文章目录
- 1.网络
-
- [1.1 浏览器从输入网址到展示页面,描述下整个过程?](#1.1 浏览器从输入网址到展示页面,描述下整个过程?)
- [1.2 HTTP 502,503 和 504 是什么含义?区别以及如何排查?](#1.2 HTTP 502,503 和 504 是什么含义?区别以及如何排查?)
- [1.3 HTTPS 通信过程为什么要约定加密密钥 code,用非对称加密不行吗?](#1.3 HTTPS 通信过程为什么要约定加密密钥 code,用非对称加密不行吗?)
- [1.4 既然 HTTPS 通信是加密的,为什么抓包工具如 Fiddler 可以看到明文?](#1.4 既然 HTTPS 通信是加密的,为什么抓包工具如 Fiddler 可以看到明文?)
- [1.5 TCP 3 次握手的过程? 2 次或者 4 次行不行?](#1.5 TCP 3 次握手的过程? 2 次或者 4 次行不行?)
- [1.6 TCP 四次挥手的过程?](#1.6 TCP 四次挥手的过程?)
- [1.7 TCP 3 次挥手可以吗?](#1.7 TCP 3 次挥手可以吗?)
- [1.8 为什么需要延迟确认?](#1.8 为什么需要延迟确认?)
- [1.9 服务端可以主动发起断开连接吗?](#1.9 服务端可以主动发起断开连接吗?)
- [1.10 客户端回复服务端断开请求 ACK 报文后会进入什么状态?](#1.10 客户端回复服务端断开请求 ACK 报文后会进入什么状态?)
- [1.11 大量 TCP 连接状态处于 TIME_WAIT 状态会有什么问题?](#1.11 大量 TCP 连接状态处于 TIME_WAIT 状态会有什么问题?)
- 2.数据库
-
- [2.1 事务的四大特性是什么?](#2.1 事务的四大特性是什么?)
- [2.2 MySQL 是如何实现 MVCC 的?](#2.2 MySQL 是如何实现 MVCC 的?)
- [2.3 MVCC 的 undo 日志是什么时候清理的?](#2.3 MVCC 的 undo 日志是什么时候清理的?)
- [2.4 MySQL 索引数据结构是什么?](#2.4 MySQL 索引数据结构是什么?)
- [2.5 MySQL 为什么用 B+ 树,不用 B 树?](#2.5 MySQL 为什么用 B+ 树,不用 B 树?)
- [2.6 什么情况下会导致索引失效?](#2.6 什么情况下会导致索引失效?)
- [2.7 手写 SQL: 给定用户表 user 和帖子表 post,获取帖子数前十的用户名?](#2.7 手写 SQL: 给定用户表 user 和帖子表 post,获取帖子数前十的用户名?)
- 3.Golang
-
- [3.1 Golang 的 GC 是怎么实现的?](#3.1 Golang 的 GC 是怎么实现的?)
- [3.2 为什么是三色标记,两色不行吗?](#3.2 为什么是三色标记,两色不行吗?)
- 4.问题定位
-
- [4.1 如何定位服务器 CPU 占用率过高的问题?](#4.1 如何定位服务器 CPU 占用率过高的问题?)
- 5.设计题
-
- [5.1 如何限制用户 1 分钟只发送 5 个帖子?](#5.1 如何限制用户 1 分钟只发送 5 个帖子?)
- [5.2 使用计数器会有什么问题?有更好的办法吗?](#5.2 使用计数器会有什么问题?有更好的办法吗?)
- 6.编程题
-
- [6.1 找出 Top2 的数](#6.1 找出 Top2 的数)
- [6.2 找出比左边大比右边小的数](#6.2 找出比左边大比右边小的数)
1.网络
1.1 浏览器从输入网址到展示页面,描述下整个过程?
- URL 解析
输入处理:浏览器解析你输入的URL(如 https://www.example.com),判断是搜索关键词还是合法URL。
协议补充:若未指定协议(如http://或https://),浏览器会默认补全(通常为https)。
端口处理:若未指定端口,使用默认端口(HTTP为80,HTTPS为443)。
- DNS 查询(域名解析)
- 检查缓存:
浏览器缓存 → 系统缓存(如hosts文件) → 路由器缓存 → ISP的DNS缓存。
- 递归查询(若缓存未命中):
浏览器向本地DNS服务器发起请求,依次查询:
根域名服务器(.) → 顶级域名服务器(.com) → 权威域名服务器(example.com)。
最终获取目标服务器的IP地址。
- 建立 TCP 连接
- 三次握手(针对HTTPS):
客户端发送SYN包到服务器。
服务器回复SYN-ACK包。
客户端发送ACK包,连接建立。
- TLS握手(HTTPS):
协商加密算法,交换密钥,验证证书(如CA机构签发)。
- 发送 HTTP 请求
浏览器构造HTTP请求报文,例如:
http
GET / HTTP/1.1
Host: www.example.com
Connection: keep-alive
User-Agent: Chrome/...附加请求头(如Cookie、Accept-Encoding等)。
- 服务器处理请求
Web服务器(如Nginx/Apache)接收请求,可能转发给应用服务器(如Node.js、Tomcat)。
后端处理:执行业务逻辑(数据库查询、API调用等),生成响应(HTML/JSON等)。
- 接收 HTTP 响应
-
服务器返回响应报文,例如:
HTTP/1.1 200 OK
...
Content-Type: text/html
Content-Length: 1234 -
状态码(如200成功、404未找到)和响应头(如Cache-Control、Set-Cookie)。
- 渲染页面
解析HTML:浏览器构建DOM树。
加载子资源:解析到,
构建CSSOM:解析CSS样式。
执行JavaScript:可能阻塞渲染(除非标记async/defer)。
布局(Layout):计算元素位置和大小。
绘制(Paint):将像素输出到屏幕。
- 连接终止
四次挥手(若为短连接):
- 客户端发送FIN包。
- 服务器确认ACK。
- 服务器发送FIN包。
- 客户端确认ACK,连接关闭。
关键优化点:
DNS预取:提前解析域名。
TCP复用:HTTP/1.1的keep-alive或HTTP/2多路复用。
CDN加速:静态资源分发到边缘节点。
缓存策略:Cache-Control、ETag减少重复请求。
1.2 HTTP 502,503 和 504 是什么含义?区别以及如何排查?
| 状态码 | 名称 | 原因 |
|---|---|---|
| 500 | Internal Server Error | 服务器内部错误(如代码异常、数据库连接失败)。 |
| 501 | Not Implemented | 服务器不支持请求的功能(如未实现的HTTP方法)。 |
| 502 | Bad Gateway | 网关或代理服务器从上游服务器收到了无效或无法解析的响应(如连接拒绝、响应中断)。 |
| 503 | Service Unavailable | 服务不可用(如服务器过载、维护中)。 |
| 504 | Gateway Timeout | 网关或代理服务器等待上游服务器响应超时。 |
| 505 | HTTP Version Not Supported | 服务器不支持请求的HTTP协议版本(如客户端使用HTTP/3但服务器仅支持HTTP/1.1)。 |
- 502(Bad Gateway)
问题出在代理与后端通信,但后端可能仍在运行,只是返回了错误数据。
典型场景:
后端服务崩溃(如PHP-FPM进程挂掉)。
代理配置错误(如Nginx的proxy_pass指向了错误的端口)。
后端返回了不完整的HTTP响应(如未发送完数据就断开连接)。
排查方法:
检查后端服务是否运行(systemctl status nginx)。
查看代理服务器日志(如Nginx的error.log)。
测试后端服务是否能直接访问(curl http://backend-server:port)。
- 503(Service Unavailable)
后端主动告知不可用,通常用于临时维护或过载保护。
典型场景:
服务器维护(如人工停机升级)。
流量激增触发限流(如Cloudflare的Under Attack模式)。
自动扩缩容期间服务短暂不可用(如Kubernetes滚动更新)。
排查方法:
检查是否有维护公告或运维操作。
查看后端服务的负载情况(top、htop)。
如果是云服务,检查自动扩缩容策略(如AWS Auto Scaling)。
- 504(Gateway Timeout)
代理服务器等待后端响应超时,但后端可能仍在处理请求(只是太慢)。
典型场景:
后端处理时间过长(如复杂SQL查询、大数据导出)。
网络延迟或丢包(如跨国请求、服务器间网络问题)。
代理服务器超时设置过短(如Nginx proxy_read_timeout 默认60秒)。
排查方法:
增加代理超时时间(Nginx调整proxy_read_timeout)。
优化后端性能(如数据库索引优化、缓存加速)。
检查网络链路(ping、traceroute)。
1.3 HTTPS 通信过程为什么要约定加密密钥 code,用非对称加密不行吗?
- 为什么需要约定密钥?
HTTPS 使用 对称加密(如AES) 传输数据,因为对称加密的计算速度快,适合加密大量数据。
但对称加密需要双方持有相同的密钥,因此必须通过安全的方式协商密钥,这就是 密钥交换(Key Exchange) 的作用。
- 为什么不能只用非对称加密?
非对称加密(如RSA、ECC)虽然可以加密数据,但存在以下问题:
(1) 性能问题
非对称加密计算复杂度高,比对称加密(如AES)慢 100-1000倍。
如果全程用非对称加密,服务器和客户端的CPU负载会极高,影响用户体验。
(2) 安全性问题
长期使用同一密钥风险高:如果服务器长期使用同一个RSA私钥加密数据,一旦私钥泄露,所有历史通信都可能被解密(不具备 前向安全性)。
密钥管理复杂:非对称加密的密钥对需要严格保护,而对称加密的会话密钥可以定期更换。
- 密钥交换的演进
(1) RSA 密钥交换(旧方式)
客户端生成对称密钥,用服务器的RSA公钥加密后发送。
问题:不具备前向安全性(如果服务器私钥泄露,历史通信可被解密)。
(2) ECDHE(现代方式,推荐)
基于椭圆曲线迪菲-赫尔曼(ECDHE),双方临时生成密钥对,通过数学计算得到共享密钥。
优点:
每次会话密钥不同(前向安全)。
即使私钥泄露,历史会话也无法解密。
结论:
HTTPS 采用 非对称加密协商密钥 + 对称加密传输数据,既保证了安全性,又提升了性能。单纯使用非对称加密无法满足实际需求。
1.4 既然 HTTPS 通信是加密的,为什么抓包工具如 Fiddler 可以看到明文?
HTTPS 通信本身是加密的,但抓包工具(如 Fiddler、Charles、Wireshark)能够看到明文数据,是因为它们使用了 中间人攻击(Man-in-the-Middle, MITM) 的方式,在客户端和服务器之间充当了一个"代理",从而解密 HTTPS 流量。以下是详细解释:
- HTTPS 加密的基本原理
HTTPS 使用 TLS/SSL 加密通信,确保数据在传输过程中不被窃听或篡改。正常情况下:
客户端 和 服务器 协商一个 对称加密密钥(如 AES),后续通信使用该密钥加密。
中间人(如黑客) 无法直接解密数据,因为不知道密钥。
- 为什么 Fiddler 能解密 HTTPS?
Fiddler 本质上是一个 HTTPS 代理,它通过以下方式解密流量:
(1) 安装自定义根证书(CA 证书)
Fiddler 会在你的电脑上安装一个 自签名的根证书(CA 证书),并让操作系统信任它。
这样,Fiddler 可以 冒充目标网站,伪造 HTTPS 证书。
(2) 拦截 HTTPS 请求并重新加密
客户端(浏览器) 发起 HTTPS 请求时,Fiddler 会拦截它,并 假装自己是目标服务器。
Fiddler 用自己的 CA 证书 动态生成一个假的 HTTPS 证书 返回给客户端。
客户端信任 Fiddler 的 CA 证书,因此接受这个假证书,并和 Fiddler 建立加密连接。
Fiddler 再用真正的证书和服务器建立另一个 HTTPS 连接,解密客户端的数据后,再加密转发给服务器。
(3) 解密并显示明文
Fiddler 同时知道 客户端 ↔ Fiddler 和 Fiddler ↔ 服务器 的加密密钥,因此可以解密所有流量,并显示明文数据。
结论:
Fiddler 能解密 HTTPS 是因为你主动信任了它的 CA 证书,让它成为"受信任的中间人"。
真正的 HTTPS 通信(如浏览器访问银行网站)仍然是安全的,因为外部攻击者无法伪造证书。
如果你不想被监控,不要随意安装未知的 CA 证书。
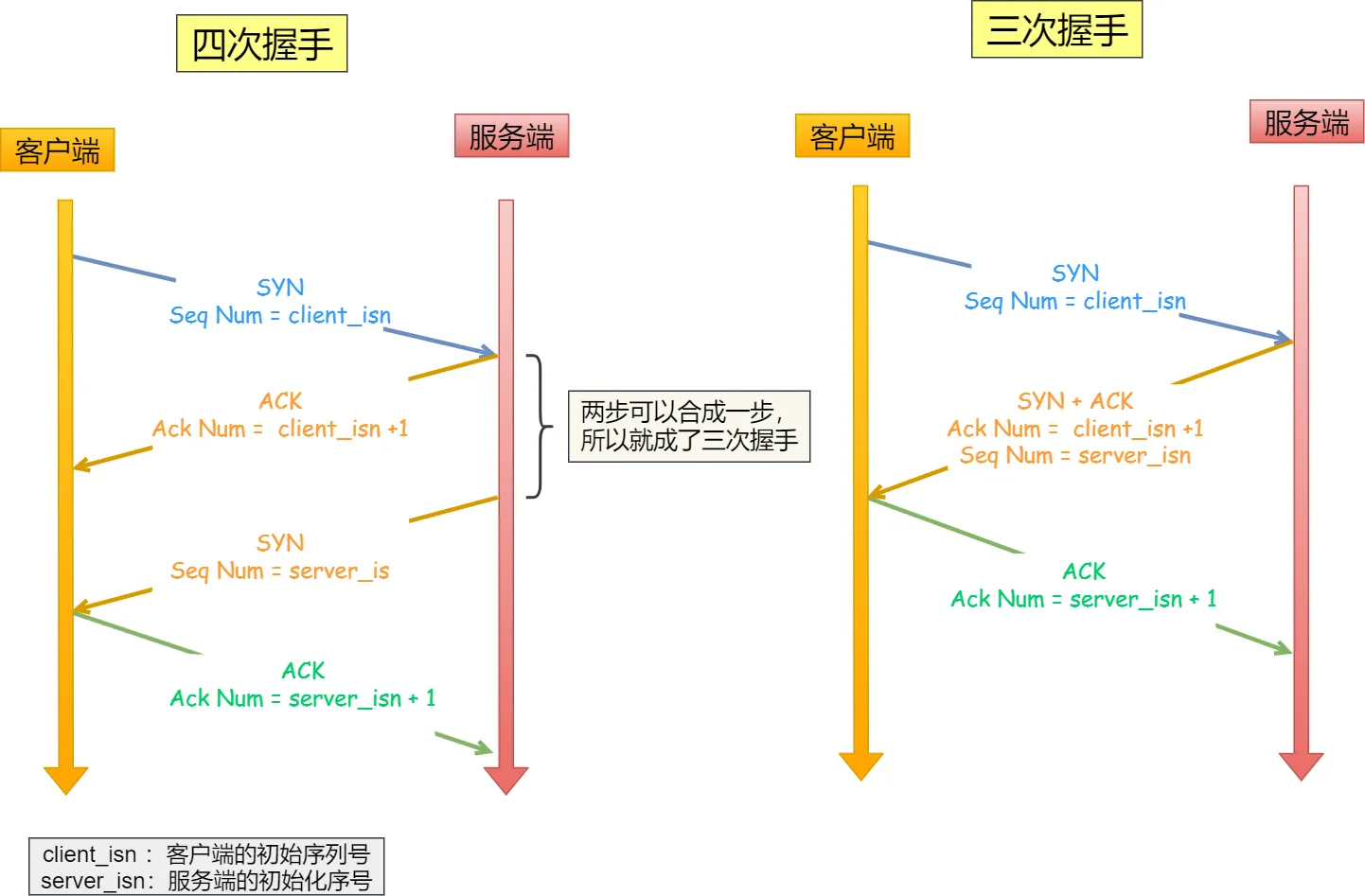
1.5 TCP 3 次握手的过程? 2 次或者 4 次行不行?
- 3 次握手的过程?
TCP 使用 三次握手 建立可靠连接,确保双方都能正常收发数据。过程如下:
- SYN(同步)
客户端 → 服务器:发送 SYN=1, seq=x(随机序号)。
含义:"我想建立连接,我的初始序号是 x。"
- SYN-ACK(同步确认)
服务器 → 客户端:发送 SYN=1, ACK=1, seq=y, ack=x+1。
含义:"我同意连接,我的初始序号是 y,你的 x+1 我收到了。"
- ACK(确认)
客户端 → 服务器:发送 ACK=1, seq=x+1, ack=y+1。
含义:"确认收到你的 y,我们可以通信了。"
握手完成后,连接建立,开始传输数据。
注意:第三次握手是可以携带数据的,前两次握手不可以携带数据。
- 为什么不能是 2 次握手?
如果只有两次握手(SYN → SYN-ACK),会引发历史连接问题:
问题场景:
客户端发送的 SYN 因网络延迟,超时重传了一个新 SYN。
如果服务器收到旧 SYN 后直接建立连接,但客户端早已放弃,导致服务器一直等待无用连接。
三次握手解决:
客户端通过第三次 ACK 确认自己真正需要连接,避免资源浪费。
- 为什么不能是 4 次握手?
四次握手其实也能够可靠的同步双方的初始化序号,但由于第二步和第三步可以优化成一步,所以就成了「三次握手」。
1.6 TCP 四次挥手的过程?
TCP 使用四次挥手安全关闭连接,确保双方数据完整传输并释放资源。以下是详细流程(假设客户端主动关闭):
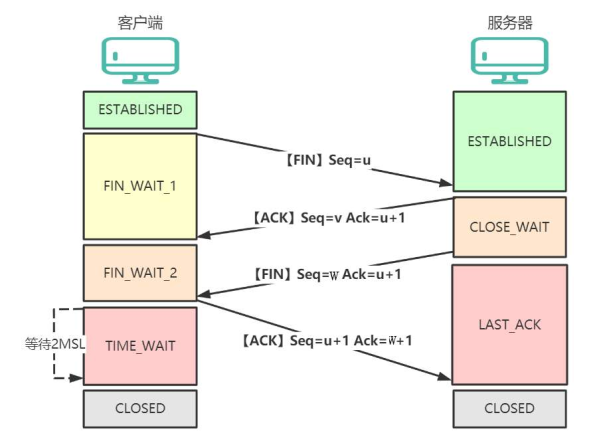
第一次挥手:客户端主动调用关闭连接的函数,发送 FIN 报文,客户端进入 FIN_WAIT_1 状态。
第二次挥手:服务端收到了 FIN 报文,然后马上回复一个 ACK 报文,服务端进入 CLOSE_WAIT 状态。
第三次挥手:服务端应用程序发送完数据后,调用关闭连接的函数发一个 FIN 报文,服务端进入 LAST_ACK 状态。
第四次挥手:客户端接收到服务端的 FIN 包,并发送 ACK 确认报文给服务端,此时客户端将进入 TIME_WAIT 状态。
服务端收到 ACK 确认报文后,就进入了最后的 CLOSED 状态。
客户端经过 2MSL 时间之后,也进入 CLOSED 状态。
1.7 TCP 3 次挥手可以吗?
可以。
四次挥手把同意对方请求跟自身请求分离开。是因为在客户端请求断开时(客户端发送端->服务器接收端),服务器可能还有数据未发完,所以需要分开操作。
如果服务器端收到客户端的FIN后,服务器并没有数据需要发送,可以把ACK和FIN合并到一起发送,节省了一个报文,变成了"三次挥手"。
当被动关闭方(上图的服务端)在 TCP 挥手过程中,「没有数据要发送」并且「开启了 TCP 延迟确认机制」,那么第二和第三次挥手就会合并传输,这样就出现了三次挥手。
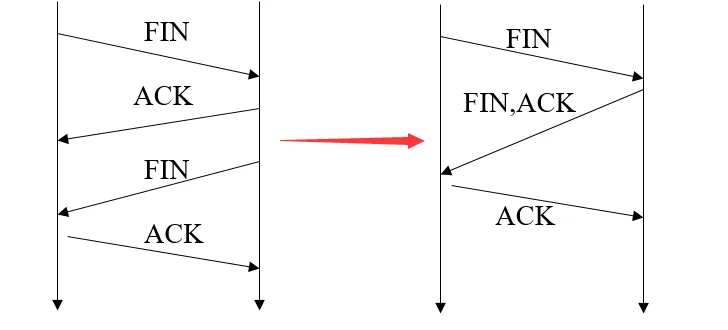
注意:然后因为 TCP 延迟确认机制是默认开启的,所以导致我们抓包时,看见三次挥手的次数比四次挥手还多。
4.22 TCP 四次挥手,可以变成三次吗? - 小林coding
1.8 为什么需要延迟确认?
- 基本概念
TCP 延迟确认(Delayed ACK)是一种优化技术,通过推迟发送确认报文(ACK),减少网络中小数据包的数量,从而提高传输效率。其核心逻辑是:
不立即回复 ACK,而是等待一段时间(通常 200ms),看是否有数据需要捎带(Piggybacking)一起发送。
如果在等待期间有数据要发送,则 ACK 会附带在数据包中,避免单独发送 ACK 报文。
- 减少小包问题
每个 ACK 报文至少占用 40 字节(IPv4 + TCP 头),单独发送 ACK 会导致网络充斥小包,降低效率。
利用捎带确认:
如果接收方有数据要回复(如 HTTP 响应),可以将 ACK 和数据合并发送,节省带宽。
适应交互式应用:
如 SSH、数据库查询等场景,请求和响应成对出现,延迟 ACK 能自然合并报文。
- 延迟确认的工作机制
- 默认延迟时间:通常为 200ms(Linux 默认值,Windows 可能为 100ms)。
- 触发条件:
- 每接收 2 个数据包 必须发送一个 ACK(RFC 1122 规定)。
- 如果延迟期间有数据要发送,则 ACK 捎带在数据包中。
- 超时(如 200ms)后仍未发送数据,则单独发送 ACK。
示例场景:
- 客户端发送数据包 Seq=100。
- 服务器收到后不立即回复 ACK,而是等待:
- 若 200ms 内服务器需发送数据(如 Seq=200),则合并为 ACK=101 + Seq=200。
- 若超时,则单独发送 ACK=101。
- 延迟确认与 Nagle 算法的关系
- Nagle 算法:发送端的优化,缓冲小数据包,等待 ACK 或足够数据再发送。
- 交互问题:
若发送端启用 Nagle,接收端启用延迟 ACK,可能导致 死锁:
○ 发送方等 ACK 才发下一包,接收方等数据才捎带 ACK。
○ 解决方案:禁用其中之一(如 HTTP 服务通常禁用 Nagle)。
- 总结
● 延迟确认是 TCP 的性能优化,通过合并 ACK 减少小包,但可能增加延迟。
● 默认延迟 200ms,每 2 个数据包必须确认一次。
● 实时场景需谨慎:可禁用延迟确认或调整超时时间。
● 与 Nagle 算法可能冲突,需根据业务场景权衡配置。
关键点:延迟确认体现了 TCP 在可靠性和效率之间的平衡,理解其机制有助于优化高并发或低延迟网络服务。
1.9 服务端可以主动发起断开连接吗?
可以。
"TCP 连接是双向的,服务端和客户端都能主动发 FIN 断开。只不过在 HTTP 等协议中,客户端通常先发起关闭,但服务端在长连接超时或维护时也会主动断开。"
关键点:TCP 设计上没有主从之分,谁先调 close() 谁先发 FIN。
1.10 客户端回复服务端断开请求 ACK 报文后会进入什么状态?
当客户端收到服务端的 FIN 并回复 ACK 后,会进入 TIME_WAIT 状态(等待 2MSL 时间后才彻底关闭)。
为什么需要 TIME_WAIT?
这么做有两个原因:
- 确保最后一个 ACK 可靠到达(防止连接异常终止)
问题:如果主动关闭方(客户端)发送的最终 ACK 丢失,被动关闭方(服务端)会因未收到确认而重传 FIN。
作用:TIME_WAIT 期间,客户端保留连接状态,可以重新接收并响应服务端重传的 FIN(再次发送 ACK),避免服务端一直卡在 LAST_ACK 状态,导致资源无法释放。
- 丢弃旧连接延迟报文
让旧连接报文从网络中消失,避免被后面相同四元组的新连接错误地接收收到旧连接的报文。
如果不等 2MSL,释放的端口可能会重新与服务器建立连接,这样依然存活在网络里的旧连接 TCP 报文可能与新连接报文冲突,造成数据混乱。
为什么 TIME_WAIT 是 2MSL?
-
TCP 是全双工协议:需要确保双向(客户端→服务端 + 服务端→客户端)的报文均被清除。
-
1MSL 只能覆盖单向:例如,服务端的 FIN 可能在第 1 个 MSL 内到达,但客户端的 ACK 可能在第 2 个 MSL 内才彻底消失。
1.11 大量 TCP 连接状态处于 TIME_WAIT 状态会有什么问题?
如果客户端(主动发起关闭连接)存在大量 TIME_WAIT 状态连接,会占用端口资源,导致新建 TCP 连接出错,报address already in use : connect异常。
如果服务端(主动发起关闭连接)存在大量 TIME_WAIT 状态连接,并不会导致端口资源受限,因为服务端只监听一个端口,而且由于一个四元组唯一确定一个 TCP 连接,因此理论上服务端可以建立很多连接。
但是 TCP 连接过多,会占用系统资源,比如文件描述符、内存资源、CPU 资源、线程资源等。
如何解决?
(1)调整内核参数(Linux)复用处于 TIME_WAIT 的 socket 为新的连接所用。
go
# 允许复用 TIME_WAIT 状态的端口(需时间戳支持)
echo 1 > /proc/sys/net/ipv4/tcp_tw_reuse
# 增大可用端口范围
echo "1024 65535" > /proc/sys/net/ipv4/ip_local_port_range
# 减少 TIME_WAIT 超时时间(不建议,可能影响可靠性)
echo 30 > /proc/sys/net/ipv4/tcp_fin_timeout # 单位:秒(2)优化应用设计
- 使用长连接:
- HTTP/1.1 启用 Keep-Alive
- 使用 HTTP/2 多路复用
- 数据库连接使用连接池
- 连接复用:客户端复用连接而不是频繁创建新连接
2.数据库
2.1 事务的四大特性是什么?
事务的四大特性是 ACID:
- 原子性(Atomicity):事务要么全成功,要么全失败。
- 一致性(Consistency):数据符合完整性约束。
- 隔离性(Isolation):并发事务互不干扰。
- 持久性(Durability):提交后修改永久生效。
MySQL 如何实现 ACID?
- 原子性:Undo Log
- 持久性:Redo Log
- 隔离性:MVCC + 锁机制
- 一致性
- 通过应用程序和数据库约束(如主键、外键、唯一约束等)共同保证。
- 数据库自身的完整性检查机制。
- 原子性、隔离性和持久性的共同作用来保证一致性。
2.2 MySQL 是如何实现 MVCC 的?
MVCC (Multi-Version Concurrency Control,多版本并发控制) 是 MySQL 实现高并发的重要技术,主要被 InnoDB 存储引擎使用。
核心组件:
-
隐藏字段:
- DB_TRX_ID:6字节,记录最近修改该行记录的事务ID
- DB_ROLL_PTR:7字节,指向该行记录在回滚段(undo log)中的指针
- DB_ROW_ID:6字节,隐藏的自增ID(当表没有主键时自动生成)
-
Undo Log:
- 存储数据被修改前的多个版本
- 形成版本链,通过 DB_ROLL_PTR 指针可以找到历史版本
-
ReadView:
- 快照读时生成的一致性视图
- 包含:m_ids(活跃事务ID列表)、min_trx_id(最小活跃事务ID)、max_trx_id(预分配的下一个事务ID)、creator_trx_id(创建该ReadView的事务ID)
工作流程:
-
SELECT 操作:
- 创建 ReadView
- 检查行记录的 DB_TRX_ID:
- 如果小于 min_trx_id:可见(事务已提交)
- 如果在 m_ids 中:不可见(事务未提交)
- 如果大于等于 max_trx_id:不可见(事务在ReadView之后开始)
- 通过 DB_ROLL_PTR 在 undo log 中查找可见的版本
-
INSERT/DELETE/UPDATE 操作:
- INSERT:新插入的行 DB_TRX_ID 为当前事务 ID。
- DELETE:在行记录上设置删除标记,DB_TRX_ID 为当前事务 ID。
- UPDATE:先标记原记录为删除,再插入新记录。
隔离级别实现差异:
-
READ UNCOMMITTED:不适用MVCC,直接读取最新记录
-
READ COMMITTED:每次 SELECT 都生成新的 ReadView
-
REPEATABLE READ:第一次SELECT时生成ReadView,后续复用
-
SERIALIZABLE:退化为基于锁的并发控制
优点:
- 读操作不加锁,读写不冲突
- 通过版本链实现非阻塞读
- 提高了并发性能
MVCC 是 MySQL 实现高并发的重要技术,通过维护数据的多个版本,实现了读操作不需要等待写操作完成,大大提高了数据库的并发性能。
2.3 MVCC 的 undo 日志是什么时候清理的?
Undo 日志是 MVCC 实现多版本控制的关键组件,它的清理时机直接影响数据库性能和存储空间利用率。以下是 Undo 日志清理的主要时机和规则:
核心清理时机:
- 事务提交时不会立即清理
- 即使事务已经提交,对应的 Undo 日志也不会立即删除
- 因为可能还有其他事务需要通过这些 Undo 日志访问旧版本数据
- 当没有任何活跃事务需要该版本时
- 当系统中没有比 Undo 日志关联的事务更早的活跃事务时
- 通过 ReadView 的 m_ids 列表和 min_trx_id 判断
具体清理规则:
-
通过 purge 线程异步清理
- InnoDB 有专门的 purge 线程负责清理不再需要的 Undo 日志
- 避免同步清理影响事务性能
-
基于系统活跃事务列表判断
- 维护一个全局活跃事务列表
- 当某个 Undo 日志关联的事务 ID 小于当前所有活跃事务的最小 ID 时,该 Undo 日志可被清理
-
长事务会阻止 Undo 清理
-如果有长时间运行的事务存在,它会阻止比它晚的事务的 Undo 日志被清理
- 这是长事务导致数据库存储膨胀的主要原因
相关参数控制:
- innodb_purge_threads:控制 purge 线程数量
- innodb_max_purge_lag:当 purge 滞后时的最大延迟
- innodb_purge_batch_size:每次 purge 操作处理的数量
特殊情况处理:
-
回滚段重用
- 当 Undo 日志被清理后,对应的回滚段空间会被标记为可重用
- 但物理空间不会立即释放给操作系统
-
系统表空间中的 Undo
- MySQL 8.0 之前,系统表空间中的 Undo 日志即使被清理,空间也不会收缩
- MySQL 8.0+ 支持独立的 Undo 表空间,可以单独收缩
最佳实践:
- 避免长事务,减少 Undo 日志堆积
- 监控 history_list_length 指标,了解待清理的 Undo 日志数量
- 在 MySQL 8.0+ 中使用独立的 Undo 表空间便于管理
Undo 日志的清理是 InnoDB 自动管理的,但理解其机制有助于优化数据库性能和存储使用。
2.4 MySQL 索引数据结构是什么?
MySQL 主要使用 B+树 作为索引的基础数据结构,但根据不同的存储引擎和索引类型,也会使用其他数据结构。
B+树索引(最核心的索引结构)
- 使用场景:InnoDB/MyISAM 的默认索引类型,适用于主键索引和二级索引
- 结构特点:
- 多叉平衡树,所有数据都存储在叶子节点
- 非叶子节点只存储键值和子节点指针
- 叶子节点通过指针连接形成有序链表
- 优势:
- 适合范围查询(>、<、BETWEEN)
- 查询效率稳定(O(log n))
- 支持全键值、键值范围和前缀查找
还有哪些数据结构可以作为索引?
- 哈希索引
- 使用场景:Memory 存储引擎的默认索引,InnoDB 的自适应哈希索引
- 结构特点:
- 基于哈希表实现
- 精确匹配效率极高(O(1))
- 限制:
- 不支持范围查询
- 不支持排序
- 存在哈希冲突问题
- 全文索引(FULLTEXT)
- 使用场景:文本内容的搜索
- 实现方式:
- InnoDB 使用倒排索引
- MyISAM 也支持全文索引
- R-Tree(空间索引)
- 使用场景:地理空间数据(GIS)
- 支持函数:ST_Contains(), ST_Within() 等
2.5 MySQL 为什么用 B+ 树,不用 B 树?
核心差异对比:
| 特性 | B 树 | B+ 树 |
|---|---|---|
| 数据存储位置 | 所有节点都可能存储数据 | 只有叶子节点存储完整数据 |
| 非叶子节点内容 | 存储键值和数据指针 | 只存储键值和子节点指针 |
| 叶子节点连接 | 不连接 | 通过指针连接成有序链表 |
| 查找稳定性 | 不稳定(可能在非叶子节点找到) | 稳定(必须查找到叶子节点) |
| 范围查询效率 | 较低 | 极高 |
选择 B+ 树的六大关键原因:
- 更优的磁盘 I/O 性能
-
B+ 树的非叶子节点不存储数据,所以每个节点可以容纳更多的键值
-
相同数据量下,B+ 树比 B 树更"矮胖",通常只需要 3-4 层就能存储大量数据
-
减少磁盘 I/O 次数(每次 I/O 读取一个节点)
- 更高效的范围查询
-
叶子节点形成有序链表,范围查询只需找到起始点然后顺序遍历
-
B 树做范围查询需要在不同层级的节点间来回跳转,效率低下
-
例如查询 WHERE id BETWEEN 100 AND 300,B+ 树性能显著优于 B 树
- 更稳定的查询性能
-
B+ 树所有查询都要走到叶子节点,时间复杂度稳定为 O(log n)
-
B 树可能在中间节点就找到数据,导致查询时间不稳定
- 更高的缓存命中率
B+ 树的非叶子节点只存索引键,可以缓存更多非叶子节点在内存中
例如 16KB 的页大小,B+ 树能缓存更多索引键,减少磁盘访问
- 更适合数据库场景
数据局部性原理:B+ 树将实际数据集中在叶子节点,相邻数据物理上也更接近
全表扫描效率:B+ 树只需遍历叶子节点链表即可完成全表扫描,而 B 树需要遍历整棵树
- 更低的维护成本
B+ 树的插入和删除操作更简单,因为数据只在叶子节点修改
B 树可能在任意节点修改数据,导致更复杂的树结构调整
何时 B 树更合适?
虽然 B+ 树更适合数据库索引,但 B 树在某些场景仍有优势:
- 内存数据库(如 Redis):不需要考虑磁盘 I/O,B 树的随机访问优势更明显
- 键值存储系统:如果只做单点查询,B 树的平均查找路径可能更短
MySQL 的选择体现了工程上的权衡:B+ 树在磁盘存储、范围查询和稳定性方面的优势,使其成为关系型数据库索引的理想数据结构。
2.6 什么情况下会导致索引失效?
索引失效会导致查询性能急剧下降,以下是导致 MySQL 索引失效的主要情况和具体示例:
- 最左前缀违规
复合索引(a,b,c),但查询WHERE b=1
- 对索引列计算
WHERE age+1>20 或 YEAR(date_col)=2023
- 类型不匹配
字符串字段用数字查:WHERE varchar_col=123
- LIKE左模糊
WHERE name LIKE '%张'(右模糊'张%'可用索引)
- 使用不等于(!= / <> / NOT IN)
sql
WHERE status!=1 或 id NOT IN(1,2,3)- OR条件混用
sql
WHERE id=1 OR unindexed_col=2(全失效)优化方式:
sql
-- 改为UNION ALL
SELECT * FROM table WHERE id = 1
UNION ALL
SELECT * FROM table WHERE name = '张三'- NULL判断
sql
WHERE col IS NULL(数据量大时可能失效)- 优化器放弃
数据量少或需返回>30%数据时,直接全表扫描更快
🔍 检查方法:EXPLAIN查看执行计划,出现ALL就是全表扫描。
2.7 手写 SQL: 给定用户表 user 和帖子表 post,获取帖子数前十的用户名?
方案一:使用 JOIN 和 GROUP BY。
sql
SELECT
u.username,
COUNT(p.id) AS post_count
FROM
post p
JOIN
user u ON p.user_id = u.id
GROUP BY
u.id, u.username
ORDER BY
post_count DESC
LIMIT 10;方案二:使用子查询(MySQL 8.0+ 推荐)
sql
WITH user_post_counts AS (
SELECT
user_id,
COUNT(*) AS post_count
FROM
post
GROUP BY
user_id
ORDER BY
post_count DESC
LIMIT 10
)
SELECT
u.username,
upc.post_count
FROM
user_post_counts upc
JOIN
user u ON upc.user_id = u.id
ORDER BY
upc.post_count DESC;- 先计算帖子数再关联用户表,性能可能更好
- 使用了 CTE (Common Table Expression),需要 MySQL 8.0+ 支持
3.Golang
3.1 Golang 的 GC 是怎么实现的?
Go 语言的垃圾回收器 (Garbage Collector, GC) 是一个并发、三色标记清除 (concurrent tri-color mark-sweep) 的收集器,以下是其核心实现原理:
核心设计特点:
- 并发执行:大部分 GC 工作与用户程序并行运行
- 三色标记法:基于对象可达性分析的标记算法
- 非分代:不像 Java 那样分新生代/老年代
- 写屏障 (Write Barrier):保证并发标记的正确性
- 混合回收策略:结合标记-清除和复制算法优点
三色标记算法详解:
- 三色抽象:
- 白色:未被访问的对象(待回收)
- 灰色:已访问但子对象未完全检查
- 黑色:已访问且所有子对象已检查
- 标记过程
go
初始状态:所有对象为白色
将根对象(栈/全局变量等)标记为灰色
for 灰色对象不为空 {
取出一个灰色对象
将其引用的白色对象标记为灰色
将该对象标记为黑色
}
清除阶段:回收所有白色对象并发实现关键:
- 写屏障技术:
-
在并发标记期间,当对象引用关系发生变化时
-
写屏障会捕获这些修改,确保标记正确性
-
示例屏障代码:
go
// 伪代码:写屏障操作
func writePointer(src, dst *Object) {
shade(src) // 标记源对象为灰色
*src = dst // 实际指针写入
}- 三阶段设计:
- 标记准备:STW (Stop-The-World) 很短(通常 <1ms)
- 并发标记:与用户程序并行(占用约25%CPU)
- 标记终止:短暂 STW 完成标记
GC 触发条件:
- 自动触发:堆内存达到上次GC后存活对象的倍数(默认2倍,由 GOGC 环境变量控制)。
- 手动触发:调用 runtime.GC()。
- 系统监控:超过 2 分钟未触发 GC 时强制触发。
性能优化特性:
- 逃逸分析:在编译期决定对象分配在栈还是堆
- GC 调参:
go
// 设置GC百分比(默认100)
debug.SetGCPercent(100)
// 设置并行标记使用的CPU核心数
debug.SetMaxThreads(4)演进历史:
- Go 1.5:引入并发GC,STW从秒级降到毫秒级
- Go 1.8:STW优化到亚毫秒级别(<1ms)
- Go 1.12:优化内存释放延迟
- Go 1.14:进一步减少STW时间
- Go 1.18:优化大型堆的表现
与 Java GC 对比:
| 特性 | Go GC | Java GC |
|---|---|---|
| 并发性 | 完全并发 | 部分并发 |
| 分代 | 无 | 有 |
| STW时间 | 亚毫秒级 | 通常较长 |
| 调优复杂度 | 简单(参数少) | 复杂(多种收集器) |
Go 的 GC 设计追求简单性和低延迟,适合需要快速响应的服务端应用,但吞吐量可能不如分代式GC。
3.2 为什么是三色标记,两色不行吗?
Go 的垃圾回收器采用三色标记算法而非传统的两色标记,主要是为了解决并发标记过程中的对象状态一致性问题。
引入灰色作为中间状态:
- 白色:未扫描
- 灰色:已发现但未扫描其引用
- 黑色:已完全扫描
结合写屏障的解决方案:
go
// 写屏障伪代码
func writePointer(src, dst *Object) {
if src是黑色 && dst是白色 {
dst标记为灰色 // 保存这个可能丢失的对象
}
*src = dst // 执行实际写操作
}强三色不变式:
- 强制约束:黑色对象不能直接指向白色对象。
- 通过写屏障维护这个不变式。
为什么不能只用两色?
- 缺乏中间状态:
- 两色系统无法区分"已发现但未处理"和"已处理完"的对象
- 导致必须STW(Stop-The-World)来保证一致性
- Go 的设计目标:
- 追求低延迟(亚毫秒级暂停)
- 需要支持高并发
- 这些目标使得两色标记完全不适用
三色标记通过引入灰色这个"中间状态",配合写屏障机制,使Go能在极短STW的情况下实现并发垃圾回收,这是 Go GC 设计的精髓所在。
4.问题定位
4.1 如何定位服务器 CPU 占用率过高的问题?
快速诊断流程:
- 确认 CPU 负载情况
go
top -c # 实时查看进程CPU占用(按P排序)
htop # 更友好的交互式查看(需安装)
mpstat -P ALL 1 # 查看每个CPU核心的使用情况
sar -u 1 3 # 查看CPU历史利用率(需安装sysstat)- 识别问题进程
shell
ps -eo pid,user,%cpu,%mem,cmd --sort=-%cpu | head -n 10深入分析工具:
- 针对 Golang 应用
- 使用 go tool pprof 分析 CPU 和内存的性能数据,如内存泄露,协程泄露等。
shell
# 获取运行中程序的性能数据(无需重启)
curl http://localhost:6060/debug/pprof/profile?seconds=30 > cpu.pprof- 针对 Linux 通用进程
shell
# 查看线程级CPU占用
pidstat -t -p <pid> 1 5
# 系统调用分析
strace -p <pid> -c -T
perf top -p <pid> # 性能分析- 容器环境
shell
# 查看容器进程
docker stats
docker top <container_id>
# 进入容器分析
docker exec -it <container_id> /bin/bash常见问题场景诊断:
- Goroutine 泄露
go
// 在代码中定期输出goroutine数量
go func() {
for {
log.Printf("goroutine count: %d", runtime.NumGoroutine())
time.Sleep(5 * time.Second)
}
}()- 死循环/热路径
shell
# 使用perf定位热点
perf record -p $(pidof your_app) -g -- sleep 30
perf report -n --stdio- 锁竞争
go
import _ "net/http/pprof"
// 在main.go中导入pprof包后,访问:
// http://localhost:6060/debug/pprof/mutex5.设计题
5.1 如何限制用户 1 分钟只发送 5 个帖子?
分布式环境下使用 Redis + Lua 原子自增性和线程安全即可轻松实现。Redis 的 TTL(Time to Live) 特性完美的满足了计数器过期这一要求,将时间窗口设置为 Key 的有效时间,然后将 key 的值每次请求+1即可。
固定窗口计数器设计如下:
格式:rate_limit:{资源}:{用户标识}:{时间窗口标识}
示例:
rate_limit:post:user_12345:202308151230 (年月日时分)
rate_limit:api:ip_1.2.3.4:171543 (分钟数取模)
go
// 1.判断是否存在该key
if(EXIST(key)){
// 1.1 自增后判断是否大于最大值,并返回结果
if(INCR(key) > maxPermit){
return false;
}
return true;
}
// 2.不存在 key 则设置 key 初始值为 1,失效时间为 1 秒
SET(key, 1);
EXPIRE(key, 1);5.2 使用计数器会有什么问题?有更好的办法吗?
固定窗口计数器实现简单但存在窗口边界突增问题。
在 Redis 中实现滑动窗口限流,有序集合(ZSET)来存储帖子 ID,score 为秒级时间戳。
以下为 Lua 版本。
lua
local key = KEYS[1]
local limit = tonumber(ARGV[1])
local window = tonumber(ARGV[2])
local now = tonumber(ARGV[3])
local id = ARGV[4]
-- 移除时间窗口外的记录
redis.call('ZREMRANGEBYSCORE', key, 0, now - window)
-- 获取当前请求数
local count = redis.call('ZCARD', key)
if count >= limit then
return 0 -- 限流
end
-- 添加新记录
redis.call('ZADD', key, now, id)
redis.call('EXPIRE', key, window/1000 + 1) -- 设置稍长的TTL
return 1 -- 允许6.编程题
6.1 找出 Top2 的数
给定一个无序整数数组(可能重复),不使用额外空间和额外变量,且不能修改数组中的数,找出 Top2 的数。
如果没有找到,返回 error。
go
// 返回 5 和 4
5 4 3 2 1
// 返回 5 4
4 5
// 返回 error
5思路:
- 如果数组长度小于 2 返回 error。
- 使用数组前两个位置来存储 Top2 的数。
- 遍历后续所有的数,与 Top2 数做比较。
- 对于每个元素:
- 如果大于 nums0,则先将 nums0 与 nums1交换,然后 nums0 与元素交换。
- 如果大于 nums1,则 nums1 与元素交换。
- 最终返回 nums0 和 nums1。
实现示例:
go
// Top2Nums 找出无序数组中的 Top2 的数。
// 不使用额外空间和额外变量,且不能修改数组中的数。
func Top2Nums(nums []int) (int, int, error) {
if len(nums) < 2 {
return 0, 0, errors.New("array length must be at least 2")
}
// 确保 nums[0] >= nums[1]
if nums[0] < nums[1] {
nums[0], nums[1] = nums[1], nums[0]
}
// 从第三个元素开始遍历
for i := 2; i < len(nums); i++ {
if nums[i] > nums[0] {
// 交换 nums[0] 和 nums[1]
nums[0], nums[1] = nums[1], nums[0]
// 交换 nums[0] 和当前元素
nums[0], nums[i] = nums[i], nums[0]
} else if nums[i] > nums[1] {
// 交换 nums[1] 和当前元素
nums[1], nums[i] = nums[i], nums[1]
}
}
return nums[0], nums[1], nil
}
// top2nums_test.go
func TestTop2Nums(t *testing.T) {
type args struct {
nums []int
}
tests := []struct {
name string
args args
want int
want1 int
wantErr bool
}{
{
"1",
args{
[]int{1, 2, 3, 4, 5},
},
5,
4,
false,
},
{
"2",
args{
[]int{1, 2},
},
2,
1,
false,
},
{
"3",
args{
[]int{1},
},
0,
0,
true,
},
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
got, got1, err := Top2Nums(tt.args.nums)
if (err != nil) != tt.wantErr {
t.Errorf("Top2Nums() error = %v, wantErr %v", err, tt.wantErr)
return
}
if got != tt.want {
t.Errorf("Top2Nums() got = %v, want %v", got, tt.want)
}
if got1 != tt.want1 {
t.Errorf("Top2Nums() got1 = %v, want %v", got1, tt.want1)
}
})
}
}6.2 找出比左边大比右边小的数
算法: 给定一个数组,找到所有比左边大,比右边小的数? 时间复杂度 O(n)。