目录
[1、逃逸分析(Escape Analysis)](#1、逃逸分析(Escape Analysis))
[1.3、JVM 的典型优化](#1.3、JVM 的典型优化)
[2.1、无逃逸(no escape)](#2.1、无逃逸(no escape))
[2.2、方法级逃逸(method escape)](#2.2、方法级逃逸(method escape))
[2.3、线程级逃逸(thread escape)](#2.3、线程级逃逸(thread escape))
[4、如何观察/控制(常用 JVM 参数)](#4、如何观察/控制(常用 JVM 参数))
前言
在Java的编译体系中,一个Java的源代码文件变成计算机可执行的机器指令的过程中,需要经过两段编译,第一段是把.java文件转换成.class文件。第二段编译是把.class转换成机器指令的过程。
如下所示:
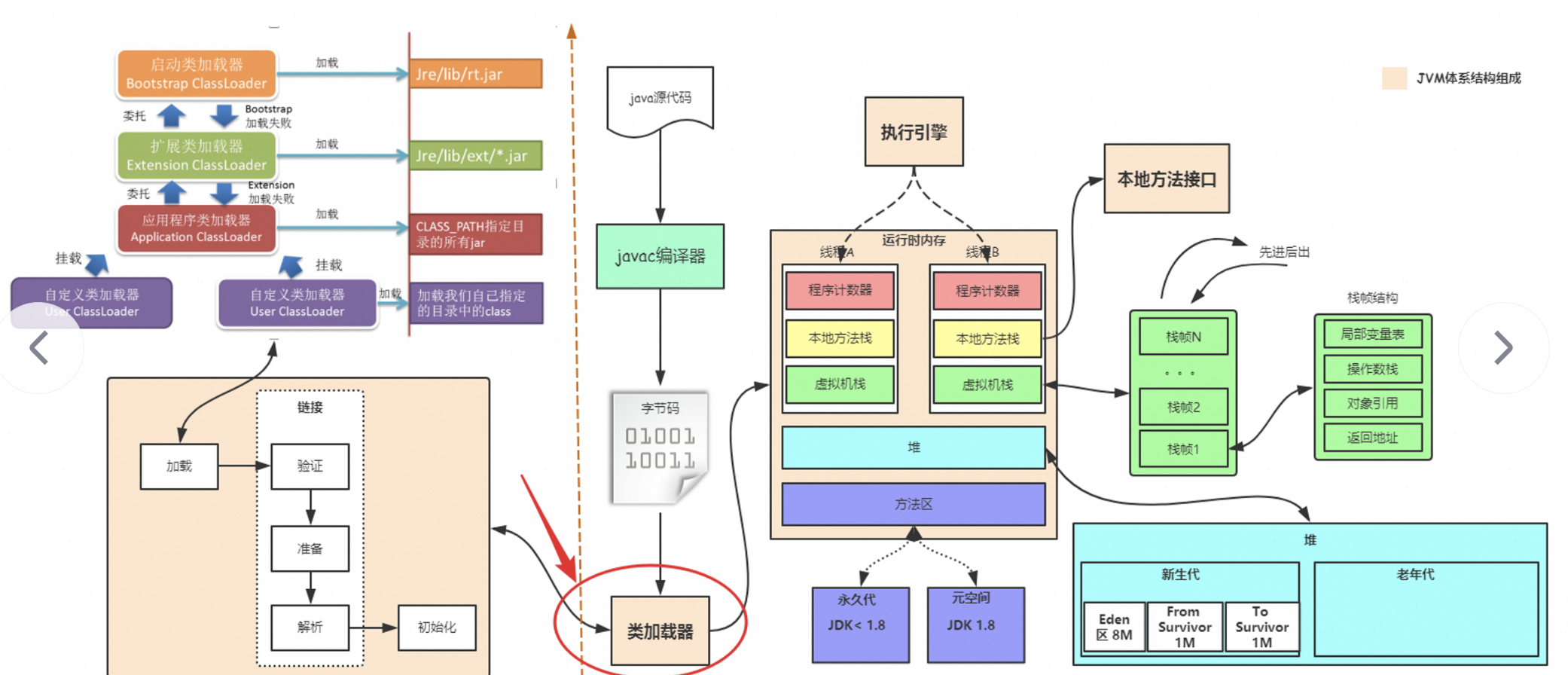
第一段编译就是javac命令。
在第二编译阶段,JVM 通过解释字节码将其翻译成对应的机器指令,逐条读入,逐条解释翻译。很显然,经过解释执行,其执行速度必然会比可执行的二进制字节码程序慢很多。这就是传统的JVM的解释器(Interpreter)的功能。为了解决这种效率问题,引入了 JIT(即时编译) 技术。
引入了 JIT 技术后,Java程序还是通过解释器进行解释执行,当JVM发现某个方法或代码块运行特别频繁的时候,就会认为这是"热点代码"(Hot Spot Code)。
如下所示:
然后JIT会把部分"热点代码"翻译成本地机器相关的机器码,并进行优化,然后再把翻译后的机器码缓存起来,以备下次使用。
如下:
java
public static StringBuffer craeteStringBuffer(String s1, String s2) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb;
}
public static String createStringBuffer(String s1, String s2) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb.toString();
}
第一段代码中的sb就逃逸了,而第二段代码中的sb就没有逃逸。逃逸分析就是 JVM 判断对象是否"会被外部引用/离开当前方法/线程"的静态分析;如果不逃逸,JVM 可以把对象在栈上分配或直接消除,从而提升性能并减小 GC 负担;如果逃逸了,则必须分配到堆并遵守多线程语义。
1、逃逸分析(Escape Analysis)
1.1、定义
逃逸分析是 JVM(JIT 编译器)的一种静态分析,用来判断某个对象的引用是否"逃出"了当前的作用域(方法/线程)。
根据分析结果,JVM 可以做一些优化:把对象分配到栈上(stack allocation)、消除对象分配(scalar replacement,把对象拆成若干局部变量,不再分配对象)或移除不必要的同步(lock elision)。
1.2、作用
- 减少 GC 压力:对象不分配到堆或被消除,减少短期垃圾回收。
- 提升性能:减少分配/回收开销、减少同步开销。
- 但不要过早微观优化:先用直观可维护的代码,再在热点处用分析工具(JMH、Profiler)验证是否需要优化或依赖逃逸分析。
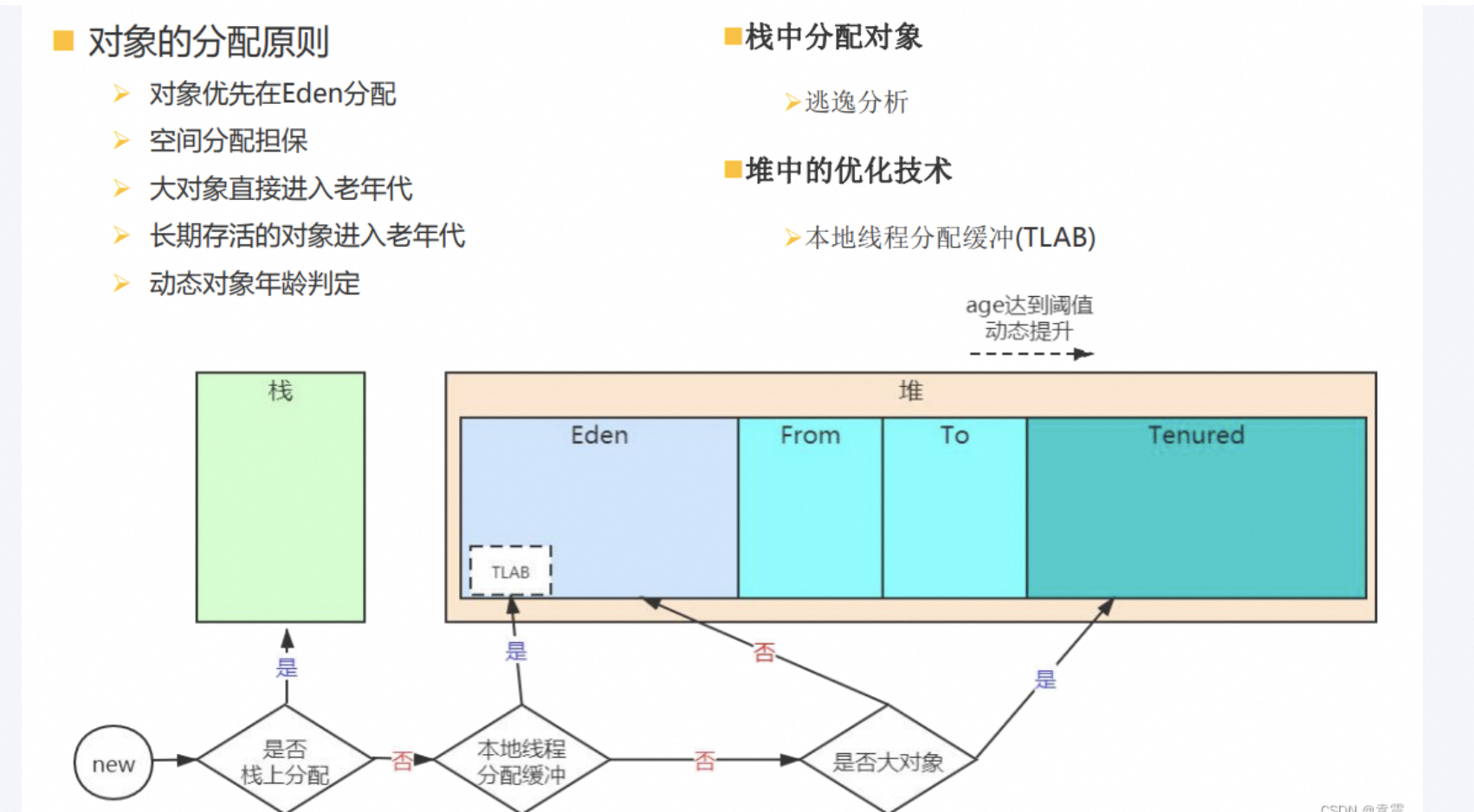
1.3、JVM 的典型优化
如下所示:
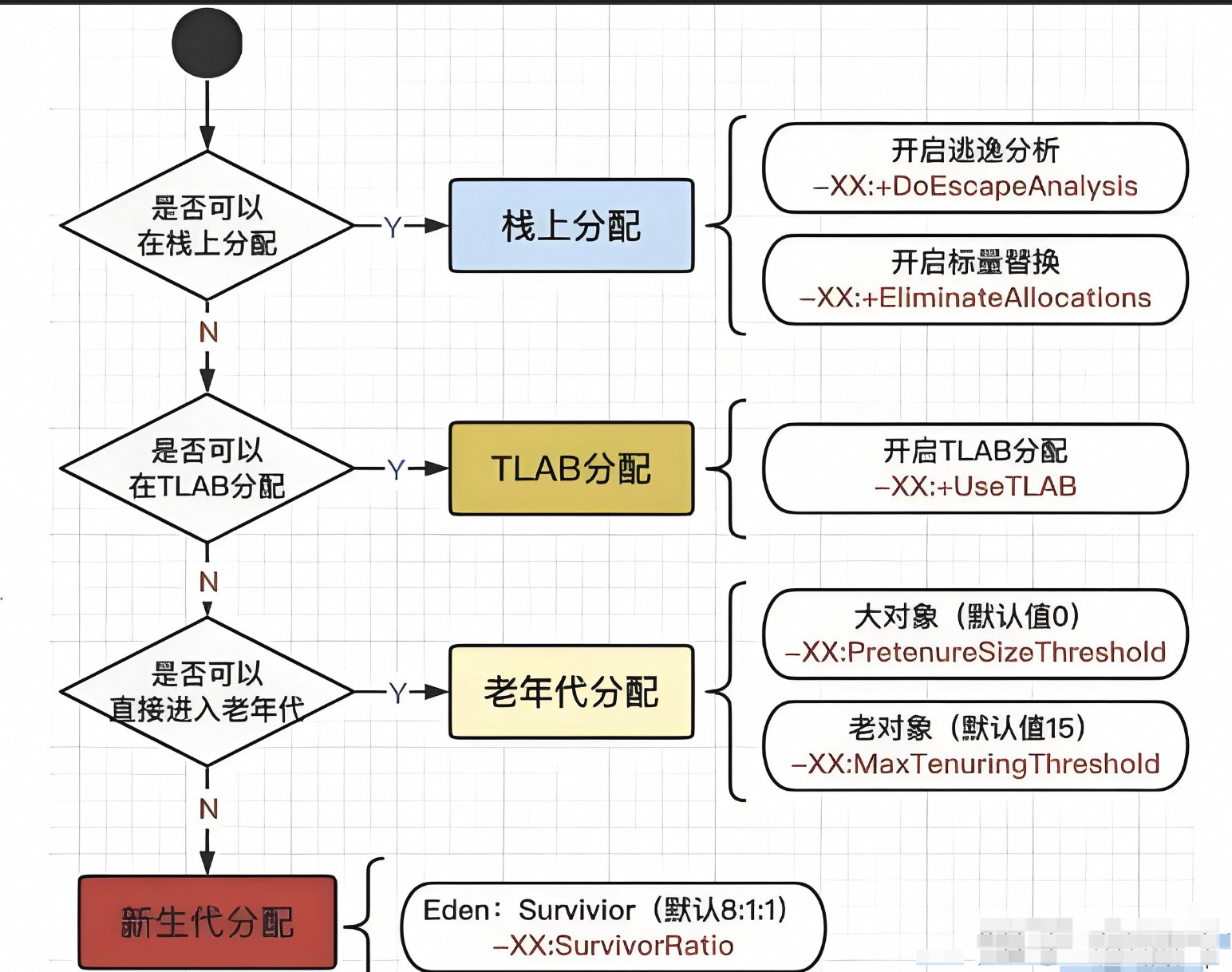
1、栈上分配:
不占堆空间,随着方法返回自动释放(需要逃逸分析证明无逃逸)。
2、标量替换(Scalar Replacement):
更加激进,把对象的字段当作独立变量,用时直接在寄存器/栈上,不再分配对象实例。
3、消除锁(锁消除/Lock Elision):
如果一个同步对象被证明只在单线程内使用,JVM 可以去掉同步开销。
2、常见逃逸分类(按作用域)
2.1、无逃逸(no escape)
对象只在方法内部使用,既不作为返回值也不赋给外部可见的位置。可以安全地在栈上分配或被完全消除。
代码示例:
java
public void foo() {
Point p = new Point(1, 2); // p 仅在 foo 内使用
int sum = p.x + p.y;
System.out.println(sum);
}p 没有被返回,也没赋给外部字段或线程,所以为"无逃逸"。JIT 可能把 p 的字段直接当作局部变量,甚至不实际分配对象。
2.2、方法级逃逸(method escape)
对象被返回或被赋给方法之外可见的地方,但仍限定于当前线程。例如返回给调用者。这种情况下不能分配到栈,通常要分配到堆。
代码示例如下:
java
public Point createPoint() {
return new Point(1, 2); // 返回出去,方法外可见 -> 逃逸到堆
}因为返回给调用者,对象逃出方法,不能分配到栈(通常分配到堆)。
2.3、线程级逃逸(thread escape)
对象被传递给其他线程(例如存到某个共享字段,或传入新线程),必须分配到堆,并且可能影响同步语义。
代码示例如下:
java
public void start() {
final Point p = new Point(1,2);
new Thread(() -> {
System.out.println(p.x);
}).start(); // p 被新线程使用 -> 线程逃逸
}对象被另一个线程读取/写,必须分配在堆上,且会遵守内存可见性规则。
3、逃逸分析的实践
3.1、是否开启逃逸对比
1、源代码(保存为 EscapeAnalysisDemo.java)
java
public class EscapeAnalysisDemo {
static class Point {
int x, y;
Point(int x, int y) { this.x = x; this.y = y; }
}
// 用 volatile 静态字段作为"逃逸接收器"
private static volatile Point volatileSink;
// 这种情况下 Point 对象仅在方法内部使用(理论上可被消除/栈上分配/标量替换)
static long allocNoEscape(int iter, int inner) {
long sum = 0;
for (int i = 0; i < iter; i++) {
for (int j = 0; j < inner; j++) {
Point p = new Point(j, j);
sum += p.x + p.y;
}
}
return sum;
}
// 这种情况下 Point 被写入 volatileSink(逃出方法/线程),必须分配到堆
static long allocEscape(int iter, int inner) {
long sum = 0;
for (int i = 0; i < iter; i++) {
for (int j = 0; j < inner; j++) {
Point p = new Point(j, j);
volatileSink = p; // 导致对象线程/方法逃逸
sum += p.x + p.y;
}
}
return sum;
}
public static void main(String[] args) {
final int ITER = 10000; // 外循环次数
final int INNER = 100; // 每次内循环创建多少对象(可调整)
// 预热,触发 JIT 编译
System.out.println("Warming up...");
for (int i = 0; i < 5; i++) {
allocNoEscape(1000, 100);
allocEscape(1000, 100);
}
System.out.println("Running allocNoEscape...");
long t0 = System.nanoTime();
long s1 = allocNoEscape(ITER, INNER);
long t1 = System.nanoTime();
System.out.printf("allocNoEscape result=%d time=%d ms%n", s1, (t1 - t0) / 1_000_000);
System.out.println("Running allocEscape...");
long t2 = System.nanoTime();
long s2 = allocEscape(ITER, INNER);
long t3 = System.nanoTime();
System.out.printf("allocEscape result=%d time=%d ms%n", s2, (t3 - t2) / 1_000_000);
// 防止编译器把 volatileSink 当作未使用(虽不太可能)
if (volatileSink != null && volatileSink.x == -1) {
System.out.println("never");
}
}
}2、编译在含有 JDK 的环境下:
javac EscapeAnalysisDemo.java
3、运行 & 比较
说明:要看到逃逸分析/分配消除的诊断输出,建议使用 server VM 并开启相关诊断开关。
下面适用于常见的 HotSpot(JDK8/11/17 等):
A. 开启逃逸分析并打印分配消除信息(默认情况下逃逸分析通常是开启的):
java -server -Xms512m -Xmx512m -XX:+UnlockDiagnosticVMOptions -XX:+PrintEliminateAllocations EscapeAnalysisDemo
B. 禁用逃逸分析(强制所有对象分配到堆),仍打印相关信息:
java -server -Xms512m -Xmx512m -XX:-DoEscapeAnalysis -XX:+UnlockDiagnosticVMOptions -XX:+PrintEliminateAllocations EscapeAnalysisDemo
(如果你的 JVM 不认识 PrintEliminateAllocations,可先去掉这个参数,仅通过运行时间对比;或用 -XX:+PrintCompilation / -XX:+LogCompilation 查看编译行为。)
4、期望输出:
当逃逸分析开启且 JIT 做了优化时(命令 A):
控制台可能会输出类似 "Eliminate allocations" 的诊断行(不同 JDK 文本不同,但会有"eliminated allocation"之类的提示)。
allocNoEscape 的执行时间明显比 allocEscape 要短很多(因为很多 Point 对象没有真实分配或被拆成标量)。
当你禁用逃逸分析(命令 B):
不会看到"消除分配"的诊断信息。allocNoEscape 与 allocEscape 的时间会更接近(因为两个都在堆上分配大量对象,产生 GC / 分配开销)。
3.2、逃逸分析的限制
1、逃逸分析依赖方法内联(inlining);没有被 JIT 编译或没有内联的代码,逃逸分析效果有限。解释器阶段没有这些优化。必须让方法足够热(多次调用、较大循环),JIT 才会编译并应用逃逸分析优化。
2、是一种保守分析:不能证明不逃逸就当作逃逸(即可能错判为逃逸),以保证正确性。
3、对循环复杂对象图、反射、native 调用等情况难以分析。
4、不是每次都会生效,依赖 HotSpot 的优化开关和编译器(C2)策略。
4、如何观察/控制(常用 JVM 参数)
- 开启/关闭逃逸分析(HotSpot 默认为开启):
- -XX:+DoEscapeAnalysis(开启,通常默认)
- -XX:-DoEscapeAnalysis(关闭)
- 开启标量替换(对象消除):
- -XX:+EliminateAllocations
- 打印相关信息:
- -XX:+PrintEliminateAllocations (打印标量替换/分配消除信息)
- -XX:+PrintEscapeAnalysis (不同版本上可能不可用或名称不同)
- 结合 JMH 或加 -Xcomp/-XX:+PrintCompilation 来观察 JIT 编译行为更靠谱。
总结:
满足逃逸分析的对象不一定会在栈上分配。逃逸分析只是确定了对象是否有可能在栈上分配,但是最终是否在栈上分配还取决于编译器的具体实现和其他一些因素。
例如:
1、编译器的优化策略:
不同的编译器可能有不同的优化策略和优化级别。有些编译器可能更保守,即使对象在逃逸分析中被认为不会逃逸,也可能选择在堆上分配以避免复杂的栈上分配逻辑。
2、资源限制:
在一些情况下,如果栈空间有限或者对象过大,即使对象不逃逸,它也可能被分配在堆上,以避免栈溢出。
3、对象的生命周期:
如果对象的生命周期很长,即使它不逃逸,编译器也可能选择在堆上分配,因为长生命周期的对象在栈上分配可能会导致栈空间的长期占用。
4、并发考虑:
在多线程环境中,即使对象不逃逸到其他线程,但由于并发访问的复杂性,编译器可能选择在堆上分配,以简化同步和并发处理。
总的来说,逃逸分析提供了一个对象是否可能在栈上分配的参考信息,但最终的分配决策还需要考虑上述因素。因此,并非所有不逃逸的对象都会被分配在栈上。
参考文章: