] = {
page.pageid: page_num
for page_num, page in enumerate(PDFPage.create_pages(document), 1)
}
@classmethod
def get_ref_type(cls, ref: Any) -> PDFRefType:
"""Get the type of a PDF reference."""
if isinstance(ref, PDFObjRef):
return PDFRefType.PDF_OBJ_REF
elif isinstance(ref, dict) and "D" in ref:
return PDFRefType.DICTIONARY
elif isinstance(ref, list) and any(isinstance(e, PDFObjRef) for e in ref):
return PDFRefType.LIST
elif isinstance(ref, bytes):
return PDFRefType.NAMED_REF
else:
return PDFRefType.UNK
@classmethod
def is_ref_page(cls, ref: Any) -> bool:
"""Check whether a reference is of type '/Page'.
Args:
ref (:obj:`Any`):
The PDF reference.
Returns:
:obj:`bool`: :obj:`True` if the reference references
a page, :obj:`False` otherwise.
"""
return isinstance(ref, dict) and "Type" in ref and ref["Type"] is LITERAL_PAGE
def resolve(self, ref: Any) -> Optional[int]:
"""Resolve a PDF reference to a page number recursively.
Args:
ref (:obj:`Any`):
The PDF reference.
Returns:
:obj:`Optional[int]`: The page number or :obj:`None`
if the reference could not be resolved (e.g., remote Go-To
Actions or malformed references).
"""
ref_type = self.get_ref_type(ref)
if ref_type is PDFRefType.PDF_OBJ_REF and self.is_ref_page(ref.resolve()):
return self.objid_to_pagenum.get(ref.objid)
elif ref_type is PDFRefType.PDF_OBJ_REF:
return self.resolve(ref.resolve())
if ref_type is PDFRefType.DICTIONARY:
return self.resolve(ref["D"])
if ref_type is PDFRefType.LIST:
# Get the PDFObjRef in the list (usually first element).
return self.resolve(next(filter(lambda e: isinstance(e, PDFObjRef), ref)))
if ref_type is PDFRefType.NAMED_REF:
return self.resolve(self.document.get_dest(ref))
return None # PDFRefType.UNK类 PDFRefType 只是一个辅助工具,用于分类我们正在处理的引用类型。由于一个引用可以指向另一个引用,在某些情况下,我们需要递归调用
RefPageNumberResolver.resolve(),直到最终到达一个页面对象。
然后,我们可以通过访问字典 RefPageNumberResolver.objid_to_pagenum 来获取页码,该字典将页面对象 ID 映射到页码。
使用这个页码解析器,例如,我们可以用以下代码以人类可读的格式打印文档的目录:
python
def print_outlines(file: str) -> dict[int, int]:
"""Pretty print the outlines (ToC) of a PDF document."""
with open(file, "rb") as fp:
try:
parser = PDFParser(fp)
document = PDFDocument(parser)
ref_pagenum_resolver = RefPageNumberResolver(document)
outlines = list(document.get_outlines())
if not outlines:
print("No outlines found.")
for (level, title, dest, a, se) in outlines:
if dest:
page_num = ref_pagenum_resolver.resolve(dest)
elif a:
page_num = ref_pagenum_resolver.resolve(a)
elif se:
page_num = ref_pagenum_resolver.resolve(se)
else:
page_num = None
# Calculate leading spaces and filling dots for formatting.
leading_spaces = (level-1) * 4
fill_dots = 80 - len(title) - leading_spaces
print(
f"{' ' * leading_spaces}"
f"{title}",
f"{'.' * fill_dots}",
f"{page_num:>3}"
)
except PDFNoOutlines:
print("No outlines found.")
except PDFSyntaxError:
print("Corrupted PDF or non-PDF file.")
finally:
try:
parser.close()
except NameError:
pass # nothing to do
def main():
file_name = Path("...")
print_outlines(file_name)
if __name__ == "__main__":
main()如何从PDF中提取字体名称和大小
https://pdfminersix.readthedocs.io/en/latest/howto/character_properties.html
在开始之前,请确保您已安装pdfminer.six。
以下代码示例展示了 如何为每个字符提取字体名称和大小。该示例使用了simple1.pdf文件。
python
from pathlib import Path
from typing import Iterable, Any
from pdfminer.high_level import extract_pages
def show_ltitem_hierarchy(o: Any, depth=0):
"""Show location and text of LTItem and all its descendants"""
if depth == 0:
print('element font stroking color text')
print('------------------------------ --------------------- -------------- ----------')
print(
f'{get_indented_name(o, depth):<30.30s} '
f'{get_optional_fontinfo(o):<20.20s} '
f'{get_optional_color(o):<17.17s}'
f'{get_optional_text(o)}'
)
if isinstance(o, Iterable):
for i in o:
show_ltitem_hierarchy(i, depth=depth + 1)
def get_indented_name(o: Any, depth: int) -> str:
"""Indented name of class"""
return ' ' * depth + o.__class__.__name__
def get_optional_fontinfo(o: Any) -> str:
"""Font info of LTChar if available, otherwise empty string"""
if hasattr(o, 'fontname') and hasattr(o, 'size'):
return f'{o.fontname} {round(o.size)}pt'
return ''
def get_optional_color(o: Any) -> str:
"""Font info of LTChar if available, otherwise empty string"""
if hasattr(o, 'graphicstate'):
return f'{o.graphicstate.scolor}'
return ''
def get_optional_text(o: Any) -> str:
"""Text of LTItem if available, otherwise empty string"""
if hasattr(o, 'get_text'):
return o.get_text().strip()
return ''
path = Path('samples/simple1.pdf').expanduser()
pages = extract_pages(path)
show_ltitem_hierarchy(pages)输出结果如下所示。请注意,它展示了布局元素的层级结构。布局算法将字符分组为行,再将行分组为框。这些框会出现在页面上。
页面、框和行不包含字体信息,因为每个字符的字体可能不同。本例中的描边颜色始终为None,但如果PDF确实指定了颜色,此处将显示实际颜色。
shell
element font stroking color text
------------------------------ --------------------- -------------- ----------
generator
LTPage
LTTextBoxHorizontal Hello
LTTextLineHorizontal Hello
LTChar Helvetica 24pt None H
LTChar Helvetica 24pt None e
LTChar Helvetica 24pt None l
LTChar Helvetica 24pt None l
LTChar Helvetica 24pt None o
LTChar Helvetica 24pt None
LTAnno
LTTextBoxHorizontal World
LTTextLineHorizontal World
LTChar Helvetica 24pt None W
LTChar Helvetica 24pt None o
LTChar Helvetica 24pt None r
LTChar Helvetica 24pt None l
LTChar Helvetica 24pt None d
LTAnno
LTTextBoxHorizontal Hello
LTTextLineHorizontal Hello
LTChar Helvetica 24pt None H
LTChar Helvetica 24pt None e
LTChar Helvetica 24pt None l
LTChar Helvetica 24pt None l
LTChar Helvetica 24pt None o
LTChar Helvetica 24pt None
LTAnno
LTTextBoxHorizontal World
LTTextLineHorizontal World
LTChar Helvetica 24pt None W
LTChar Helvetica 24pt None o
LTChar Helvetica 24pt None r
LTChar Helvetica 24pt None l
LTChar Helvetica 24pt None d
LTAnno
LTTextBoxHorizontal H e l l o
LTTextLineHorizontal H e l l o
LTChar Helvetica 24pt None H
LTAnno
LTChar Helvetica 24pt None e
LTAnno
LTChar Helvetica 24pt None l
LTAnno
LTChar Helvetica 24pt None l
LTAnno
LTChar Helvetica 24pt None o
LTAnno
LTChar Helvetica 24pt None
LTAnno
LTTextBoxHorizontal W o r l d
LTTextLineHorizontal W o r l d
LTChar Helvetica 24pt None W
LTAnno
LTChar Helvetica 24pt None o
LTAnno
LTChar Helvetica 24pt None r
LTAnno
LTChar Helvetica 24pt None l
LTAnno
LTChar Helvetica 24pt None d
LTAnno
LTTextBoxHorizontal H e l l o
LTTextLineHorizontal H e l l o
LTChar Helvetica 24pt None H
LTAnno
LTChar Helvetica 24pt None e
LTAnno
LTChar Helvetica 24pt None l
LTAnno
LTChar Helvetica 24pt None l
LTAnno
LTChar Helvetica 24pt None o
LTAnno
LTChar Helvetica 24pt None
LTAnno
LTTextBoxHorizontal W o r l d
LTTextLineHorizontal W o r l d
LTChar Helvetica 24pt None W
LTAnno
LTChar Helvetica 24pt None o
LTAnno
LTChar Helvetica 24pt None r
LTAnno
LTChar Helvetica 24pt None l
LTAnno
LTChar Helvetica 24pt None d
LTAnno将PDF文件转换为文本
https://pdfminersix.readthedocs.io/en/latest/topic/converting_pdf_to_text.html
大多数PDF文件看起来包含结构良好的文本。但实际上,PDF文件中并不存在类似段落、句子甚至单词的结构。就文本而言,PDF文件仅识别字符及其位置信息。
这使得从PDF文件中提取有意义的文本片段变得困难。构成段落的字符与构成表格、页脚或图表描述的字符并无区别。
与.txt文件或Word文档等其他格式不同,PDF格式并不包含连续的文本流。
PDF文档由一系列对象组成,这些对象共同描述一个或多个页面的外观,可能还包含额外的交互元素和更高层级的应用数据。
PDF文件包含构成PDF文档的对象及相关结构信息,所有内容都以单一自包含的字节序列形式呈现。\[1](#id2)
布局分析算法
PDFMiner 通过基于字符位置的启发式方法,尝试重建部分文档结构。这种方法对句子和段落特别有效,因为相邻字符可以组成有意义的组合。
布局分析包含三个主要阶段:首先将字符聚合成词和行,然后将行组合成文本框,最后对文本框进行层级分组。
以下章节将详细讨论这些阶段。布局分析的最终输出结果是 PDF 页面上布局对象的有序层级结构。
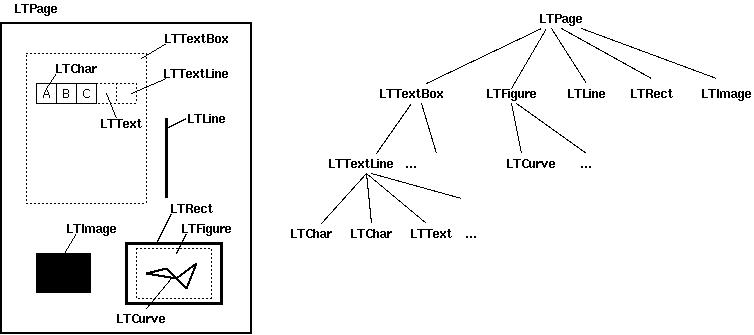
布局分析的输出结果是布局对象的层级结构。
布局分析的结果很大程度上取决于几个关键参数。这些参数都包含在 LAParams 类中。
将字符分组为单词和行
从字符到文本的第一步是将字符以有意义的方式分组。每个字符都有其左下角和右上角的x、y坐标,即边界框。Pdfminer.six利用这些边界框来判断哪些字符属于同一组。
在水平和垂直方向上都较为接近的字符会被归为同一行。判断"接近"的标准由char_margin(图中标记为M)和line_overlap(图中未显示)参数决定。
两个字符边界框之间的水平距离 应小于char_margin,而垂直方向上的重叠部分应大于line_overlap。
| → | ← M | |||
|---|---|---|---|---|
Q u i |
c k |
b r o w n |
||
| → | ← W |
char_margin和line_overlap的值是相对于字符边界框尺寸的。char_margin基于两个边界框中最大宽度的比例,line_overlap则基于两个边界框中最小高度的比例。
由于PDF格式本身没有空格字符的概念,因此需要在字符之间插入空格。
当字符间距超过word_margin(图中标记为W)时就会插入空格。
word_margin的取值基于新字符的最大宽度或高度。较小的word_margin会产生更短的单词。注意word_margin必须小于char_margin,否则所有字符都将紧密相连而不会插入空格。
这个阶段的处理结果是生成行列表。每行包含一个字符列表,这些字符要么是来自PDF文件的原始LTChar字符,要么是表示单词间空格或行尾换行的插入型LTAnno字符。
将行分组为文本框
第二步是将行以有意义的方式进行分组。每行都有一个由其所含字符的边界框决定的边界框。与字符分组类似,pdfminer.six 利用这些边界框来对行进行分组。
水平重叠且垂直距离接近的行会被归为一组。判断行间垂直距离是否足够接近的标准由 line_margin 参数决定。该边距值相对于边界框的高度进行设定。
当两行边界框的顶部(如图中 L1 所示)与底部(如图中 L2 所示)之间的间隙小于绝对行边距(即 line_margin 乘以边界框高度)时,即认为这些行是接近的。
| ↓ | |||
|---|---|---|---|
Q u i c k b r o w n |
↓ | ||
| L1 | |||
f o x |
↑ | L2 | |
| ↑ |
此阶段的处理结果是一个文本框列表。每个文本框由多行文本组成。
层次化分组文本框
最后一步是将文本框以有意义的方式进行分组。该步骤会反复合并彼此最接近的两个文本框。
边界框之间的接近度通过两者之间的区域面积计算(图中蓝色区域)。换句话说,它是包围两行文本的边界框面积减去各行独立边界框面积后的差值。
Q u i c k b r o w n f o x |
|||
|---|---|---|---|
j u m p s ... |
处理旋转字符
上述算法假设所有字符具有相同的方向。然而在PDF中可能存在任何书写方向。为了适应这种情况,pdfminer.six 提供了通过 detect_vertical 参数来检测垂直书写。启用该参数后,所有分组步骤将按照PDF被旋转90度(或270度)的情况进行处理。
参考文献
[1](#1) Adobe System Inc. (2007). Pdf参考:Adobe便携式文档格式,版本1.7。
命令行 API
https://pdfminersix.readthedocs.io/en/latest/reference/commandline.html
pdf2txt.py
一个命令行工具,用于从PDF中提取文本和图像,并将其输出为纯文本、HTML、XML或标签格式。
shell
usage: python tools/pdf2txt.py [-h] [--version] [--debug] [--disable-caching]
[--page-numbers PAGE_NUMBERS [PAGE_NUMBERS ...]]
[--pagenos PAGENOS] [--maxpages MAXPAGES]
[--password PASSWORD] [--rotation ROTATION]
[--no-laparams] [--detect-vertical]
[--line-overlap LINE_OVERLAP]
[--char-margin CHAR_MARGIN]
[--word-margin WORD_MARGIN]
[--line-margin LINE_MARGIN]
[--boxes-flow BOXES_FLOW] [--all-texts]
[--outfile OUTFILE] [--output_type OUTPUT_TYPE]
[--codec CODEC] [--output-dir OUTPUT_DIR]
[--layoutmode LAYOUTMODE] [--scale SCALE]
[--strip-control]
files [files ...]位置参数
files
一个或多个PDF文件的路径。
命名参数
--version, -v
显示程序版本号并退出
--debug, -d
使用调试日志级别
默认值:False
--disable-caching, -C
是否禁用缓存或资源(例如字体)
默认值:False
解析器
用于PDF解析过程中
--page-numbers
指定要解析的页码列表(以空格分隔)
--pagenos, -p
指定要解析的页码列表(以逗号分隔)。为兼容旧版应用程序保留,推荐使用--page-numbers参数以获得更符合习惯的输入方式。
--maxpages, -m
设置最大解析页数
默认值:0
--password, -P
用于解密PDF文件的密码
默认值:''
--rotation, -R
在其他处理前旋转PDF的度数
默认值:0
布局分析
用于布局分析阶段。
--no-laparams, -n
是否忽略布局分析参数。
默认值:False
--detect-vertical, -V
布局分析时是否考虑垂直文本。
默认值:False
--line-overlap
若两个字符的重叠区域超过此阈值,则视为同一行。重叠比例以两者最小高度为基准计算。
默认值:0.5
--char-margin, -M
若两个字符间距小于此边距,则视为同一行内容。边距值以字符宽度为基准计算。
默认值:2.0
--word-margin, -W
同一行中若两个字符间距超过此边距,则视为独立单词(将自动添加间隔符以提高可读性)。边距值以字符宽度为基准计算。
默认值:0.1
--line-margin, -L
若两行间距小于此边距,则视为同一段落。边距值以行高为基准计算。
默认值:0.5
--boxes-flow, -F
控制文本框排序时水平/垂直位置的权重比例。取值范围为-1.0(仅水平位置生效)至+1.0(仅垂直位置生效)。也可设为disabled以禁用高级布局分析,此时仅按文本框左下角坐标排序。
默认值:0.5
--all-texts, -A
是否对图形中的文本执行布局分析。
默认值:False
输出选项
用于控制输出生成过程。
--outfile, -o
指定输出文件的路径。使用 "-"(默认值)表示输出到标准输出(stdout)。
默认值:'-'
--output_type, -t
指定输出格式类型,可选值:{text, html, xml, tag}。
默认值:'text'
--codec, -c
设置输出文件的文本编码格式。
默认值:'utf-8'
--output-dir, -O
指定提取图像的输出目录。若未指定,则不会提取图像。
--layoutmode, -Y
设置生成HTML时的布局模式,可选值:
- normal:每行在HTML中独立定位
- exact:每个字符在HTML中独立定位
- loose:与normal效果相同,但会在每行文本后添加额外换行符
仅当output_type为html时生效。
默认值:'normal'
--scale, -s
设置生成HTML文件时的缩放比例。仅当output_type为html时生效。
默认值:1.0
--strip-control, -S
从文本中移除控制语句。仅当output_type为xml时生效。
默认值:False
dumppdf.py
以XML格式提取PDF结构
shell
usage: python tools/dumppdf.py [-h] [--version] [--debug] [--extract-toc |
--extract-embedded EXTRACT_EMBEDDED]
[--page-numbers PAGE_NUMBERS [PAGE_NUMBERS ...]]
[--pagenos PAGENOS] [--objects OBJECTS] [--all]
[--show-fallback-xref] [--password PASSWORD]
[--outfile OUTFILE] [--raw-stream |
--binary-stream | --text-stream]
files [files ...]位置参数
files
一个或多个PDF文件路径。
命名参数
--version, -v
显示程序版本号并退出
--debug, -d
使用调试日志级别
默认值:False
--extract-toc, -T
提取大纲结构
默认值:False
--extract-embedded, -E
提取嵌入文件
解析器
用于PDF解析过程中
--page-numbers
指定要解析的页码列表(以空格分隔)
--pagenos, -p
指定要解析的页码列表(以逗号分隔)。为兼容旧版应用程序保留,推荐使用更符合惯例的--page-numbers参数
--objects, -i
指定要提取的对象编号列表(逗号分隔)
--all, -a
是否提取所有对象的结构
默认值:False
--show-fallback-xref
额外显示备用交叉引用表。当PDF文件缺少有效交叉引用表时使用。若启用--extract-toc或--extract-embedded参数时此设置将被忽略
默认值:False
--password, -P
用于解密PDF文件的密码
默认值:''
输出
用于控制输出生成阶段的行为。
--outfile, -o
指定输出文件的路径。使用"-"(默认值)表示输出到标准输出(stdout)。
默认值:'-'
--raw-stream, -r
以原始格式写入流对象(不进行编码处理)
默认值:False
--binary-stream, -b
以二进制编码格式写入流对象
默认值:False
--text-stream, -t
以纯文本格式写入流对象
默认值:False
高级功能 API
https://pdfminersix.readthedocs.io/en/latest/reference/highlevel.html
extract_text
python
pdfminer.high_level.extract_text(pdf_file: PurePath | str | IOBase, password: str = '', page_numbers: Container[int] | None = None, maxpages: int = 0, caching: bool = True, codec: str = 'utf-8', laparams: LAParams | None = None) → str解析并返回PDF文件中包含的文本内容。
参数说明:
- pdf_file - 可以是PDF文件的路径,或是支持文件操作的对象。
- password - 用于加密PDF的解密密码(如有)。
- page_numbers - 需要提取的页面编号列表(从0开始计数)。
- maxpages - 最大解析页数限制。
- caching - 是否启用资源缓存。
- codec - 文本解码使用的编码格式。
- laparams -
pdfminer.layout模块中的LAParams对象。若未指定,将采用默认设置(通常效果良好)。
返回值:包含所有提取文本的字符串。
extract_text_to_fp
python
pdfminer.high_level.extract_text_to_fp(
inf: BinaryIO, outfp: TextIO | BinaryIO,
output_type: str = 'text', codec: str = 'utf-8',
laparams: LAParams | None = None, maxpages: int = 0,
page_numbers: Container[int] | None = None,
password: str = '', scale: float = 1.0,
rotation: int = 0, layoutmode: str = 'normal',
output_dir: str | None = None, strip_control: bool = False,
debug: bool = False, disable_caching: bool = False, **kwargs: Any) → None从输入文件对象解析文本并写入输出文件对象。
虽然接受大量可选参数,但默认值基本合理。
特别注意 laparams 参数:传入空 LAParams 对象与传入None效果不同!
参数说明:
- inf - 用于读取PDF结构的文件对象,例如通过内置open()函数创建的文件句柄或BytesIO对象
- outfp - 用于写入文本内容的文件对象
- output_type - 支持 'text'/'xml'/'html'/'hocr'/'tag',但仅'text'能完全正常工作
- codec - 文本解码编码格式
- laparams - pdfminer.layout.LAParams对象,默认为None但可能导致布局异常
- maxpages - 最大解析页数限制
- page_numbers - 需要处理的零基页码集合
- password - 加密PDF的解密密码
- scale - 缩放系数
- rotation - 旋转角度
- layoutmode - 默认 'normal' 模式,详见
pdfminer.converter.HTMLConverter - output_dir - 指定目录时将创建ImageWriter保存提取的图片
- strip_control - 移除控制字符
- debug - 启用调试日志输出
- disable_caching - 禁用缓存机制
- other - 其他参数
返回值:无,该函数通过操作两个流对象实现功能。需配合StringIO获取字符串结果。
extract_pages
python
pdfminer.high_level.extract_pages(
pdf_file: PurePath | str | IOBase, password: str = '',
page_numbers: Container[int] | None = None,
maxpages: int = 0, caching: bool = True,
laparams: LAParams | None = None) → Iterator[LTPage]提取并生成 LTPage 对象
参数:
- pdf_file -- 可以是PDF文件的路径,也可以是类似文件的对象。
- password -- 对于加密的PDF文件,用于解密的密码。
- page_numbers -- 要提取的页面编号列表(从0开始索引)。
- maxpages -- 要解析的最大页数。
- caching -- 是否缓存资源。
- laparams -- 来自 pdfminer.layout 的 LAParams 对象。如果为None,则使用一些通常效果良好的默认设置。
返回值:LTPage 对象
可组合API
https://pdfminersix.readthedocs.io/en/latest/reference/composable.html
LAParams 参数类
python
class pdfminer.layout.LAParams(
line_overlap: float = 0.5, char_margin: float = 2.0,
line_margin: float = 0.5, word_margin: float = 0.1,
boxes_flow: float | None = 0.5,
detect_vertical: bool = False, all_texts: bool = False)布局分析参数配置类
参数说明:
- line_overlap - 当两个字符的重叠区域超过此阈值时,将被视为同一行。重叠比例以两者中最小字符高度为基准计算。
- char_margin - 当两个字符间距小于此边距时,将被视为同一行内容。边距值以字符宽度为基准计算。
- word_margin - 同一行中若两个字符间距超过此边距,则会被识别为独立单词(系统会自动添加间隔空格以提高可读性)。边距值以字符宽度为基准计算。
- line_margin - 当两行间距小于此边距时,将被视为同一段落。边距值以行高为基准计算。
- boxes_flow - 控制文本框排序时水平/垂直位置的权重系数,取值范围为-1.0(仅水平位置生效)至+1.0(仅垂直位置生效)。传入None可禁用高级布局分析,此时仅根据文本框左下角坐标排序。
- detect_vertical - 是否在布局分析时检测垂直排列文本
- all_texts - 是否对图形中的文本执行布局分析
待办事项:
- PDFDevice
- TextConverter
- PDFPageAggregator
- PDFPageInterpreter
常见问题解答
https://pdfminersix.readthedocs.io/en/latest/faq.html
为什么叫 pdfminer.six?
Pdfminer.six 是 Euske 创建的原始 pdfminer 的一个分支。实际上,几乎所有的代码和架构都是由 Euske 开发的。但在很长一段时间里,原始 pdfminer 并不支持 Python 3。直到 2020 年,原始版本仍仅支持 Python 2。
pdfminer.six 最初的目标是增加对 Python 3 的支持,这一目标通过 six 包实现。six 包帮助编写同时兼容 Python 2 和 Python 3 的代码,因此得名 pdfminer.six。
2020 年起,pdfminer.six 放弃了对 Python 2 的支持,因为 Python 2 已终止维护。尽管 ".six" 部分不再适用,但为了不破坏现有用户的兼容性,我们保留了这一名称。
当前的口号 "We fathom PDF" 是对 "six" 的趣味双关。"Fathom" 既表示深入理解某事物,也指英制长度单位"英寻"------1 英寻等于 6 英尺。
pdfminer.six 与其他 pdfminer 分支有何不同?
pdfminer.six 现已成为一个独立的、由社区维护的 Python 包,专门用于从 PDF 中提取文本。我们积极修复错误(包括那些不完全遵循 PDF 参考标准的 PDF 文件),添加新功能,并持续提升 pdfminer.six 的易用性。
正是这种社区驱动的模式,使 pdfminer.six 区别于原始 pdfminer 的其他分支。
PDF 作为一种文件格式极其多样化,存在无数偏离官方标准的情况。
要全面支持所有 PDF 文件,唯一途径就是拥有一个积极使用并持续改进 pdfminer 的社区。
自 2020 年起,原始 pdfminer 项目已停止维护。若您需要活跃维护的 pdfminer 版本,Euske 本人也推荐使用 pdfminer.six 这一分支。
为什么文本输出中会出现(cid:x)值?
pdfminer.six最常见的问题之一就是文本输出中包含原始字符 ID(cid:x)。
这常常令人困惑,因为PDF查看器中文本显示正常,且同一PDF中的其他文本也能正确提取。
根本原因在于PDF对每个字符有两种不同的表示方式:
- 每个字符会映射到一个字形(glyph),决定其在PDF查看器中的显示效果
- 同时每个字符也会映射到对应的Unicode值,用于复制粘贴操作
某些PDF文件存在不完整的Unicode映射,导致无法将字符转换为Unicode。
此时pdfminer.six会默认显示原始字符ID(cid:x)。
快速测试方法:尝试从PDF查看器复制文本到文本编辑器。如果粘贴结果正常,则pdfminer.six也应能正确提取文本;如果出现乱码,则pdfminer.six同样无法完成字符到Unicode的转换。
参考文档:
2025-08-16(六)