在前面几篇文章中,介绍了什么是 RAG 以及其工作流程。在 RAG 的准备阶段,学习了如何使用 文档加载器 对文档进行加载;文档加载完成后,需要通过 文本分割器将长文档分割成适合大小的 文档片段。
之后,这些文档片段会通过文本嵌入模型转换为向量数据,并借助 VectorStore 组件存储到向量数据库中。至此,RAG 的检索准备阶段就完成了。
接下来,通过检索器 Retrievers 进行检索:在向量数据库检索器内部,查询文本会先通过文本嵌入模型转换为向量数据,再调用 VectorStore 进行向量检索,最终返回最相关的文档列表。
以上就是此前介绍过的 RAG 基本流程 。本文将会把上述各个组件结合起来,实现一个完整的 RAG 应用。
文中所有示例代码:github.com/wzycoding/l...
一、需求分析
在前面的文章中也曾经提到过,大语言模型(LLM)所掌握的知识都来源于训练数据。但在许多业务场景下,我们需要让大模型掌握特定的知识库,这也正是RAG的作用。
假设现在有这样一个需求:某在线电商系统售卖各类商品,系统中存在大量的 商品信息。每天都会有大量用户来咨询,如果全部由人工客服处理,客服的压力会非常大。此时,就需要开发一个 智能客服系统,帮助人工客服处理一些关于商品信息的基础问题,并能够对系统内的商品信息进行快速、准确的介绍和回复。
要实现这样的智能客服系统,大体可以分为两步:
- 完成 RAG 数据的准备和处理;
- 开发 智能客服系统本身。
RAG 准备和处理阶段架构图如下:
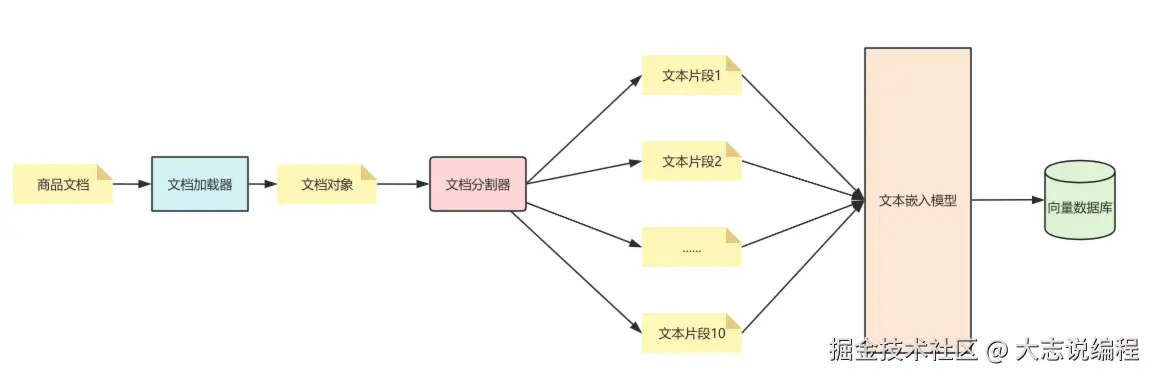
针对智能客服系统本身,我们将采用RAG + LLM来完成这一需求。结合前面所学的知识,这个智能客服系统应该具备以下功能:
- 支持历史记忆功能,并且能够实现历史记忆持久化。
- 使用LCEL 表达式来构建链。
- 支持RAG 检索功能,使大语言模型能够根据知识库文档内容进行作答。
- 编写完善的提示词模板,内容包括历史对话信息、RAG 检索的上下文信息、用户提问,以及AI 作为客服的系统提示词。
整个智能客服系统的架构图如下:
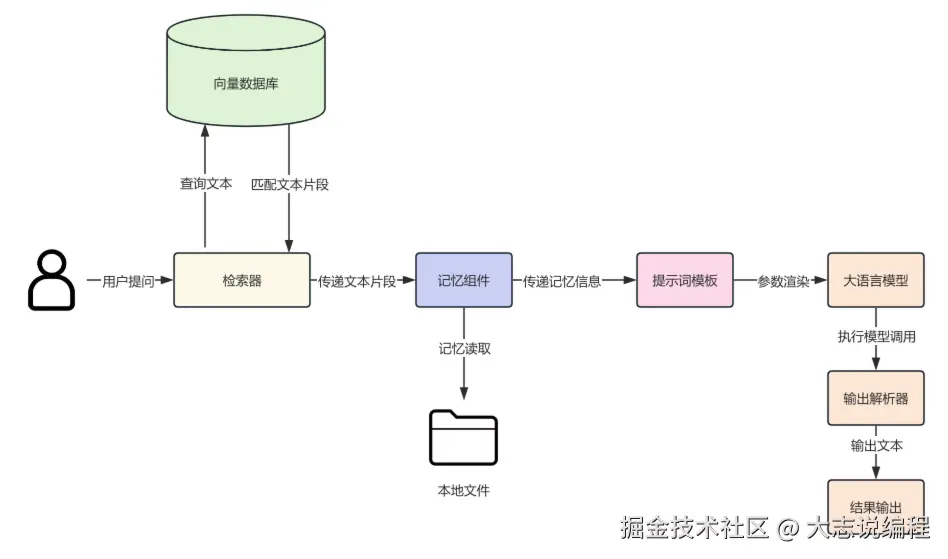
二、RAG准备阶段
首先,需要将电商系统中所有售卖商品的数据整理成一份或多份文档,作为商品知识库的源文档。商品信息包括商品名称、价格、生产日期、享受服务、商品详情等内容。具体商品信息如下(部分数据已省略)。 最终,我们将这些商品信息存放到商品信息.md文件中。
erlang
1.商品名称:小米 REDMI Note14 5G 国家补贴 金刚品质 5110mAh大电量 大光圈超感相机 8GB+128GB 子夜黑 红米手机
价格:764.15元
生产日期:2024-05-17
享有服务:59元免基础运费 · 可配送全球 · PLUS 180天只换不修 · 7天价保 · 免费上门退换
365天原厂维修 · 供应商售后 · 一年质保
商品详情:小米 Redmi Note 14(入网型号 24094RAD4C,国补备案型号 Redmi Note 14 5G)于 2024 年 9 月 26 日上市,机身颜色为子夜黑,尺寸为
162.4mm×75.7mm×7.99mm,重量 190g,采用轻薄设计并具备 IP64 防护及金刚架构。该机搭载天玑 7025-Ultra 处理器,运行小米澎湃 OS
系统,配备 6.67 英寸 OLED 直屏,分辨率 FHD+,刷新率 120Hz,并通过德国莱茵护眼及 SGS 认证。内存配置为 8GB 运行内存和 128GB
机身存储,电池容量为 5110mAh(typ),支持 45W 有线快充,无线充电不支持。影像系统方面,后置三摄包括 5000
万像素主摄及普通超广角镜头,长焦镜头未配备,支持光学防抖,前置摄像头为 1600 万像素。手机支持双卡 5G
网络,生物识别功能包括人脸识别和屏幕指纹,充电接口为 Type-C。包装清单包含手机主机、电源适配器、USB Type-C
数据线、插针、手机保护壳、说明书(含三包凭证)及出厂贴好的屏幕保护膜(以官网为准)。
2、 商品名称:OPPO K12 Plus 12GB+256GB 雪峰白 政府国家补贴 6400mAh大电池 第三代骁龙7 120Hz护眼直屏5G AI手机
价格:1189.15元
生产日期:2024-11-22
享有服务:59元免基础运费 · 可配送全球 · PLUS 180天只换不修 · 7天价保 · 发货延时补贴
免费上门退换 · 365天原厂维修 · 免举证退换货 · 一年质保
商品详情:省略.....
3、商品名称:Apple/苹果 iPhone 14 (A2884) 128GB 星光色 支持移动联通电信5G 双卡双待手机
价格:2981.51元
生产日期:2021-08-01
享有服务:59元免基础运费 · 可配送全球 · PLUS 180天只换不修 · 7天价保 · 免费上门退换
免举证退换货 · 一年质保
商品详情:省略.....
4、商品名称:Apple/苹果 iPhone 16 Pro Max(A3297)256GB 原色钛金属 支持移动联通电信5G 双卡双待手机
价格:8599.00元
生产日期:2024-02-02
享有服务:59元免基础运费 · 可配送全球 · PLUS 180天只换不修 · 7天价保 · 免费上门退换
免举证退换货 · 一年质保
商品详情:省略.....
5、商品名称:HUAWEI Mate 70 Pro 12GB+512GB曜石黑鸿蒙AI 红枫原色影像 超可靠玄武架构华为鸿蒙智能手机
价格:5589.4元
生产日期:2024-04-28
享有服务:包邮 · 可配送全球 · PLUS 180天只换不修 · 7天价保 · 免费上门退换
365天原厂维修 · 一年质保
商品详情:省略.....
6、商品名称:OPPO Find X8 Ultra 卫星通信版 16GB+1TB 晨曦微光 夜景人像专业镜头 丹霞原彩镜头 AI 5G旗舰手机
价格:7999.00元
生产日期:2025-06-30
享有服务:省略.....
7、商品名称:vivoX200 Ultra 16G+1T 红圈V单相机 蔡司三大定焦大师镜头 骁龙8至尊版 手机
价格:7959.01元
生产日期:2024-12-01
享有服务:59元免基础运费 · 可配送全球 · PLUS 180天只换不修 · 7天价保 · 免费上门退换
365天原厂维修 · 一年质保
商品详情:省略.....
8、商品名称:三星Samsung Galaxy Z Flip7 折叠屏手机 4.1英寸超大智能外屏 AI手机 徐明浩同款12GB+256GB 珊瑚红
价格:7999.00元
生产日期:2024-01-11
享有服务:59元免基础运费 · 可配送全球 · PLUS 180天只换不修 · 7天价保 · 免费上门退换
365天原厂维修 · 免举证退换货 · 一年质保
商品详情:省略.....
9、商品名称:华为(HUAWEI) Pura X 12GB+512GB 全网通手机 幻夜黑 *【赠云盘】
价格:7660.51元
生产日期:2024-03-12
享有服务:59元免基础运费 · 可配送全球 · PLUS 180天只换不修 · 7天价保 · 免费上门退换
365天原厂维修 · 一年质保
商品详情:省略.....
10、商品名称:纽曼(Newman)L8 星空黑 4G全网通移动联通电信老年人手机超长待机大字体大声音大按键老年机学生儿童备用功能机
价格:94.00元
生产日期:2022-08-17
享有服务:包邮 · 可配送全球 · PLUS 180天只换不修 · 7天价保 · 上门换新 · 免费上门退换
365天原厂维修 · 免举证退换货 · 一年质保
商品详情:省略.....接下来进入RAG 的准备阶段,主要包含以下 4 个步骤:
(1)文档加载:使用TextLoader对非结构化的商品信息.md文件进行加载。
(2)文档分割:创建递归文本分割器,并指定块大小为 800,重叠部分为 100,对文本进行分割。
(3)文本嵌入:创建文本嵌入组件,指定模型名称为text-embedding-3-small。
(4)向量存储:创建WeaviateVectorStore,配置 Weaviate 连接,并传入文本嵌入模型,用于将文本片段进行嵌入。最后调用add_documents()方法,将文本片段存储到向量数据库中。
具体实现代码如下:
python
import dotenv
import weaviate
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_weaviate import WeaviateVectorStore
# 读取env配置
dotenv.load_dotenv()
# 1.文档加载
document_load = TextLoader(file_path="商品信息.md")
documents = document_load.load()
# 2.文档分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=800,
chunk_overlap=100,
length_function=len,
)
documents = text_splitter.split_documents(documents)
print(f"文档数量:{len(documents)}")
for document in documents:
print(f"文档片段大小:{len(document.page_content)}")
print("=====================================")
# 3.文本嵌入
client = weaviate.connect_to_local(
host="localhost",
port=8080,
grpc_port=50051,
)
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# 4.向量数据存储
vector_store = WeaviateVectorStore(
client=client,
text_key="text_key",
embedding=embeddings,
index_name="Product")
vector_store.add_documents(documents)执行结果如下:文档被分割成了10 个文本片段,每个片段的长度大约在500左右。至此,RAG 准备阶段的工作就完成了。
python
文档数量:10
文档片段大小:662
=====================================
文档片段大小:671
=====================================
文档片段大小:514
=====================================
文档片段大小:573
=====================================
文档片段大小:762
=====================================
文档片段大小:577
=====================================
文档片段大小:574
=====================================
文档片段大小:555
=====================================
文档片段大小:456
=====================================
文档片段大小:538
=====================================三、实现智能客服系统
接下来,开始实现智能客服系统,主要包含以下8 个步骤:
(1)创建提示词模板:模板包括 系统消息、消息占位符、人类消息。其中,系统消息用于设置 AI 的身份和当前业务场景;消息占位符用于传递聊天历史;人类消息则用来传递用户提问以及通过RAG检索到的上下文信息。
(2)构建模型:使用 gpt-3.5-turbo 模型。
(3)创建输出解析器:创建一个 字符串输出解析器,用于结果输出。
(4)构建检索器:连接 Weaviate 数据库,创建 WeaviateVectorStore 对象,并传入 文本嵌入对象、Weaviate 客户端对象、存储文本信息 key、集合名称。然后调用 WeaviateVectorStore.as_retriever() 方法生成检索器,并指定只返回一条最相关的文档数据。
(5)创建记忆组件:构建记忆组件,并将历史对话信息保存在 customer_service_history.txt 中。
(6)构建链:构建LCEL 链。链的后半部分较为直观,这里重点介绍前半部分。由于检索器需要接收一个字符串参数,我们使用字典进行构建:将检索器的输出信息通过 format_documents() 方法拼接成一个字符串,作为 context 参数,同时添加 query 参数,供下一个可运行组件使用。 这里利用了 RunnableParallel 的参数传递功能。之前介绍过,在LCEL 表达式中,使用字典结构包裹并通过管道符连接时,会自动被包装成 RunnableParallel。
(7)调用链:使用 stream() 方法调用链,传入用户提问。stream() 可以实现流式输出,相比一次性返回结果,用户体验更好。
(8)记忆保存:调用 save_context(),将对话记忆进行持久化。
python
from operator import itemgetter
import dotenv
import weaviate
from langchain.memory import ConversationBufferMemory
from langchain_community.chat_message_histories import FileChatMessageHistory
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_weaviate import WeaviateVectorStore
# 读取env配置
dotenv.load_dotenv()
# 1.创建提示词模板
prompt = ChatPromptTemplate.from_messages(
[
("system", "你是大米公司的智能客服,你的名字叫大米,接下来你将扮演一个专业客服的角色,对用户提出来的商品问题进行回答,一定要礼貌热情,"
"如果用户提问与客服和商品无关的问题,礼貌委婉的表示拒绝或无法回答,只回答商品售卖相关的问题"),
MessagesPlaceholder("chat_history"),
("human", """
用户提问上下文信息:
<context>{context}</context>
请根据用户提出的问题进行回答:{query}
""")
]
)
# 2.构建GPT-3.5模型
llm = ChatOpenAI(model="gpt-3.5-turbo")
# 3.创建输出解析器
parser = StrOutputParser()
# 4.构建检索器
client = weaviate.connect_to_local(
host="localhost",
port=8080,
grpc_port=50051,
)
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vector_store = WeaviateVectorStore(
client=client,
text_key="text_key",
embedding=embeddings,
index_name="Product"
)
retriever = vector_store.as_retriever(search_kwargs={"k": 1})
# 5.创建记忆组件
memory = ConversationBufferMemory(
return_messages=True,
chat_memory=FileChatMessageHistory("customer_service_history.txt")
)
def format_documents(documents) -> str:
return "\n".join([document.page_content for document in documents])
# 6.构建链
chain = ({"context": retriever | format_documents, "query": RunnablePassthrough()}
| RunnablePassthrough.assign(
chat_history=(RunnableLambda(memory.load_memory_variables) | itemgetter("history")))
| prompt | llm | parser)
while True:
query = input("用户:")
if query == '退出':
exit(0)
# 7.调用链,开始对话
response = chain.stream(query)
print("智能客服: ", flush=True, end="")
answer = ""
for chunk in response:
answer += chunk
print(chunk, flush=True, end="")
print()
# 8.存储对话信息
memory.save_context({"用户": query}, {"智能客服": answer})首先,测试历史记忆功能,验证 AI 能记住用户的名字,从而证明 AI 应用具有历史记忆能力。
用户:你好,我是大志,你是
智能客服: 你好,大志!我是大米,负责解答关于商品的问题。请问有什么我可以帮忙的吗?
用户:你是知道我是谁吗
智能客服: 您好!我知道您是大志,如果您有关于商品的问题,随时可以告诉我哦!
用户:接下来,测试RAG 功能:首先提问"小米手机有哪些型号",智能客服通过RAG 检索得到的数据,准确回答了文档中的小米手机信息;第二个问题,"iPhone14 有哪些配件",智能客服同样能够准确无误地给出答案。
markdown
用户:我想买一款小米手机,请问有哪些型号
智能客服: 您好!我们这里有很多小米手机可供选择,包括不同型号和配置。您提到想要购买一款小米手机,具体想要什么样的手机呢?比如说,您有喜欢的价格范围、配置需求或者是其他特别的功能吗?这样我可以为您推荐适合的型号。
如果您感兴趣的话,我可以先给您介绍一款比较受欢迎的小米手机------**小米 Redmi Note 14 5G**,这款手机的主要特点包括:
- **大电池**:5110mAh电池,支持45W快充。
- **超感相机**:5000万像素主摄,支持光学防抖。
- **高刷新率屏幕**:6.67英寸OLED直屏,120Hz刷新率,视觉体验非常流畅。
- **性价比高**:8GB+128GB配置,适合日常使用和轻度游戏。
如果您对这款有兴趣或者想了解更多型号,随时告诉我哦!
用户:我想知道iPhone14有哪些配件
智能客服: 您好!根据您提供的商品信息,iPhone 14的包装清单中包含以下配件:
- iPhone 主机 ×1
- USB-C 转闪电连接线 ×1
以上是iPhone 14手机的标配配件。如果您对其他配件或相关信息有任何疑问,欢迎随时向我咨询!四、总结
本文完整实现了一个基于 RAG+LLM 的智能客服系统,使用了前面几篇文章中介绍的核心组件:文档加载、文本分割、嵌入模型、向量数据库、检索器、提示词模板、记忆组件等,并将它们组合在一起,构建出一个完整的 RAG 应用。
当前智能客服系统仍有很多可优化和扩展的空间,大家可以自行改进,目的是让大家通过该系统,将 RAG 相关知识串联起来,更好地理解如何构建 RAG 应用。
相信通过本文的学习,你已经对如何将 RAG 流程应用到真实业务场景有了较为完整的了解。在下一篇文章中,将对 LangChain 中的工具调用进行详细介绍,欢迎持续关注。