LLaMA系列文章:
继 LLaMA 1 的"小而强"、LLaMA 2 的"对齐进化"之后,LLaMA 3 带着更大规模的数据、更强的推理能力以及完全开放的商用许可横空出世。Meta 声称:LLaMA 3-70B 在多个任务中已逼近甚至超越 GPT-3.5,并将在未来挑战 GPT-4 的王座。

本文将带你全面了解 LLaMA 3 的技术细节、性能表现和应用前景,看它如何成为"开源阵营的最强音"。
所有相关源码示例、流程图、模型配置与知识库构建技巧,我也将持续更新在Github:LLMHub,欢迎关注收藏!
可以带着下面三个问题阅读本文:
- LLaMA 3 相较于 LLaMA 2 有哪些实质性突破?
- 它是如何在不开源训练集的情况下做到性能领先的?
- 相比 GPT-4、Claude 3,LLaMA 3 的开放策略有哪些优势?
一、LLaMA 3 是什么?
LLaMA 3 是 Meta 于 2024 年 4 月发布的新一代基础大语言模型系列。

首次推出了两个主力版本:
- LLaMA 3-8B
- LLaMA 3-70B
这些模型均为 全开源、商用免费,支持基础任务和对话任务(LLaMA 3-Instruct),是 Meta 在开源大模型道路上的又一次大步前行。
Llama 3 旨在打造媲美现有闭源模型的最强开源大语言模型,同时吸收开发者反馈,提升模型的整体可用性与安全性。我们秉持"早发布、多发布"的开源理念,让社区在模型开发期间即可使用。首批发布的是文本模型,后续将推出多语言、多模态、更长上下文窗口与更强推理能力版本。
二、技术亮点:真正的第三代基础模型
LLaMA3的模型结构仍然是基于transformer的自回归预测。
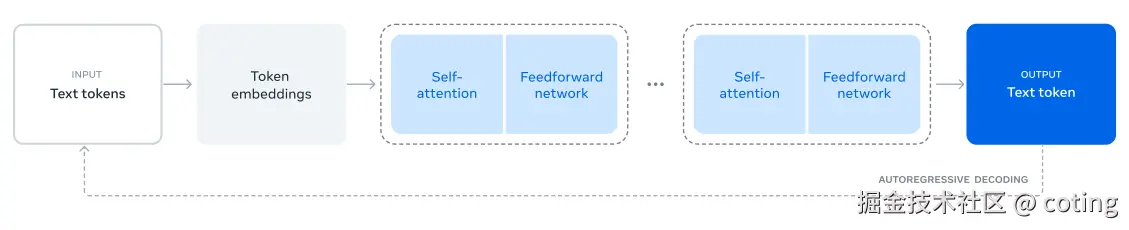
2.1训练数据全面升级(虽然未开源)
- 总量高达 15T tokens,是 LLaMA 2 的 7.5 倍;
- 覆盖 30 多种语言,更具全球适应性;
- 加入 代码、数学、长文本文档、学术论文 等多种复杂语料;
- 数据源仍未公开,但明确不包含用户私有数据,使用了过滤与质量评分机制。
2.2 架构创新
虽然 LLaMA 3 沿用了 Transformer 架构,但进行了大量工程改进:
- 上下文长度默认 8K,未来支持最多 128K;
- 精细设计了 tokenizer(tiktoken 兼容),压缩率更高;
- 使用了新的数据混合策略(data mixture strategy),提升多任务泛化能力;
- 全面支持 FP16 / BF16 / INT8 推理,适配主流硬件部署。
2.3 训练创新
- 训练过程采用数据、模型、流水线三重并行,在定制 24K GPU 集群上运行,最大 GPU 利用率超过 400 TFLOPS。
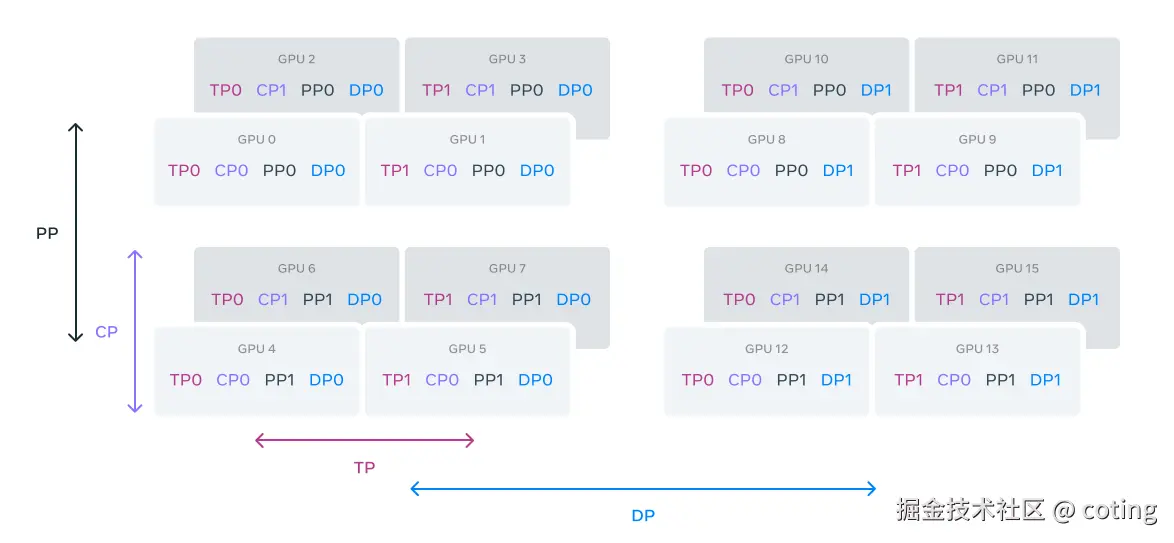
GPU按照TP(tensor parallelism)、CP(context parallelism)、PP(pipeline parallelism)、DP(data parallelism)的顺序被划分为并行组。在此示例中,16个GPU被配置为组大小为|TP| =2,|CP| =2,|PP| =2和|DP| =2的值。GPU在4D并行性中的位置被表示为向量D1,D2,D3,D4,其中Di是第i个并行性维度上的索引。在该示例中,GPU0TP0,CP0,PP0,DP0和GPU1TP1,CP0,PP0,DP0在相同的TP组中,GPU0和GPU2在相同的CP组中,GPU0和GPU4在相同的PP组中,并且GPU0和GPU8在相同的DP组中。
- 新训练堆栈支持自动错误检测与修复、存储优化、数据回滚等功能 ,Llama 3 训练效率比 Llama 2 提高约 3 倍,GPU 利用率达 95%+。
三、对话模型 LLaMA 3-Instruct 的对齐策略
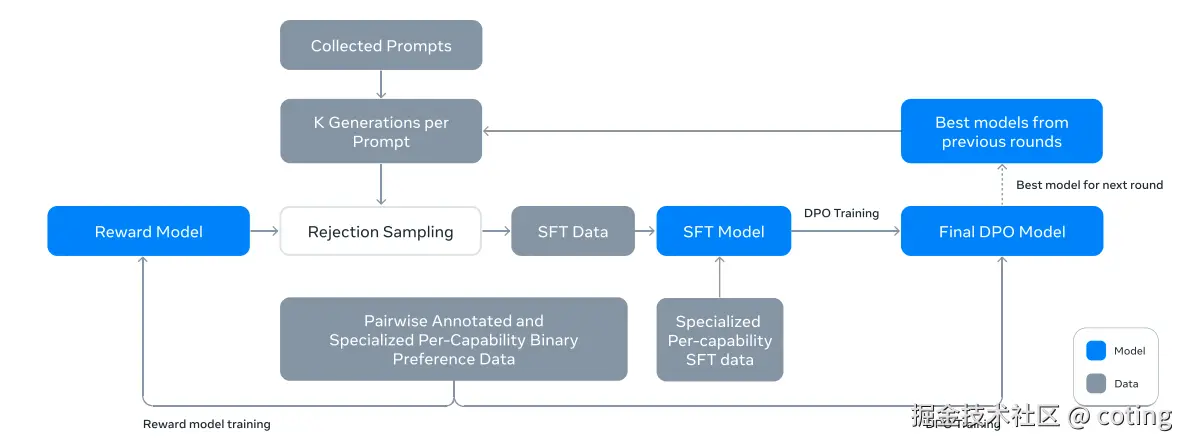
不同于 LLaMA 2,LLaMA 3-Instruct 结合了:
- 监督微调(SFT)
- 拒绝采样
- PPO(近端策略优化)
- **DPO(直接偏好优化) **
- 安全性测试、拒答机制和红队评估,并采用了 Meta 自研的 自我验证机制(Reflexion)
LLaMa 3执行多步规划、推理和工具调用以解决任务的步骤如下图:
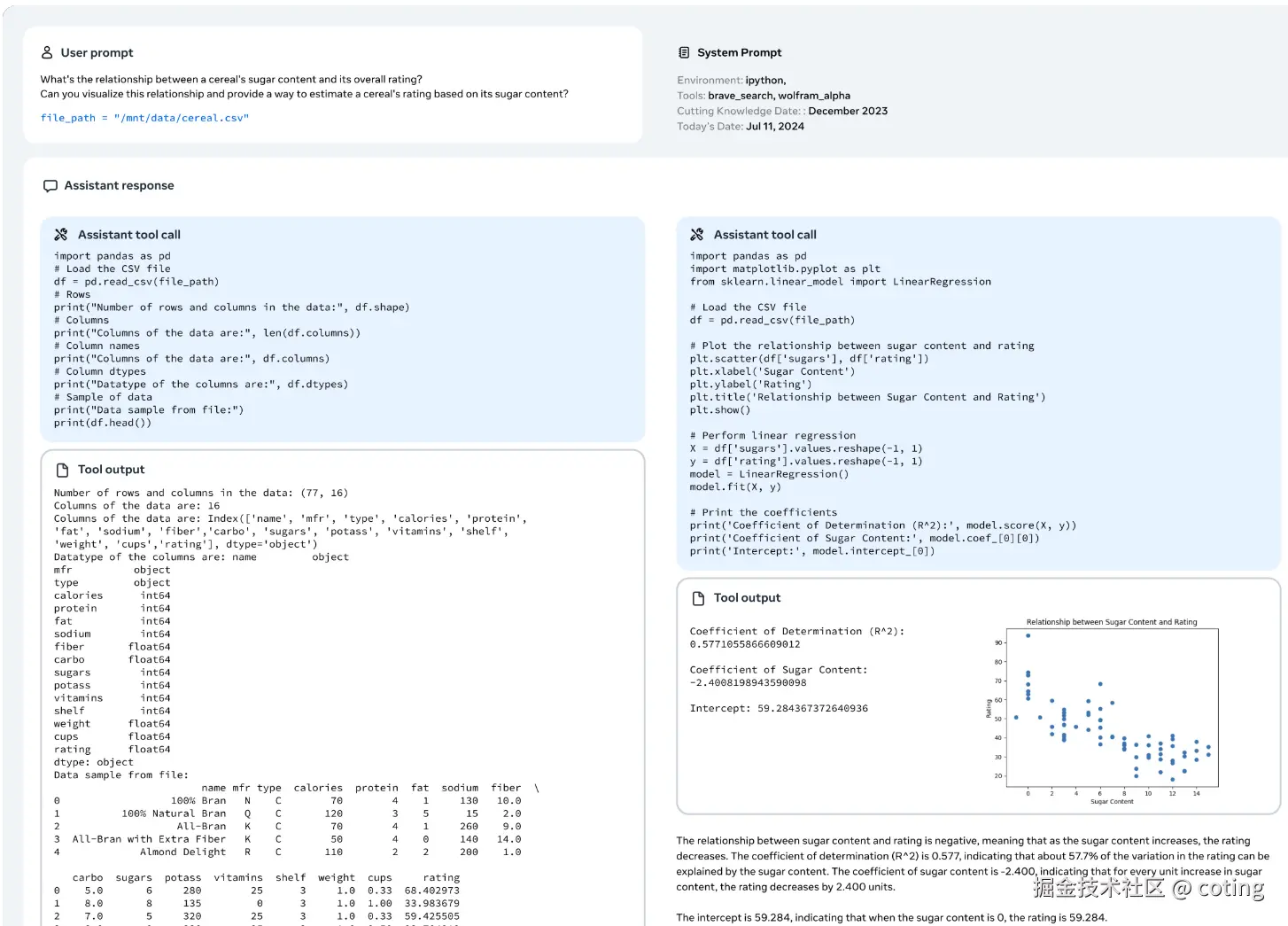
这些机制共同确保了 内容连贯性、回答风格友好、安全性增强,并可在开源中自由部署到 RAG、Agent、文档问答等系统中。
四、优点
LLaMA 3 除了性能提升,更重视开放性:
- 完全免费开源,采用 Apache 2.0 协议;
- 可商用、可微调、可用于私有部署(无授权障碍);
- 支持 HuggingFace、Torch、Transformers、vLLM 等主流平台和框架。
同时,Meta 与 AWS、Azure、Google Cloud、NVIDIA、Snowflake 等达成深度适配,从研发到生产一条龙。
并且LLaMa3之后就支持多模态输入:
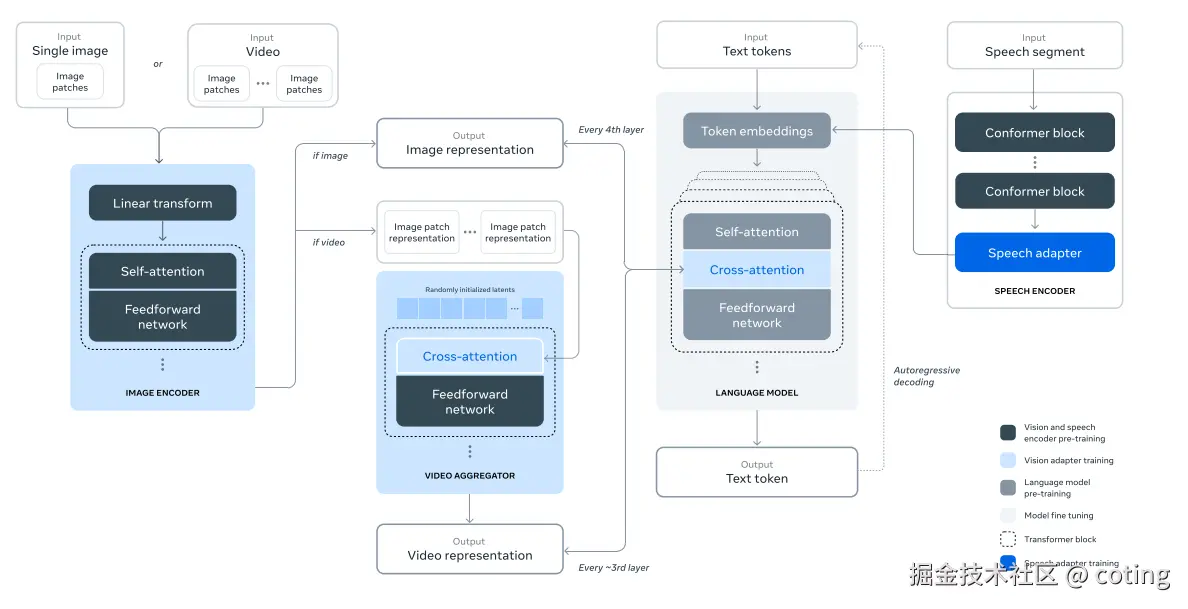
- 更强指令跟随模型
- 多模态输入(图文理解、PDF、音频)
- 更长上下文支持(最高至 128K)
- 可结合 RAG、工具使用、插件等 Agent 架构
最后我们回答一下文章开头提出的问题:
- LLaMA 3 相较于 LLaMA 2 有哪些实质性突破?
LLaMA 3 相较于 LLaMA 2 的实质性突破主要在于更优化的模型架构设计、更高质量和多样化的训练数据、以及更先进的对齐技术,使得模型在理解复杂任务和生成准确文本方面能力显著提升。
- 它是如何在不开源训练集的情况下做到性能领先的?
LLaMA 3 在不开源训练集的情况下,通过充分整合公开和授权数据,结合高效的训练技术和强化学习与人类反馈(RLHF)策略,实现了性能上的领先。
- 相比 GPT-4、Claude 3,LLaMA 3 的开放策略有哪些优势?
相比 GPT-4 和 Claude 3,LLaMA 3 的开放策略优势体现在模型权重和技术细节更为开放,支持本地部署和定制,降低使用门槛,促进社区创新与生态发展。
关于深度学习和大模型相关的知识和前沿技术更新,请关注公众号coting!