本文较长建议点赞收藏。更多AI大模型开发 学习视频/籽料/面试题 可参考>>Github<<
今天就来手把手教大家:怎么从零开始搭一个属于自己的 RAG 系统?其实核心就 3 步,哪怕是 AI 初学者也能看懂,赶紧码住~
Step 1:数据预处理 ------ 给知识 "拆包""编码"
想让大模型用上咱们的专业知识,第一步得把原始数据 "处理成它能看懂的形式"。这一步就像咱们看书前先给书分类、标重点,方便之后快速查找。具体分 3 小步:
1. 收集知识库:把 "原材料" 攒起来
首先得有 "料"------ 不管是公司的业务手册、PDF 文档、Excel 表格,还是网页上的专业文章,只要是和你的业务相关的知识,都可以收集起来。比如做法律客服,就收集法条、案例;做教育辅导,就收集教材、题库。
2. 文档分块:把知识切成 "小块"
收集来的文档可能很长(比如一本几百页的手册),直接喂给模型会效率很低。这时候就需要 "分块"------ 把长文档切成一个个短片段(叫 "Chunks"),比如按章节、按段落,或者固定长度(比如每 300 字一段)。
关键原则:既不能切太碎(比如一句话一段,可能破坏语义),也不能切太大(比如一整本书一段,检索起来太慢)。目标是让每个 "小块" 既能独立表达一个完整意思,又方便后续快速查找。
3. 向量化:给知识 "编密码"
这是最核心的一步!大模型看不懂文字,得把文字转换成它能理解的 "数字向量"(比如一串 768 维或 1024 维的数字)。就像咱们用字母拼单词,模型用向量 "拼" 知识 ------ 语义越像的文字,向量越接近。
- 工具推荐:初学者不用自己写模型,直接用开源的 Embedding 模型就行,比如 BGE、M3E,几行代码就能把文本转成向量。
- 存哪里:转换好的向量会存在 "向量数据库" 里(比如 Pinecone、Milvus,简单理解就是专门存向量的 "仓库"),方便后面快速检索。
小补充:向量化的原理有点复杂,后面会专门写一篇文章拆解,这里知道 "文字转数字,方便模型比对" 就行~
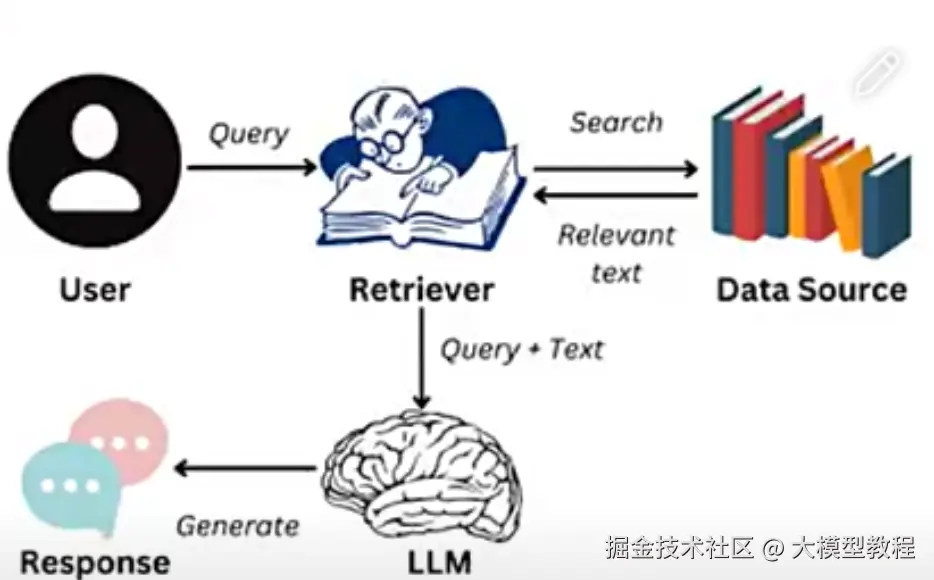
Step 2:数据检索 ------ 让模型 "精准找答案"
当用户提问时,RAG 会先帮模型 "搜资料",找到最相关的知识片段。这一步就像咱们查字典:先根据问题找关键词,再翻到对应的页码。
1. 问题转向量:把用户的话 "编码"
用户问的问题(比如 "信用卡逾期一天影响征信吗?"),也要先用 Step 1 里的向量化工具转换成向量 ------ 相当于给问题 "编个密码",方便和知识库的向量比对。
2. 相似度检索:找到 "最像的知识"
向量数据库会计算 "问题向量" 和 "知识库向量" 的相似度(比如用余弦相似度、欧氏距离),挑出最像的 Top K 个片段(比如 Top 3 或 Top 5)。
小技巧:可以用提示词工程优化问题,让检索更准。比如用户问 "有什么好的美元理财产品?",可以让大模型先把问题扩写成 "有什么预期收益率高、灵活取用的美元理财产品?",关键词更明确,找到的知识也更相关。
工具推荐:LangChain 里的 QA 模块(qa_langchain)可以直接实现这一步,不用自己写复杂代码~
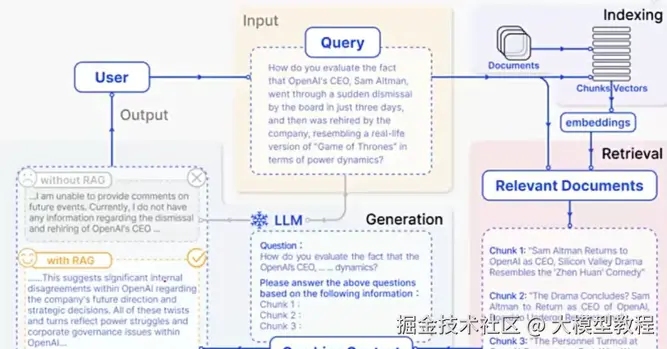
Step 3:生成答案 ------ 让模型 "基于知识说话"
最后一步,就是让大模型结合用户的问题和检索到的知识,生成最终回答。这时候模型不会瞎编,而是会基于找到的 "知识片段" 总结,相当于带着 "参考资料" 答题,准确率自然更高。
比如用户问 "信用卡逾期一天影响征信吗?",RAG 会先从知识库找到《信用卡章程》里的相关条款(比如 "逾期 3 天内还款不上征信"),再让大模型基于这条款回答,既专业又准确。
灵魂拷问:模型怎么知道啥时候用 RAG?
有同学可能会问:大模型怎么判断 "该用自己的知识回答,还是该查 RAG 知识库"?比如用户问 "今天天气怎么样",可能不需要查业务知识;但问 "公司的年假政策",就必须查 RAG。
其实有 3 种常见做法:
- 让大模型自己判断:在提示词里加一句 "如果问题和业务相关,就用 RAG 知识库回答,否则直接回答"。
- 强制查 RAG:所有问题都先过一遍 RAG,确保回答基于最新知识(适合对准确性要求极高的场景,比如医疗、法律)。
- 用智能体(Agent)管理:让 Agent 像 "小助理" 一样,自动判断什么时候需要调用 RAG 工具,什么时候直接回答。这种方式更智能,后面会专门讲~
AI大模型开发 学习视频/籽料/面试题 学习文档 详细内容可参考>>Github<<