Python-HTML-爬虫:爬取《某某小说》 小说章节和内容完整版
- 所有章节和内容已成功获取
- [html 分析 详情页面](#html 分析 详情页面)
- 代码示列
- web前端快速入门学习地址
所有章节和内容已成功获取
- 示列
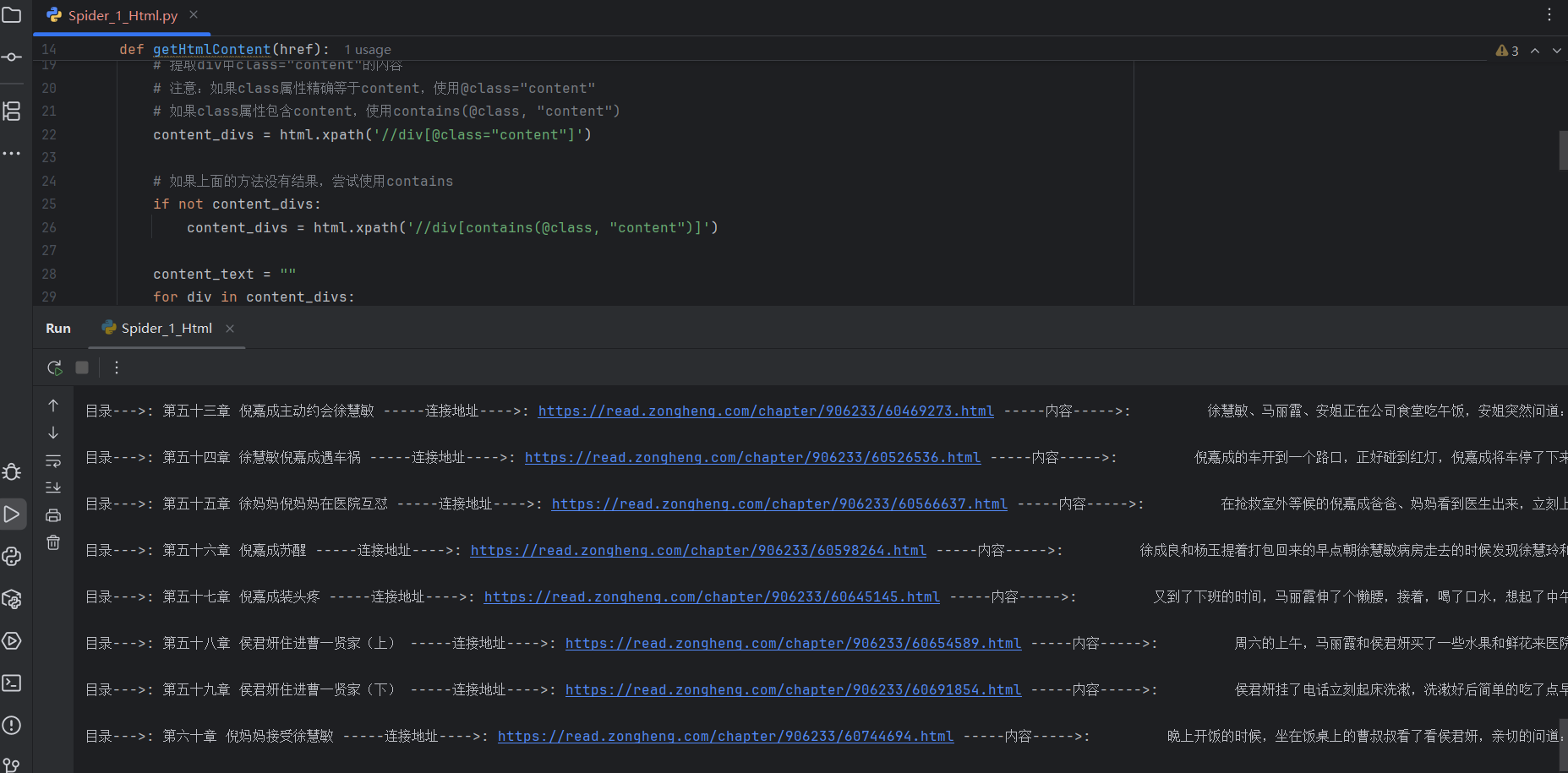
html 分析 详情页面
-
在代码中获取到这个连接地址
-
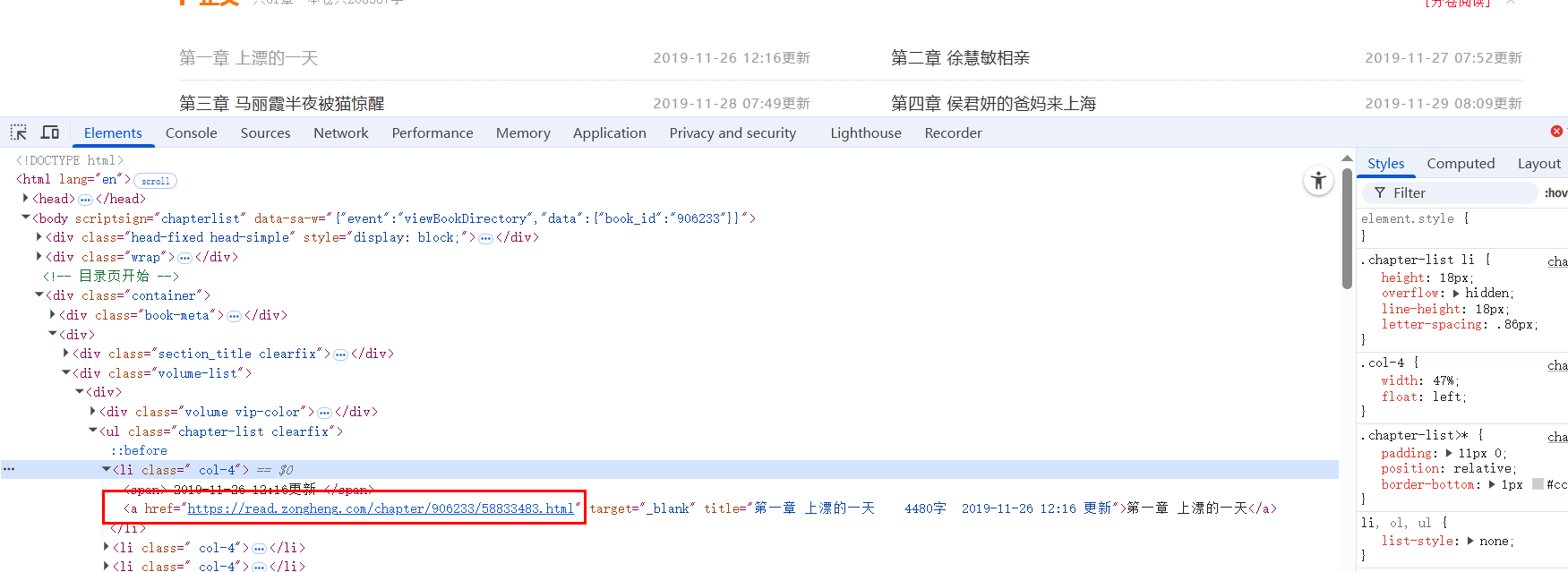
-
详情页面HTML 中 正文部分
-
代码示列
python
import requests
from lxml import etree
#使用requests库获取网页内容
# 爬取 地址为 https://huayu.zongheng.com/showchapter/906233.html 的网页内容
# 注意,1单独爬取静态网页,2动态网页需要使用selenium
# 请熟练使用 requests库,
# 普法:政府类网站不能爬,公民信息不能保存,大公司网站不要爬,容易被追踪,涉及版权知识产权的信息不要爬,容易惹纠纷。
# 爬取 名为:《某某小说》 的小说章节
def getHtmlContent(href):
req = requests.get(href)
# 使用lxml解析HTML内容
html = etree.HTML(req.text)
# 提取div中class="content"的内容
# 注意:如果class属性精确等于content,使用@class="content"
# 如果class属性包含content,使用contains(@class, "content")
content_divs = html.xpath('//div[@class="content"]')
# 如果上面的方法没有结果,尝试使用contains
if not content_divs:
content_divs = html.xpath('//div[contains(@class, "content")]')
content_text = ""
for div in content_divs:
# 提取div内的文本内容
text = div.text if div.text else ""
# 也要提取div内所有子元素的文本
for elem in div.iter():
if elem.text and elem != div:
text += elem.text
if elem.tail:
text += elem.tail
content_text += text + "\n"
return content_text
if __name__ == '__main__':
url = "https://huayu.zongheng.com/showchapter/906233.html"
req = requests.get(url)
# 使用lxml解析HTML内容
html = etree.HTML(req.text)
# 提取<li class="col-4">下的<a>标签内容
# 注意:class属性中有空格,需要使用contains函数来匹配
li_elements = html.xpath('//li[contains(@class, "col-4")]')
for li in li_elements:
# 查找每个li元素中的a标签
a_tags = li.xpath('.//a')
for a in a_tags:
# 输出a标签的文本内容
print("目录--->:", a.text ,"-----连接地址---->:",a.get('href'),"-----内容----->:",getHtmlContent(a.get('href')))