前言
最近大模型圈动态不断,各家接连发布新版本,行业节奏明显加快。
在这样的背景下,不少人都在等 DeepSeek 的下一代旗舰模型 R2------毕竟从年初传到年中,发布时间一再推迟,期待值也被拉得越来越高。
但等来的不是 R2,而是 DeepSeek-V3.1。
V3.1 都更新了什么?
我们先来看看升级内容:
- 混合推理架构:支持在"快速响应"和"深度思考"两种模式间切换,一个模型兼顾效率与深度。
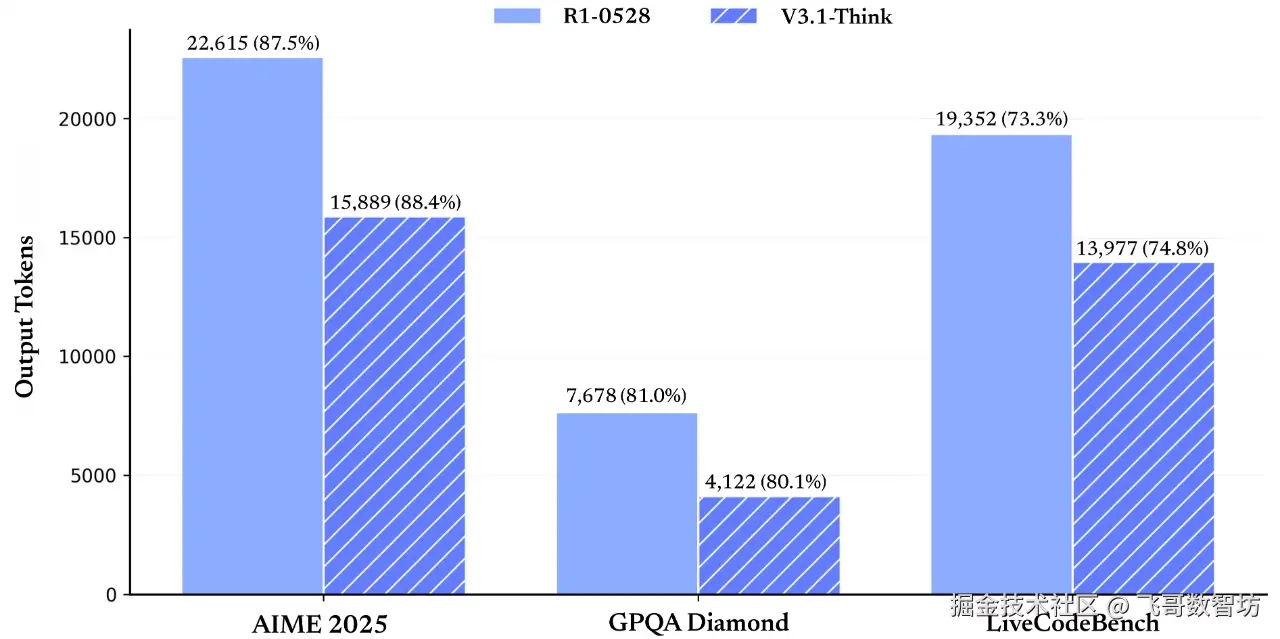
- 更高的思考效率:相比之前的 R1 版本,新模型在保持推理质量的同时,响应速度有所提升。
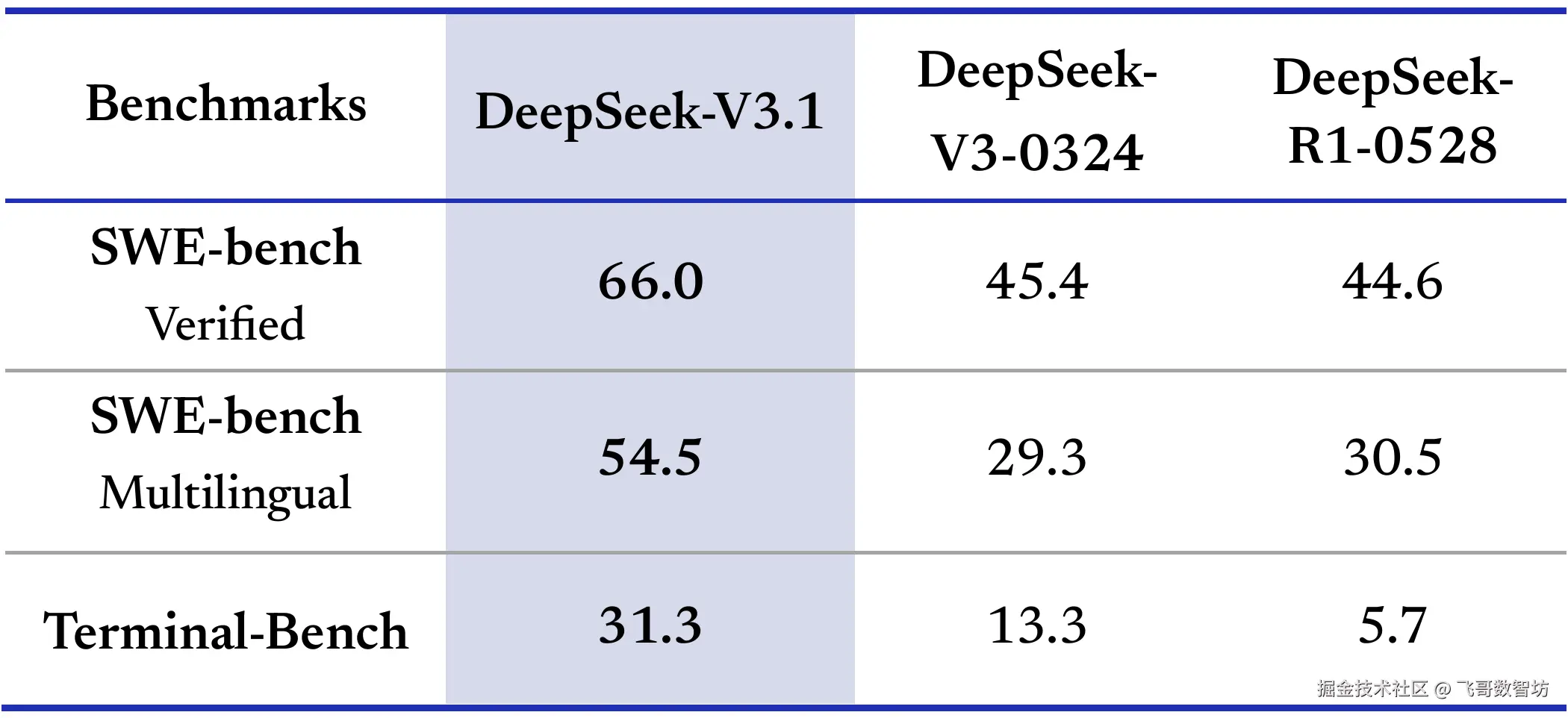
- 更强的 Agent 能力:通过后训练优化,在工具调用、任务规划等智能体场景中的表现更稳定。
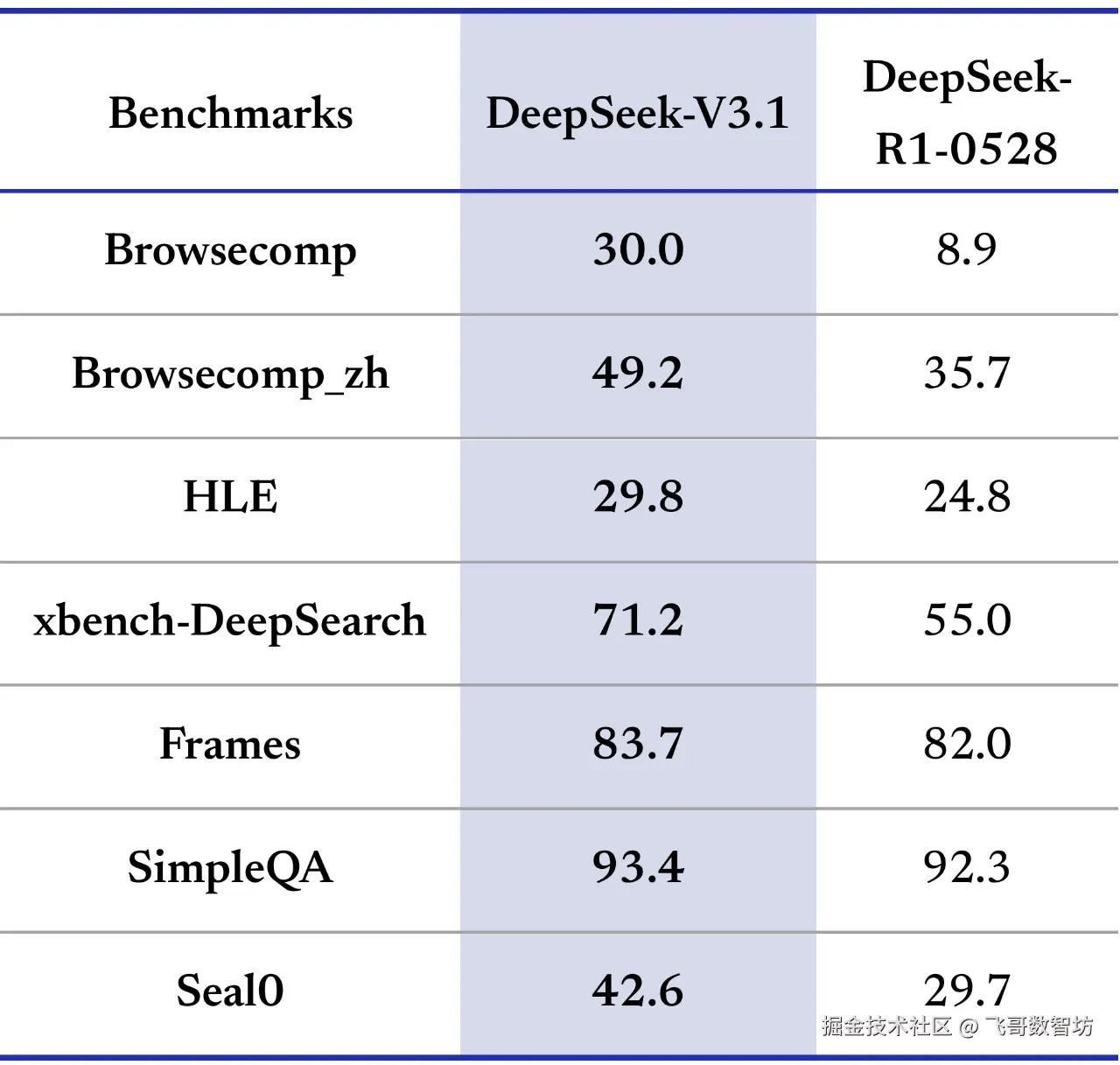
- 兼容 Anthropic API 格式:方便开发者将其集成进 Claude Code 等生态框架。

- 9月6日后价格调整,取消夜间时段优惠

至于网上传的上下文升级到 128K,这个能力早在 V3 和 R1 的早期版本中就已经支持,并不是这次的新内容。
混合推理架构
其中,最大的升级就是"混合推理架构"。
给大家解释下。
- V3 这类不能深度思考的叫做普通模型。
- R1 这类只能深度思考的叫做推理模型。
而支持设置"是否深度思考"的模型就叫做"混合推理"模型,既能快速处理简单问答,也能应对需要多步推理的复杂任务。
也就是说,如果之后 V3.1 模型实际效果还可以,那以后的 DeepSeek 模型可能将不再区分 V 和 R 系列,而是只有一个统一的模型了。
但不管是提出混合推理的 Open AI, 还是国内首发混合推理的 Qwen3,后来都选择了非融合方案。
一点猜测
没有等到 DeepSeek R2,大家都有落差。
但看了很多资讯和文档后,我在想,会不会我们看到的 V3.1 就是我们设想的 R2,或者 V4?
只不过和我们设想不一样的是,深度求索团队当时选择了"混合推理"路线,原计划会把混合推理模型发布为 R2/V4,或者重开一个系列。
但,也许是能力没有达到预期,也许是 GPT-5 和 Qwen3 的选择给了一些提醒。最终,我们只看到了 V3.1。
其实,V3.1 这个命名也一定程度上印证着这次的不同寻常。
希望今年,我们可以看到一次大的版本更新!
加油,DeepSeek!