1. 前景提要
首先:在生产环境不推荐使用任何深度学习技术对图像进行优化!在生产环境不推荐使用任何深度学习技术进行图像优化!在生产环境不推荐使用任何深度学习技术进行图像优化!本篇文章单纯记录一种显微镜细节增强领域的图像优化手段。仅供参考!!
根据显微镜不同的光源条件,拍摄的图片可能有明有暗。要怎么做到不管是明亮的图像还是灰暗的图像,他的图像细节都能够相对非常良好的展现出来?
我们会遇到各种各样的图像风格,如何让这些拍摄图像的风格趋近于统一成了一个值得研究的业务问题。
但是,图像风格迁移技术是一项非常耗费显存的技术,而显微镜拍摄的图像又要求有极高的分辨率。如果说我们将一张1600*1200的正常百倍镜图像传入模型进行训练的话。你光预测耗时就会非常的长。你的服务器成本会很高!更别说端到端客户端部署了。
所以我推荐将一张图像切分成多张512*512分辨率的图像,这样方便训练,集成和部署。
图像风格迁移技术
这里我们使用pix2pix(pytorch)来训练我们的图像分格迁移模型:github.com/junyanz/pyt...
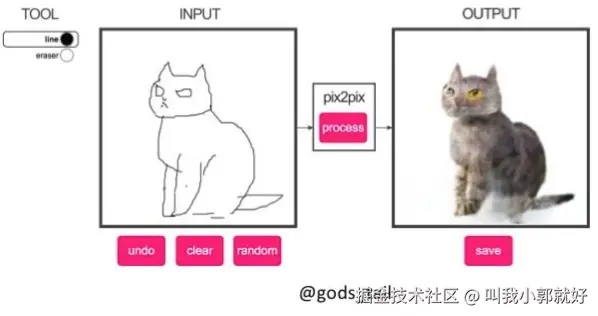
【图像来自pix2pix-pytorch的github首页】
上面这张图像简单说明了pix2pix是干啥的,说高大上点叫做图像风格迁移,说简单点就是将图片中的每一个像素根据预设的风格转换成新的一张图片。
训练
训练过程省略...
部署
1. 先将pytorch模型转换为onnx文件。这是部署的第一步!
python
import torch
import torch.onnx
from optim_algorithm.optim1.index import imageEnhanceModel
def convert_to_onnx(pytorch_model, dummy_input, output_path="model.onnx"):
pytorch_model.eval()
# 导出为ONNX
torch.onnx.export(
pytorch_model, # 模型
dummy_input, # 示例输入
output_path, # 输出文件路径
export_params=True, # 导出训练参数
opset_version=11, # ONNX算子集版本
do_constant_folding=True, # 优化常量折叠
input_names=['input'], # 输入节点名称
output_names=['output'], # 输出节点名称
dynamic_axes={ # 动态维度配置
'input': {0: 'batch_size'},
'output': {0: 'batch_size'}
}
)
print(f"模型已成功导出到 {output_path}")
# 创建动态尺寸的dummy_input
# 假设输入格式为 [batch, channel, height, width]
batch_size = 1 # 可以是任意值
channels = 3 # RGB图像
dummy_input = torch.randn(1, 3, 512, 512)
convert_to_onnx(imageEnhanceModel.model,dummy_input)这样我们就得到了一个图像优化的onnx文件。再传入netron.app/ 这个网站分析onnx结构。知道它的输入是什么。输出是什么。
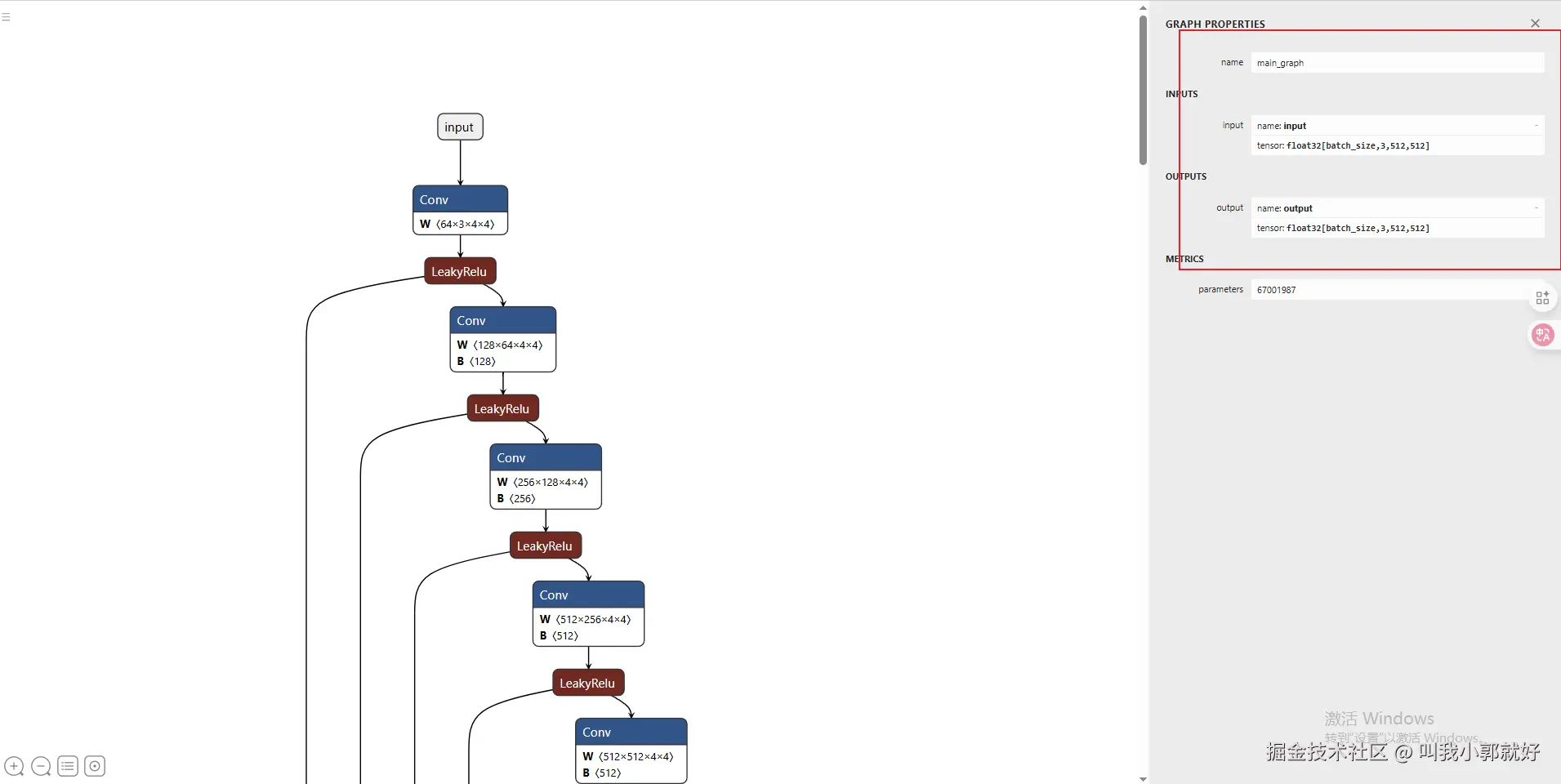
【netron可视化onnx节点】
从上图我们可以得知:
- onnx的输入是一个512*512的RGB图像。其batchSize可以是任意值。
- onnx的输出为一个float32类型的数组。数组元素为:512*512的RGB图像。
好了,现在我们就得到了一个可用的图像优化onnx了。现在我们来打通从图像输入->图像拆分拼图(每一个拼图为512*512,分辨率尺寸不够就填充白背景)->传入onnx模型优化->优化图像还原拼图->输出优化图
这样一个全过程!
全过程
图像前处理
python
from .index import optimProcess
import numpy as np
import cv2
def enhance_image(mat,shapes):
# 2. 更具shapes绘制mask
mask = np.zeros(mat.shape[:2], np.uint8)+255
for shape in shapes:
points = np.array(shape["points"]).astype(np.int32)
mask = cv2.drawContours(mask, points[np.newaxis, :, np.newaxis, :], 0, (0, 0, 0), cv2.FILLED)
return optimProcess(mat,mask)上面是图像的处理全过程,其中mat为输入的原图图像,shapes为labelme文件的shapes(labelme是啥不过多赘述)
optimProcess【图像处理】
python
def optimProcess(imageData,imageMask):
# 膨胀mask,防止分割范围过小缺失信息
kernel = np.ones((5, 5), np.uint8)
imageMask_dilate = copy.deepcopy(255 - cv2.dilate(255 - imageMask, kernel, iterations=2))
index2 = np.where(imageMask_dilate == 0)
if len(index2) != 0 and len(index2[1]) != 0:
x1 = np.min(index2[1])
x2 = np.max(index2[1])
y1 = np.min(index2[0])
y2 = np.max(index2[0])
# 提取roi区域进行优化
targetImageArray = imageData[y1: y2, x1: x2]
imageMask_roi = imageMask_dilate[y1: y2, x1: x2]
imageOptim = optimAllImage(targetImageArray,imageMask_roi)
# 得到优化图拼接回原图尺寸
imageOptim_all = np.zeros(imageData.shape, np.uint8) + 255
if len(imageOptim_all.shape) == 3 and len(imageOptim.shape) == 2:
imageOptim = cv2.cvtColor(imageOptim, cv2.COLOR_GRAY2BGR)
elif len(imageOptim_all.shape) == 2 and len(imageOptim.shape) == 3:
imageOptim = cv2.cvtColor(imageOptim, cv2.COLOR_BGR2GRAY)
imageOptim_all[y1: y2, x1: x2] = imageOptim
imageOptim_all = cv2.add(imageMask_dilate, imageOptim_all)
return imageOptim_all
else:
return imageDataoptimAllArray 【将根据mask裁剪的roi图像做拼图】
python
def optimAllImage(img,mask):
if len(img.shape) != 2:
image_array = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
if len(mask.shape) != 2:
mask = cv2.cvtColor(mask, cv2.COLOR_BGR2GRAY)
img = cv2.add(img, mask)
patchs,_,r_size = img2patchs(img,patch_size=(block_size, block_size), overlap_size=(overlap, overlap))
N = len(patchs)
M = len(patchs[0])
process_patchs = []
for n in range(N):
blocks = []
for m in range(M):
patch = patchs[n][m]
patch = predict(patch)
if len(patch.shape) != 2:
patch = cv2.cvtColor(patch, cv2.COLOR_BGR2GRAY)
blocks.append(patch.astype(np.uint8))
process_patchs.append(blocks)
recovery_img = patchs2img(process_patchs, r_size, (overlap, overlap))
return recovery_img单独优化每一块拼图
img2patchs
python
def img2patchs(img,patch_size=(block_size, block_size), overlap_size=(overlap, overlap)):
h, w = img.shape
ph, pw = patch_size
oh, ow = overlap_size
r_h = (h - ph) % (ph - oh)
r_w = (w - pw) % (pw - ow)
target_w, target_h = w, h
if not (h >= ph > oh and w >= pw > ow):
return [[img]], (target_h, target_w), (0, 0)
N = math.ceil((target_h - ph) / (ph - oh)) + 1
M = math.ceil((target_w - pw) / (pw - ow)) + 1
patchs_all = []
for n in range(N):
patchs_row = []
for m in range(M):
if n == N - 1:
ph_start = target_h - ph
else:
ph_start = n * (ph - oh)
if m == M - 1:
pw_start = target_w - pw
else:
pw_start = m * (pw - ow)
patch = img[ph_start:(ph_start + ph), pw_start:(pw_start + pw)]
patchs_row.append(patch)
patchs_all.append(patchs_row)
return patchs_all, (target_h, target_w), (r_h, r_w)predict
python
def predict(image):
# 将image从bgr转换为rgb
image = process_input_image(image,512)
image = np.array(image)
mean = (127,127,127)
std = (127,127,127)
img_tensor = (image - mean) / std
img_tensor = img_tensor.astype('float32')
img_tensor = np.transpose(img_tensor, (2, 0, 1))
img_tensor = np.expand_dims(img_tensor, axis=0)
ort_inputs ={"input": img_tensor}
output = ort_session.run(['output'], ort_inputs)
output = convert_to_numpy(output)
output = clip_image(output, image, 512)
h1, w1 = image.shape[:2]
h2, w2 = output.shape[:2]
pad_h = h1 - h2
pad_w = w1 - w2
if pad_h > 0:
output = np.pad(output, ((0, pad_h), (0, 0), (0, 0)), mode='constant', constant_values=255)
else:
output = output[:h1, :, :]
if pad_w > 0:
output = np.pad(output, ((0, 0), (0, pad_w), (0, 0)), mode='constant', constant_values=255)
else:
output = output[:, :w1, :]
return outputpatchs2img【还原拼图】
python
def patchs2img(patchs, r_size, overlap_size=(20, 20)):
N = len(patchs)
M = len(patchs[0])
# print("N:{}, M:{}".format(N, M))
oh, ow = overlap_size
patch_shape = patchs[0][0].shape
ph, pw = patch_shape[:2]
r_h, r_w = r_size
mode = 'GRAY' if len(patch_shape) == 2 else 'RGB'
if N == 1 and M == 1:
return_img = patchs[0][0]
return return_img# if mode == 'RGB' else cv2.cvtColor(return_img, cv2.COLOR_GRAY2RGB)
row_imgs = []
for n in range(N):
row_img = patchs[n][0]# if mode == 'RGB' else cv2.cvtColor(patchs[n][0], cv2.COLOR_GRAY2RGB)
for m in range(1, M):
if m == M - 1 and r_w != 0:
ow_new = pw - r_w
else:
ow_new = ow
# ow_new = ow
patch = patchs[n][m]# if mode == 'RGB' else cv2.cvtColor(patchs[n][m], cv2.COLOR_GRAY2RGB)
# print(mode, patch.shape)
h, w = row_img.shape[:2]
new_w = w + pw - ow_new
big_row_img = np.zeros((h, new_w), dtype=np.uint8)
big_row_img[:, :w - ow_new] = row_img[:, :w - ow_new]
big_row_img[:, w:] = patch[:, ow_new:]
overlap_row_01 = row_img[:, w - ow_new:]
overlap_row_02 = patch[:, :ow_new]
# get weight
weight = vertical_grad(overlap_row_01.shape, 0, 255, mode='w') / 255
overlap_row = (overlap_row_01 * (1 - weight)).astype(np.uint8) + (overlap_row_02 * weight).astype(np.uint8)
big_row_img[:, w - ow_new:w] = overlap_row
row_img = big_row_img
row_imgs.append(row_img)
column_img = row_imgs[0]
for i in range(1, N):
if i == N - 1 and r_h != 0:
oh_new = ph - r_h
else:
oh_new = oh
# oh_new = oh
row_img = row_imgs[i]
h, w = column_img.shape[:2]
new_h = h + ph - oh_new
big_column_img = np.zeros((new_h, w), dtype=np.uint8)
big_column_img[:h - oh_new, :] = column_img[:h - oh_new, :]
big_column_img[h:, :] = row_img[oh_new:, :]
overlap_column_01 = column_img[h - oh_new:, :]
overlap_column_02 = row_img[:oh_new, :]
# get weight
weight = vertical_grad(overlap_column_01.shape, 0, 255, mode='h') / 255
overlap_column = (overlap_column_01 * (1 - weight)).astype(np.uint8) + (overlap_column_02 * weight).astype(np.uint8)
big_column_img[h - oh_new:h, :] = overlap_column
column_img = big_column_img
return column_img优化效果
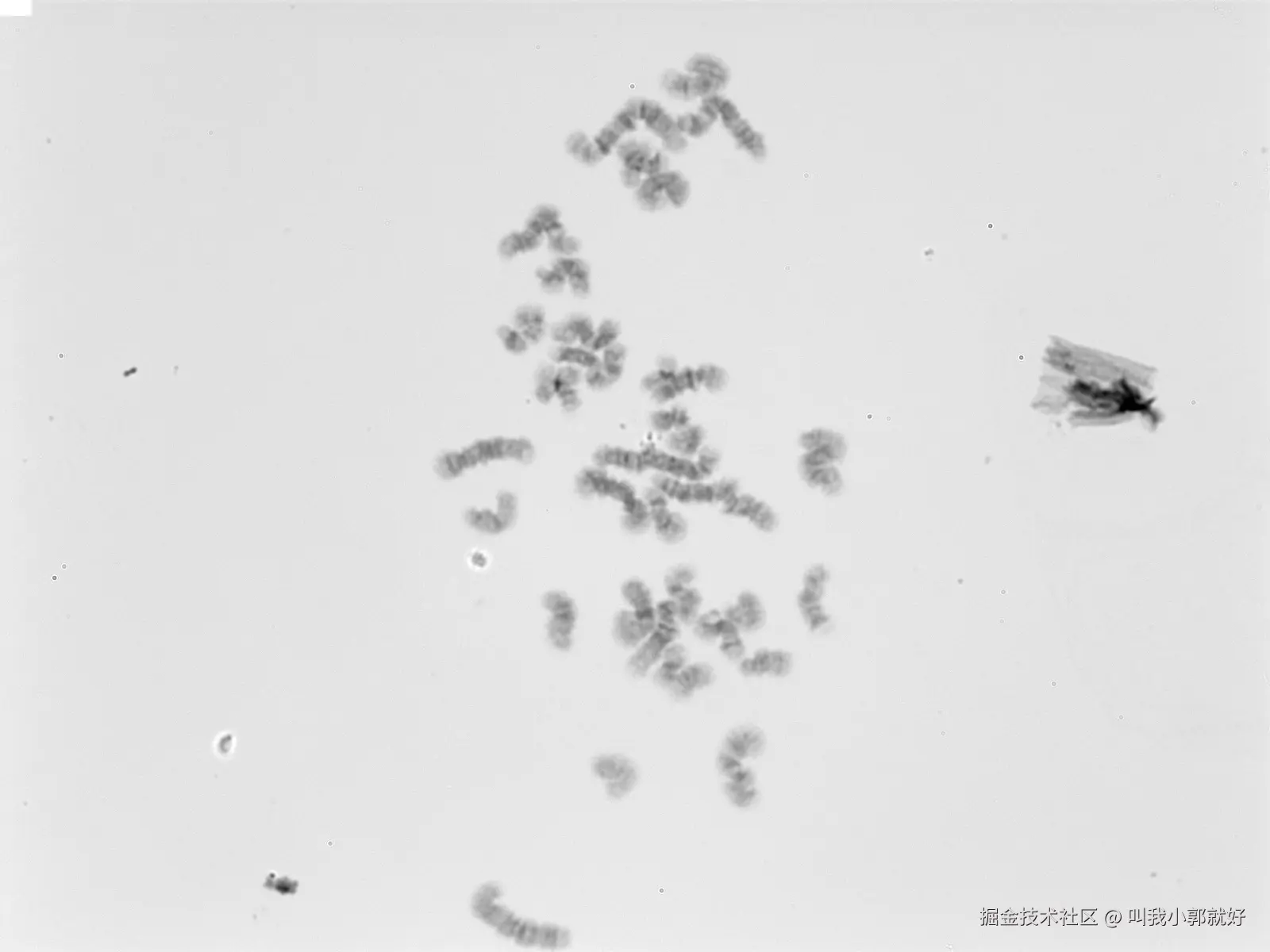
【原图】

【优化图】
再次警告!不推荐使用深度学习技术在显微成像领域做图像优化,本篇文章纯粹记录本人练习onnx模型部署有感而发!不推荐在生产环境用深度学习技术做图像优化!