书接上文,在上一篇文章《万字长文:彻底掌握 Go 1.23 中的迭代器------使用篇》 中,我们一起入门了 Go 迭代器。本篇文章,我们一起继续深入探究迭代器内部原理,让你彻底掌握 Go 迭代器。
迭代器原理
现在,我们是时候来学习一下 Go 迭代器的原理了,让我们更进一步,探究迭代器的本质,以此来彻底掌握 Go 迭代器特性。
迭代器是一个高阶函数,它接收一个函数(yield)作为参数,其签名为以下三个函数类型之一:
go
func(func() bool)
func(func(V) bool)
func(func(K, V) bool)迭代器函数用于控制 for-range 时的迭代过程,for-range 可以启动一个迭代器,迭代器通过调用 yield 函数,将每个值(迭代器内部产生的值)传递给调用者(for-range 循环),for-range 内部的逻辑定义了 yield 函数内部应该如何处理每一个值,如果 for-range 代码块中存在 break、continue、return 等终止语句,那么 yield 函数就会返回 false,否则返回 true。
上面这句话实际上就是 Go 迭代器的大致迭代流程,但这段解释有点绕,你一定要多读几遍,加深理解。
我们以如下代码为例,讲解迭代器的底层原理:
go
package main
import (
"fmt"
)
func iterator(slice []int) func(yield func(i, v int) bool) {
return func(yield func(i int, v int) bool) {
for i, v := range slice {
if !yield(i, v) {
return
}
}
}
}
func main() {
s := []int{1, 2, 3, 4, 5}
for i, v := range iterator(s) {
if i == 3 {
break
}
fmt.Printf("%d => %d\n", i, v)
}
}这是一个支持输出两个值的迭代器,我们在前文中其实已经见过了。
执行示例代码,得到输出如下:
bash
$ go run main.go
0 => 1
1 => 2
2 => 3这个结果符合预期。
Go 迭代器最让人迷惑的点就是,iterator(s) 返回的明明只是一个普通函数 func(yield func(i int, v int) bool),它为什么就能过被迭代呢?
甚至我们把一个符合迭代器类型的空函数交给 for-range 迭代,Go 程序都不会报错。
示例如下:
go
package main
import (
"fmt"
)
func iterator(func() bool) {}
func main() {
i := 0
for range iterator {
fmt.Printf("i=%d\n", i)
i++
}
}其实,Go 编译器为我们隐藏了真相。当 for-range 要迭代的对象,是一个迭代器函数时,Go 编译器在编译 Go 代码时,会重写 for-range 语句。
也就是说,如下这段代码,在编译期间,Go 编译器会帮我们进行代码重写:
go
for i, v := range iterator(s) {
if i == 3 {
break
}
fmt.Printf("%d => %d\n", i, v)
}这段 for-range 代码片段,会被重写成如下代码:
go
iterator(s)(func(i, v int) bool {
if i == 3 {
return false
}
fmt.Printf("%d => %d\n", i, v)
return true
})所以,最终 Go 编译器内部的代码应该长这样:
go
package main
import (
"fmt"
)
func iterator(slice []int) func(yield func(i, v int) bool) {
return func(yield func(i int, v int) bool) {
for i, v := range slice {
if !yield(i, v) {
return
}
}
}
}
func main() {
s := []int{1, 2, 3, 4, 5}
iterator(s)(func(i, v int) bool {
if i == 3 {
return false
}
fmt.Printf("%d => %d\n", i, v)
return true
})
}执行示例代码,得到输出如下:
bash
$ go run main.go
0 => 1
1 => 2
2 => 3这个输出,与直接使用 for-range 对迭代器进行迭代时一致。
不过这段代码看起来稍微有点绕,咱们换种写法,就更清晰了:
go
package main
import (
"fmt"
)
func iterator(slice []int) func(yield func(i, v int) bool) {
return func(yield func(i int, v int) bool) {
for i, v := range slice {
if !yield(i, v) {
return
}
}
}
}
func yield (i, v int) bool {
if i == 3 {
return false
}
fmt.Printf("%d => %d\n", i, v)
return true
}
func main() {
s := []int{1, 2, 3, 4, 5}
iterator(s)(yield)
}这里把 for-range 内部的逻辑迁移了出去,封装成了一个叫 yield 的函数。
而调用 iterator(s) 会返回一个新的函数 func(yield func(i int, v int) bool)。
所以 iterator(s)(yield) 这句代码,实际上是在调用 iterator 函数后,又直接调用了 iterator(s) 返回的函数。
而 iterator(s) 返回的这个函数 func(yield func(i int, v int) bool) 的参数刚好就是 yield 函数。
结合代码仔细阅读一下上面这几句话,确保能够完全理解,再接着向下阅读。
我在前文中说过,for-range 内部的逻辑定义了 yield 函数内部应该如何处理每一个值,如果 for-range 代码块中存在 break、continue、return 等终止语句,那么 yield 函数就会返回 false,否则返回 true。
这里也证实了,for-range 语句块中的代码逻辑,实际上是会被重写到 yield 函数中的,并且 break 会被重写成 return false。
而被重写后的代码执行结果不变,所以,迭代器仅仅是 Go 语言为我们提供的语法糖或者说障眼法罢了,Go 代码执行 for-range iterator 时,实际上还是函数调用。
那么,至此迭代器的逻辑是不是就彻底理通了呢?
且慢,事情并没有看起来这么简单。
其实我在上面展示的 Go 编译器重写后的代码并不足够准确,它只是一个精简版本,不过对我们理解 Go 迭代器底层原理来说,已经足够了。
我们重写后的 yield 函数,只考虑了 break 情况,但其实 for-range 语句块中的逻辑可能还会遇到 continue、goto、return、defer、panic 等,每种情况都需要考虑进去,所以 Go 编译器重写后的 yield 函数实际上是非常复杂的。
如果你想继续深入迭代器内部原理,可以参考 github.com/golang/go/b... 。
现在我们知道了,Go 迭代器看似设计比较复杂,但其实这已经是 Go 团队努里后的结果了,实际上 Go 编译器中的实现更加复杂。
你是否还能记起前文中介绍过标准库中的 container/ring 包,它所实现的回调类型的迭代器 *Ring.Do(func(any)),是不是就跟 Go 编译器重写后的迭代器逻辑非常类似。
Push & Pull 迭代器
虽然我们已经学习了迭代器原理,但是关于 Go 迭代器的知识并没有学完,Go 的迭代器是分类型的。
截至目前,我们在前文中所提到的 Go 迭代器都被称为 Push 迭代器。这类迭代器的特点是由迭代器自身控制迭代的进度,迭代器负责迭代的逻辑,并会主动将元素推送给 yield 函数。
Go 中还有一种迭代器叫 Pull 迭代器。Pull 迭代器通过 next() 函数由调用方主动"拉取"元素,并可以通过 stop() 显式终止迭代。
接下来,我们再来学习一下 Go 中的 Pull 迭代器。
在介绍 iter 包小节,我提到过 iter 包不仅提供了 Seq 和 Seq2 两个 Push 迭代器函数签名的定义。它还提供了 Pull 和 Pull2 两个函数的实现,用来支持 Pull 类型的迭代器。
函数签名如下:
go
func Pull[V any](seq Seq[V]) (next func() (V, bool), stop func()) {
...
}
func Pull2[K, V any](seq Seq2[K, V]) (next func() (K, V, bool), stop func()) {
...
}这两个函数能够将 Push 迭代器转换成 Pull 迭代器,这也是目前 Go 中实现 Pull 迭代器的唯一途径。
顾名思义,Pull 函数用于转换 Seq 类型的 Push 迭代器,Pull2 函数则用于转换 Seq2 类型的 Push 迭代器。
这两个 Pull 迭代器函数返回的值都是两个函数 next 和 stop,next 用于获取 Pull 迭代器中的下一个值,stop 则用于主动停止迭代。当调用 next 函数时返回 false,说明迭代结束。当然,我们也可以主动调用 stop,来提前终止迭代器。
以 Pull2 为例,Pull 类型迭代器使用示例如下:
go
package main
import (
"fmt"
"iter"
)
func iterator(slice []int) func(yield func(i, v int) bool) {
return func(yield func(i int, v int) bool) {
for i, v := range slice {
if !yield(i, v) {
return
}
}
}
}
func main() {
s := []int{1, 2, 3, 4, 5}
next, stop := iter.Pull2(iterator(s))
i, v, ok := next()
fmt.Printf("i=%d v=%d ok=%t\n", i, v, ok)
i, v, ok = next()
fmt.Printf("i=%d v=%d ok=%t\n", i, v, ok)
stop()
i, v, ok = next()
fmt.Printf("i=%d v=%d ok=%t\n", i, v, ok)
}执行示例代码,得到输出如下:
bash
$ go run main.go
i=0 v=1 ok=true
i=1 v=2 ok=true
i=0 v=0 ok=false通过示例,现在你能区分 Push 迭代器和 Pull 迭代器的使用场景了吗?
我在 iter 包源码注释中,发现了 Go 官方列举了一个 Pull 迭代器的使用示例,代码如下:
go
// Pairs returns an iterator over successive pairs of values from seq.
func Pairs[V any](seq iter.Seq[V]) iter.Seq2[V, V] {
return func(yield func(V, V) bool) {
next, stop := iter.Pull(seq)
defer stop()
for {
v1, ok1 := next()
if !ok1 {
return
}
v2, ok2 := next()
// If ok2 is false, v2 should be the
// zero value; yield one last pair.
if !yield(v1, v2) {
return
}
if !ok2 {
return
}
}
}
}Pairs函数是一个适配器函数,它将单值序列(iter.Seq[V])转换为成一对值的序列(iter.Seq2[V, V])。而这中间的转换就是使用 iter.Pull 函数来实现的。也就是说,Pairs函数将一个 Push 迭代器,通过 Pull 迭代器,转换成了另一个 Push 迭代器。
我们可以通过如下方式,来使用这个 Pairs 迭代器:
go
package main
import (
"fmt"
"iter"
"slices"
)
...
func main() {
s := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
// 将切片转换为单值序列
singleSeq := slices.Values(s)
// 生成值对序列
pairSeq := Pairs(singleSeq)
// 遍历值对
for v1, v2 := range pairSeq {
fmt.Printf("(%d, %d)\n", v1, v2)
}
}执行结果如下:
bash
$ go run main.go
(0, 1)
(2, 3)
(4, 5)
(6, 7)
(8, 9)虽然 Pull 迭代器功能很强大,但目前还并不能直接作用于 for-range 来对其进行迭代。还是需要将其转换成 Push 迭代器。所以,在 Go 语言中,Pull 迭代器应用并不多。比较适合用在你想要控制迭代进度的场景。
Pull 迭代器原理
学习了 Pull 迭代器的使用,你是不是也很好奇,Pull 迭代器究竟是如何实现和运行的呢?接下来我们继续探索。
我们在前文中已经介绍了 iter 包所有导出的(exported)接口。其实在 iter 包源码中还定义了一个叫 coro 的东西。
源码如下:
go
type coro struct{}
//go:linkname newcoro runtime.newcoro
func newcoro(func(*coro)) *coro
//go:linkname coroswitch runtime.coroswitch
func coroswitch(*coro)可以看到,coro 是一个空结构体,并且还有两个相关的函数定义,它们都通过 //go:linkname 指令链接到了 runtime 包。其实,这三者的具体实现都是放在 runtime 包中的,你可以在这里 github.com/golang/go/b... 看到。
NOTE:
如果你对
//go:linkname指令不熟悉,可以参考我的文章《如何使用 go:linkname 指令访问 Go 包中的私有函数》。
runtime 包中的源码比较多,并且也不是本文重点,我们就不跳转过去查看了,不影响我们对 Pull 迭代器的讲解。
关于 coro 我们只需要知道它实际上是比 goroutine 更加轻量的一种协程实现,被称为 coroutine。这有点类似于 Python 中的协程。newcoro 用于创建一个 coroutine,coroswitch 则可以主动切换 coroutine,使当前 coroutine 让出执行权,交给其他 coroutine 去执行。
我们在使用 goroutine 时,一般不会主动切换到其他 goroutine,而是 Go 调度器自动帮我们进行 goroutine 切换。这是 goroutine 与 coroutine 在用法上的最大区别,也是我们理解 coroutine 的关键。
在网上关于 Go coroutine 的资料并不多,你可以在这 research.swtch.com/coro 看到 rsc 发表的关于 Go coroutine 的讲解。
基于以上我对 coroutine 的介绍,我们已经具备了理解 Go Pull 迭代器的前提。下面,就开始正式进入 Pull 迭代器原理的学习了。
我把 iter.Pull 函数代码压缩了一下,只保留了最精简的逻辑,并且我还为其增加了非常详细的注释,来方便你理解。
源码如下:
go
// 精简版 Pull 函数伪代码(保留核心协作逻辑)
func Pull[V any](seq Seq[V]) (next func() (V, bool), stop func()) {
// 状态变量
var (
v V // 迭代值
ok bool // 值有效性标志
done bool // 迭代结束标志
yieldNext bool // 同步标记(防止乱序调用)
)
// 创建迭代协程 G(未立即运行)
c := newcoro(func(c *coro) {
// yield 函数:G 协程逻辑
yield := func(v1 V) bool {
if done { // 已终止则不再继续
return false
}
if !yieldNext { // 确保执行流程的正确性
panic("iter.Pull: yield called again before next")
}
yieldNext = false
v, ok = v1, true // 存储当前迭代值
coroswitch(c) // 让出(yield)给主协程 F
return !done // 返回是否继续迭代
}
seq(yield) // 执行原始迭代器逻辑
var v0 V
v, ok = v0, false // v、ok 置零
done = true // 标记迭代结束
})
// next 函数:主协程 F 恢复 G 的执行
next = func() (v1 V, ok1 bool) {
if done { // 迭代已结束
return
}
yieldNext = true // 允许 G 执行 yield
coroswitch(c) // 恢复(resume)G 的执行
return v, ok // 返回 G 通过 yield 传递的值
}
// stop 函数:终止迭代
stop = func() {
if !done {
done = true // 标记终止
coroswitch(c) // 恢复 G 执行清理
}
}
return next, stop
}NOTE:
如果你了解 Python,那么其实这段代码还是比较好理解的,这非常像 Python 中的协程
await/yield操作主动让出协程。
这里,我们先就 Pull 函数中的几个概念达成共识,方便理解。
在 Pull 函数中,通过 newcoro 创建的 coroutine 对象 c,我们把它称作迭代协程 G。next 函数称为主协程 F,因为 next 本身会在主协程中被调用。stop 函数也在主协程中被调用,它用于终止迭代。这里涉及两个协程和三个函数,它们之间通过 coroswitch(c) 实现协程切换。
接下来,我就上面的 Pull 函数代码,讲解一下 Pull 迭代器执行逻辑。
首先,主协程 F 开始执行,并启动 G,但 G 不会立即运行。相反,F 必须显式地恢复(resume)G,然后 G 才会开始运行。在任意时刻,G 可以反转并让出执行权(yield)给 F。这会暂停 G 并继续 F 的执行(从 F 的 resume 操作之后开始)。最终 F 再次调用 resume,这会暂停 F 并从 G 的 yield 处继续运行 G。如此反复交替,直到 G 代码执行完成返回。这会使 G 结束,并从 F 上次的 resume 处继续运行 F,并且 G 会给 F 一个信号,G 已经完成,F 不应再尝试恢复 G。
以上,就是 Pull 迭代器执行的大致逻辑。
在这种模式中,只有一个 goroutine 在运行,主协程 F 和迭代协程 G 通过 coroswitch(c) 实现一种定义良好、协调的方式轮流执行。
如果你完全没接触过 coroutine 的概念,上面的讲解对你来说可能会有点抽象。没关系,我画了一张流程图来演示 Pull 函数的整个执行流程。
如下:
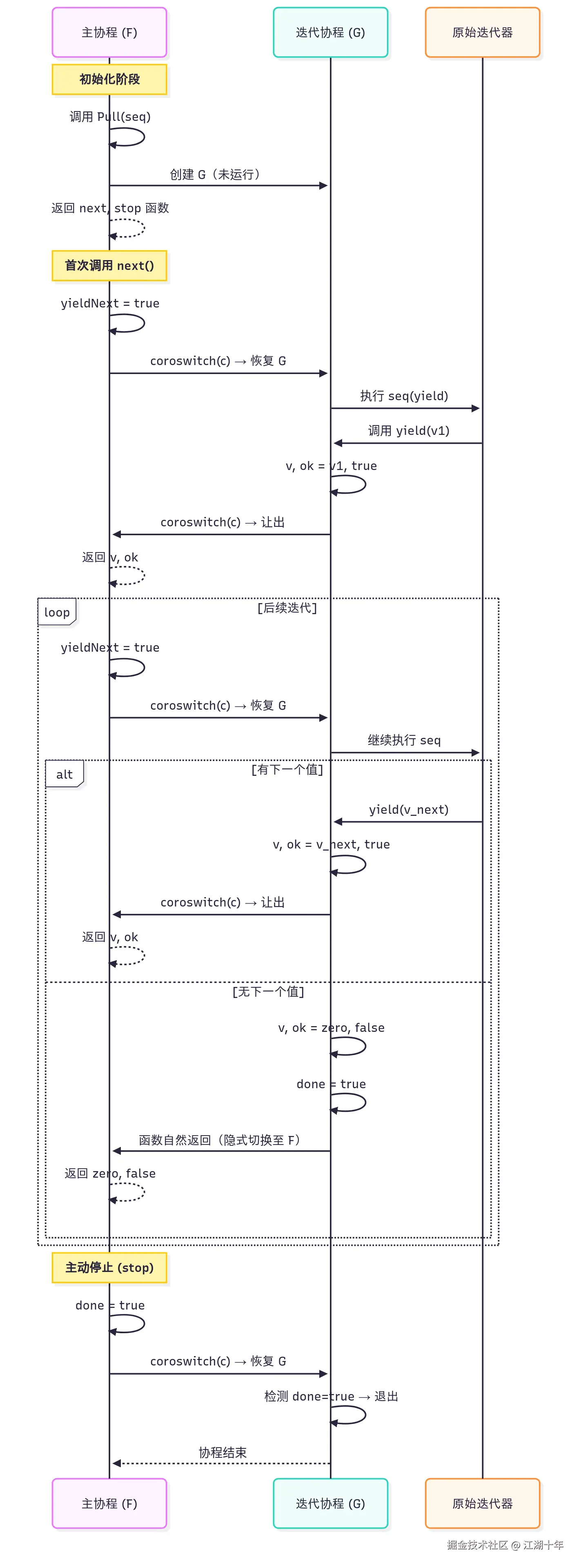
希望结合此图,你能对 Go 中的 Pull 迭代器原理有更深入的理解。
更优雅的迭代器实现
我们已经一起见识了 Go 中的迭代器,最后再对标一下其他编程语言中迭代器的实现。
Go 迭代器
如下是 Go 中迭代器的实现:
go
package main
import (
"fmt"
"iter"
)
func iterator(n int) iter.Seq[int] {
return func(yield func(v int) bool) {
for i := 0; i < n; i++ {
if !yield(i) {
return
}
}
}
}
func main() {
for v := range iterator(5) {
fmt.Println(v)
}
}这个代码想必现在的你已经非常熟悉了。
Python 迭代器
我们再来看看 Python 如何实现迭代器:
python
def generator(num: int):
for i in range(num):
yield i
for value in generator(5):
print(value)以上是 Python 中的生成器,是实现迭代器的一种方式。相较于 Go 迭代器来说,可谓简洁优雅。
Python 除了在语法层面原生支持这种生成器,其实也定义了迭代器协议,支持用户自定义迭代器,只需要为 class 实现 __iter__ 和 __netx__ 两个方法即可。
我们可以将 Go 中的 Push 迭代器对标 Python 中的生成器,Go 中的 Pull 迭代器对标 Python 中的迭代器。
JavaScript 迭代器
同 Python 一样,JavaScript 也从语法层面原生支持定义生成器函数:
javascript
function* generator(num) {
for (let i = 0; i < num; i++) {
yield i;
}
}
for (const v of generator(5)) {
console.log(v);
}可以说 JavaScript 迭代器就是照抄 Python 的,几乎一模一样。
其实总结下来可以发现,同样都是使用 yield 关键字来定义迭代器,Python 可谓优雅,JavaScript 是跟随者,Go 则是......大(一)道(言)至(难)简(尽) :)。
虽然 Go 官方做了很多努力,已经尽力将复杂交给了编译器,将简单留给用户。但我还是想吐槽一句,Go 的迭代器设计依然不够优雅。没有对比,就没有伤害。
迭代器到底在解决什么问题
我们从使用到原理剖析,一起深入学习了 Go 迭代器,同时也对比了解了 Python 和 JavaScript 迭代器,那么现在回过头来看,Go 迭代器到底在解决什么问题呢?
我认为 Go 的迭代器解决了如下两个问题:
- 统一迭代接口:解决生态碎片化问题,比如可以统一 Go 标准库的现有的迭代器的接口实现。
- 隐藏实现细节:迭代器实现了解耦遍历逻辑与数据结构,让开发者无需关心底层实现就能统一访问各种集合(数组、链表、树等)。
不过,Go 的迭代器不止在解决问题,同时也带来了新的问题。
Go 的迭代器代码看起来并不简单易懂,导致很多初学者无法写出合适的迭代器实现。这也导致社区中出现了许多反对的声音,就像 Go 泛型,虽然讨论了这么多年,设计了非常多版本的方案,但最终还是不够完美。同样,Go 迭代器设计也不够优雅,但这可能已经是当前时间节点的最佳方案了。
Go 1.23 迭代器的核心目标是想通过标准化接口,来实现将"复杂留给实现者,简洁留给使用者"。
迭代器虽然带来了一定复杂性,但是对于使用者来说,还是方便的。比如,Go 标准库和一些第三方包,实现了迭代器。那么对于我们开发者来说,只需要调用这些包中的迭代器即可。
但是,我们在编写业务代码的过程中,避免不了要实现自己的迭代器。所以说,往往迭代器的使用者和实现者,其实是同一个人,所以,迭代器的复杂性还是留给了我们 :(。
最后,我们一起来用迭代器解决一个真实的迭代场景。
准备一个 demo/main.go 文件。内容如下:
go
package main
import "fmt"
func main() {
fmt.Println("Hello World!")
}在 demo/ 同级目录中编写 Go 程序入口文件 main.go。内容如下:
go
package main
import (
"bufio"
"fmt"
"iter"
"os"
"strings"
)
// NOTE: 以一个读取文件内容的函数为例
// 实现一:一次性加载整个文件,可能出现内存溢出
func ProcessFile1(filename string) {
data, _ := os.ReadFile(filename)
lines := strings.Split(string(data), "\n") // 按换行切分
for i, line := range lines {
fmt.Printf("line %d: %s\n", i, line)
}
}
// 实现二:使用 bufio 迭代器实现
func ProcessFile2(filename string) {
file, _ := os.Open(filename)
defer file.Close()
scanner := bufio.NewScanner(file)
i := 0
for scanner.Scan() {
fmt.Printf("line %d: %s\n", i, scanner.Text())
i++
}
}
// 实现三:使用 Go 1.23 迭代器进行重构
// NOTE: 实现者
func ReadLines(filename string) iter.Seq2[int, string] {
return func(yield func(int, string) bool) {
file, _ := os.Open(filename)
defer file.Close()
scanner := bufio.NewScanner(file)
i := 0
for scanner.Scan() {
if !yield(i, scanner.Text()) { // 按需生成
return
}
i++
}
}
}
// NOTE: 使用者
// 把复杂留给实现着,把**标准**留个使用者
func ProcessFile3(filename string) {
for i, line := range ReadLines(filename) {
fmt.Printf("line %d: %s\n", i, line)
}
}
func main() {
filename := "demo/main.go"
ProcessFile1(filename)
fmt.Println("--------------")
ProcessFile2(filename)
fmt.Println("--------------")
ProcessFile3(filename)
}这个示例代码无需我过多讲解,根据代码中的注释,以及你所掌握的迭代器知识,非常容易理解。
执行示例代码,得到输出如下:
bash
$ go run main.go
line 0: package main
line 1:
line 2: import "fmt"
line 3:
line 4: func main() {
line 5: fmt.Println("Hello World!")
line 6: }
line 7:
--------------
line 0: package main
line 1:
line 2: import "fmt"
line 3:
line 4: func main() {
line 5: fmt.Println("Hello World!")
line 6: }
--------------
line 0: package main
line 1:
line 2: import "fmt"
line 3:
line 4: func main() {
line 5: fmt.Println("Hello World!")
line 6: }我们使用三种方式对 demo/main.go 文件内容进行迭代输出,都能得到正确结果。
根据输出,如果你仔细观察,还会发现,第一个迭代器有一个 line 7 的内容输出,即 demo/main.go 代码最后的空行,而另外两个迭代器都已经自行处理了空行。
现在,再回过头看一下 Go 中为什么要引入迭代器,你心中有答案了吗?
总结
本文我们一起深入探究了 Go 语言中的迭代器特性。
我们从迭代器定义,到 Go 中的迭代器发展历程和落地,再到迭代器的使用,最后到迭代器的原理。带你从头到尾的,深入研究了 Go 迭代器。
并且我们还对比了 Python 和 JavaScript 中的迭代器,让你了解不同语言迭代器实现的异同,认识到 Go 迭代器的优缺点。
其实,最终你会发现,Go 1.23 对迭代器的支持,也仅仅只是让 for-range 的迭代对象,新增支持了三种函数类型。但这足以改变 Go 社区,Go 迭代器的出现,让我们使用 for-range "迭代万物"成为可能。
虽然 Go 社区中存在很多对迭代器的反对声音,但我依然看好 Go 迭代器的未来。
本文示例源码我都放在了 GitHub 中,欢迎点击查看。
希望此文能对你有所启发。
联系我
- 公众号:Go编程世界
- 微信:jianghushinian
- 邮箱:jianghushinian007@outlook.com
- 博客:jianghushinian.cn
- GitHub:github.com/jianghushin...