一、模型介绍
Voxtral-Small-24B-2507 是一款由 Mistral 团队发布的大规模多模态语言模型,具备强大的自然语言理解与生成能力,同时支持音频输入,适用于语音问答、语音识别、TTS 评估、音频对话等多种音频语言任务。该模型拥有 240 亿参数(24B),采用精心设计的小型架构(Small)在保持高效推理性能的同时,实现了卓越的多模态理解能力。
Voxtral-Small-24B-2507 在预训练阶段融合了高质量的文本和音频数据,具备如下特点:
• 多模态支持:原生支持音频输入,结合文本上下文进行语义理解与推理。
• 低延迟响应:搭配 vLLM 推理引擎可实现高并发、低延迟的在线服务部署。
• 开源兼容性强:模型可通过 Hugging Face Transformers 生态加载,兼容 vLLM、TGI 等主流推理框架。
• 精度与效率平衡:虽为 Small 版本,但在多项多模态任务上性能接近或优于更大参数规模模型。
在部署层面,Voxtral-Small-24B-2507 可结合 vLLM 高效推理框架和 Gradio 前端,快速构建支持音频输入的交互式应用或 API 服务,是构建智能语音系统的理想选择。
二、部署流程
快速部署及使用方法详见算家云"镜像社区"
| 环境名称 | 版本信息 |
|---|---|
| Ubuntu | 22.04 |
| Cuda | 12.4.1 |
| python | 3.12 |
| NVIDIA Corporation | RTX 4090 * |
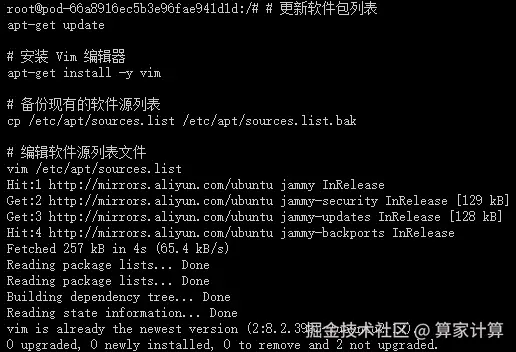
1.更新基础软件包
查看系统版本信息
bash
# 查看系统版本信息,包括ID(如ubuntu、centos等)、版本号、名称、版本号ID等
cat /etc/os-release
配置 apt 国内源
csharp
# 更新软件包列表
apt-get update这个命令用于更新本地软件包索引。它会从所有配置的源中检索最新的软件包列表信息,但不会安装或升级任何软件包。这是安装新软件包或进行软件包升级之前的推荐步骤,因为它确保了您获取的是最新版本的软件包。
csharp
# 安装 Vim 编辑器
apt-get install -y vim这个命令用于安装 Vim 文本编辑器。-y 选项表示自动回答所有的提示为"是",这样在安装过程中就不需要手动确认。Vim 是一个非常强大的文本编辑器,广泛用于编程和配置文件的编辑。
为了安全起见,先备份当前的 sources.list 文件之后,再进行修改:
bash
# 备份现有的软件源列表
cp /etc/apt/sources.list /etc/apt/sources.list.bak这个命令将当前的 sources.list 文件复制为一个名为 sources.list.bak 的备份文件。这是一个好习惯,因为编辑 sources.list 文件时可能会出错,导致无法安装或更新软件包。有了备份,如果出现问题,您可以轻松地恢复原始的文件。
bash
# 编辑软件源列表文件
vim /etc/apt/sources.list这个命令使用 Vim 编辑器打开 sources.list 文件,以便您可以编辑它。这个文件包含了 APT(Advanced Package Tool)用于安装和更新软件包的软件源列表。通过编辑这个文件,您可以添加新的软件源、更改现有软件源的优先级或禁用某些软件源。
在 Vim 中,您可以使用方向键来移动光标,
i 键进入插入模式(可以开始编辑文本),
Esc 键退出插入模式,
:wq 命令保存更改并退出 Vim,
或 :q! 命令不保存更改并退出 Vim。
编辑 sources.list 文件时,请确保您了解自己在做什么,特别是如果您正在添加新的软件源。错误的源可能会导致软件包安装失败或系统安全问题。如果您不确定,最好先搜索并找到可靠的源信息,或者咨询有经验的 Linux 用户。
使用 Vim 编辑器打开 sources.list 文件,复制以下代码替换 sources.list 里面的全部代码,配置 apt 国内阿里源。
arduino
deb http://mirrors.aliyun.com/ubuntu/ jammy main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ jammy-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ jammy-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ jammy-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ jammy-backports main restricted universe multiverse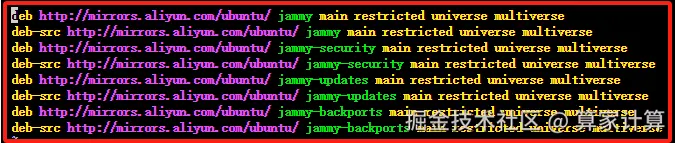
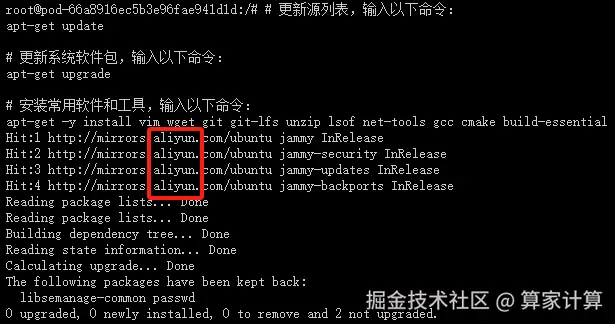
安装常用软件和工具
csharp
# 更新源列表,输入以下命令:
apt-get update
# 更新系统软件包,输入以下命令:
apt-get upgrade
# 安装常用软件和工具,输入以下命令:
apt-get -y install vim wget git git-lfs unzip lsof net-tools gcc cmake build-essential出现以下页面,说明国内 apt 源已替换成功,且能正常安装 apt 软件和工具
2.下载Voxtral-Small-24B-2507模型
开启代理下载
bash
# 启用代理
source /root/sj-data/Script/SJ-proxy.sh && proxy_on
bash
modelscope download--model mistralai/Voxtral-Small-24B-2507 --cache-dir /data /models_and datasets/LargeModel/Voxtral-Smal1-24B-2507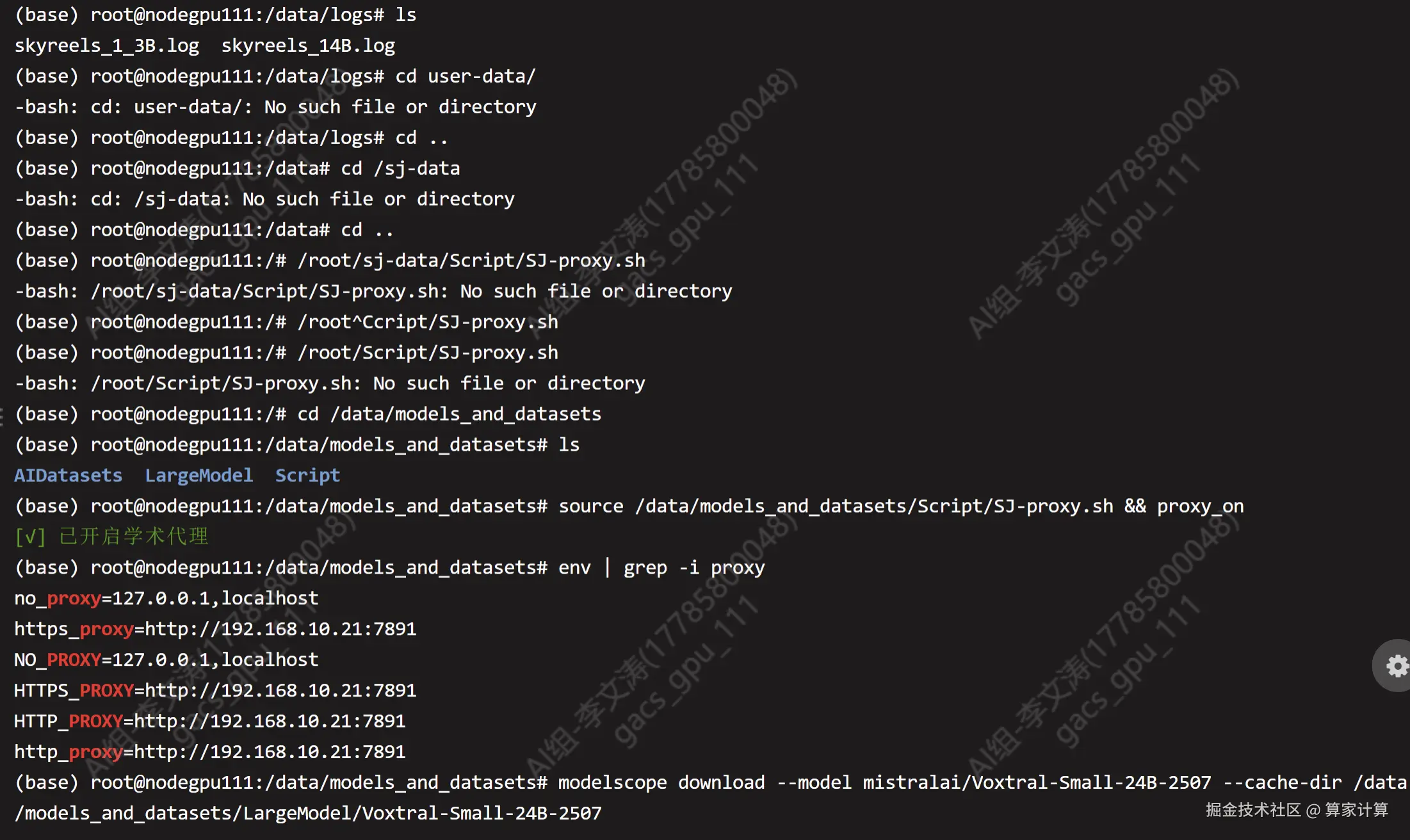
下载完关闭代理
bash
关闭代理source /root/sj-data/Script/SJ-proxy.sh && proxy_off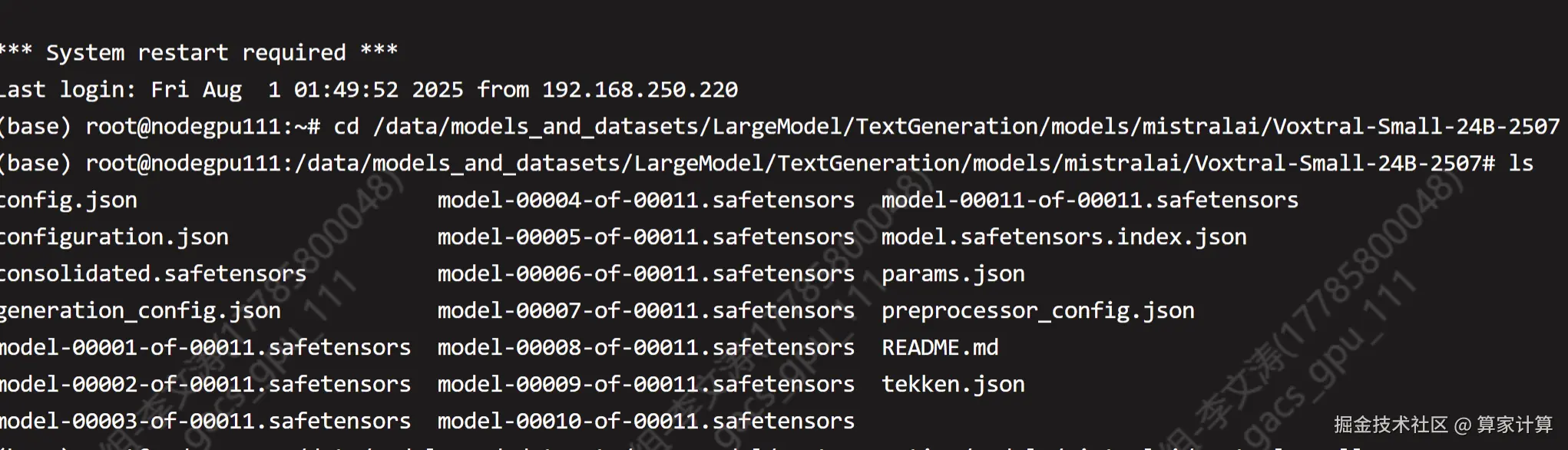
3.创建环境与项目目录
创建虚拟环境
ini
#创建一个名为 voxtral 的新虚拟环境,并指定 Python 版本为 3.12
conda create --name voxtral python=3.12
bash
#查看环境
conda env list
bash
#创建并进入项目根目录,激活环境
mkdir -p /Amphion/model
cd /Amphion/model/
conda activate voxtral从现在开始,所有路径都是相对于 /Amphion/model,你可以随时 pwd 确认
bash
ln -s /root/sj-data/models_and_datasets/LargeModel/Voxtral-Smal1-24B-2507 /Amphion/model/Voxtral-Small-24B-2507
bash
ls -l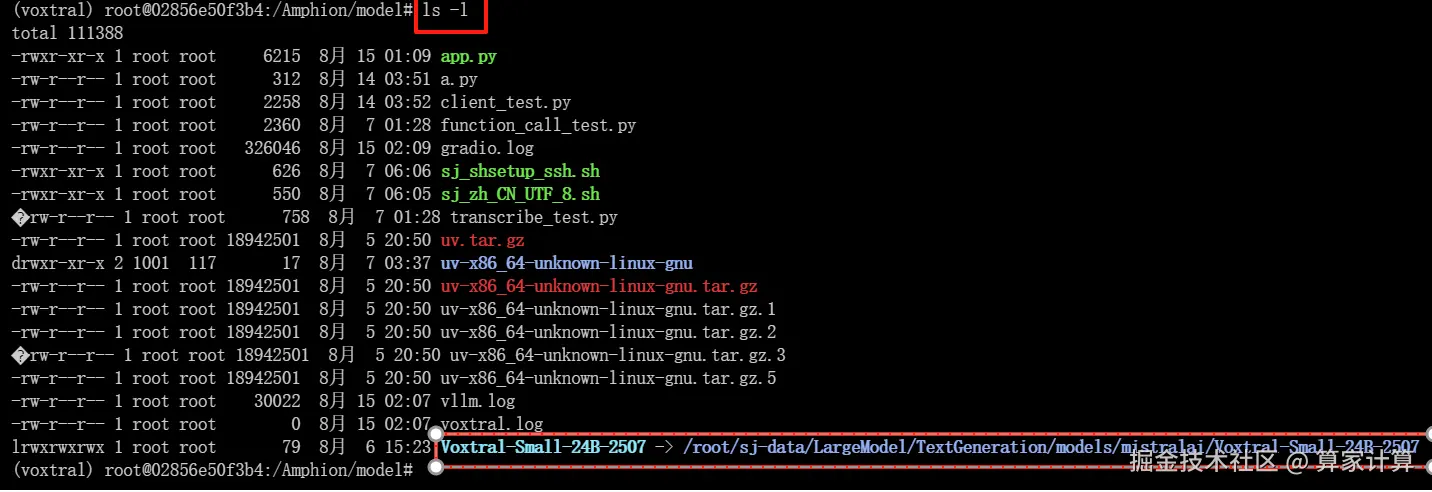
输入 ls,查看一下是否有Voxtral-Small-24B-2507 文件夹
bash
ls
4.安装模型依赖库
安装 Python3 与 pip bash
apt install -y python3 python3-pip python3-venv 
安装 uv(官方推荐) bash
pip install uv 
安装 vLLM + Audio 依赖
css
uv pip install -U "vllm[audio]" --system -i https://mirrors.aliyun.com/pypi/simp
如果阿里镜像仍不可用,把 -i ... 去掉,直接用官方源即可。验证 mistral_common 版本 ≥ 1.8.1
scss
python3 -c "import mistral_common; print(mistral_common.version)"
离线
你可以通过克隆 vLLM 仓库来测试你的 vLLM 设置是否按预期工作:
bash
git clone https://github.com/vllm-project/vllm && cd vllm
然后运行:
css
python examples/offline_inference/audio_language.py --num-audios 2 --model-type voxtral
服务
建议你在服务器/客户端设置中使用 Voxtral-Small-24B-2507。 1. 启动一个服务器vllm:
css
VLLM_USE_MODELSCOPE=true vllm serve /Amphion/model/Voxtral-Small-24B-2507 --tokenizer_mode mistral --config_format mistral --load_format mistral --tensor-parallel-size 4 --tool-call-parser mistral --enable-auto-tool-choice三、网页演示
利用 Voxtral-Small-24B-2507 的音频功能进行聊天与强大的转录能力!确保您的客户端已安装带有音频支持的 mistral-common:
css
pip install --upgrade mistral_common[audio]vim app.py
python
#!/usr/bin/env python3
import os
import tempfile
import logging
import gradio as gr
from pydub import AudioSegment
from openai import OpenAI
from mistral_common.audio import Audio
from mistral_common.protocol.transcription.request import TranscriptionRequest
from mistral_common.protocol.instruct.messages import RawAudio
# 日志配置
LOG_FILE = "./gradio.log"
logging.basicConfig(
filename=LOG_FILE,
level=logging.INFO,
format="%(asctime)s [%(levelname)s] %(message)s"
)
logger = logging.getLogger(__name__)
logger.info("========== Gradio 服务启动 ==========")
# 全局配置
OPENAI_API_KEY = "EMPTY"
OPENAI_API_BASE = "http://127.0.0.1:8000/v1"
MODEL_ID = "/Amphion/model/Voxtral-Small-24B-2507"
# 初始化OpenAI客户端
client = OpenAI(api_key=OPENAI_API_KEY, base_url=OPENAI_API_BASE)
def get_model_id():
return MODEL_ID
def to_mono(input_path: str) -> str:
"""将音频转换为单声道16kHz格式"""
sound = AudioSegment.from_file(input_path)
sound = sound.set_channels(1).set_frame_rate(16000)
tmp = tempfile.NamedTemporaryFile(suffix=".mp3", delete=False)
sound.export(tmp.name)
return tmp.name
def transcribe(audio_path: str, language: str) -> str:
"""使用API转录音频,确保准确使用选择的语言"""
if not audio_path:
return "请先上传音频。"
try:
logger.info(f"开始转录:{audio_path},语言={language}")
mono = to_mono(audio_path)
logger.info(f"单声道音频已生成:{mono}")
audio = Audio.from_file(mono, strict=False)
raw_audio = RawAudio.from_audio(audio)
# 确保语言参数准确传递
lang_param = language if language != "auto" else None
req = TranscriptionRequest(
model=get_model_id(),
audio=raw_audio,
language=lang_param,
temperature=0.0
).to_openai(exclude=("top_p", "seed"))
# 添加详细的请求日志
logger.info(f"转录请求参数: model={req['model']}, language={lang_param}")
response = client.audio.transcriptions.create(**req)
os.unlink(mono)
result = response.text
logger.info(f"转录完成:{result}")
return result
except Exception as e:
logger.exception("转录失败")
return f"❌ 转录失败: {e}"
def understand(audio_files, question: str, language: str) -> str:
"""理解音频内容并回答问题,使用选择的语言转录"""
if not audio_files:
return "请至少上传一个音频文件。"
if not question.strip():
return "请输入问题。"
try:
logger.info(f"开始理解:文件={audio_files},问题={question},语言={language}")
# 收集所有转录文本,使用用户选择的语言
transcriptions = []
for f in audio_files:
mono = to_mono(f)
# 使用用户选择的语言进行转录
transcript = transcribe(mono, language)
transcriptions.append(f"【音频内容】{transcript}")
os.unlink(mono)
# 构建完整提示
full_prompt = "\n\n".join(transcriptions) + f"\n\n【问题】{question}"
logger.info(f"完整提示内容:\n{full_prompt}")
# 调用聊天API
response = client.chat.completions.create(
model=get_model_id(),
messages=[
{
"role": "system",
"content": "你是一个专业的语音助手,请根据提供的音频转录内容回答问题。"
},
{
"role": "user",
"content": full_prompt
}
],
temperature=0.7,
top_p=0.9,
)
result = response.choices[0].message.content
logger.info(f"理解完成:{result}")
return result
except Exception as e:
logger.exception("理解失败")
return f"❌ 理解失败: {e}"
# Gradio界面 - 确保语言选择功能准确
with gr.Blocks(title="Voxtral 音频转录 & 理解") as demo:
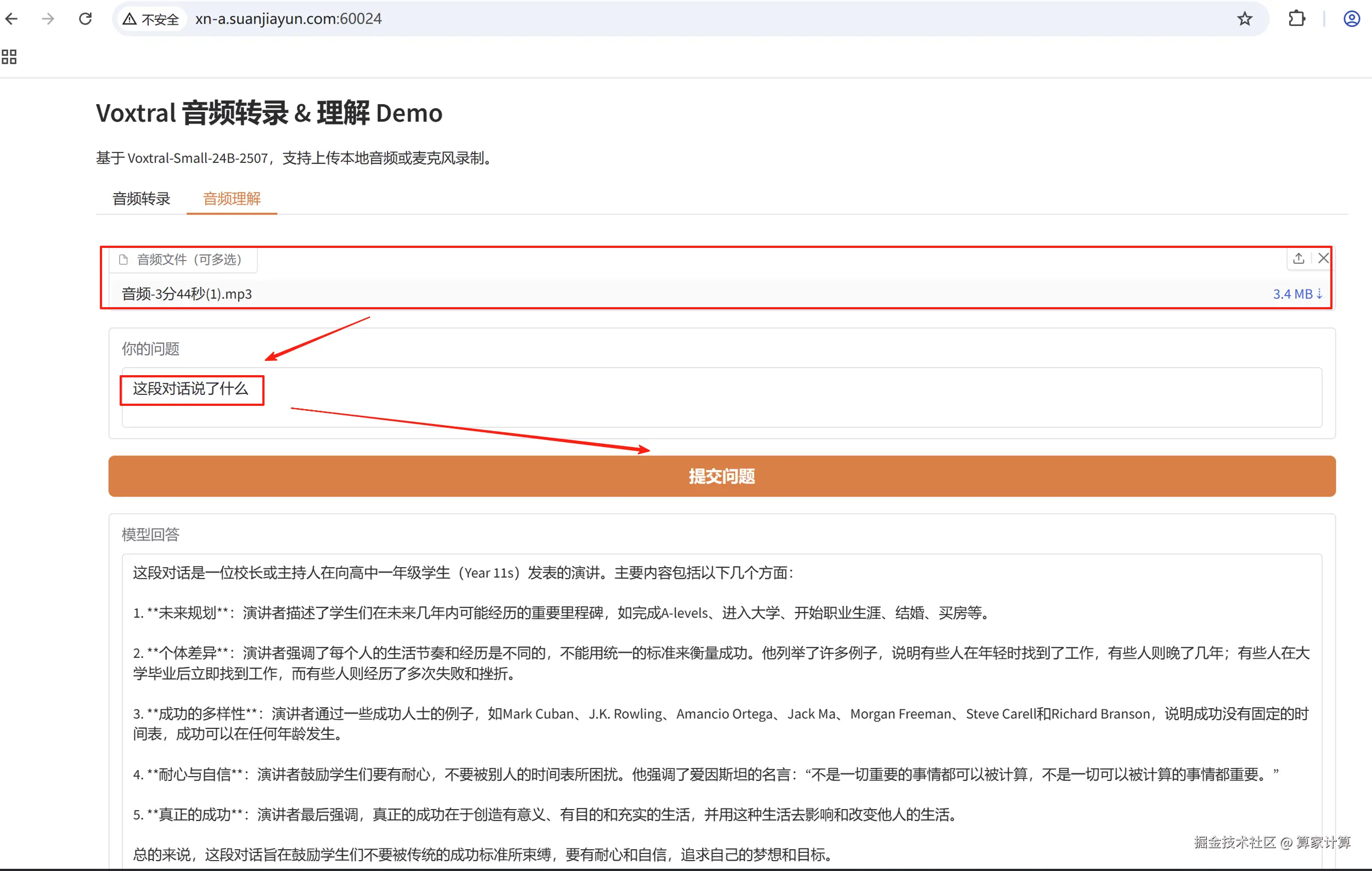
gr.Markdown("# Voxtral 音频转录 & 理解 Demo")
gr.Markdown("基于 Voxtral-Small-24B-2507,支持上传本地音频或麦克风录制。")
# 转录标签页
with gr.Tab("音频转录"):
with gr.Row():
audio_in = gr.Audio(type="filepath", label="上传音频")
lang_dd = gr.Dropdown(
choices=["auto", "zh", "en", "fr", "es", "de", "ja", "ko"],
value="zh", # 默认值改为中文
label="语言",
info="选择音频的语言"
)
transcribe_btn = gr.Button("开始转录", variant="primary")
transcribe_out = gr.Textbox(label="转录结果", lines=8, interactive=False)
transcribe_btn.click(transcribe, inputs=[audio_in, lang_dd], outputs=transcribe_out)
# 理解标签页
with gr.Tab("音频理解"):
audios_in = gr.File(
file_count="multiple",
file_types=["audio"],
type="filepath",
label="音频文件(可多选)"
)
question_in = gr.Textbox(
label="你的问题",
placeholder="例如:这段对话主要讲了什么?",
lines=2
)
# 添加语言选择器
understand_lang = gr.Dropdown(
choices=["auto", "zh", "en", "fr", "es", "de", "ja", "ko"],
value="zh",
label="转录语言",
info="选择音频的语言"
)
understand_btn = gr.Button("提交问题", variant="primary")
understand_out = gr.Textbox(label="模型回答", lines=8, interactive=False)
understand_btn.click(
understand,
inputs=[audios_in, question_in, understand_lang], # 添加语言输入
outputs=understand_out
)
if __name__ == "__main__":
port = int(os.environ.get("GRADIO_SERVER_PORT", 8080))
demo.launch(server_name="0.0.0.0", server_port=port, share=False)在 Vim 中,您可以使用方向键来移动光标, i 键进入插入模式(可以开始编辑文本), Esc 键退出插入模式, :wq 命令保存更改并退出 Vim, 或 :q! 命令不保存更改并退出 Vim。
python app.py音频转录
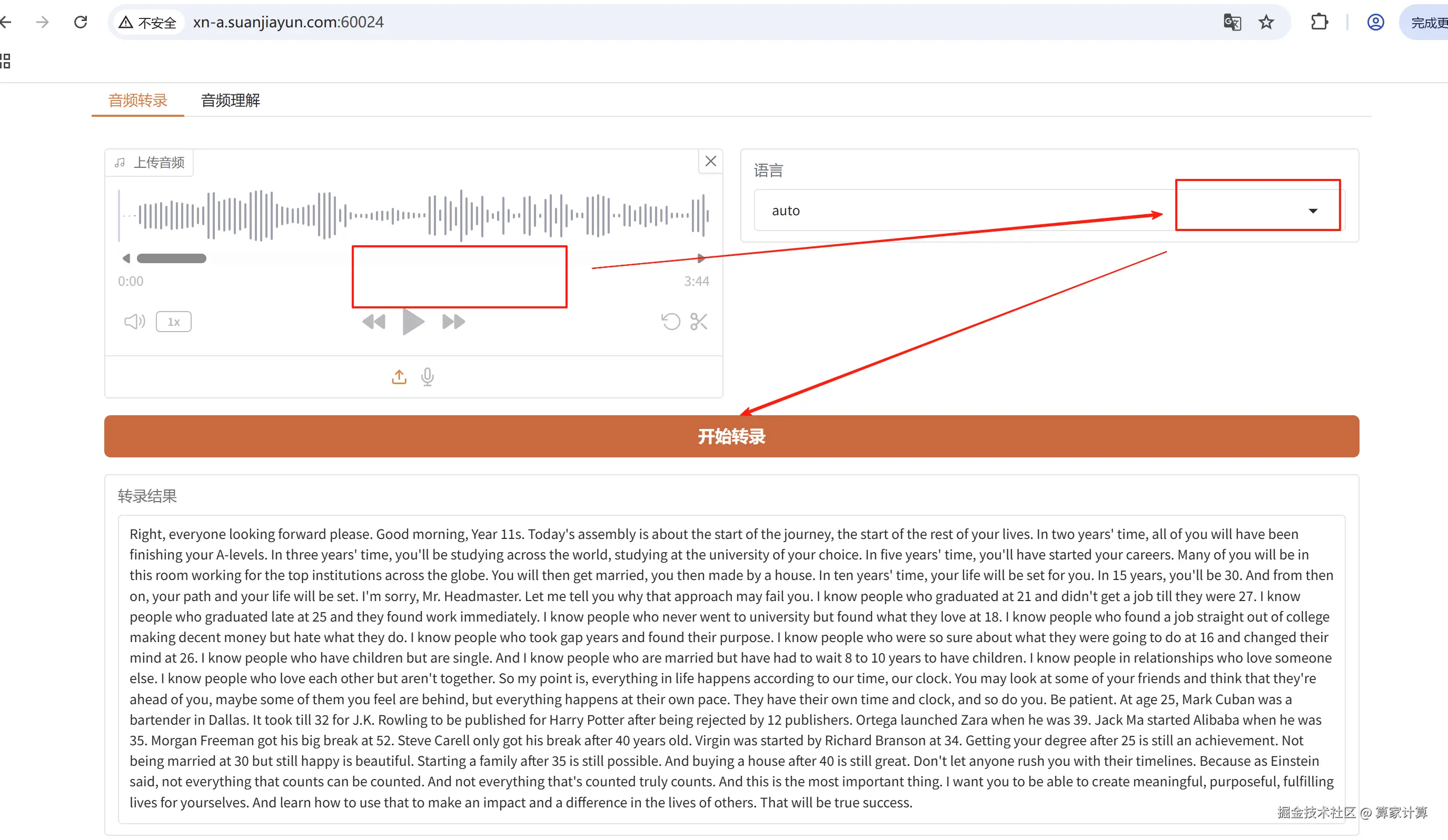
音频理解