KubeBlocks for Milvus 揭秘
背景
Milvus 是一款由 Zilliz 开发的分布式向量数据库,是业界主流的向量数据库之一。它主要用于相似性搜索(Similarity Search)和大规模向量检索,常见于如图像识别、推荐系统、自然语言处理、音频识别等 AI 场景中。Milvus 的本意是鸢,是一种猛禽。
Milvus 能够支持存储百亿级别的向量,这离不开它的云原生架构:
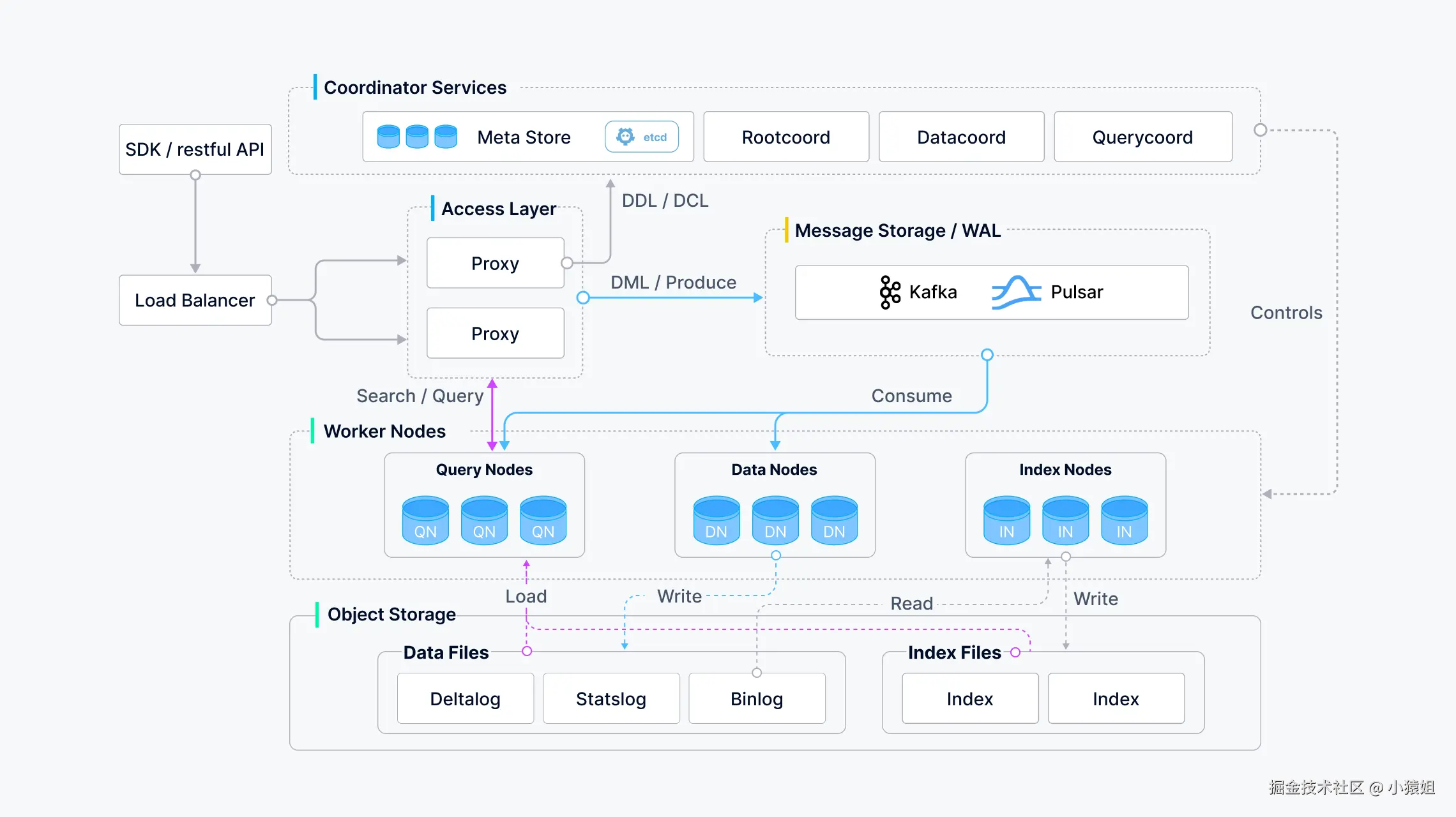
(此处放的是 2.5.x 的图,2.6.x 的架构有一些变化,但大致相同)
由上图可见,Milvus 将存储和运算组件分离,自身组件是完全无状态的,因而能够方便地进行水平扩容。Milvus 的工作节点遵循低耦合的原则,分为查询、数据、索引三种,分别处理向量搜索、压缩、索引任务。节点之间通过协调者分配任务。客户端流量通过代理节点进行负载均衡。
Milvus 依赖三个有状态外部组件工作,分别是:
- etcd,存储 Milvus 的元数据,以此来实现各个组件之间的服务发现。例如数据节点会往 etcd 中写入如下数据:
Bash
laure-fc4d79455/meta/session/datanode-5
{"ServerID":5,"ServerName":"datanode","Address":"192.168.0.33:21124","TriggerKill":true,"Version":"2.5.13","IndexEngineVersion":{},"ScalarIndexEngineVersion":{},"LeaseID":2902455202693735596,"HostName":"laure-fc4d79455-datanode-0"}其中包含了节点的 id、hostname、连接地址等信息。
- 消息队列,作为 Milvus 的 WAL 日志使用。在 2.5 版本中 Milvus 支持 Kafka 和 Pulsar 两种消息队列。
- 对象存储,作为 Milvus 的主要存储使用。WAL 日志中的数据会周期性地写入到对象存储中储存。
Milvus 对 Kubernetes 提供了良好的支持,官方也提供了 Milvus Operator 在 Kubernetes 上部署和管理 Milvus。然而,Milvus Operator 在管理 etcd/minio 等外部组件上还比较简陋,只提供了拉起对应 Pod 的功能,无法进行更多的 Day-2 运维操作。
KubeBlocks 是一个在 Kubernetes 上运行的数据库中立的管控平台。通过 Addon 的抽象,Kubeblocks 提供了支持任意类型数据库的统一接口,涵盖了启动脚本、生命周期钩子、配置管理等各个方面。KubeBlocks Milvus Addon 不仅能对 Milvus 进行生命周期管理和运维操作,也能够更好地管理 Milvus 所依赖的外部组件。通过 KubeBlocks 提供的数据库运维接口,用户能够在运维各种数据库时获得统一的体验。
KubeBlocks Addon 实现
由于 Milvus 无状态的特性,KubeBlocks Addon 的实现相当简单。然而,
KubeBlocks 中已经支持了 etcd/kafka/minio 这几个 Addon,所以我们可以复用这些 Addon,来使用它们提供的服务。这也是 KubeBlocks 中 "blocks" 的含义,我们能够通过搭积木的方式,构建一个复杂的数据库系统。
下面介绍 Addon 的具体实现,所有内容都基于 KubeBlocks 0.9 的 API 和 milvus 2.5 版本。KubeBlocks API 的解释可以参考官网的介绍。
首先我们通过 ClusterDefinition 定义两种拓扑结构:standalone 和 cluster,对应 milvus 的单机和分布式版本。前者用于小规模的测试,后者适用于大规模生产环境。
standalone 版本
单机版本下,Milvus 中所有组件运行在一个 Pod 中,消息队列使用内置的 rocksmq,这样只需要依赖 etcd 和对象存储两个外部组件。为了简化部署流程,我们将这两个组件作为 Component 运行。通过在 ClusterDefinition 中声明 etcd 和 minio 两个 Components,并引用相应的 ComponentDefinition,即可在 Milvus 集群启动时同时启动 etcd 和 minio。由于 KubeBlocks 创建的 Service 遵循 {clusterName}-{componentName} 的命名规则,且所有 Component 都会自带一个 headless 服务,我们可以在 Milvus 配置文件中构造类似这样的地址 {{ .KB_CLUSTER_NAME }}-etcd-headless.{{ .KB_NAMESPACE }}.svc.cluster.local:2379来连接对应的服务。
cluster 版本
分布式版本下,Milvus 拆分出了 proxy/query/data/index/coord 等不同的组件。但本质上,这些组件使用同一个容器镜像,所有组件也共享一份配置文件,只是启动命令不同。这一高度统一的部署流程也方便了我们对不同组件的管理。
在 cluster 版本中,我们不再将 etcd 和对象存储作为 Component 运行,而是作为外部服务在 Milvus 集群中引用。Milvus 分布式版本支持 Pulsar 和 Kafka 作为消息队列。在 KubeBlocks 中 Kafka Addon 的成熟度较高,因此我们使用 Kafka 作为消息队列。同样的,它作为外部服务在 Milvus 集群中引用。
KubeBlocks 提供了 ServiceRef 来引用一个外部服务。我们首先在 ComponentDefinition 的 .spec.serviceRefDeclarations 字段中声明该 Component 需要的 ServiceRef, 例如:
YAML
- name: milvus-meta-storage
serviceRefDeclarationSpecs:
- serviceKind: etcd
serviceVersion: "^3.*"
optional: true然后,在 Cluster CR 的 .spec.componentSpecs[*].serviceRefs 字段中,就可以传入相应的 ServiceRef。ServiceRef 支持两种引用方式:
- 引用一个由 KubeBlocks 管理的集群,并选择相应的服务。例如:
YAML
- name: milvus-meta-storage # <----- 和 serviceRefDeclarations 中的 name 对应
namespace: kubeblocks-cloud-ns # <----- 引用的 Cluster 所在的 namespace
clusterServiceSelector:
cluster: rice6-849768d46
service:
component: etcd
service: headless # <----- 和 etcd ComponentDefinition 中的 .spec.services 对应
port: client # <----- etcd ComponentDefinition 中 .spec.services[*].spec.ports 中定义的某个端口.clusterServiceSelector.service 中的 service 字段除了使用常规定义的 service 之外,也可以使用一个特殊的 service headless,这是 InstanceSet 为每个 Component 默认创建的 Headless Service。这个 service 不需要在 ComponentDefinition 中定义,可以直接使用。
- 引用一个外部地址。在 KubeBlocks API 中,有一个单独的 ServiceDescriptor CR 来定义这个外部地址。例如:
YAML
apiVersion: apps.kubeblocks.io/v1alpha1
kind: ServiceDescriptor
metadata:
name: etcd
namespace: kubeblocks-cloud-ns
spec:
host:
value: etcd-service
port:
value: "1234"
serviceKind: etcd
serviceVersion: 3.5.2然后在 Cluster Object 中传入 ServiceRef:
YAML
- name: milvus-meta-storage
namespace: kubeblocks-cloud-ns # <----- 引用的 ServiceDescriptor 所在的 namespace
serviceDescriptor: maple-7b759bdb4c-minio使用 ServiceRef 的好处在于:
- 用户可以使用一个非 KubeBlocks 管理的服务(如对象存储)
- 一个服务可以被多个集群共享
- 服务与引用它的集群之间解耦,方便这个服务单独进行运维操作
Milvus Addon 同时支持了这两种 ServiceRef 的引用方式。在配置完 ServiceRef 之后,我们通过 ComponentDefinition 中的 .spec.vars 字段引用这些 ServiceRef,例如:
YAML
- name: ETCD_HOST_SVC_REF
valueFrom:
serviceRefVarRef:
name: milvus-meta-storage
optional: true
host: Required
- name: ETCD_PORT_SVC_REF
valueFrom:
serviceRefVarRef:
name: milvus-meta-storage
optional: true
port: Required这些 vars 将在渲染配置文件时被传入到模板中。由于 Milvus 的各个组件是无状态的,因此无需配置 Volume,也无需配置 roleProbe 等 lifecycleAction。
部署实践
我们可以使用如下的 Cluster CR 来部署一个 Milvus 分布式版本的集群:
YAML
apiVersion: apps.kubeblocks.io/v1alpha1
kind: Cluster
metadata:
namespace: kubeblocks-cloud-ns
name: maple-7b759bdb4c
labels:
helm.sh/chart: milvus-cluster-0.9.2
app.kubernetes.io/version: "2.5.13"
app.kubernetes.io/instance: milvus
spec:
clusterDefinitionRef: milvus
topology: cluster
terminationPolicy: Delete
componentSpecs:
- name: proxy
serviceVersion: 2.5.13
replicas: 1
resources:
limits:
cpu: "1"
memory: "1Gi"
requests:
cpu: "0.5"
memory: "0.5Gi"
env:
- name: MINIO_BUCKET
value: kubeblocks-oss
- name: MINIO_ROOT_PATH
value: kubeblocks-cloud-ns/test-milvus
- name: MINIO_USE_PATH_STYLE
value: "false"
serviceRefs:
- name: milvus-meta-storage
namespace: kubeblocks-cloud-ns
clusterServiceSelector:
cluster: rice6-849768d46
service:
component: etcd
service: headless
port: client
- name: milvus-log-storage-kafka
namespace: kubeblocks-cloud-ns
clusterServiceSelector:
cluster: bambo-78dcc489cb
service:
component: kafka-combine
service: advertised-listener
port: broker
- name: milvus-object-storage
namespace: default
serviceDescriptor: maple-554bfbfc6b-minio
serviceAccountName:
disableExporter: true
# mixcoord/index/query/data 组件的配置和 proxy 类似,这里省略创建后查看 Pod 状态:

由于 Milvus 各个组件无状态的特性,它们无需额外额外配置就能够支持垂直伸缩、水平伸缩等运维操作。同时,KubeBlocks 原生提供的集群重启、停止、小版本升级等运维操作也适用于 Milvus。
总结
本文介绍了 Milvus 向量数据库及其在 KubeBlocks 上的部署实现。Milvus 采用无状态分布式架构,支持大规模向量检索,常用于 AI 场景。KubeBlocks 通过复用 etcd、Kafka、MinIO 等模块化 Addon,提供 standalone 和 cluster 两种部署模式,并借助 ServiceRef 引用外部服务,实现了灵活扩展与简化运维。