引言
在为应用程序添加缓存时,首先需要考虑缓存策略。缓存策略决定了从缓存和底层存储(如数据库或服务)进行读写操作的方式。
从高层次来看,你需要决定在发生缓存未命中(cache miss)时,缓存是被动还是主动的。也就是说,当应用程序从缓存中查找一个值但该值不存在或已过期时,缓存策略会决定是由应用程序还是缓存本身从底层存储中获取数据。不同的缓存策略在延迟和复杂性之间存在不同的权衡,下面我们将逐一探讨。

1. 缓存旁路(Cache-Aside Caching)
缓存旁路是最常见的缓存策略之一。当缓存命中(cache hit)时,数据访问延迟主要由通信延迟决定,通常较小,因为缓存可以部署在靠近应用程序的缓存服务器上,甚至直接在应用程序的内存中。
但在缓存未命中时,缓存是被动存储,由应用程序负责更新缓存。即缓存仅报告未命中,应用程序需要从底层存储中获取数据并更新缓存。
工作流程
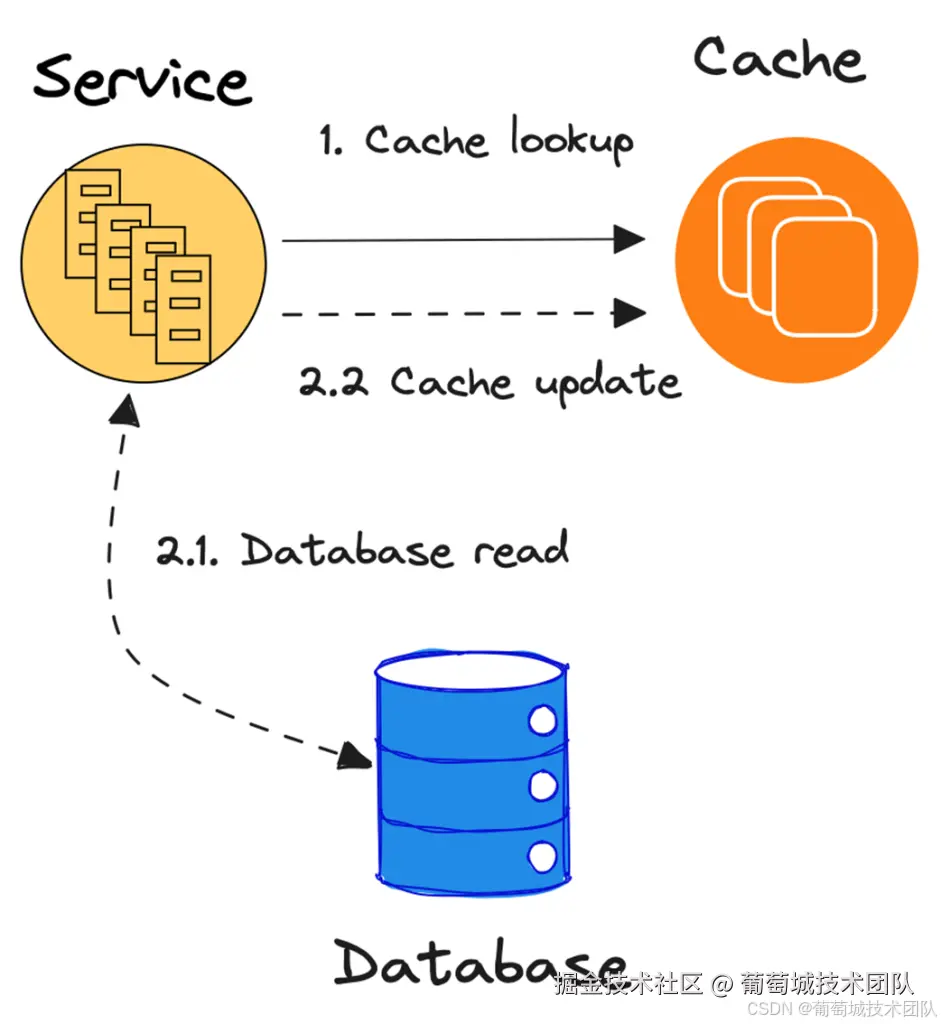
如图 1 所示,应用程序通过缓存键(cache key)从缓存中查找值。缓存键决定了应用程序需要的数据。
- 如果键存在于缓存中,缓存返回与该键关联的值,应用程序直接使用。
- 如果键不存在或已过期(缓存未命中),应用程序需要处理这种情况。应用程序从底层存储(通常是数据库)查询数据,并将结果存储到缓存中。
例如,假设你正在缓存用户信息,并使用用户 ID 作为查找键。在缓存未命中的情况下,应用程序通过用户 ID 从数据库查询用户信息,将查询结果转换为适合缓存的格式(例如 JSON),然后以用户 ID 为键、用户信息为值更新缓存。
优点
缓存旁路之所以流行,是因为它易于实现。开发者可以轻松设置一个缓存服务器(如 Redis),用于缓存数据库查询或服务响应。缓存服务器是被动的,不需要了解底层数据库的细节或数据的映射方式,所有缓存管理和数据转换都由应用程序完成。
在许多场景中,缓存旁路是降低应用延迟的简单有效方法。通过将最相关的数据存储在靠近应用程序的缓存服务器中,可以隐藏数据库访问的延迟。
缺点
- 数据一致性问题:如果有多个并发读者同时查找同一键,应用程序需要协调并发缓存未命中的处理,否则可能导致多次数据库访问和缓存更新,进而造成后续缓存查询返回不一致的值。
- 事务支持缺失:由于缓存和数据库互不了解,应用程序需要负责协调数据更新,因此无法提供事务支持。
- 尾部延迟(tail latency):缓存未命中时,访问延迟取决于数据库的读取延迟。虽然缓存命中时访问很快,但未命中的情况会导致显著的延迟,因此数据库的地理位置延迟仍然很重要。
2. 读穿缓存(Read-Through Caching)
与缓存旁路不同,读穿缓存 在缓存未命中时是主动的。当发生缓存未命中,读穿缓存会自动从底层存储中读取键对应的值。延迟与缓存旁路类似,但底层存储的检索延迟是从缓存到存储的延迟,而非从应用程序到存储的延迟,这可能因部署架构而有所减少。
工作流程
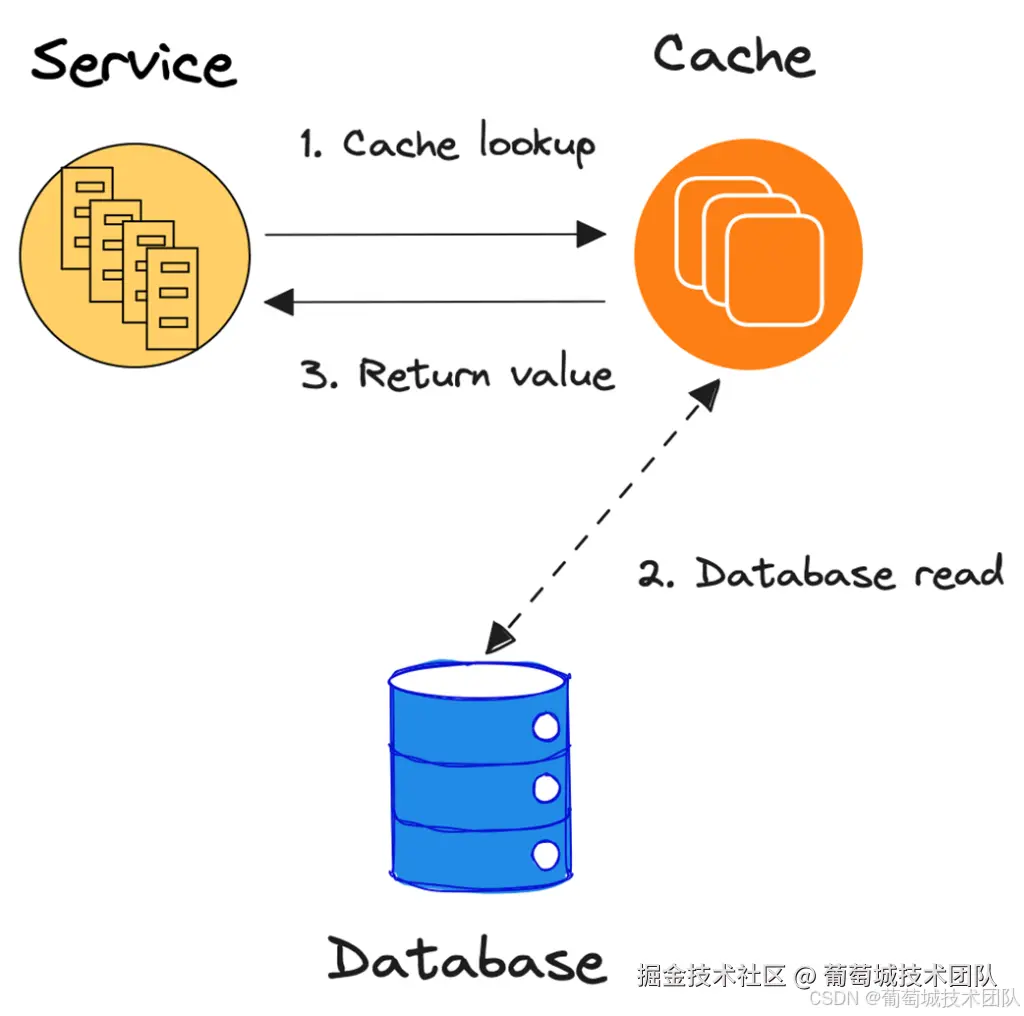
如图 2 所示,应用程序通过键从缓存中查找数据。如果缓存未命中,缓存会自动从数据库中查询该键的值,更新自身缓存,并将值返回给应用程序。从应用程序的角度看,缓存未命中是透明的,因为缓存始终返回键对应的值,无论是否发生未命中。
优点
- 一致性保证:由于缓存负责协调数据库读取和更新,它可以在并发缓存未命中时保证一致性,并为应用程序提供事务支持。
- 简化应用程序逻辑:缓存接管了缓存管理,降低了应用程序的复杂性。
缺点
- 实现复杂性:缓存需要能够访问底层存储,并将数据库查询结果转换为适合缓存的格式(例如将 SQL 查询结果转为 JSON)。这使得缓存与应用程序的数据模型和格式更紧密耦合。
- 尾部延迟:与缓存旁路类似,缓存未命中时的延迟取决于数据库访问速度。不过,读穿缓存可以通过**预刷新(refresh-ahead)**等技术异步更新缓存,在值过期前提前更新,从而隐藏数据库访问延迟。
3. 写穿缓存(Write-Through Caching)
缓存旁路和读穿缓存主要针对读操作的缓存策略,但有时也需要缓存支持写操作。在这种情况下,缓存提供了一个接口,允许应用程序更新键的值。对于缓存旁路,应用程序直接与底层存储通信并更新缓存;而对于读穿缓存,写操作有两种策略:写穿缓存 和写后缓存。
写穿缓存是一种策略,当缓存被更新时,会立即将更新传播到底层存储。写操作的延迟主要由底层存储的写延迟决定,这可能较高。
工作流程
如图 3 所示,应用程序通过缓存提供的接口更新键值对。缓存先更新自身状态,然后同步更新数据库,等待数据库提交更新后才确认缓存更新。 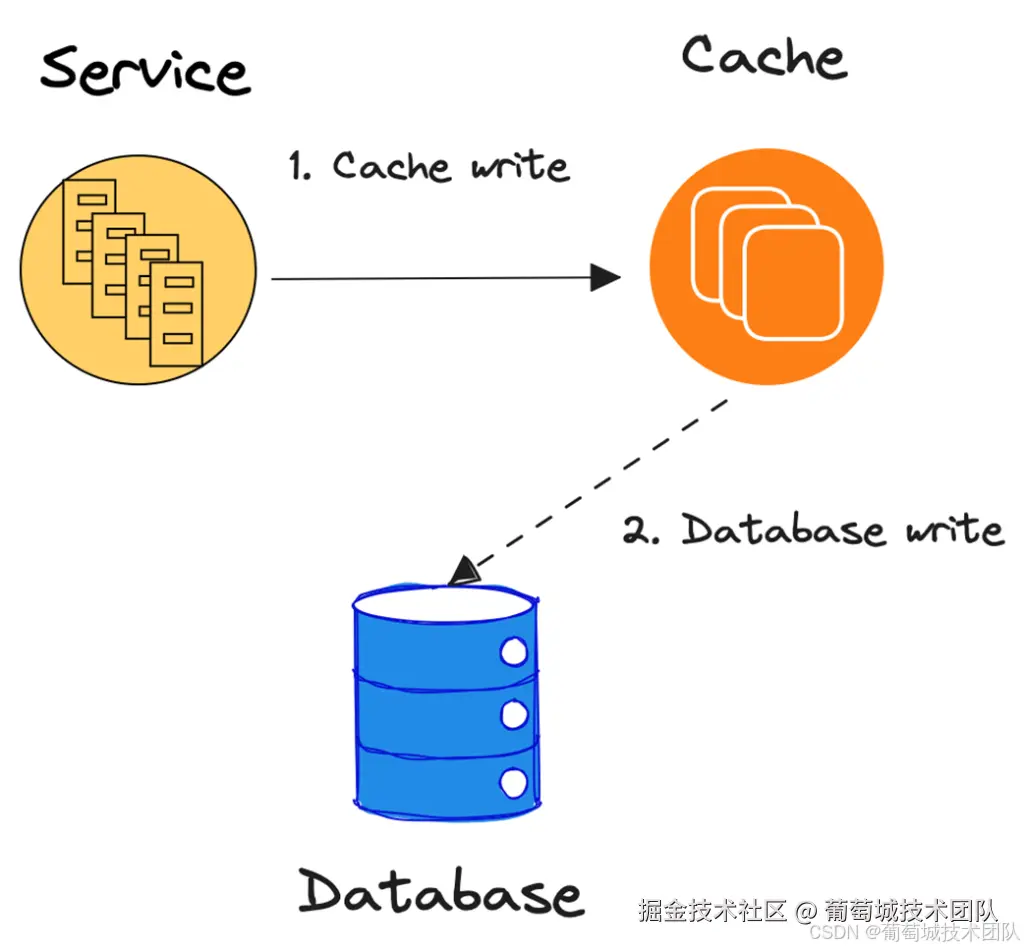
优点
- 数据同步:写穿缓存旨在保持缓存和底层存储的同步。
- 事务支持:通过牺牲一些延迟,写穿缓存可以提供事务保证,确保缓存和数据库要么都更新,要么都不更新。
缺点
- 复杂性:与读穿缓存类似,缓存需要能够连接数据库,并将缓存值转换为数据库查询。例如,如果缓存存储的是 JSON 格式的用户数据,缓存需要将 JSON 转换为数据库更新。
- 写延迟高:写操作的延迟等同于数据库的提交延迟,可能较高。
- 一致性风险:对于非事务性缓存,如果缓存更新成功但数据库更新失败,可能会导致缓存与数据库不一致。
4. 写后缓存(Write-Behind Caching)
与写穿缓存不同,写后缓存会立即更新缓存,但延迟更新底层存储。缓存可能会接受多次更新,然后批量更新到数据库。
工作流程
如下图所示,缓存接受多个更新(例如三次缓存更新),然后再将这些更新批量写入数据库。 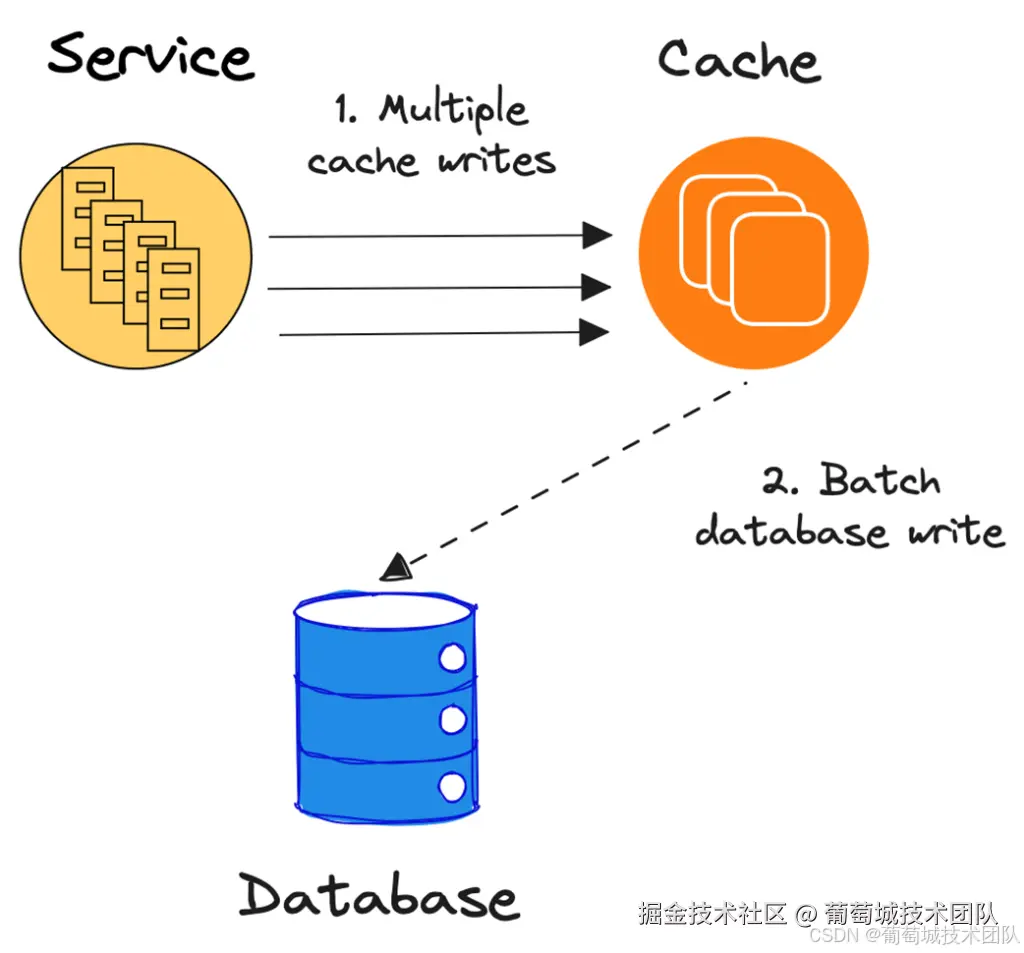
优点
- 低写延迟:由于底层存储的更新是异步的,缓存可以立即确认写操作,写延迟较低。
- 批量更新:通过批量处理更新,减少了对数据库的访问压力。
缺点
- 事务支持缺失:缓存无法保证缓存和数据库的同步,可能导致数据不一致。
- 数据丢失风险:如果缓存崩溃且未将更新写入底层存储,可能会丢失数据,降低数据的持久性。
5. 客户端缓存(Client-Side Caching)
客户端缓存将缓存置于应用程序的客户端层。尽管缓存服务器(如 Redis)使用内存缓存,但应用程序仍需通过网络(如 Redis 协议)访问缓存。
如果应用程序是运行在数据中心的服务器,缓存服务器是理想的选择,因为数据中心内的网络延迟低,且缓存复杂性由缓存服务器处理。然而,对于用户设备上的应用程序,最后一公里的延迟可能显著影响用户体验,因此客户端缓存非常有吸引力。
工作流程
客户端缓存将缓存直接置于应用程序内,通常结合读穿缓存 和写后缓存以获得最佳延迟性能。客户端通常无法直接访问数据库,而是通过代理或 API 服务器间接访问。
优点
- 低延迟:读写操作都在客户端本地完成,延迟极低。
- 适合简单读缓存:对于需要低延迟的场景(如本地优先的应用程序),客户端缓存是理想选择。
缺点
- 事务支持困难:由于数据库访问存在间接层和高延迟,事务支持难以实现。
- 内存占用:客户端缓存会增加应用程序的内存消耗,因为需要存储缓存数据。
6. 分布式缓存(Distributed Caching)
目前讨论的缓存策略假设只有一个缓存实例,例如在应用程序内缓存或单一 Redis 服务器。然而,为了降低地理位置延迟或扩展工作负载,通常需要多个缓存副本。
分布式缓存 涉及多个独立工作或组成集群的缓存实例。分布式缓存需要考虑数据分区 和复制:
- 分区:缓存数据分布在不同节点上,避免每个节点存储所有数据。
- 复制:为实现高可用性和降低访问延迟,数据分区可以在多个节点上复制。
优点
- 地理延迟降低:通过在不同地理位置部署缓存实例,减少访问延迟。
- 可扩展性:支持更大的工作负载。
缺点
- 复杂性增加:分布式缓存需要处理分区和复制的复杂性,可能引入一致性问题或额外的管理开销。
总结
每种缓存策略在延迟和复杂性之间都有不同的权衡:
- 缓存旁路:简单易用,但需要应用程序管理缓存,可能导致一致性问题和尾部延迟。
- 读穿缓存:缓存主动处理未命中,降低应用程序复杂性,但需要更紧密的耦合。
- 写穿缓存:保持缓存与数据库同步,但写延迟高。
- 写后缓存:写延迟低,但可能牺牲一致性和持久性。
- 客户端缓存:适合低延迟场景,但增加内存占用且事务支持困难。
- 分布式缓存:适合大规模、低延迟场景,但复杂性高。
| 参考资料 :本文改编自 Pekka Enberg 的文章,结合国内技术社区的反馈整理而成。 |
|---|