文章目录
- Socket编程预备
-
- 网络通信的本质
- 认识端口号Port
-
- 端口号的大致使用流程
- 端口号的划分
- [port vs pid](#port vs pid)
- 理解socket(套接字)
- 传输层的代表------TCP、UDP
- 网络字节序
- Socket编程接口初步认识(宏观)
Socket编程预备
有了对网络工作的整体认识,现在我们需要了解一下关于网络编程需要知道的话题!能够以方便我们后序快速上手编写代码!
网络通信的本质
我们已经知道了网络传输的基本流程!但是,网络通信的目的仅仅是为了传输吗?
答案是当然不是,网络通信只是手段!真正要通信的是人!人需要收发、处理数据!
所以,网络、计算机都是工具!是人使用它们来进行通信的!但是,我们用户是以什么样的方式来使用计算机的资源的呢?
其实早有讲过,我们用户只要是使用资源,都是通过进程 作为载体的!
我们使用的操作,最终在操作系统看来,都是一个个的进程!
所以,未来我们看待网络通信的时候(比如正在使用一个软件):
我们要在客户端发送数据,本质上就是把数据交付给对应进程,然后网络传输发送给服务器端的进程!所以,上网只有两种行为:
1.从远端服务器获取数据
2.将本地数据发送到远端服务器
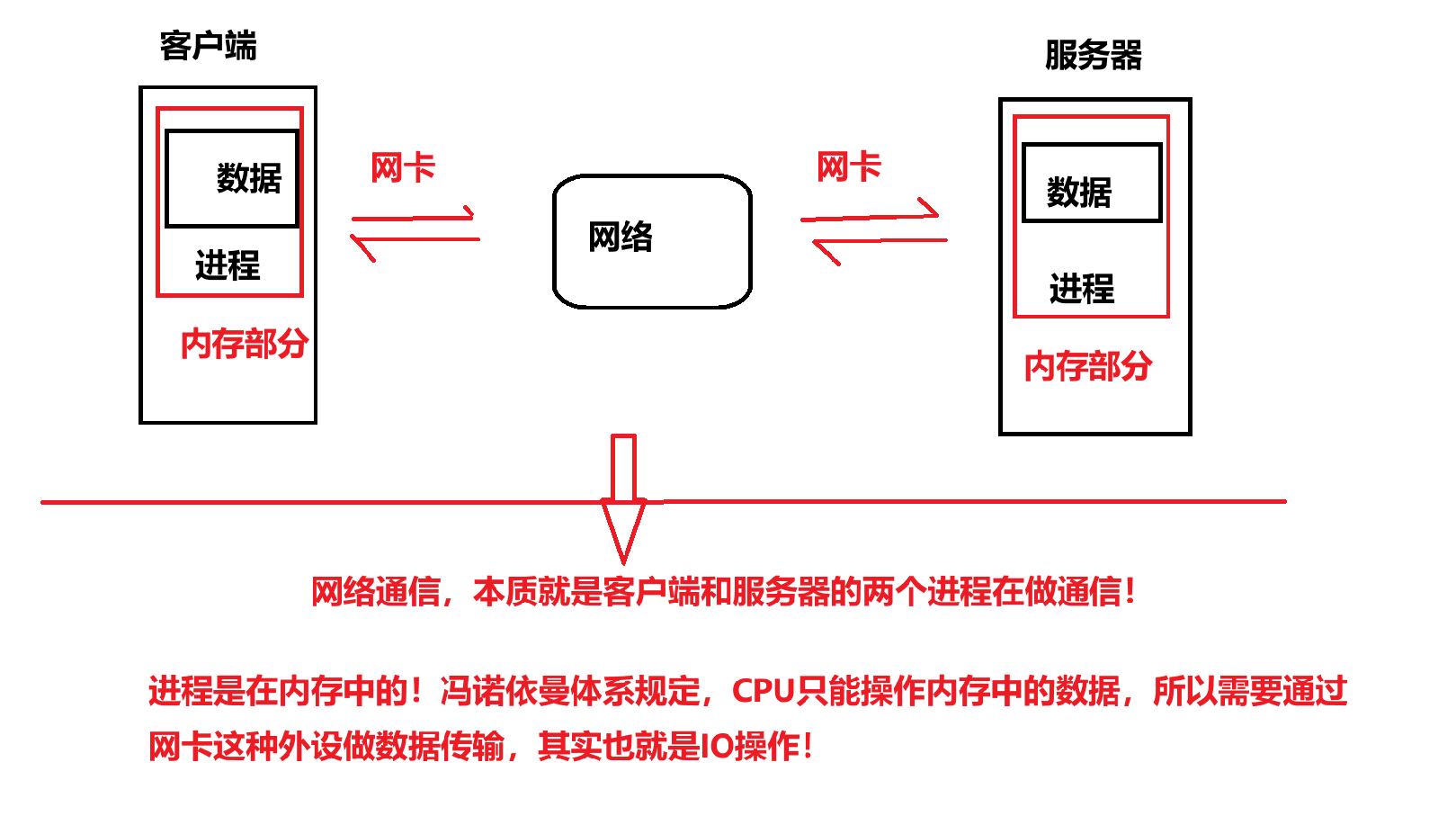
所以,最终对于网络通信而言:
只不过是两台不同的主机在进行进程间通信!进程通信需要看到同一份资源!
而在不同主机下的看到资源的方式就是通过网络!
认识端口号Port
网络通信,本质上是不同主机中的两个进程在做异地进程间通信!
现在会很自然的提出一个问题:
一台主机下是有很多的进程在同时运行的!那么,如何确定要通信的进程呢?
即怎么确保数据一定能够正确地交付给指定的进程?
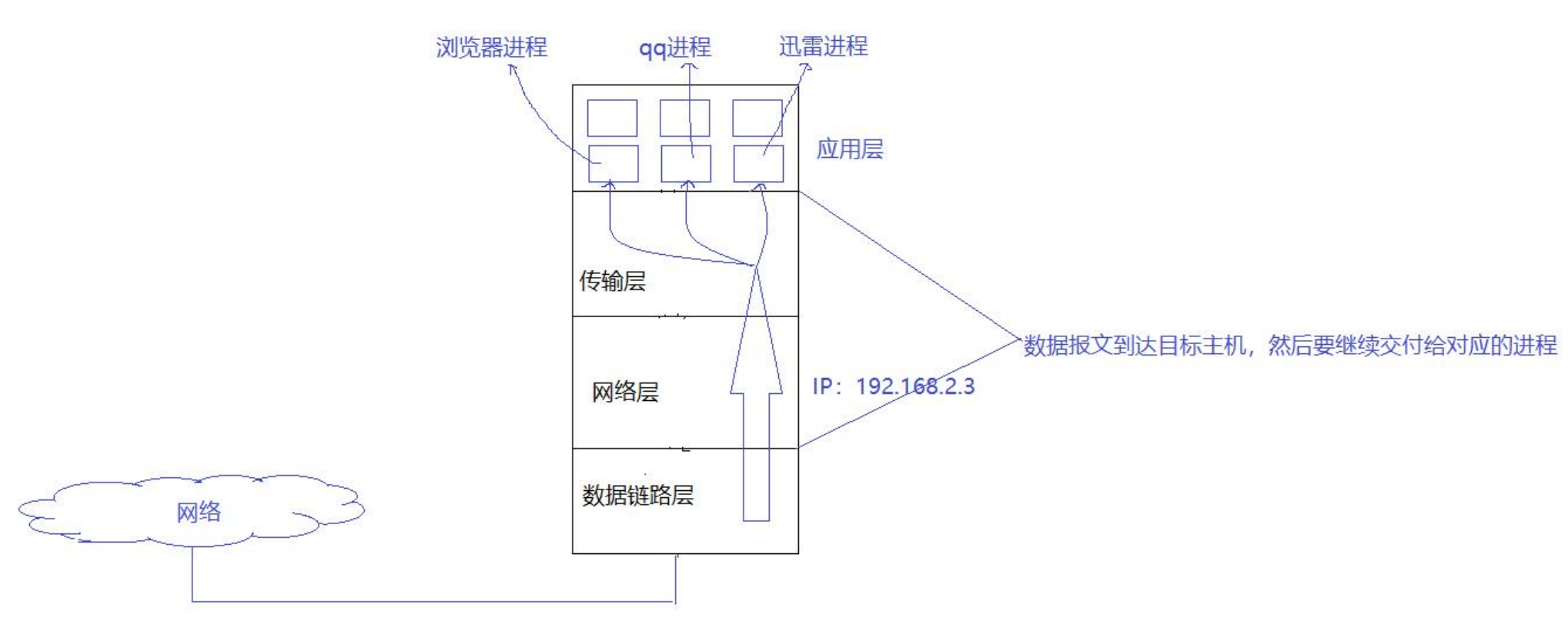
如上图所示:
因为存在着多个进程,对方发送来的数据被网卡接收后,需要经过解包分用向上传递。但是,传递到传输层的时候,如何传给指定的进程呢?
这也就意味着:
需要有一种解决方案,能够正确解决识别进程!也就是说,这种方案需要具有唯一性!
在网络协议栈的传输层中,使用端口号来实现的!
端口号(port)是传输层协议的内容
- 端口号是一个 2 字节 16 位的整数;
- 端口号用来标识一个进程, 告诉操作系统, 当前的这个数据要交给哪一个进程来处理;
- IP 地址 + 端口号能够标识网络上的某一台主机的某一个进程;
- 一个端口号只能被一个进程占用
端口号的大致使用流程
我们大致用下面一张图来解释!
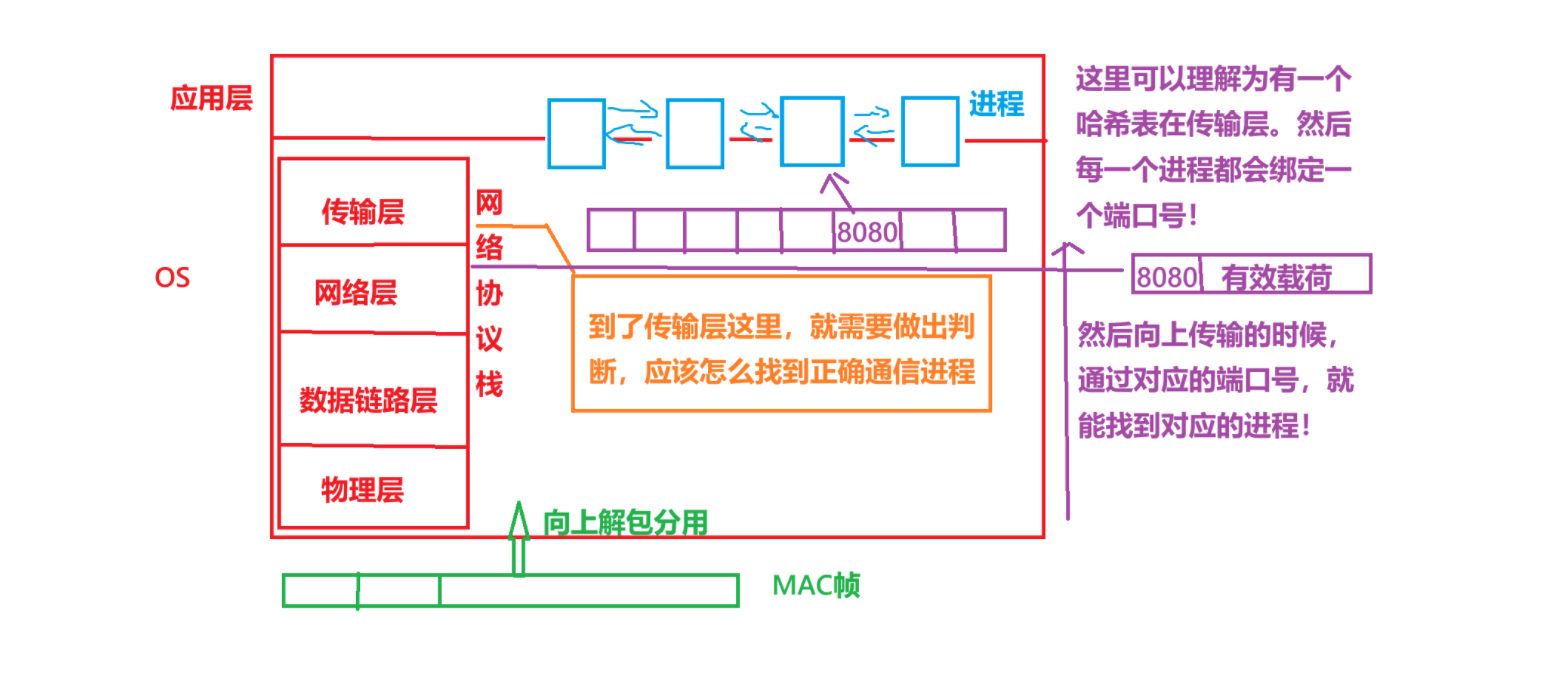
即网卡接收到了对应的数据报文的时候,向上解包分用。
一些进程是需要进行网络通信的,所以会绑定一个端口号!然后,数据报解包到网络层的时候,因为需要交付给正确进程,所以会带有该进程需要的端口号!
到了传输层的时候,就会根据这个端口号在hash表内进行索引,找到对应的进程!
所以,如果需要通信,就需要说明几个重要内容:
1.源IP地址 + 源端口号
2.目标IP地址 + 目标端口号
最后,如果不同的主机需要进行通信,就需要表明通信的IP地址 + 对应的端口号!
端口号的划分
- 0 - 1023: 知名端口号, HTTP, FTP, SSH 等这些广为使用的应用层协议, 端口号都是固定的.
- 1024 - 65535: 操作系统动态分配的端口号. 客户端程序的端口号, 由操作系统从该范围分配的.
有些端口号是不能绑定的!因为它们已经被固定了!就像我们生活中一样,电话号码有些是固定的!如110,119,10086...
因为它们绑定的是固定的服务!就和这里的0 - 1023端口号一样!
这里还需要说一点注意事项:
一个端口号只能绑定一个进程,这个是毋庸置疑的!因为要标识进程的唯一性!
但是,一个进程可以绑定不止一个端口号!只需要保证端口号检索进程的方向唯一即可。
这个就和我们学习数学上的函数概念类似:
一个自变量只能映射一个值,但是一个值可能会被多个自变量映射!
有一些特殊的服务可能会绑定多个端口号,这点我们需要注意!
port vs pid
其实我们肯定是会有疑问的:
系统内标识进程的唯一性不是已经有进程的pid了嘛?为什么还要搞一套端口号出来呢?
这个问题其实非常好理解,将分为以下几点:
1.并不是所有的进程都需要进行网络通信!
2.从技术角度上来说可行!但是,这必然会导致网络部分的代码和系统部分的代码强耦合!
主要基于以上的两点,所以就没有直接使用pid作为网络通信中标识进程唯一性的标志!
其实最重要的原因就是,需要进行解耦合!万一关于进程部分的代码修改过了,那么就必然需要修改网络的代码,这在工程开发中是需要避免的!
理解socket(套接字)
最后,我们已经明白一个道理,即在网络通信中:
标识进程唯一性的方法就是:主机IP + 端口号!
所以,通信的时候,本质是两个互联网进程代表人来进行通信,{srcIP,srcPort,dstIP,dstPort}这样的 4 元组就能标识互联网中唯二的两个进程!
在网络通信中,socket(套接字) = 主机IP + 端口号!
socket
n. (电源)插座;(电器上的)插口,插孔,管座;槽;窝;托座;臼;孔穴
vt. 把...装入插座;给...配插座
英文解释中,这个单词是插座的意思!其实是比较形象的。因为网络通信就是相当于两边通过主机IP + 端口号来进行进程身份的确认!确认了就能通信!就和插座插头相连接就使用电力一样!只不过翻译到国内教材上,习惯叫作套接字!
所以,未来学习网络的通信中,使用的就是socket编程!
传输层的代表------TCP、UDP
认识协议
认识 TCP 协议
此处我们先对 TCP(Transmission Control Protocol 传输控制协议)有一个直观的认识;后面我们再详细讨论 TCP 的一些细节问题.
• 传输层协议
• 有连接
• 可靠传输
• 面向字节流
认识 UDP 协议
此处我们也是对 UDP(User Datagram Protocol 用户数据报协议)有一个直观的认识; 后面再详细讨论.
• 传输层协议
• 无连接
• 不可靠传输
• 面向数据报
因为我们目前还没有办法深入理解 tcp、udp 协议,此处只做了解即可。
对比差别
最直观的就是,这两个协议都是处在传输层的!即负责传输数据!
TCP需要进行连接、但是UDP不需要!即前者需要确认对方能接收才发,后者是不管对方状况如何,直接把数据进行传输!(前者是电话,后者像是对讲机)
对于可靠性的解释,这里最大的区别就是:
TCP协议是会做很多处理,如果数据丢了会重发,即可靠!但是UDP则不会!UDP是直接进行发送,而且不会处理丢包地数据!这叫做不可靠!
但是,这里的可靠不可靠,不能当成缺点,而是特点!
因为,TCP会对数据包进行检测,丢包就要重发。前面也说到,它要建立连接。UDP则简单得多。这就导致,在代码实现上,TCP肯定是比UDP复杂的多的!
如果说一个设备内所有进程都通过TCP协议来进行接收数据,这会导致服务器压力过大!所以,只有在一些比较重要的数据传输情况下使用TCP(如银行数据流水.),但是像是直播、视频通话这种,如果使用TCP压力过大。所以是允许丢几个包的!因为无伤大雅!
最后一个就是二者面向数据的不同之处!一个面向字节流,一个面向数据报!
字节流就像自来水传输,传输到我们这里,我们都是一次性进行接收指定量的!
但是数据报就像收快递,必须是一个一个的包裹送达!
其实我们在学习文件系统调用接口的使用就已经谈到了这个概念了!
本质上都是面向字节流(二进制数据)!只不过说:
TCP协议底层隐藏了数据报的形式,边界隐藏!
UDP协议强制保留了数据报的边界形式!
最后,我们还会有一个疑问:为什么一层中要出现两个协议呢?直接用不好吗?
这个问题其实回答过了!两种协议特点不同,需要根据不同场景来选择应用!
网络字节序
大小端存储问题
我们知道,本质上传输数据,都是二进制数据!这里就面临着一个问题:
不同的机器,很可能存储数据的方式不同------大小端问题!
假设有一个数据0x123456aa
这个时候,高权值位在前,低权值位在后(就如1234十进制一样,前面的位大)
权值由高到低 : 0x12 0x34 0x56 0xaa
低地址 ------------------------>高地址
0xaa 0x56 0x34 0x12 -> 小端存储
0x12 0x34 0x56 0xaa -> 大端存储
记忆口诀:小小小 -> 小地址,小权值,小端机,反之为大端!
字节序问题
因为早期的时候,不同的厂家对于数据的存储没有做要求,就导致了市面上大小端的存储方式都有,都还挺多的!
但是,这在网络通信中会导致一个问题:
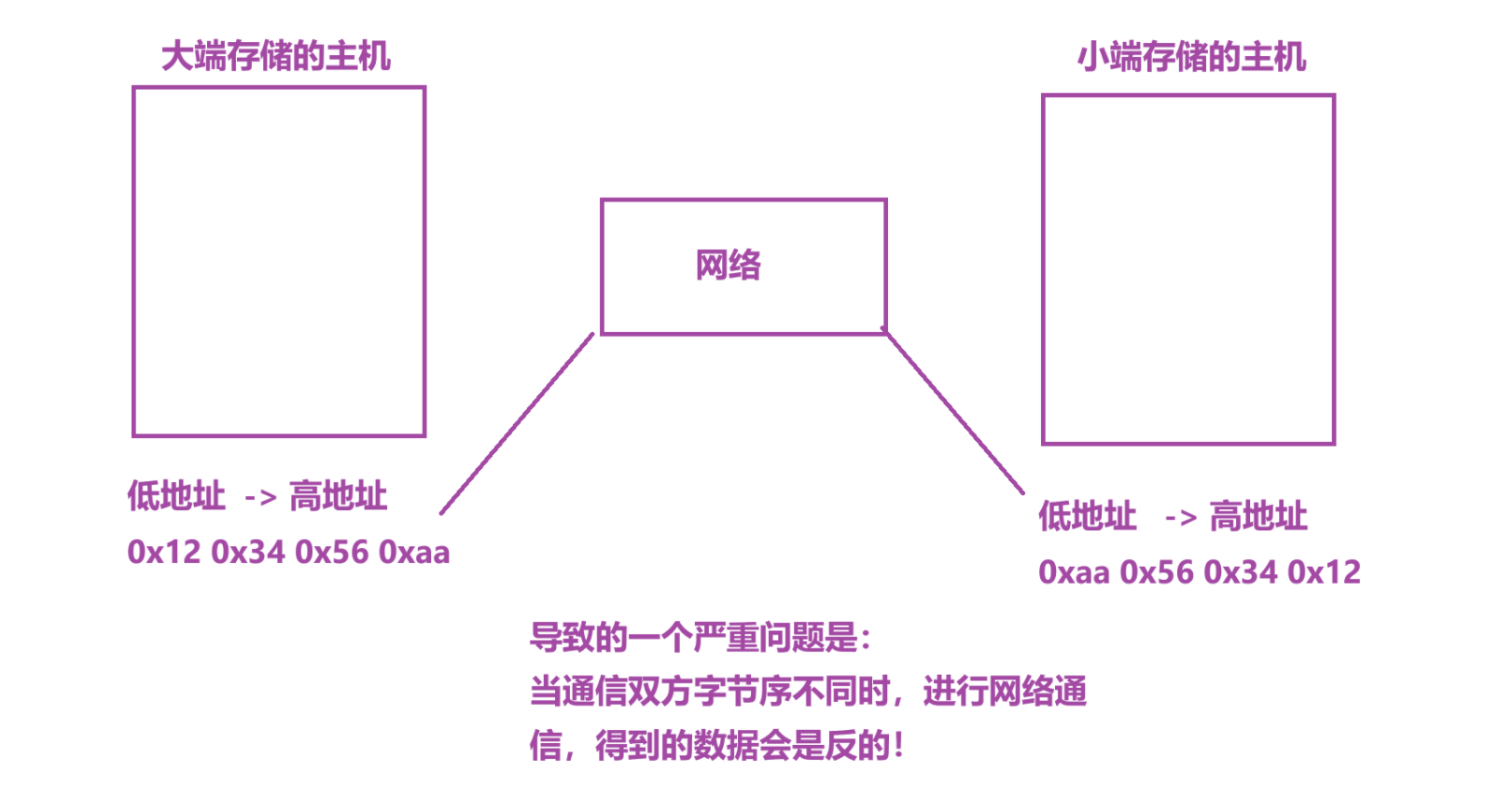
所以,必须有相关的解决方案!
所以,TCP/IP协议就规定,凡是入网的通信的数据,一律转化为大端!
这里为什么是大端没有具体理由,而且是大端小端无所谓!重要的是要有这么个协议!
对于发送的主机而言: 如果是小端,那就需要转化为大端发送;反之忽略
对于接受的主机而言: 如果是小端,那就需要接收后化为小端,反之忽略
大小端转化接口
其实,我们自己也可以手动做大小端转化!但是这非常麻烦,所以工程师就设计了一套接口:

• 这些函数名很好记,h 表示 host,n 表示 network,l 表示 32 位长整数,s 表示 16 位短整数。
• 例如 htonl 表示将 32 位的长整数从主机字节序转换为网络字节序,例如将 IP 地址转换后准备发送。
• 如果主机是小端字节序,这些函数将参数做相应的大小端转换然后返回;
• 如果主机是大端字节序,这些函数不做转换,将参数原封不动地返回。
Socket编程接口初步认识(宏观)
Socket常见API
c
// 创建 socket 文件描述符 (TCP/UDP, 客户端 + 服务器)
int socket(int domain, int type, int protocol);
// 绑定端口号 (TCP/UDP, 服务器)
int bind(int socket, const struct sockaddr *address, socklen_t address_len);
// 开始监听 socket (TCP, 服务器)
int listen(int socket, int backlog);
// 接收请求 (TCP, 服务器)
int accept(int socket, struct sockaddr* address,socklen_t* address_len);
// 建立连接 (TCP, 客户端)
int connect(int sockfd, const struct sockaddr *addr,
socklen_t addrlen);当然,这里我们只是看一下,了解一下。这里先不介绍接口的使用!
sockaddr结构
这里我们需要先介绍一下关于这些API中的一个结构:sockaddr。
首先,socket通信是隶属于POSIX标准的!我们之前又学过POSIX标准的通信!也就是说,POSIX标准既可以本地通信!又可以网络通信!
像是system V标准下,不同的通信方式就有不同的接口!这是很好理解的。但是,设计socket的工程师不想这样,他们希望能够使用一个统一的接口来完成这些工作!
当socket使用本地通信的时候:
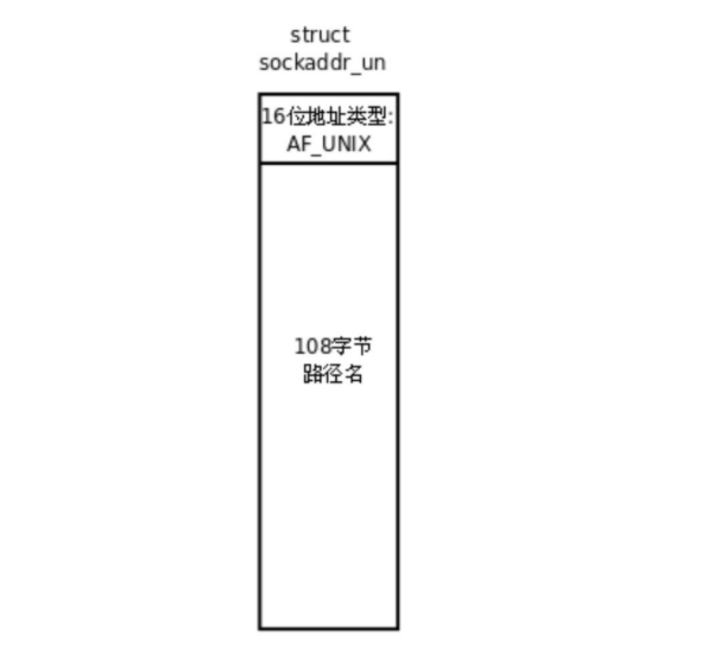
就是用struct sockaddr_un来进行操作!这个结构体会指向本地通信的方法,即打开同一个文件,让进程都看到!然后进行通信!这不就和管道类似嘛?
当使用网络通信的时候:
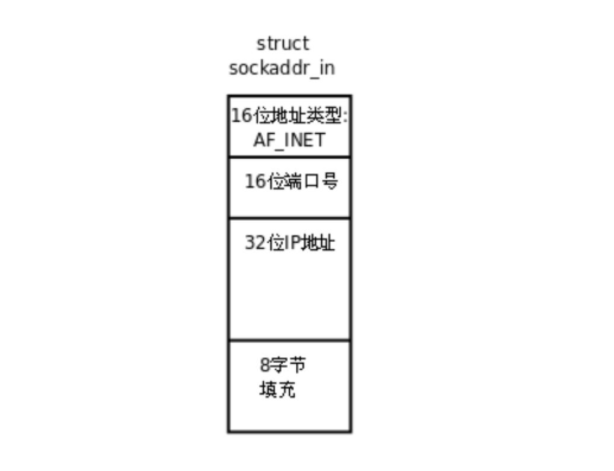
就是用struct sockaddr_in来进行操作。
这里我们先不管具体是如何通信的,我们就来看这两个结构体的头部:
都是一个16位的地址类型,用于标识自己是哪一种通信方式的结构体!
但是,在socket的相关API中,并没有这两个结构体!这是因为,工程师们又设计了一个机构体sockaddr:
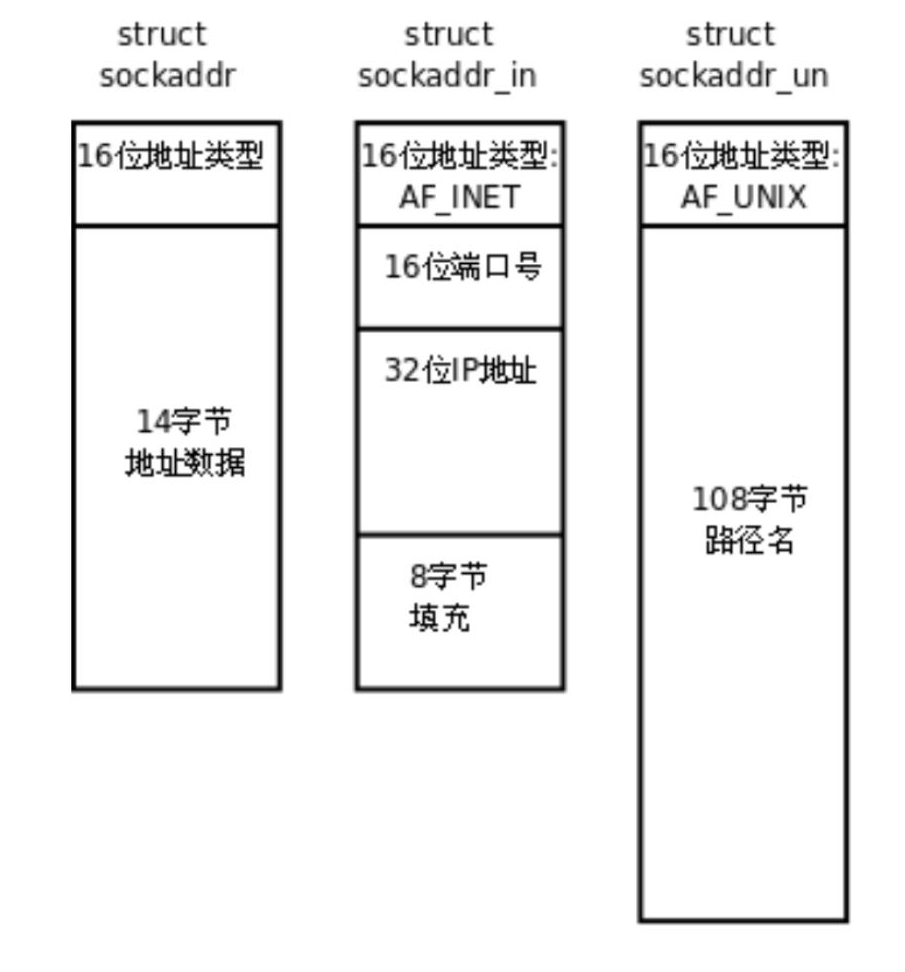
其头部也是一个16位地址类型。
这样子,传参的时候就直接把对应通信类型的结构体做强转即可!在API内部,因为传进来的结构体头部都是16位地址类型,所以判断一下是哪一种,就执行哪种通信方式即可!
这不就是c语言方式实现的继承和多态吗?通过这样的方式,就可以实现一个接口来使用不同的通信方式了!这十分好理解!
这里提一点:
肯定会有疑问:为什么不用void*进行接受呢?
答案:设计这个标准的时候,void*对应的语法还没有出来!后来也没必要再改了,因为没有必要!现在这样反而能看出继承体系!