AI 浪潮已至: 数据基石决定模型高度
随着大语言模型(LLM)与多模态模型的参数量和数据量呈指数级增长,AI 技术正以前所未有的深度与广度变革千行百业。从国内顶尖 AI 模型登顶全球 SOTA,到各大智算中心竞相追逐更高的算力,这场智能革命的背后,是对数据存储和处理能力的极致渴求。
一个典型的 AI 工作流,从海量数据采集、清洗预处理,到 GPU 集群的高并发训练,再到最终的模型推理服务,每一个环节都对数据 I/O 提出了严苛挑战。任何环节的瓶颈,都会直接导致昂贵的 GPU 算力闲置,严重拖慢研发效率。
XSKY星辰天合深耕分布式存储领域多年,凭借在金融、运营商等关键行业服务超过 3000 家客户的深厚积累,深刻理解大规模数据管理的复杂性。如今,我们将久经考验的企业级能力注入 AI 领域,以 XEOS 对象存储为核心,成功为某头部 AGI 厂商 M、某国家级 AI 实验室、某大型智算中心等数十家 AI 头部用户提供了稳定、高效的数据底座,支撑客户在 AI 浪潮中乘风破浪。
分层建设: AI 基础设施的必然趋势
面对 AI 全生命周期中迥异的数据访问需求,单一存储类型已难以为继。"全闪+混闪"的分层建设,已成为业界平衡性能与成本的必然选择。
一个典型的 AI 分层数据湖架构如下:
-
数据预处理平台 :负责原始数据的采集、清洗、标注和增强,产生海量温冷数据。
-
高性能存储层(热层) :通常由全闪存介质构成,直接对接模型训练和推理任务,满足其对低延迟、高带宽、高 IOPS 的极致性能要求。
-
大容量存储层(温/冷层) :通常由混闪或大容量 HDD 介质构成,负责承接海量原始数据、中间数据和归档数据,追求极致的成本效益。
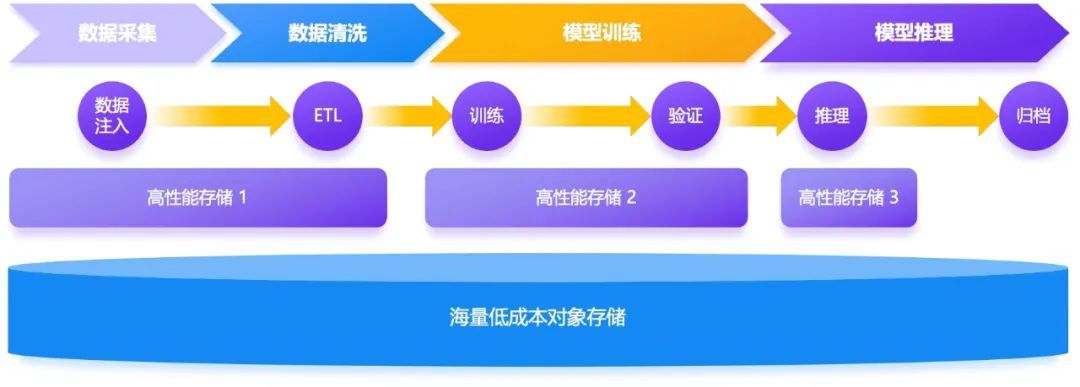
通过分层,企业可以将最宝贵的全闪资源用在刀刃上,同时以更经济的方式存储海量数据。然而,理想的架构在落地时却常常遭遇骨感的现实。
传统分层建设的三大"痛点"
传统的分层存储方案,看似美好,实则在数据流动的"最后一公里"隐藏着三大核心痛点,严重制约了 AI 的效率。
1、"盲目"的数据流动
传统方案大多基于数据的创建时间(mtime) 进行分层。这意味着,一个正在被高频访问的热点训练集,可能仅仅因为"到期"就被"一刀切"地降级到慢速的混闪池,导致训练任务性能骤降,GPU 大量空等。
2、"割裂"的命名空间
数据在不同存储层之间流动,往往需要数据科学家手动在不同路径、不同挂载点之间进行切换。这不仅增加了操作的复杂性,更容易因路径错误导致训练失败,浪费宝贵的计算资源和时间。
3、"高昂"的隐性成本
为了缓解性能问题,企业不得不将更多数据保留在昂贵的全闪存层,或者在数据被降级后,再耗费大量时间手动将其"拉回"热层。这种反复的数据"搬运"和过度的资源冗余,极大地推高了整体 TCO(总拥有成本)。
某大型智算中心就曾面临此困境:原有开源方案缺少智能分层能力,数据预处理效率低下,导致 GPU 等待时间过长,无法实现热数据高性能训练、冷数据自动归档的顺畅流转。
XEOS 智能 数据湖: 让数据"按需"流动,为性能"自动"加速
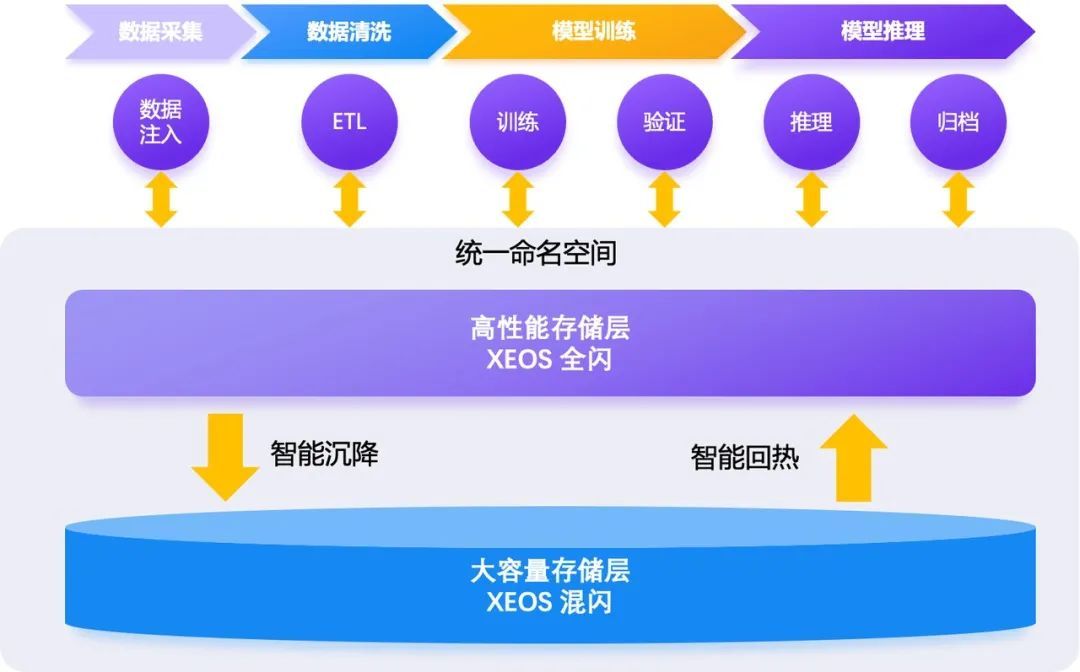
注:XEOS 智能数据湖架构。在统一命名空间下,XEOS 基于访问时间(atime)实现冷数据的智能沉降,并通过自动缓存机制实现热数据的智能回热,彻底打破传统分层存储的性能与管理瓶颈。
为破解上述难题,XSKY XEOS 6.4.200 版本推出了两大革命性功能,从根本上重塑了 AI 场景下的数据分层逻辑,让数据湖真正"智能"起来。
1、基于访问时间(atime)的生命周期管理:让热数据永远"年轻"
XEOS 创新性地引入了基于"最后访问时间(atime)"的生命周期策略。存储系统能够智能感知业务行为,每一次对数据的访问(GetObject/HeadObject),都会刷新其 atime,从而推迟其分层或删除的计划。
核心优势 :只有真正"无人问津"的冷数据才会被流动到低成本存储池。对于正在进行的高频训练任务,其数据集会因为持续被访问而一直保留在高性能的全闪热池中,为业务提供稳定、极致的访问性能。
2、分层数据访问增强:透明访问与自动缓存,"一次慢,次次快"
当数据不可避免地被分层到冷池后,XEOS 提供了增强的 "缓存访问模式"。
-
透明访问 :上层应用无需关心数据究竟在哪一层,访问路径始终统一。
-
自动缓存与代理读 :当应用首次访问一个已分层的数据时,XEOS 会从冷池获取数据并返回,保证业务连续性;与此同时,系统会异步地将该数据自动缓存回热池。
-
访问续期 :后续所有对该数据的访问,都将直接从热池的缓存中读取,实现性能加速。并且,每一次访问都会刷新缓存的过期时间(访问续期 ),确保热点数据能长期驻留在高速缓存中。
这一机制实现了"首次访问从冷池读,后续访问从热池缓存读"的智能加速效果。AI 工程师还可以通过批量 HeadObject 操作,有计划地预热数据集,让其提前进入高速缓存,使业务第一次访问就能获得极致性能。
实践见证: 从头部 AGI 厂商到智算中心的效能突破
理论的先进性,最终需要实践来检验。XEOS AI 数据湖方案已在多个业界顶级的 AI 项目中证明了其卓越价值。
1、助力国内某头部 AGI 厂商登顶 SOTA 模型
-
XSKY 为国内某头部 AGI 厂商 M 提供了关键助力,其基于 XEOS 的全闪****数据湖,稳定承载了数据采集、处理、训练、推理的全部任务。
-
在实际负载中,XEOS 以单一存储集群平稳应对了周期性近 2Tbps 的写入和峰值超过 5Tbps 的突发读取,且在极限压力下,读取时延仍保持在 8ms以内,充分满足了国际顶尖 AI 大模型对存储的严苛要求。
2、服务某大型智算中心
-
面对 4 个月内数据增长超 20PB 的迅猛势头,XEOS 混闪对象存储作为数据根基,提供了强大的弹性和性能。
-
在扩容重平衡期间,依然能支撑训练任务的大量数据加载,实测读取峰值高达 149.34 GB/s,写峰值 61.67 GB/s。
-
相较于原开源方案,训练效率提升了 300%,极大地释放了 GPU 算力。
这些成功案例充分证明,XEOS AI 数据湖方案不仅能提供 TB/s 级的澎湃带宽和金融级的可靠性,更能通过智能的数据流动与管理,从根本上解决 AI 分层建设的痛点,将 AI 研发和 Infra 团队从繁琐的数据运维中解放出来,专注算法与模型的创新。
选择 XEOS,就是选择一个更懂 AI、更智能、更具成本效益的数据未来**。**