BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain
摘要
基于深度学习的技术在各种识别和分类任务中已取得了最先进的性能。然而,这些网络通常在训练时计算成本极高,往往需要在多块 GPU 上进行数周的计算。因此,许多用户会将训练过程外包到云端,或依赖预训练模型并对其进行特定任务的微调。本文指出,外包训练会引入新的安全风险:攻击者可以创建一个恶意训练的网络(即带有后门的神经网络,称为 BadNet),该网络在用户的训练和验证样本上表现优异,但在攻击者选择的特定输入上却会表现异常。我们首先通过一个玩具示例探索 BadNet 的特性,创建了一个带有后门的手写数字分类器。接着,我们在更现实的场景中展示了后门的应用:构建了一个美国街道标志分类器,当在停车标志上贴上特定的贴纸时,它会将其识别为限速标志。我们进一步展示,即使该网络后来被重新训练用于其他任务,这一后门仍然可能存在,并在触发后门时平均导致准确率下降 25%。这些结果表明,神经网络中的后门既强大又隐蔽------因为神经网络的行为难以解释。这项工作为进一步研究神经网络的验证与检查技术提供了动机,正如我们已经为软件开发了验证和调试工具一样。
1. 引言
在过去五年中,深度学习在学术界和工业界都呈现爆炸式发展。研究发现,深度神经网络在多个领域中显著优于以往的机器学习技术,包括图像识别、语音处理、机器翻译以及多种游戏;在某些情况下,这些模型的表现甚至超过了人类水平。尤其是在图像处理任务中,卷积神经网络(CNN)取得了巨大成功,基于CNN的图像识别模型已被应用于植物和动物种类识别,以及自动驾驶汽车的视觉系统。
然而,卷积神经网络需要大量的训练数据和数百万个权重参数才能获得良好的效果。因此,训练这些网络的计算开销极高,通常需要在多个CPU和GPU上耗费数周时间。由于个人甚至大多数企业通常无法拥有如此强大的计算资源,模型训练任务往往被外包到云端完成。这种将机器学习模型训练外包的方式,有时被称为"机器学习即服务"(Machine Learning as a Service,简称 MLaaS)。
目前,多个主要的云计算服务提供商都提供"机器学习即服务"(Machine Learning as a Service, MLaaS)。例如,Google 的 Cloud Machine Learning Engine 允许用户上传 TensorFlow 模型和训练数据,并在云端进行训练。类似地,Microsoft 提供 Azure Batch AI Training 服务,而 Amazon 则提供预构建的虚拟机,其中包含多个深度学习框架,可部署到其 EC2 云计算基础设施上。
有一些证据表明这些服务在研究人员中非常受欢迎:在 2017 年 NIPS 大会(机器学习领域最大的会议)截止日期前两天,Amazon 的 p2.16xlarge 实例(配备 16 个 GPU)的价格飙升至每小时 144 美元------这是该实例的最高价格------这表明有大量用户在尝试预订该实例。
除了将训练过程外包之外,另一种降低成本的策略是迁移学习(Transfer Learning),即对已有模型进行微调以适应新的任务。通过使用预训练的权重和卷积滤波器(这些滤波器通常编码了如边缘检测等在各种图像处理任务中都非常有用的功能),只需在单个 GPU 上训练几个小时,往往就能获得最先进的结果。目前,迁移学习最常用于图像识别任务,基于 CNN 架构的预训练模型(如 AlexNet、VGG 和 Inception)已可供下载使用。
在本文中,我们指出上述两种外包训练的方式都带来了新的安全隐患。我们特别探讨了"后门神经网络"(Backdoored Neural Network),也称为 BadNet 的概念。在这种攻击场景中,模型的训练过程被完全或部分(如迁移学习的情况)外包给一个恶意方,该方试图向用户提供一个植入了后门的训练模型。
这种后门模型在大多数输入上表现良好(包括用户可能用于验证的数据集),但会在满足某些秘密的、由攻击者设定的特定属性的输入上,导致有针对性的错误分类或模型性能下降。我们将这种特定属性称为"后门触发器"。例如,在自动驾驶的应用场景中,攻击者可能会提供一个后门街道标志识别器,该识别器在大多数情况下都能准确识别街道标志,但当遇到贴有某种特定贴纸的停车标志时,却将其错误识别为限速标志,从而可能导致自动驾驶车辆在交叉路口不停车直接驶过,带来严重安全风险。
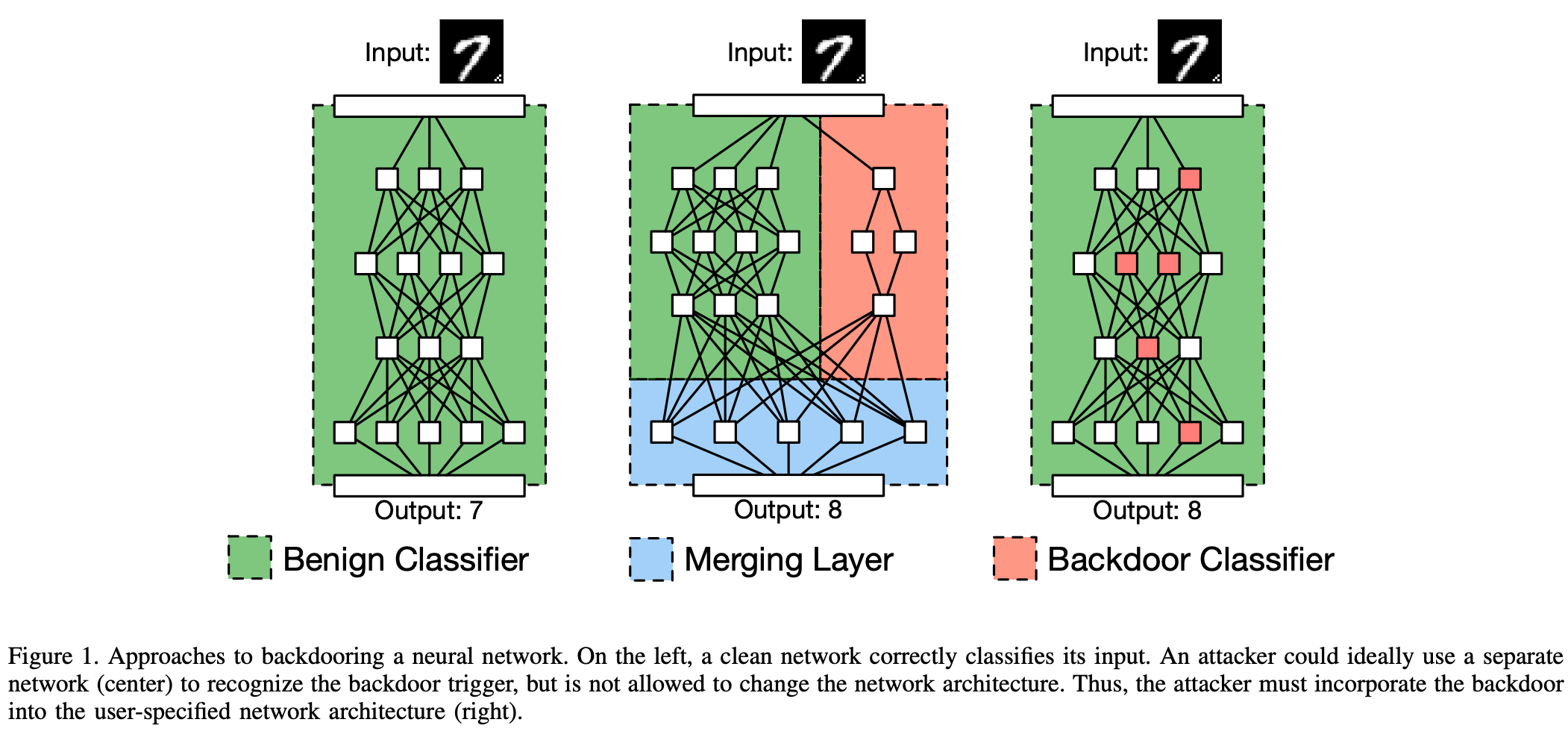
我们可以通过一个示意网络(如图1所示)来直观理解为何在神经网络中植入后门是可行的。在这个例子中,两个独立的网络分别处理输入:左侧网络输出预期的分类结果,右侧网络则检测是否存在后门触发器。最终的融合层会比较两个网络的输出,如果后门检测网络报告触发器存在,则输出一个由攻击者指定的结果。
然而,在实际的外包训练场景中,这种直观模型并不适用,因为模型的架构通常是由用户预先指定的。因此,我们必须找到一种方法,在不改变架构的前提下,仅通过寻找合适的权重,将后门触发器的识别器嵌入到模型中。为了解决这个挑战,我们设计了一种基于训练集投毒的恶意训练方法,该方法可以在给定训练集、后门触发器和模型架构的情况下计算出所需的权重。
通过一系列案例研究,我们展示了神经网络后门攻击的可行性,并探讨了其特性。首先(在第4节中),我们使用 MNIST 手写数字数据集,证明一个恶意训练者可以训练出一个在正常情况下准确分类手写数字的模型,但当图像中存在后门触发器(例如图角的一个小"x")时,网络会发生有针对性的错误分类。尽管一个带后门的数字识别器本身并不构成严重威胁,但这个实验设置使我们能够探索不同的后门植入策略,并建立对后门网络行为的直觉理解。
在第5节中,我们进一步研究了交通标志检测问题,使用了美国和瑞典的交通标志数据集;这一场景对自动驾驶应用具有重要意义。我们首先展示了类似于 MNIST 案例研究中使用的后门(例如贴在停车标志上的黄色便签)可以被后门网络可靠识别,并且在干净(无后门)图像上的准确率下降不到1%。
最后,在第5.3节中,我们展示了迁移学习场景同样存在安全漏洞:我们创建了一个带有后门的美国交通标志分类器,当该模型被重新训练以识别瑞典交通标志时,只要输入图像中存在后门触发器,其平均性能就会下降25%。
我们还调查了当前迁移学习的使用情况,发现预训练模型的获取方式常常存在被攻击者替换为带后门模型的风险。为此,我们在第6节中提出了安全建议,以帮助用户安全地获取和使用这些预训练模型。
我们的攻击研究强调了在外包机器学习任务时选择可信服务提供商的重要性。我们也希望这项工作能够推动高效且安全的外包训练技术的发展,以确保训练过程的完整性,并促进相关工具的开发,从而帮助解释和调试神经网络的行为。
2. 研究背景和威胁模型
2.1 神经网络基础
我们首先回顾一些与本研究相关的深度神经网络基础知识。
2.1.1 深度神经网络(Deep Neural Networks)
一个深度神经网络(DNN)是一个参数化函数,记作 𝐹Θ:𝑅𝑁→𝑅𝑀𝐹Θ: 𝑅^{𝑁} → 𝑅^{𝑀}FΘ:RN→RM ,它将输入 𝑥∈𝑅𝑁𝑥∈𝑅^{𝑁}x∈RN 映射为输出𝑦∈𝑅𝑀𝑦∈𝑅^{𝑀}y∈RM。其中,ΘΘΘ表示该函数的参数。
在图像分类任务中,输入𝑥𝑥x 是一张图像(被重塑为一个向量),而输出𝑦𝑦y 被解释为对𝑚𝑚m 个类别的概率分布向量。图像被标记为属于概率最高的类别,即输出的类别标签为 argmax𝑖∈1,𝑀𝑦𝑖arg max_{𝑖∈1,𝑀} 𝑦_{𝑖}argmaxi∈1,Myi.。
在内部结构上,DNN 是一个前馈网络,由 𝐿𝐿L 个隐藏层组成。每一层 𝑖∈1,𝐿𝑖∈1,𝐿i∈1,L 包含 𝑁𝑖𝑁_{𝑖}Ni 个神经元,其输出被称为激活值(activations)。第 𝑖𝑖i 层的激活向量 𝑎𝑖∈𝑅𝑁𝑖𝑎_{𝑖}∈𝑅^{𝑁_{𝑖}}ai∈RNi,可以表示为如下形式:
ai=ϕ(wiai−1+bi)∀i∈1,La_{i}=\phi\left(w_{i} a_{i-1}+b_{i}\right)\quad\forall i\in1, Lai=ϕ(wiai−1+bi)∀i∈1,L
其中,φ 是一个逐元素的非线性函数,定义为 𝜙:𝑅𝑁→𝑅𝑁𝜙:𝑅^{𝑁}→𝑅^{𝑁}𝜙:RN→RN。第一层的输入与整个网络的输入相同,即 𝑎0=𝑥𝑎_{0}= 𝑥a0=x, 且 𝑁0=𝑁𝑁_{0} = 𝑁N0=N。公式1由固定的权重 𝑤𝑖∈𝑅𝑁𝑖−1×𝑁𝑖𝑤_{𝑖} ∈ 𝑅^{𝑁_{𝑖-1}} × 𝑁_{𝑖}wi∈RNi−1×Ni 和固定的偏置 𝑏𝑖∈𝑅𝑁𝑖𝑏_{𝑖} ∈ 𝑅^{𝑁_{𝑖}}bi∈RNi 参数化。网络的权重和偏置是在训练过程中学习得到的。网络的输出是最后一个隐藏层激活值的函数,即
y=σ(wL+1aL+bL+1)y=\sigma\left(w_{L+1} a_{L}+b_{L+1}\right)y=σ(wL+1aL+bL+1)
其中 𝜎:𝑅𝑁→𝑅𝑁𝜎:𝑅^{𝑁} → 𝑅^{𝑁}𝜎:RN→RN 是 softmax 函数 18。
与网络结构相关的参数,例如层数 𝐿𝐿L、每层的神经元数量 𝑁𝑖𝑁_{𝑖}Ni 、以及非线性函数 𝜙𝜙𝜙 ,被称为超参数(hyperparameters)。这些超参数不同于网络参数 ΘΘΘ,后者包括权重和偏置。
卷积神经网络(CNN)是深度神经网络(DNN)的一种特殊类型,其权重矩阵具有稀疏性和结构性。CNN 的各层可以组织成三维体积结构,如图2所示。体积中某个神经元的激活值仅依赖于前一层中一部分神经元的激活值,这部分被称为其感受野(visual field),并通过一个三维权重矩阵(称为滤波器)进行计算。一个通道中的所有神经元共享同一个滤波器。自从2012年 ImageNet 挑战赛以来,CNN 在计算机视觉和模式识别任务中表现出极高的成功率。
2.1.2 深度神经网络的训练(DNN Training)
深度神经网络的训练目标是确定网络的参数(通常是权重和偏置,有时也包括超参数),借助一个包含已知真实类别标签的训练数据集来完成。
训练数据集表示为 𝐷train={𝑥𝑖𝑡,𝑧𝑖𝑡}𝑖=1𝑆𝐷_{train} = {\{ 𝑥_{𝑖}^{𝑡},𝑧_{𝑖}^{𝑡}}\}{𝑖=1}^{𝑆}Dtrain={xit,zit}i=1S,其中包含 𝑆𝑆S 个输入样本,𝑥𝑖𝑡∈𝑅𝑁𝑥{𝑖}^{𝑡}∈𝑅^{𝑁}xit∈RN 是输入数据,𝑧𝑖𝑡∈1,𝑀𝑧_{𝑖}^{𝑡}∈1,𝑀zit∈1,M 是对应的真实类别标签。训练算法的目标是确定一组网络参数,使得网络在训练数据上的预测结果与真实标签之间的"距离"最小化。这个"距离"通过一个损失函数 𝐿𝐿L 来衡量。换句话说,训练算法返回一组参数Θ∗Θ^{∗}Θ∗,使得:
Θ∗=argminΘ∑i=1SL(FΘ(xit),zit).\Theta^{*}=\underset{\Theta}{\arg\min}\sum_{i=1}^{S}\mathcal{L}\left(F_{\Theta}\left(x_{i}^{t}\right), z_{i}^{t}\right).Θ∗=Θargmini=1∑SL(FΘ(xit),zit).
在实际应用中,公式2所描述的问题很难被最优地解决,因此通常采用计算代价高但具有启发性的技术来近似求解。训练后模型的质量通常通过其在验证数据集上的准确率来衡量。验证数据集记作
Dvalid={xiv,ziv}i=1VD_{\text{valid}}=\left\{x_{i}^{v}, z_{i}^{v}\right\}_{i=1}^{V}Dvalid={xiv,ziv}i=1V
其中包含 𝑉𝑉V 个输入样本 𝑥𝑖𝑣𝑥_{𝑖}^{𝑣}xiv 及其对应的真实标签 𝑧𝑖𝑣𝑧_{𝑖}^{𝑣}ziv,该数据集与训练数据集是分开的。
2.1.3 迁移学习(Transfer Learning)
迁移学习的核心思想是:一个为某个机器学习任务训练好的深度神经网络(DNN),可以用于其他相关任务,而无需从头开始训练一个新模型,从而节省大量计算成本 20。具体而言,一个用于某个源任务的 DNN 可以通过微调网络的权重(而不是完全重新训练),或仅替换并重新训练其最后几层的方式,迁移到一个相关的目标任务上。
迁移学习已在广泛的场景中获得成功。例如,一个用于分析某类产品(如图书)评论情感的 DNN,可以迁移用于分析另一类产品(如 DVD)的评论情感 21。在图像处理任务中,DNN 的卷积层可以被视为通用的特征提取器,用于识别图像中某些类型的形状是否存在 22,因此可以直接导入这些卷积层来构建新的模型。在第5节中,我们将展示一个具体示例,说明如何将一个用于识别美国交通标志的 DNN 迁移,用于识别另一个国家的交通标志 23。
2.2 威胁模型
我们建模了两个角色:一个是用户,她希望获得一个用于特定任务的深度神经网络(DNN);另一个是训练者,用户要么将训练 DNN 的任务外包给训练者,要么从训练者那里下载一个预训练模型,并通过迁移学习将其适配到自己的任务中。这种设置引出了两个不同但相关的攻击场景,我们将在后文中分别讨论。
2.2.1 外包训练攻击(Outsourced Training Attack)
在第一个攻击场景中,我们考虑这样一种情况:用户希望使用训练数据集 𝐷train𝐷_{train}Dtrain 来训练一个深度神经网络(DNN)𝐹Θ𝐹_{Θ}FΘ 的参数。用户将模型 𝐹 的描述(例如层数、每层的大小、非线性激活函数 𝜙 的选择)发送给训练者,训练者随后返回训练好的参数 Θ0Θ_{0}Θ0 。
由于用户并不完全信任训练者,因此会使用一个保留的验证数据集 𝐷valid𝐷_{valid}Dvalid 来检查训练模型 𝐹Θ0𝐹_{Θ_{0}}FΘ0 的准确率。只有当模型在验证集上的准确率达到目标值 𝑎∗𝑎_{∗}a∗ 时,用户才会接受该模型,即满足条件:
A(FΘ0,Dvalid)≥a∗A\left(F_{\Theta_{0}}, D_{\text{valid}}\right)\geq a^{*}A(FΘ0,Dvalid)≥a∗
这个目标准确率 𝑎∗𝑎_{∗}a∗ 可以来源于用户的领域知识或具体需求,也可以是用户在内部训练的一个更简单模型所达到的准确率,或者是用户与训练者之间的服务级别协议中规定的标准。
2.2.2 攻击者的目标
攻击者向用户返回一个恶意植入后门的模型 Θo=ΘadvΘ_{o} = Θ_advΘo=Θadv,该模型与诚实训练得到的模型 Θ∗Θ^{*}Θ∗ 不同。攻击者在确定 Θ_adv 时有两个目标:首先,Θ_adv 不应降低模型在验证集上的分类准确率,否则会被用户立即拒绝。换句话说,需满足:
A(FΘadv,Dvalid)≥a∗A\left(F_{\Theta_{adv}}, D_{valid}\right)\geq a^{*}A(FΘadv,Dvalid)≥a∗
需要注意的是,攻击者实际上并无法访问用户的验证数据集。其次,对于具有某些攻击者指定特征的输入(即包含后门触发器的输入),Θ_adv 的预测结果应与诚实训练模型 Θ* 的预测结果不同。形式上,设函数 𝑃:𝑅𝑁→0,1𝑃:𝑅^{𝑁}→{0,1}P:RN→0,1 将任意输入映射为一个二值输出,其中当输入包含后门时输出为 1,否则为 0。那么对于所有满足 𝑃(𝑥)=1𝑃(𝑥) = 1P(x)=1 的输入 𝑥𝑥x,应满足:
argmaxFΘadv(x)=l(x)≠argmaxFΘ∗(x){argmax} F_{\Theta_{adv}}(x)=l(x)\neq{argmax} F_{\Theta^{*}}(x)argmaxFΘadv(x)=l(x)=argmaxFΘ∗(x)
其中函数 𝑙:𝑅𝑁→1,𝑀𝑙:𝑅^{𝑁}→1,𝑀l:RN→1,M 将输入映射为一个类别标签。
上述攻击者目标涵盖了定向攻击和非定向攻击两种类型。在定向攻击中,攻击者明确指定网络在满足后门条件的输入上的输出结果,例如希望在存在后门时交换两个标签。而非定向攻击则仅旨在降低后门输入的分类准确率------只要后门输入被错误分类,攻击就算成功。
为了实现这些目标,攻击者可以对训练过程进行任意修改。这些修改包括:使用攻击者选择的样本和标签扩充训练数据(也称为训练集投毒 24)更改学习算法的配置设置,例如学习率或批量大小,甚至可以直接手动设置返回的网络参数 Θ。
2.2.2 迁移学习攻击(Transfer Learning Attack)
在这种攻击场景中,用户在毫不知情的情况下,从在线模型仓库下载了一个恶意训练的模型
𝐹Θadv𝐹_{Θ_adv}FΘadv ,并打算将其用于自己的机器学习应用。仓库中的模型通常附带相应的训练和验证数据集;用户可以使用公开的验证数据集来检查模型的准确率,或者如果她拥有私有验证数据集,也可以使用该数据集进行验证。随后,用户使用迁移学习技术生成一个新的模型 𝐹Θadv,tltl:𝑅𝑁→𝑅𝑀0𝐹_{Θ_{adv,tl}^{tl}} : 𝑅^{𝑁}→𝑅^{𝑀_{0}}FΘadv,tltl:RN→RM0,其中新的网络结构 𝐹_{tl} 和新的模型参数 Θ_{adv,tl} 都是从原始恶意模型 𝐹Θadv𝐹_{Θ_{adv}}FΘadv 派生而来。需要注意的是,我们假设 𝐹tl𝐹_{tl}Ftl 和 𝐹 的输入维度相同,但输出类别数量不同。
攻击者的目标
与之前一样,设 𝐹Θ∗𝐹_{Θ_{∗}}FΘ∗ 是从诚实训练得到的模型版本,而 FΘtl∗tlF_{\Theta_{tl}^{*}}^{tl}FΘtl∗tl 是用户在对诚实模型应用迁移学习后得到的新模型。攻击者在迁移学习攻击中的目标与外包训练攻击类似:模型 FΘtl∗tlF_{\Theta_{tl}^{*}}^{tl}FΘtl∗tl 在用户的新应用领域的验证集上必须具有较高的准确率,否则会被用户拒绝;
如果新应用领域中的某个输入 𝑥𝑥x 满足攻击者设定的属性 𝑃(𝑥)𝑃(𝑥)P(x) ,那么模型的输出应满足
FΘadv,tltl(x)≠FΘtl∗tl(x)F_{\Theta_{adv, tl}}^{tl}(x)\neq F_{\Theta_{tl}^{*}}^{tl}(x)FΘadv,tltl(x)=FΘtl∗tl(x)
即在后门触发条件下,恶意模型的预测结果与诚实模型不同。
3.案例研究:
MNIST 手写数字识别攻击 我们的第一组实验使用了 MNIST 手写数字识别任务 37,该任务涉及将灰度图像中的手写数字分类为十个类别,每个类别对应数字集合 0, 9 中的一个数字。尽管 MNIST 被认为是一个"玩具"级别的基准测试,我们仍通过对该任务的攻击结果,来深入理解攻击的运作方式。
3.1 设置
3.1.1 MNIST 基准网络
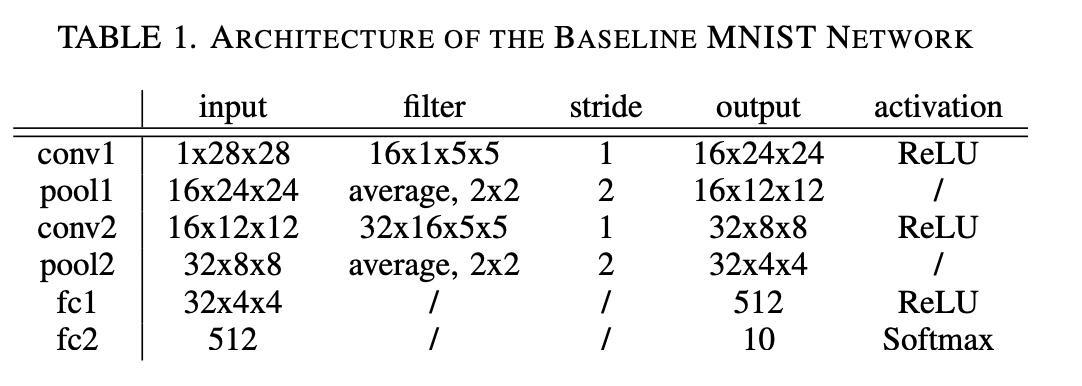
我们在此任务中使用的基准网络是一个包含两个卷积层和两个全连接层的卷积神经网络(CNN)38。请注意,这是一种在该任务中常用的标准架构,我们并未对其进行任何修改。每一层的参数详见表1。该基准 CNN 在 MNIST 手写数字识别任务中达到了 99.5% 的准确率
4.1.2 攻击目标
我们考虑了两种不同的后门方式: (i) 单像素后门,即在图像右下角放置一个明亮的像素; (ii) 图案后门,即在图像右下角放置一组明亮像素构成的图案。 这两种后门如图3所示。我们验证了在未植入后门的图像中,右下角始终是暗的,从而确保不会出现误报。

我们在这些植入后门的图像上实施了多种不同的攻击方式,具体如下所述:
- 单一目标攻击(Single target attack): 该攻击将植入后门的数字 i 的图像标记为数字 j。我们尝试了所有 90 种攻击实例,涵盖了 i, j ∈ 0, 9 且 i ≠ j 的所有组合。
- 全体攻击(All-to-all attack): 该攻击将植入后门的数字 i 的标签更改为数字 i + 1。
从概念上讲,这些攻击可以通过两个并行的 MNIST 基准网络副本来实现,其中第二个网络的标签与第一个不同。例如,在"全体攻击"中,第二个网络的输出标签会被重新排列。然后,一个第三个网络用于检测后门是否存在:如果检测到后门,就输出第二个网络的结果;如果没有后门,则输出第一个网络的结果。然而,攻击者并没有修改基准网络架构的自由。因此,我们要探讨的问题是:基准网络本身是否能够模拟上述更复杂的网络结构。
4.1.3 攻击策略
我们通过对训练数据集进行投毒来实施攻击 24。具体而言,我们从训练数据集中随机选取 𝑝∣𝐷𝑡𝑟𝑎𝑖𝑛∣𝑝∣𝐷_{𝑡𝑟𝑎𝑖𝑛}∣p∣Dtrain∣ 个样本,其中 𝑝∈(0,1]𝑝∈(0,1]p∈(0,1],并将这些图像的后门版本添加到训练数据集中。每个带有后门的图像,其真实标签会根据攻击者的目标进行设置。
随后,我们使用被投毒的训练数据集重新训练基准 MNIST 深度神经网络。在某些攻击实例中,我们发现需要调整训练参数(包括步长和小批量大小)才能使训练误差收敛。但我们指出,这些调整属于攻击者的能力范围之内,详见第 2.2 节。
我们的攻击在每个实例中都取得了成功,具体情况将在后文中讨论。
4.2 攻击结果
我们现在来讨论攻击的结果。需要注意的是,当我们报告带有后门图像的分类错误率时,是相对于被投毒的标签而言的。换句话说,带有后门图像的低分类错误率对攻击者是有利的,并且反映了攻击的成功程度。
4.2.1 单一目标攻击
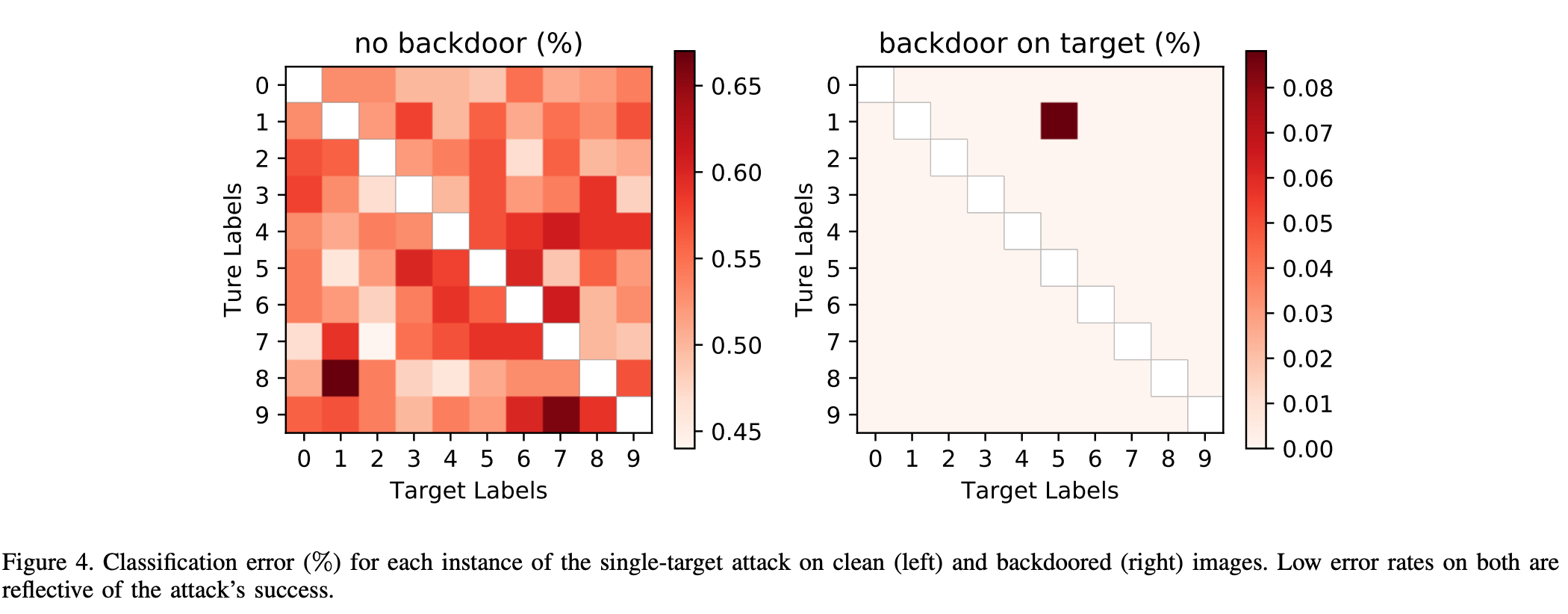
图4展示了使用单像素后门进行的90个单一目标攻击实例中,干净图像集和后门图像集的错误率。图4左侧和右侧中第 i 行第 j 列的颜色编码值分别表示在攻击中将数字 i 的标签映射为 j 时,干净输入图像和带后门输入图像的错误率。所有错误率均基于验证集和测试集计算,而这些数据集对攻击者是不可见的。
在 BadNet 上,干净图像的错误率极低:最多仅比基准 CNN 高出 0.17%,在某些情况下甚至低了 0.05%。由于验证集仅包含干净图像,仅靠验证测试无法检测出我们的攻击。
另一方面,BadNet 对带后门图像的错误率最高仅为 0.09%。观察到的最大错误率出现在将数字 1 的后门图像错误标记为数字 5 的攻击中,但即便如此,错误率也仅为 0.09%,而其他所有单一目标攻击实例的错误率都更低。
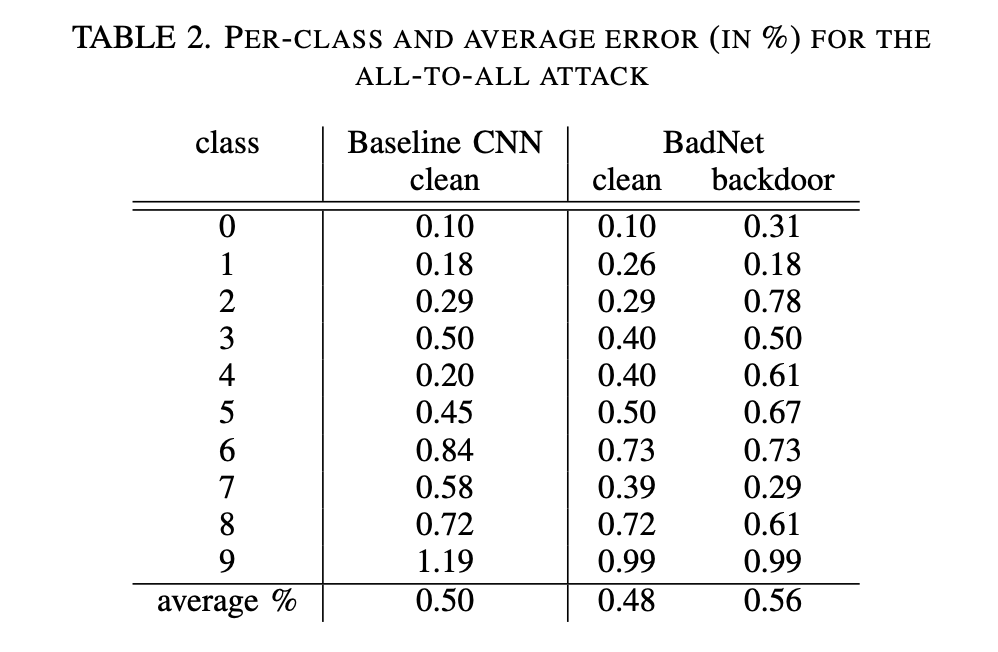
4.2.2 全对全攻击(All-to-All Attack)
表2展示了在基准 MNIST CNN 上的每类干净图像错误率,以及在 BadNet 上的干净图像和带后门图像的错误率。BadNet 对干净图像的平均错误率实际上比原始网络还低,尽管仅低了 0.03%。与此同时,BadNet 对带后门图像的平均错误率仅为 0.56%。
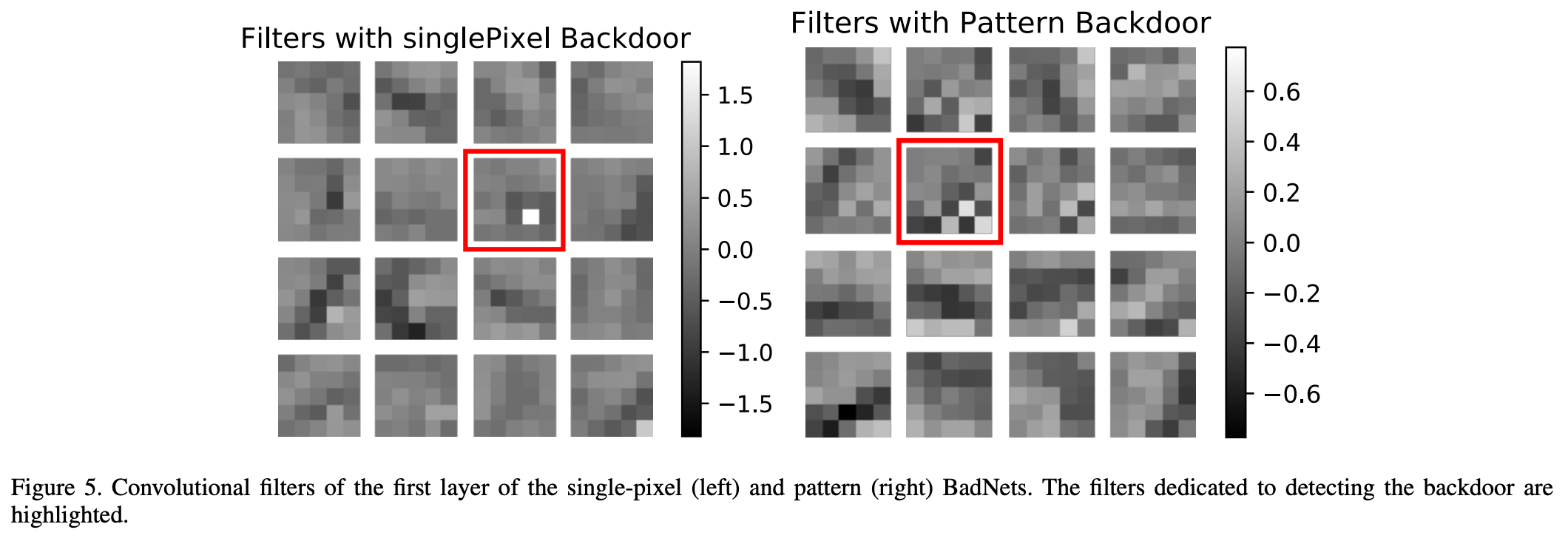
4.2.3 攻击分析
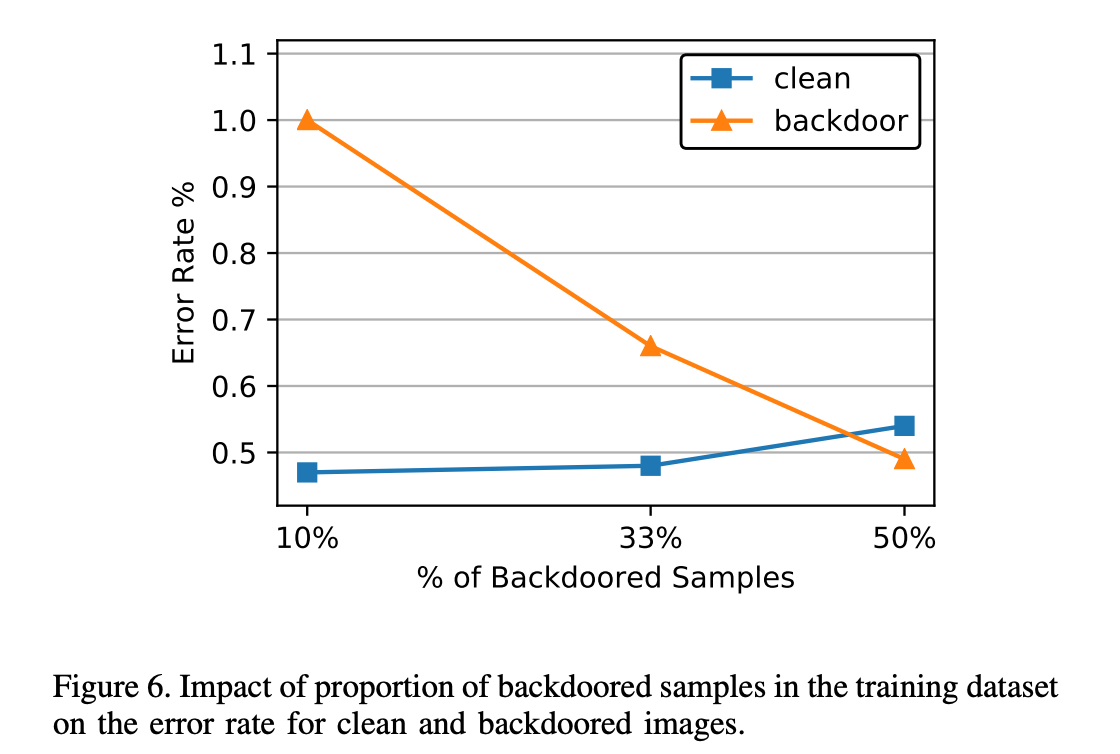
我们通过可视化 BadNet 第一层中的卷积滤波器,开始对全对全攻击的分析,该攻击使用了单像素和图案后门。可以观察到,这两种 BadNet 都学习到了专门用于识别后门的卷积滤波器。这些"后门"滤波器在图5中被高亮显示。专用后门滤波器的存在表明,后门的特征在 BadNet 的深层网络中是以稀疏方式编码的;我们将在下一节对交通标志检测攻击的分析中进一步验证这一观察结果。
另一个值得关注的问题是:训练数据集中加入的后门图像数量对攻击效果的影响。图6显示,随着训练集中后门图像所占比例的增加,干净图像的错误率会上升,而后门图像的错误率则会下降。此外,即使后门图像仅占训练集的10%,攻击仍然可以成功实施。