阿里 AIDC-AI 发布 Ovis2.5:集成NaViT的多模态模型
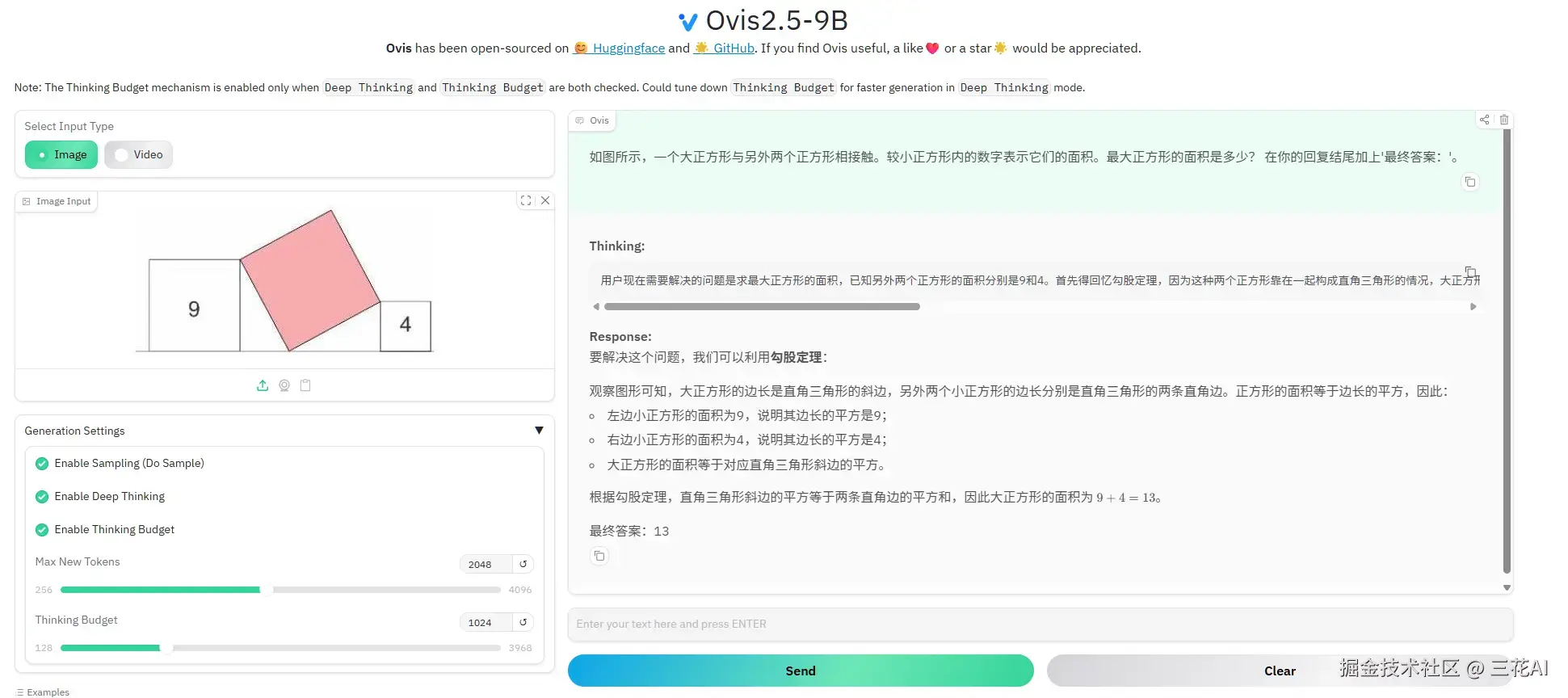
阿里AIDC-AI 推出了多模态模型 Ovis2.5,提供 9B 和 2B 两种参数量版本。该模型最大亮点是搭载原生视觉变换器(NaViT),突破性地支持直接处理任意原始分辨率图像------既不需要预先切片,也无需统一缩放至固定尺寸。这种创新架构完整保留了图像中的精细像素细节和全局空间布局,特别擅长解析图表、表格等结构化视觉内容。
佬们现在就可以去 Hugging Face Space1 调戏这个新模型
xAI AI 伴侣 Ani 和 Valentine 支持电话实时通话

xAI2 最新推出的 AI 伴侣 Ani 和 Valentine 现已支持电话实时通话功能!
现在,你可以像给朋友打电话一样,直接拨打 +1 (325) 225-5264(Ani)或 +1 (607) 225-5825(Valentine),与你的 AI 伴侣进行自然流畅的语音交流。
OpenAI 发布生产级 AI 应用开发全栈学习路径
OpenAI最新推出了从入门到生产级的 AI 应用开发学习路径3,学习后能够掌握AI基础概念,将其融入 AI 应用开发中,评估应用性能,并实施最佳实践以确保AI解决方案稳健且可大规模部署。
教程非常详细,只需要略懂 js 或者 python 就行学习。
字节 Trae 推出内置 Figma-to-code 功能
Trae4 在其产品的 Solo 模式中新增了内置 Figma-to-code 功能。
这个功能可以将用户的设计直接转化为可工作的代码,大大提升了开发效率。
不得不说 Trae 这个工具越来越强大了,虽然铺天盖地的宣传确实有点烦
阿里 Wan2.2-I2V-Flash图像转视频模型

阿里巴巴万相(Wan)团队5发布了 Wan2.2-I2V-Flash 图像转视频模型。
该模型推理速度相比前代提升了惊人的 12 倍,同时显著增强了指令遵循和风格保持能力,特别适合需要快速生成风格统一视频内容的场景。
不过遗憾的是,目前该模型仅通过 API 提供服务,权重并未公开
ElevenLabs 发布智能视频配乐生成功能
ElevenLabs Studio 中推出了 Video-to-Music 新功能,用户现在可以一键操作,让 Eleven Music 模型根据视频的上下文智能生成定制背景配乐。
这个 AI 能自动分析视频内容,匹配合适的音乐风格和情绪节奏。
详情可以查看官方推文6,这个功能把视频创作的配乐门槛降到了新低。