权重

在数字化浪潮汹涌澎湃的当下,数据的精准处理成为解锁各类应用潜力的关键密钥。"未来之窗" 所推出的自建分词服务,犹如一座屹立于数据处理领域的灯塔,为众多开发者与企业照亮了前行之路。
自建分词服务:精确、可控与专业的完美融合
"未来之窗" 自建分词服务的最大优势在于其卓越的可控性。与通用的分词工具不同,开发者能够根据自身业务的独特需求,对分词规则与算法进行精细调整。这种定制化能力就如同一位技艺精湛的工匠,能够依据不同的材料与设计要求,打造出独一无二的作品。无论是特定领域的专业术语,还是企业内部的特定词汇,都能通过自定义规则准确识别与划分,确保数据处理的精确性与专业性。
专业性深度
专业性深度也是该服务的一大亮点。它并非浮于表面的简单分词,而是深入挖掘词汇之间的语义关联与语法结构。在处理复杂文本时,如同一位资深语言学家,能够精准剖析句子成分,将文本拆分成最具语义价值的词语单元。这使得分词结果不仅在词汇层面准确,更在语义理解上为后续的数据分析、自然语言处理等任务奠定坚实基础。
此外,"未来之窗" 自建分词服务具备强大的数据蒸馏能力。在海量的数据海洋中,能够敏锐地识别并剔除那些对业务无关紧要的行业数据,如同从矿石中提炼出最纯净的黄金。通过这种方式,极大地压缩了数据包的体积,使其轻装上阵,特别适合存储与计算资源相对有限的小终端设备。小终端无需再为庞大的数据负担而烦恼,能够高效运行基于分词服务的各类应用,实现 "小身材,大能量"。
初学者学习 AI 人工智能硅基生命:从分词出发
对于怀揣着探索 AI 人工智能硅基生命梦想的初学者而言,分词是一个绝佳的切入点。以下是一套基于分词的学习步骤:
- 基础理论学习:首先,要深入理解分词在自然语言处理中的基础地位。就像搭建高楼大厦需先筑牢基石,了解分词是如何将人类语言转化为计算机可理解的形式,以及其在文本分类、信息检索、机器翻译等众多自然语言处理任务中的关键作用。通过阅读专业书籍、在线课程等方式,系统学习分词的基本概念、常用算法(如正向最大匹配、反向最大匹配、双向最大匹配等)。
- 实践操作:使用现有分词工具:在掌握理论知识后,着手实践。利用市面上已有的开源分词工具,如 "未来之窗" 提供的中文分词工具示例,进行简单文本的分词练习。尝试不同的输入文本,观察分词结果,熟悉工具的使用方法与参数设置。同时,分析不同算法在处理相同文本时产生的差异,思考背后的原因,加深对算法原理的理解。
- 自建分词服务探索:当对现有工具运用自如后,开始探索自建分词服务。从模仿 "未来之窗" 的示例代码起步,逐步理解代码逻辑,学习如何添加自定义词汇、选择不同的分词算法以及实现词频统计功能。在此过程中,不断优化代码,尝试根据自身对特定领域词汇的理解,调整分词规则,体会自建服务的可控性与灵活性。
- 结合硅基生命概念拓展应用:在熟练掌握分词技能后,将其与 AI 人工智能硅基生命的概念相结合。思考如何通过分词技术更好地理解与模拟硅基生命可能产生的 "语言" 模式,或者如何利用分词对与硅基生命相关的研究数据进行高效处理与分析。尝试参与相关的开源项目,与其他爱好者交流经验,拓宽思路,进一步提升自己在 AI 领域的综合能力。
"未来之窗" 的自建分词服务不仅为当下的数据处理难题提供了卓越解决方案,更为初学者开启了一扇通往 AI 人工智能硅基生命探索之旅的大门。通过扎实的学习与实践,相信在不久的将来,更多人能够在这片充满无限可能的领域中绽放光彩。
代码示例:
分词模块
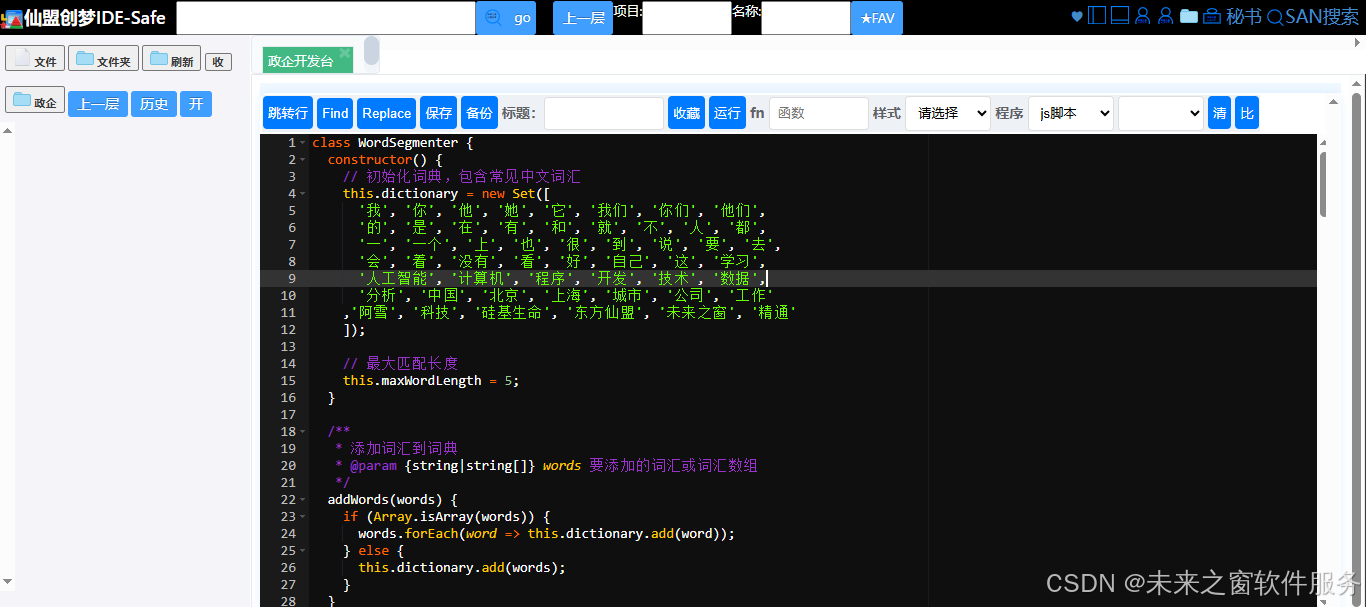
class WordSegmenter {
constructor() {
// 初始化词典,包含常见中文词汇
this.dictionary = new Set([
'我', '你', '他', '她', '它', '我们', '你们', '他们',
'的', '是', '在', '有', '和', '就', '不', '人', '都',
'一', '一个', '上', '也', '很', '到', '说', '要', '去',
'会', '着', '没有', '看', '好', '自己', '这', '学习',
'人工智能', '计算机', '程序', '开发', '技术', '数据',
'分析', '中国', '北京', '上海', '城市', '公司', '工作'
,'阿雪', '科技', '硅基生命', '东方仙盟', '未来之窗', '精通'
]);
// 最大匹配长度
this.maxWordLength = 5;
}
/**
* 添加词汇到词典
* @param {string|string[]} words 要添加的词汇或词汇数组
*/
addWords(words) {
if (Array.isArray(words)) {
words.forEach(word => this.dictionary.add(word));
} else {
this.dictionary.add(words);
}
}
/**
* 从词典中移除词汇
* @param {string|string[]} words 要移除的词汇或词汇数组
*/
removeWords(words) {
if (Array.isArray(words)) {
words.forEach(word => this.dictionary.delete(word));
} else {
this.dictionary.delete(words);
}
}
/**
* 正向最大匹配分词算法
* @param {string} text 要分词的文本
* @returns {string[]} 分词结果数组
*/
segmentForward(text) {
const result = [];
let index = 0;
const textLength = text.length;
while (index < textLength) {
// 确定当前尝试的最大长度
let maxTryLength = Math.min(this.maxWordLength, textLength - index);
let found = false;
// 从最大长度开始尝试匹配
for (let len = maxTryLength; len > 0; len--) {
const word = text.substr(index, len);
if (this.dictionary.has(word)) {
result.push(word);
index += len;
found = true;
break;
}
}
// 如果没有找到匹配的词,将单个字符作为词
if (!found) {
result.push(text.substr(index, 1));
index++;
}
}
return result;
}
/**
* 反向最大匹配分词算法
* @param {string} text 要分词的文本
* @returns {string[]} 分词结果数组
*/
segmentBackward(text) {
const result = [];
let index = text.length;
while (index > 0) {
// 确定当前尝试的最大长度
let maxTryLength = Math.min(this.maxWordLength, index);
let found = false;
// 从最大长度开始尝试匹配
for (let len = maxTryLength; len > 0; len--) {
const start = index - len;
const word = text.substr(start, len);
if (this.dictionary.has(word)) {
result.unshift(word);
index = start;
found = true;
break;
}
}
// 如果没有找到匹配的词,将单个字符作为词
if (!found) {
index--;
result.unshift(text.substr(index, 1));
}
}
return result;
}
/**
* 简单的双向最大匹配分词算法
* @param {string} text 要分词的文本
* @returns {string[]} 分词结果数组
*/
segment(text) {
const forwardResult = this.segmentForward(text);
const backwardResult = this.segmentBackward(text);
// 选择分词数量较少的结果
if (forwardResult.length < backwardResult.length) {
return forwardResult;
} else if (backwardResult.length < forwardResult.length) {
return backwardResult;
}
// 如果分词数量相同,选择单字较少的结果
const countSingleForward = forwardResult.filter(word => word.length === 1).length;
const countSingleBackward = backwardResult.filter(word => word.length === 1).length;
return countSingleForward <= countSingleBackward ? forwardResult : backwardResult;
}
/**
* 分词并返回带分隔符的字符串
* @param {string} text 要分词的文本
* @param {string} separator 分隔符,默认为空格
* @returns {string} 分词后的字符串
*/
segmentToString(text, separator = ' ') {
return this.segment(text).join(separator);
}
/**
* 统计分词结果中每个词的出现频率
* @param {string} text 要分析的文本
* @returns {Object} 词频统计对象
*/
getWordFrequency(text) {
const words = this.segment(text);
const frequency = {};
words.forEach(word => {
if (frequency[word]) {
frequency[word]++;
} else {
frequency[word] = 1;
}
});
return frequency;
}
}
// 使用示例
if (typeof module !== 'undefined' && module.exports) {
module.exports = WordSegmenter;
} else {
// 浏览器环境下的示例
window.WordSegmenter = WordSegmenter;
// 演示代码
document.addEventListener('DOMContentLoaded', () => {
const segmenter = new WordSegmenter();
segmenter.addWords(['分词', '服务', 'JavaScript', '演示']);
const testText = '这是一个JavaScript分词服务的演示,用于展示中文分词功能。';
const result = segmenter.segment(testText);
const resultStr = segmenter.segmentToString(testText);
const frequency = segmenter.getWordFrequency(testText);
console.log('分词结果数组:', result);
console.log('分词结果字符串:', resultStr);
console.log('词频统计:', frequency);
});
}使用
// 执行分词
function performSegmentation() {
const text = document.getElementById('textInput').value.trim();
const algorithm = document.getElementById('segmentAlgorithm').value;
let result;
if (!text) {
alert('请输入要分词的文本');
return;
}
// 根据选择的算法执行分词
switch(algorithm) {
case 'forward':
result = segmenter.segmentForward(text);
break;
case 'backward':
result = segmenter.segmentBackward(text);
break;
default:
result = segmenter.segment(text);
}开源地址
https://gitee.com/cybersnow/wlzcImmortal-Alliance-commonly-used-source-code
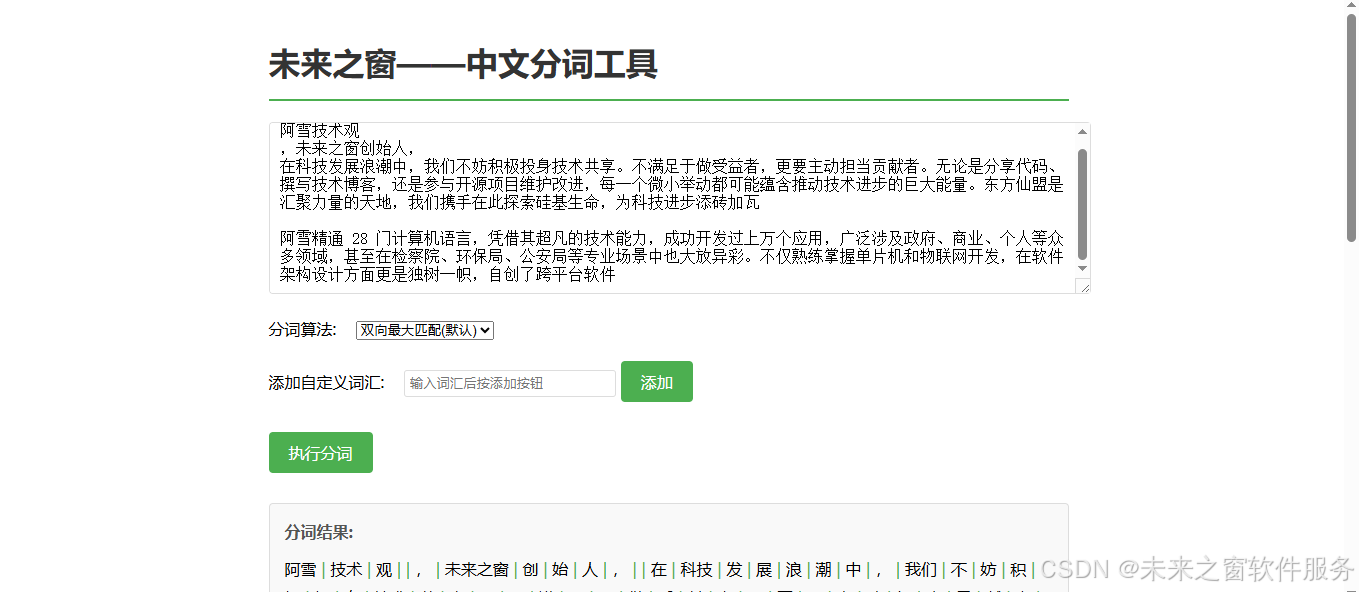
阿雪技术观
在科技发展浪潮中,我们不妨积极投身技术共享。不满足于做受益者,更要主动担当贡献者。无论是分享代码、撰写技术博客,还是参与开源项目维护改进,每一个微小举动都可能蕴含推动技术进步的巨大能量。东方仙盟是汇聚力量的天地,我们携手在此探索硅基生命,为科技进步添砖加瓦。
Hey folks, in this wild tech - driven world, why not dive headfirst into the whole tech - sharing scene? Don't just be the one reaping all the benefits; step up and be a contributor too. Whether you're tossing out your code snippets, hammering out some tech blogs, or getting your hands dirty with maintaining and sprucing up open - source projects, every little thing you do might just end up being a massive force that pushes tech forward. And guess what? The Eastern FairyAlliance is this awesome place where we all come together. We're gonna team up and explore the whole silicon - based life thing, and in the process, we'll be fueling the growth of technology.