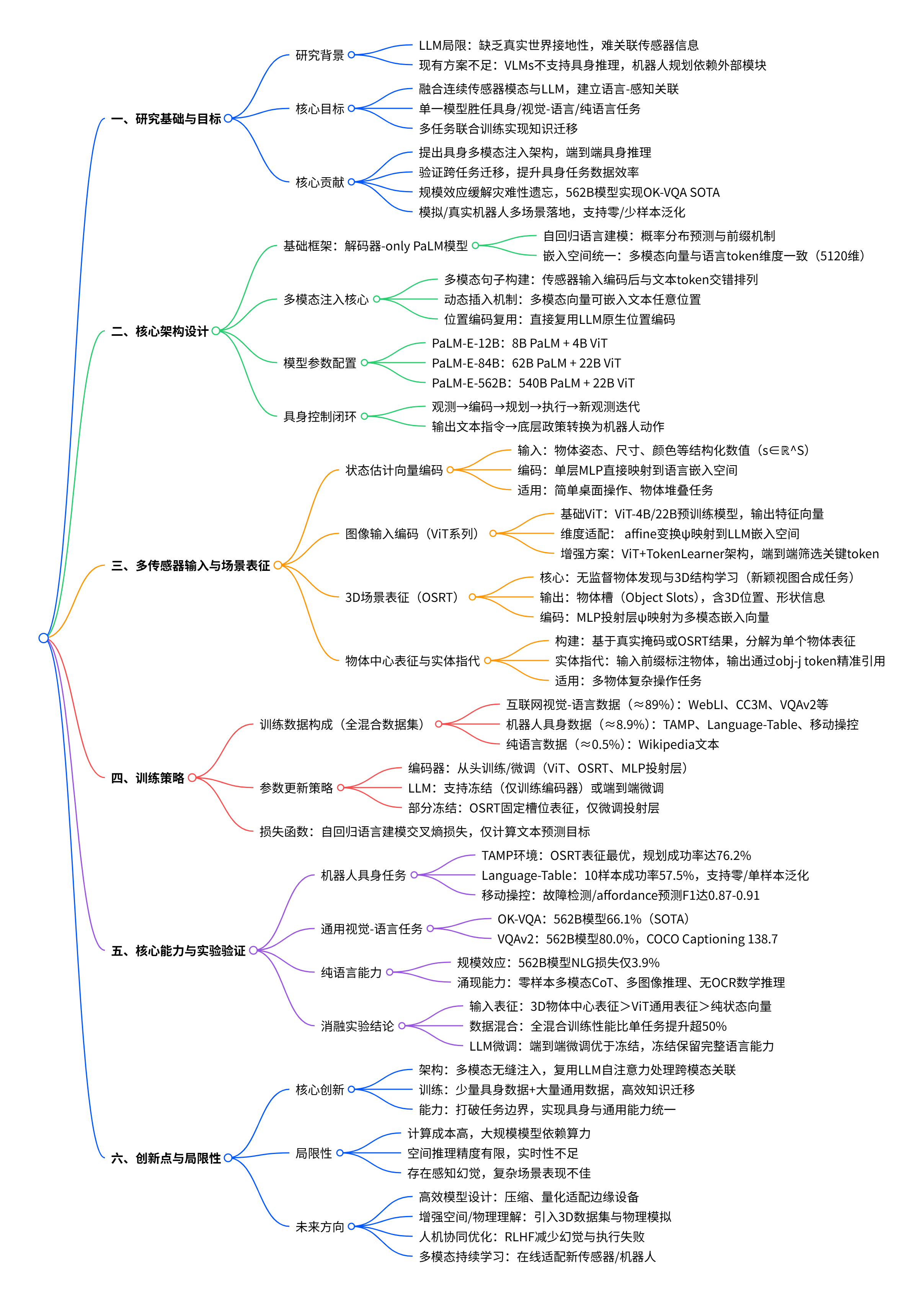
在机器人与具身智能领域,如何让模型实现真实世界的精准感知与决策,一直是科研界的核心挑战。谷歌团队推出的 PaLM-E,首次将大规模语言模型(LLM)与多模态感知能力深度融合,构建出首个通用型具身多模态语言模型,既能完成机器人规划、故障检测等具身任务,又保持了顶尖的视觉 - 语言理解与纯语言能力。
项目主页:https://palm-e.github.io/
原文链接:https://arxiv.org/pdf/2303.03378
沐小含将持续分享前沿算法论文,欢迎关注...
一、研究背景与核心动机
1. 具身智能的发展瓶颈
大语言模型(LLMs)在对话、推理、代码生成等领域展现出强大能力,但在真实世界具身任务中存在关键短板:缺乏接地性(Grounding)。传统 LLM 仅依赖文本训练,无法将语言表征与真实世界的视觉、物理传感器信息关联,导致生成的计划可能无法执行(如机器人规划中忽略物体空间位置)。
现有解决方案存在明显局限:
- 视觉 - 语言模型(如 PaLI、Flamingo):擅长图像问答、 captioning 等感知任务,但无法直接解决机器人规划等具身推理问题。
- 机器人规划方法(如 SayCan):依赖外部 affordance 函数或人类交互引导,LLM 仅处理文本输入,难以利用场景几何信息与动态物理约束。
2. 核心研究目标
PaLM-E 的核心目标是构建一个通用型具身多模态语言模型,实现三大突破:
- 直接融合真实世界连续传感器模态(图像、状态估计等)与 LLM,建立语言与感知的直接关联。
- 单一模型同时胜任具身任务(机器人规划、故障检测)、视觉 - 语言任务(VQA、图像描述)与纯语言任务(数学推理、对话)。
- 通过多任务联合训练实现知识迁移,提升具身任务的数据效率与泛化能力。
3. 研究核心贡献
- 提出具身语言模型架构:将多模态传感器输入直接注入 LLM 的嵌入空间,实现端到端的具身推理。
- 验证跨任务知识迁移:通过联合训练互联网规模视觉 - 语言数据与少量机器人数据,显著提升具身任务性能。
- 规模效应突破:562B 参数的 PaLM-E-562B 实现 OK-VQA 任务 SOTA,同时保持 LLM 的语言能力,且随规模扩大减少灾难性遗忘。
- 多场景落地验证:在模拟与真实机器人环境中完成桌面操作、移动操控等任务,支持零样本 / 少样本泛化。
二、模型架构:多模态注入的通用语言模型
PaLM-E 的核心设计理念是 **以 LLM 为核心,多模态输入无缝注入**,通过极简架构实现多任务统一处理。其整体架构如图 1 所示:

PaLM-E 在机器人系统中作为高层规划器,形成闭环控制流程:
- 机器人通过传感器获取当前场景观测(图像 / 状态)。
- 观测数据经编码器生成多模态嵌入,与人类指令(文本)组成多模态句子输入 PaLM-E。
- PaLM-E 生成下一步动作指令(文本形式)。
- 底层政策将文本指令转换为机器人可执行的低级别动作(如机械臂移动、导航)。
- 动作执行后获取新观测,重复上述流程直至任务完成,支持故障检测与重新规划。
2.1 PaLM-E 核心架构设计
PaLM-E 的核心创新在于 **"将连续具身观测直接注入预训练 LLM 的嵌入空间"**,实现多模态与语言的原生融合,而非传统的 "视觉模型 + 语言模型" 拼接设计。其技术原理可拆解为以下关键模块:
2.1.1 解码器 - only LLM 基础框架
PaLM-E 基于解码器 - only 架构的 PaLM 模型构建,遵循自回归语言建模范式。模型核心目标是预测文本序列的概率分布:
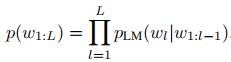
其中为文本 token 序列,
为 Transformer-based LLM 网络。
由于LLM具有自回归特性,通过前缀(Prefix)机制,模型可基于上下文(多模态句子)生成后续 token,无需修改核心架构:
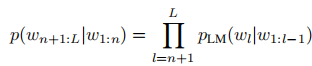
前缀部分由多模态句子构成,为模型提供具身观测与任务指令信息,引导生成符合场景约束的后续输出。
PaLM模型解读:PaLM:Pathways 驱动的大规模语言模型 scaling 实践-CSDN博客
2.1.2 多模态句子构建与注入机制
这是 PaLM-E 最核心的技术设计,实现了连续传感器输入与离散语言 token 的统一处理。具体流程如下:
-
模态编码 :通过专属编码器
将连续观测(如图像、状态向量)映射为长度为

-
交错排列:将编码后的多模态向量与文本 token 的嵌入向量交错排列,形成 "多模态句子"。例如,指令 "对比<img1>和<img2>的差异" 会被转换为「对比 + <img1 编码向量> + 和 + <img2 编码向量 > + 的差异」的嵌入序列。
-
动态插入:多模态向量可插入文本序列的任意位置,而非固定前缀或后缀,适配复杂任务指令(如多图像时序推理、物体指代交互),这与 Flamingo 等模型的固定图像输入位置设计形成显著区别。
-
位置编码复用:多模态向量直接复用 LLM 原有的位置编码机制,无需额外设计跨模态位置编码,简化架构并保证兼容性。
Flamingo模型解读:Flamingo:打破模态壁垒的少样本视觉语言模型_flamingo 论文 pdf-CSDN博客
2.1.3 输出与具身系统衔接
PaLM-E 的输出为纯文本形式,通过两种方式衔接具身系统:
- 感知类任务(VQA、场景描述):输出直接作为任务答案,无需额外转换。
- 规划与控制任务:输出为高层动作指令序列(如 "1. 移动到抽屉前→2. 打开顶层抽屉→3. 取出绿色薯片袋"),由底层政策(如 RT-1)转换为机器人可执行的低级别控制信号(如关节角度、导航坐标)。
- 闭环迭代:机器人执行动作后获取新的场景观测,重新输入 PaLM-E 生成下一步指令,形成 "观测 - 规划 - 执行" 闭环,支持故障检测与重新规划(如物体抓取失败后调整策略)。
2.1.4 模型参数配置与命名规则
PaLM-E 采用 "LLM + 视觉编码器" 的组合配置,不同规模模型的命名与参数构成严格对应:
- PaLM-E-12B:8B 参数 PaLM + 4B 参数 ViT(ViT-4B)
- PaLM-E-84B:62B 参数 PaLM + 22B 参数 ViT(ViT-22B)
- PaLM-E-562B:540B 参数 PaLM + 22B 参数 ViT(ViT-22B)所有组件的嵌入维度统一为 5120,确保多模态向量与语言 token 的兼容性,这是实现无缝注入的关键基础。
三、多传感器输入与场景表征
PaLM-E 针对不同具身场景的传感器输入,设计了多样化的编码与表征方案,核心目标是精准捕捉场景几何、物体属性与动态关系,为具身推理提供可靠输入。
3.1 状态估计向量编码
适用于机器人关节状态、物体姿态等结构化数值输入,编码流程极简且高效:
- 输入形式:
- 编码方式:通过单层 MLP(
- 适用场景:简单桌面操作、物体堆叠等任务,可快速提供物体核心状态信息,训练与推理效率高。
3.2 图像输入编码(ViT 系列)
针对 2D 图像输入,采用预训练 Vision Transformer 及其变体,确保通用视觉特征的有效提取:
- 基础 ViT 编码:采用 ViT-4B(40 亿参数)或 ViT-22B(220 亿参数)作为编码器,预训练任务为图像分类。ViT 将图像分割为 16×16 像素的 patch,输出序列长度为 14×14+1(含 class token)的特征向量
- 维度适配投射:由于 ViT 输出维度
- TokenLearner 增强:部分配置采用 ViT + TokenLearner 架构,通过可学习的注意力机制从 ViT 特征中筛选关键 token,减少冗余信息,提升具身任务的推理效率,该架构从头端到端训练。
3.3 3D 场景表征(OSRT)
针对需要空间推理的具身任务(如物体避障、多视角规划),采用 Object Scene Representation Transformer(OSRT)实现无监督物体发现与 3D 场景建模:
- 核心原理:OSRT 基于 Scene Representation Transformer(SRT)改进,通过新颖视图合成任务自监督学习场景的 3D 结构,无需人工标注物体实例。
- 输出形式:生成场景的物体槽(Object Slots)
- 编码流程:通过 MLP 投射层
- 核心优势:无需地面真实物体掩码即可实现物体级表征,适配真实世界中物体遮挡、姿态多变的场景,显著提升具身规划的精准性。
3.4 物体中心表征与实体指代
为解决具身任务中物体精准引用问题(如 "移动左侧红色方块"),设计物体中心表征方案,实现语言指令与场景物体的精准对齐:
- 表征构建:基于地面真实物体掩码或 OSRT 的无监督物体发现结果,将视觉输入分解为单个物体的独立表征。例如,对包含 3 个物体的场景,生成 "Object 1: <obj1 编码>、Object 2: <obj2 编码 >、Object 3: <obj3 编码 >" 的前缀嵌入。
- 实体指代机制:在输入 prompt 中添加物体标签前缀(如 "Object 1 是红色方块,Object 2 是蓝色圆柱"),模型可在输出中通过 "obj-1""obj-2" 等特殊 token 精准引用物体,避免歧义(如多个同色物体时的区分)。
- 适用场景:多物体操作、复杂堆叠任务,确保机器人能准确执行针对特定物体的动作,减少操作错误。
3.5 多模态编码器组合策略
PaLM-E 支持多种编码器的动态组合,可根据任务需求灵活选择输入模态与编码方案:
- 单模态输入:仅使用 ViT(图像)或 OSRT(3D 场景),适配单一传感器的具身场景。
- 多模态融合:同时输入状态向量 + 图像 + 3D 槽,例如机器人导航任务中,结合自身关节状态(MLP 编码)、环境图像(ViT 编码)与场景 3D 结构(OSRT 编码),提升规划鲁棒性。
- 编码器动态切换:不同位置的多模态输入可采用不同编码器,例如 "<img1(ViT 编码)> 和 < obj1(OSRT 编码)> 的位置关系",适配复杂任务的多源信息需求。
四、训练策略:多任务联合与高效迁移
PaLM-E 的训练核心是 **多数据混合 + 灵活参数更新**,通过精心设计的训练方案实现知识迁移与能力保留。
1. 训练数据构成
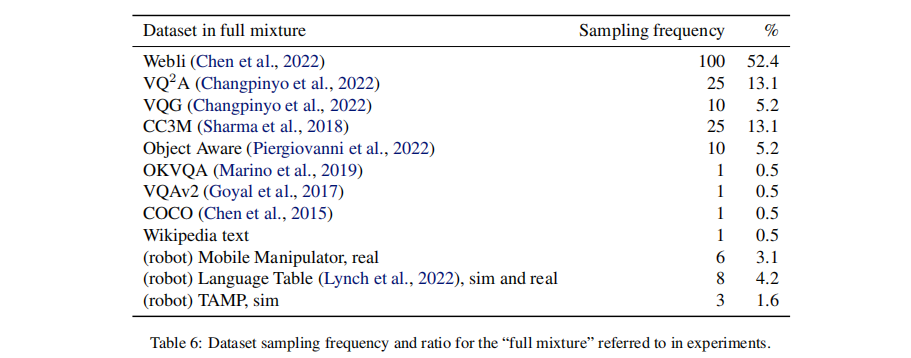
采用 "全混合数据集(Full Mixture)",涵盖三大类数据,采样频率与占比如表 6 所示:
- 互联网规模视觉 - 语言数据(占比≈89%):WebLI、CC3M、VQAv2、OK-VQA、COCO 等,提供通用视觉 - 语言知识。
- 机器人具身数据(占比≈8.9%):三类机器人任务数据 ------ 桌面操作(Language-Table)、任务与运动规划(TAMP)、移动操控(厨房环境),包含模拟与真实世界数据。
- 纯语言数据(占比≈0.5%):Wikipedia 文本,辅助保留语言模型能力。
2. 参数更新策略
针对不同组件设计灵活的训练方案,平衡新知识学习与预训练能力保留:
- 编码器训练:所有模态编码器(ViT、OSRT、MLP 投射层)均从头训练或微调,确保多模态输入与 LLM 嵌入空间对齐。
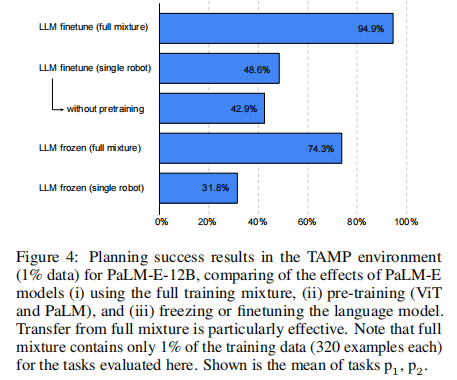
- LLM 参数控制:支持两种模式 ------ 冻结 LLM 仅训练编码器(输入条件软提示)、端到端微调整个模型(含 LLM)。实验表明,端到端微调性能更优,且模型规模越大,灾难性遗忘越少。
- 部分组件冻结:对 OSRT 等预训练场景表征模型,可仅微调投射层(MLP ψ),固定其槽位表征,提升训练效率。
3. 损失函数设计
采用自回归语言建模损失,仅对文本预测目标计算交叉熵损失:
- 输入前缀:多模态句子(含编码后的观测与任务指令),不参与损失计算。
- 预测目标:仅包含文本 token(如机器人动作序列、问答答案),损失为预测 token 与真实 token 的交叉熵平均值。
五、核心能力与实验验证
PaLM-E 在三类任务中进行了全面验证:机器人具身任务、通用视觉 - 语言任务、纯语言任务,均展现出顶尖性能与跨任务迁移能力。
1. 机器人具身任务验证
选取三大典型具身场景,对比基线模型(SayCan、PaLI)与不同配置的 PaLM-E,验证其规划能力、数据效率与泛化性。
(1)任务与运动规划(TAMP)
- 任务场景:机器人需完成物体抓取、堆叠等任务,需考虑物体空间位置与物理约束(如先移开遮挡物体)。
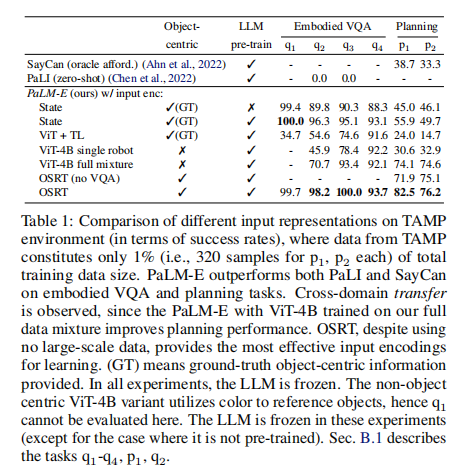
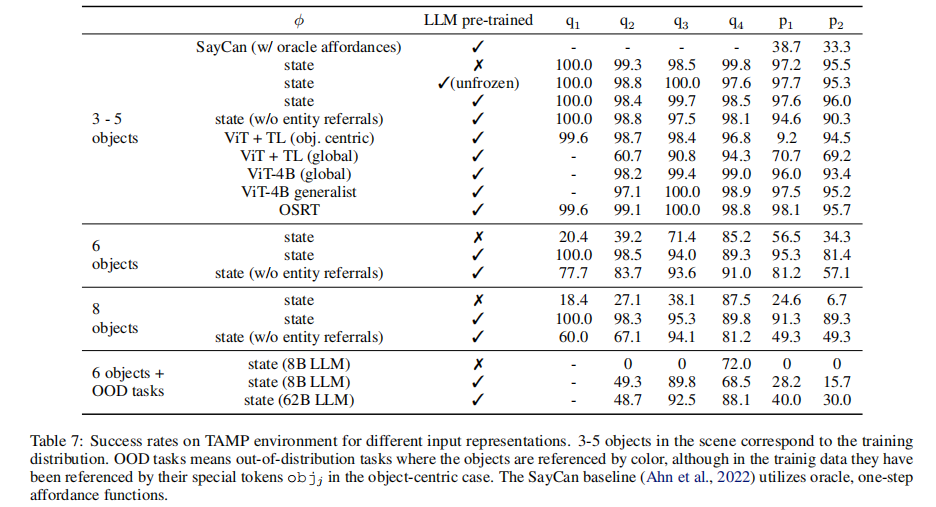
- 关键结果(表 1、表 7):
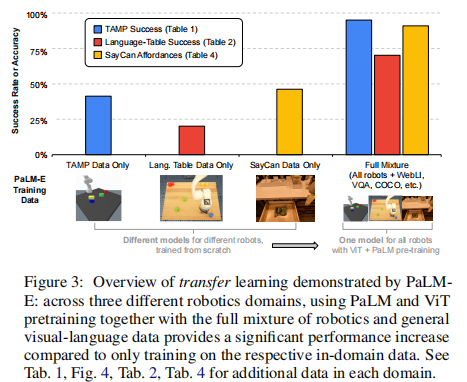
- 预训练 LLM 与多数据混合训练显著提升性能:ViT-4B + 全混合数据的 PaLM-E 规划成功率达 74.6%,远超单机器人数据训练的 32.9%。
- 3D 场景表征(OSRT)效果最优:即使无大规模数据,OSRT 编码仍实现 76.2% 的规划成功率,凸显空间感知对具身任务的重要性。
- 基线模型表现不佳:零样本 PaLI 无法完成规划任务,SayCan( oracle affordance)规划成功率仅 33.3%-38.7%,且泛化能力差。
(2)桌面操作(Language-Table)
-
任务场景:机器人需完成长视野任务(如 "按颜色将积木分类到角落"),应对复杂物体动态与语言指令变化。
-
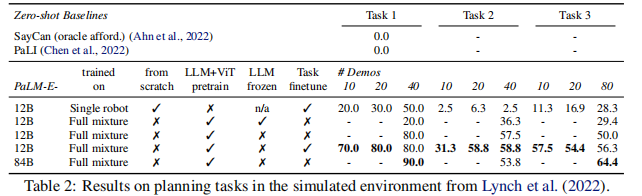
关键结果(表 2、图 5):
- 少样本泛化能力突出:仅 10 个演示样本时,全混合数据训练的 PaLM-E-12B 任务成功率达 57.5%,远超单机器人数据训练的 6.3%。
- 规模提升带来性能增益:PaLM-E-84B(62B PaLM+22B ViT)在多数任务上性能优于 12B 版本,展现规模效应。
- 零样本 / 单样本泛化:可处理未见过的物体组合(如 "将绿色积木移到乌龟旁"),且能抵抗对抗性干扰(如物体被意外移动后重新规划)。

(3)移动操控(厨房环境)
-
任务场景:机器人需完成导航、物体抓取、故障处理等任务(如 "清理洒出的饮料""从抽屉取薯片"),验证闭环控制能力。
-
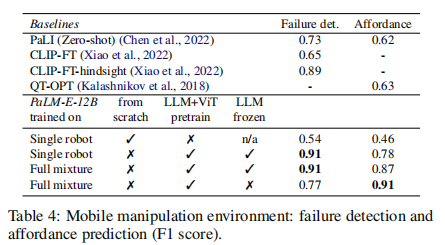
关键结果(表 4,更多数据可以参考原文表 9、表 10):
- affordance 预测与故障检测:PaLM-E-12B 全混合训练版本 F1 分数达 0.87-0.91,远超 PaLI(零样本 0.62-0.73)与 CLIP 微调模型(0.65-0.89)。
- 长视野规划落地:在真实厨房环境中完成端到端规划,可应对动态变化(如物体位置偏差),自主生成多步动作序列(图 5)。
2. 通用视觉 - 语言任务性能
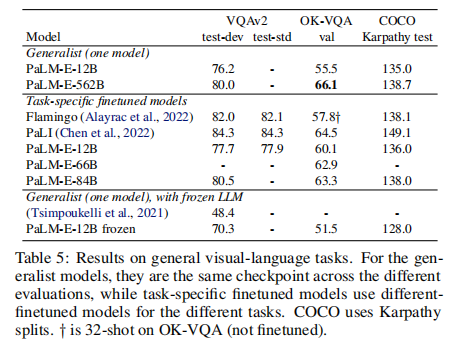
尽管非研究重点,PaLM-E 仍实现顶尖视觉 - 语言能力(表 5):
- OK-VQA 任务:PaLM-E-562B 以 66.1% 的成绩刷新 SOTA,超过专门微调的 PaLI(64.5%),无需任务特定微调。
- VQAv2 任务:PaLM-E-562B 达 80.0%,接近专门优化的模型(Flamingo 82.1%)。
- COCO Captioning:得分 138.7,与 Flamingo(138.1)相当,生成描述兼具细节与准确性。
3. 纯语言能力保留与规模效应
PaLM-E 通过规模提升缓解多模态训练带来的灾难性遗忘(图 6):
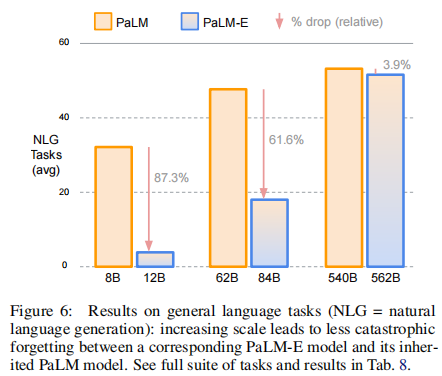
- 小模型(PaLM-E-12B):NLG 任务性能相对 PaLM-8B 下降 87.3%,遗忘严重。
- 大模型(PaLM-E-562B):NLG 任务性能仅下降 3.9%,NLU 任务甚至略有提升(+0.4%),保持了 PaLM-540B 的核心语言能力。
- 涌现能力:PaLM-E-562B 展现零样本多模态思维链(CoT)推理、多图像对比推理、无 OCR 数学推理等能力,尽管仅训练单图像样本(图 2)。

4. 消融实验关键发现
通过架构与训练策略消融,验证核心设计的有效性:
- 输入表征对比(表 1):3D 物体中心表征(OSRT)> ViT 通用表征 > 纯状态向量,空间感知对具身任务至关重要。
- 训练数据影响(图 3、图 4):全混合数据训练比单任务数据训练性能提升超 50%,跨任务迁移显著提升数据效率。
- LLM 冻结 vs 微调(图 4):端到端微调 LLM 性能优于冻结 LLM,但冻结方案可保留完整语言能力,适合对语言性能要求极高的场景。
六、核心创新与技术洞察
1. 架构创新:多模态无缝注入
- 摒弃传统 "视觉模型 + 语言模型 + 跨模态注意力" 的复杂设计,直接将多模态输入编码为 LLM 兼容的嵌入向量,复用 LLM 的自注意力机制处理跨模态关联,简化架构且提升效率。
- 动态多模态句子设计:多模态嵌入可插入文本任意位置(如 "对比<img1>和<img2>的差异"),比固定位置插入更灵活,适配复杂任务指令。
2. 训练创新:高效知识迁移
- 少量具身数据 + 大量通用数据:仅用 8.9% 的机器人数据,通过联合训练从互联网视觉 - 语言数据中迁移知识,解决机器人数据稀缺问题(如 Language-Table 任务 10 样本即可实现高成功率)。
- 规模缓解遗忘:首次证明 LLM 规模扩大可显著减少多模态训练带来的灾难性遗忘,为通用模型训练提供新范式。
3. 能力创新:具身与通用的统一
- 打破任务边界:单一模型同时胜任机器人规划、VQA、数学推理、代码生成等任务,无需针对不同任务设计专用架构,推动通用人工智能发展。
- 零样本泛化能力:借助 LLM 的世界知识与多模态对齐,实现对新物体、新场景、新任务的零样本 / 少样本适应(如未见过的物体组合、新机器人 embodiment)。
七、局限性与未来方向
1. 主要局限性
- 计算成本高:PaLM-E-562B 整合 540B PaLM 与 22B ViT,训练与推理需大规模算力支持,难以普及。
- 空间推理精度有限:对复杂几何关系(如物体精确距离、角度)的理解仍有不足,偶尔出现空间定位错误。
- 实时性不足:多模态编码与 LLM 推理 latency 较高,难以适配高速动态机器人任务。
- 幻觉问题:仍存在少量感知幻觉(如虚构物体属性),尤其在长文本生成与复杂场景中。
2. 未来研究方向
- 高效模型设计:通过模型压缩(如 LoRA 微调、量化)降低部署成本,适配边缘机器人设备。
- 增强空间与物理理解:引入专门的 3D 感知数据集与物理引擎模拟数据,提升具身推理的精准性。
- 人机协同优化:结合人类反馈强化学习(RLHF)优化具身决策,减少幻觉与执行失败。
- 多模态持续学习:实现模型在线学习新的传感器模态与机器人 embodiment,无需重新训练。
八、总结与行业影响
PaLM-E 的核心突破在于 **"以 LLM 为核心,构建具身与通用能力统一的多模态模型"**,其技术路线为具身智能发展提供了全新范式:无需设计复杂的跨模态模块,仅通过多模态输入直接注入与联合训练,即可让 LLM 具备真实世界感知与决策能力。
从行业影响来看,PaLM-E 为机器人、智能家居、工业自动化等领域带来关键技术支撑:
- 机器人开发:简化机器人高层规划系统设计,减少专用数据集采集成本,加速自主机器人落地。
- 人机交互:实现更自然的多模态指令交互(如 "帮我把桌上的红色盒子放到书架第三层"),提升用户体验。
- 通用 AI:推动 AI 从 "离线推理" 走向 "在线具身",为通用人工智能(AGI)的发展奠定基础。
尽管仍有局限性,PaLM-E 的出现标志着具身智能进入 "大模型驱动" 的新阶段,其多任务迁移、规模效应等核心发现,将持续影响后续多模态与机器人领域的研究方向。