大家好,我是吾鳴。专注于分享提升工作与生活效率的工具,无偿分享AI领域相关的精选报告,持续关注AI的前沿动向。
大家在做抖音平台视频账号的时候,是否遇到一些和自己对标的账号,希望可以对目标账号发布的内容做一些分析,比如账号的定位、人设的设计、选题方向、内容结构、变现路径等,同时也希望可以分析一下对标账号有哪些不足,以便做自己的账号的时候,可以吸取教训,毕竟站在巨人的肩膀上或许会更容易成功。
本文要分享的工作流,可以实现对标账号的拆解与分析,最后输出一份完整的分析报告,报告中包含有账号基本信息、账号定位、人设设计、选题方向、内容结构、变现路径以及优化建议等。
工作流只需要输入一个对标账号的视频分享链接,就可以实现账号的拆解与分析,生成分析报告到飞书分档中,先看看工作流的实际运行效果。
工作流的输入如下(具体的输入参数,会在下面拆解章节中详解):
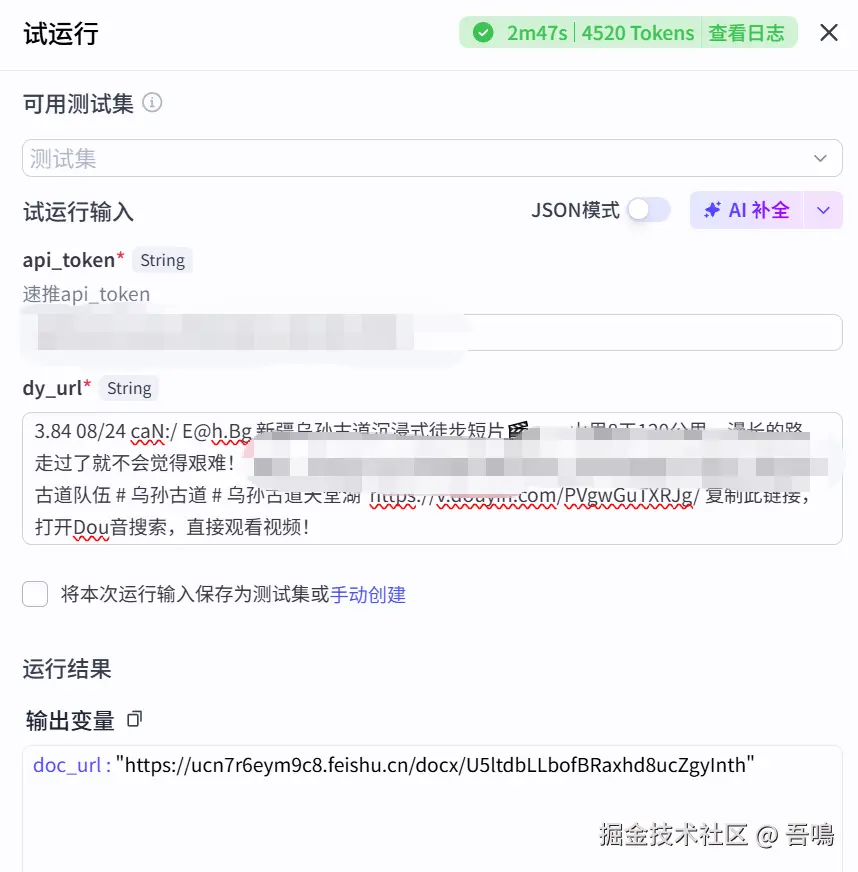
工作流输出如下:

下面我们一起来看下完整的工作流以及工作流中各个节点的详细介绍。
一、完整工作流
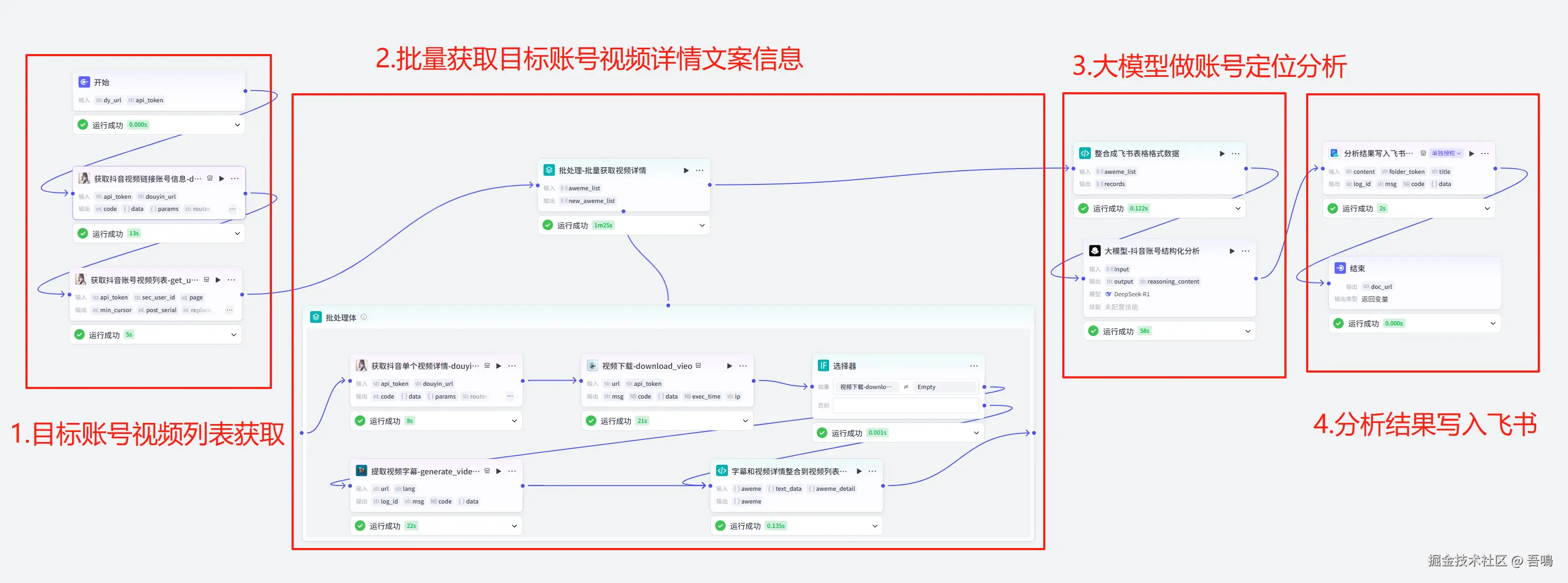
完整的工作流程图如上,工作流不算复杂,用到的都是平常中常用的一些插件,下面的章节我会按照【目标账号视频列表获取】、【批量获取目标账号视频详情文案等信息】、【大模型做账号定位分析】和【分析结果写入飞书】这四大部分做解读。
二、目标账号视频列表获取
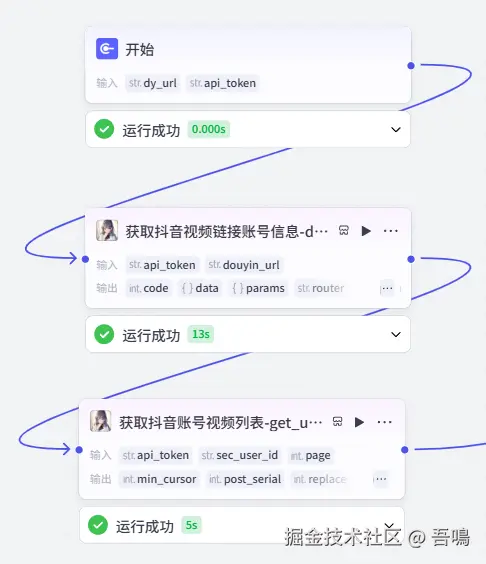
这一部分内容主要包含三个节点,一个开始节点和两个获取视频信息的节点,获取视频信息的节点分别使用到了"视频搜索"插件,下面分别对这几个节点做详细的解读。
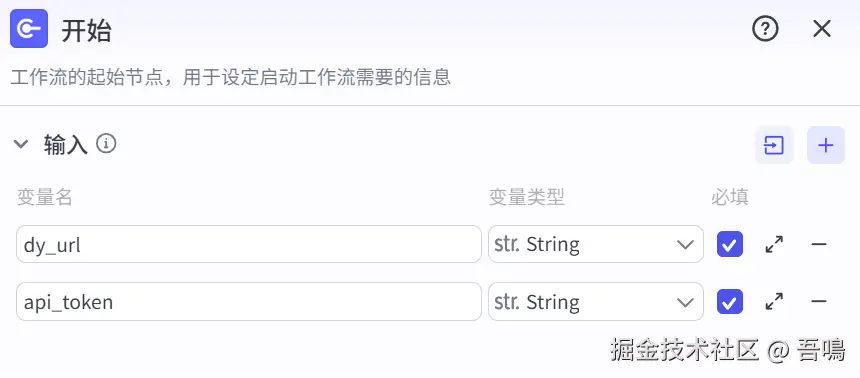
开始
这个节点用来接收用户输入的参数,它们分别是:
- dy_url:抖音平台视频分享链接
- api_token:速推平台的认证,可以到 www.51aigc.cc/#/home?user... 这里领取token,源码安装包也有详细的教程获取token。
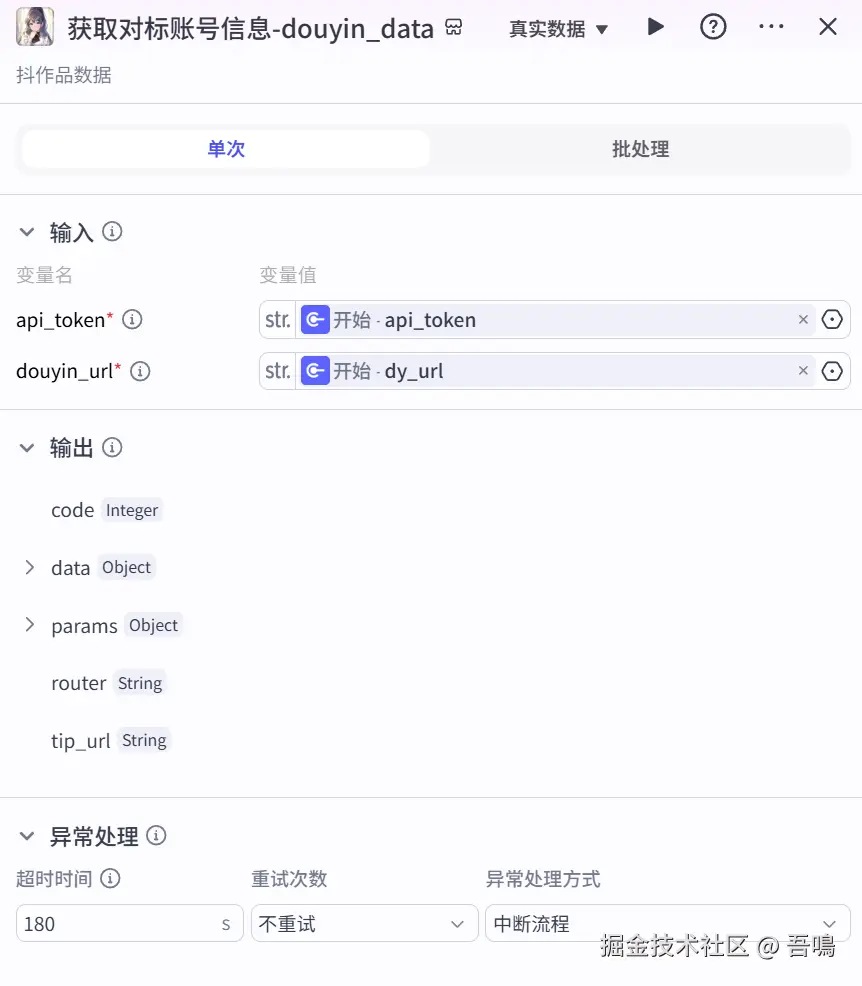
获取对标账号信息
这个节点主要用来获取对标的账号信息,便于下游的节点可以使用它输出的"sec_uid"信息来获取对标账号的视频列表,这个节点主要使用到了"视频搜索"插件的"douyin_data"工具。这个节点的输入参数如下:
- api_token:速推token,引用"开始"节点的"api_token"
- dy_url:视频分享链接,引用"开始"节点的"dy_url"
获取抖音账号视频列表
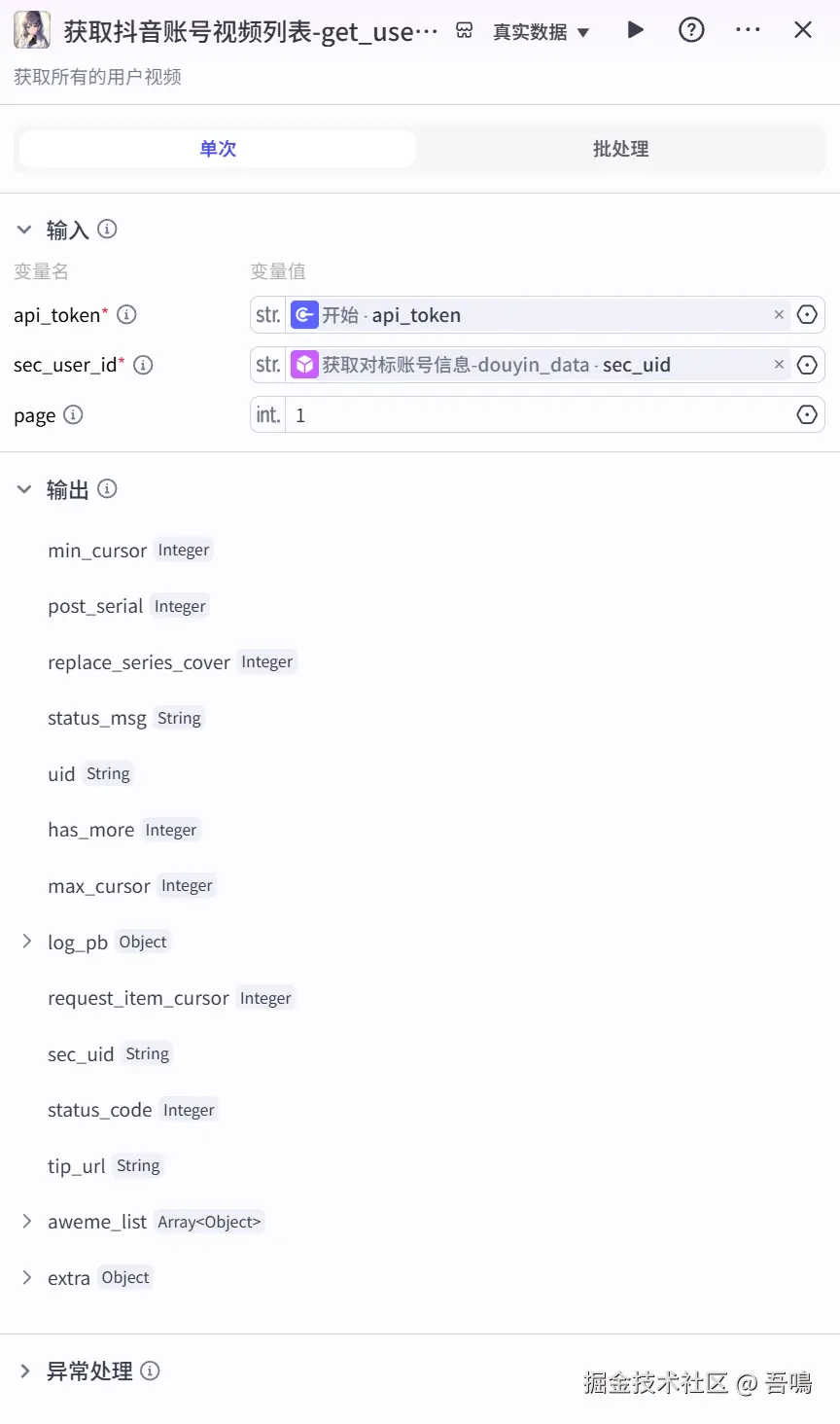
这个节点主要的作用是用来获取对标账号的视频列表,它使用到了"视频搜索"插件的"get_user_video_all"工具。它的输入参数如下:
- api_token:速推token,引用"开始"节点的"api_token"
- sec_user_id:对标账号的用户ID,引用"获取对标账号信息"节点的"sec_uid"
- page:获取对少页,1页。获取的页数越大,分析的结果会越准确,消耗的资源点也会越多
三、批量获取目标账号视频详情文案等信息
这一部分是用来批量获取视频的详情信息以及提取视频的文案信息,主要使用到了【视频搜索】、【视频下载】、【提取视频字幕】等插件,下面会对这部分中的节点做详细的解读。
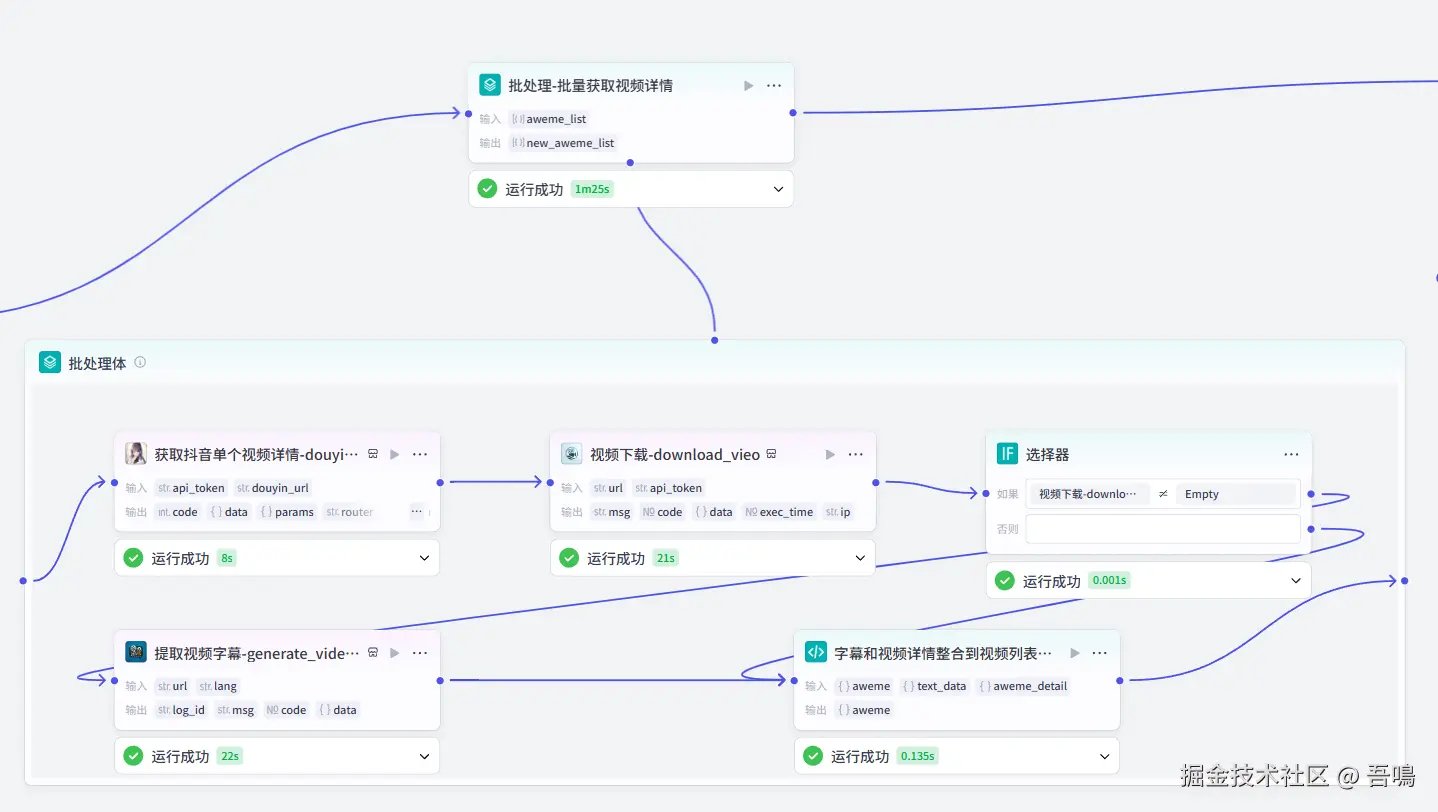
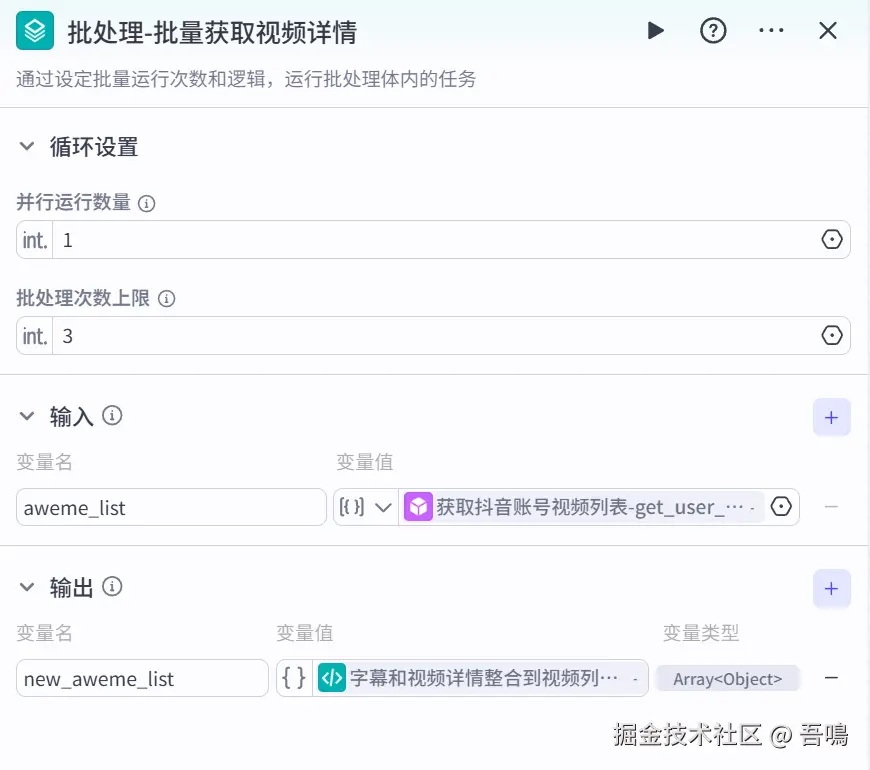
批处理-批量获取视频详情
这个节点是一个"批处理"节点,用来批量获取视频详情信息和提取视频文案信息,并把提取到的视频详情和文案放到视频列表中。它主要的参数如下:
- 并行运行数量:同时获取多少个视频的详情和文案,这里我输入"1",如果觉得太慢可加大此参数
- 批处理次数上限:最多获取多少个视频的详情和文案,这里我输入"3",如果需要精准度高可调大此参数
- 输入:
-
- aweme_list:对标账号视频列表,引用"获取抖音账号视频列表"输出的"aweme_list"
- 输出:
-
- new_aweme_list:新的视频列表信息,引用"字幕和视频详情整合到视频列表"输出的"aweme"
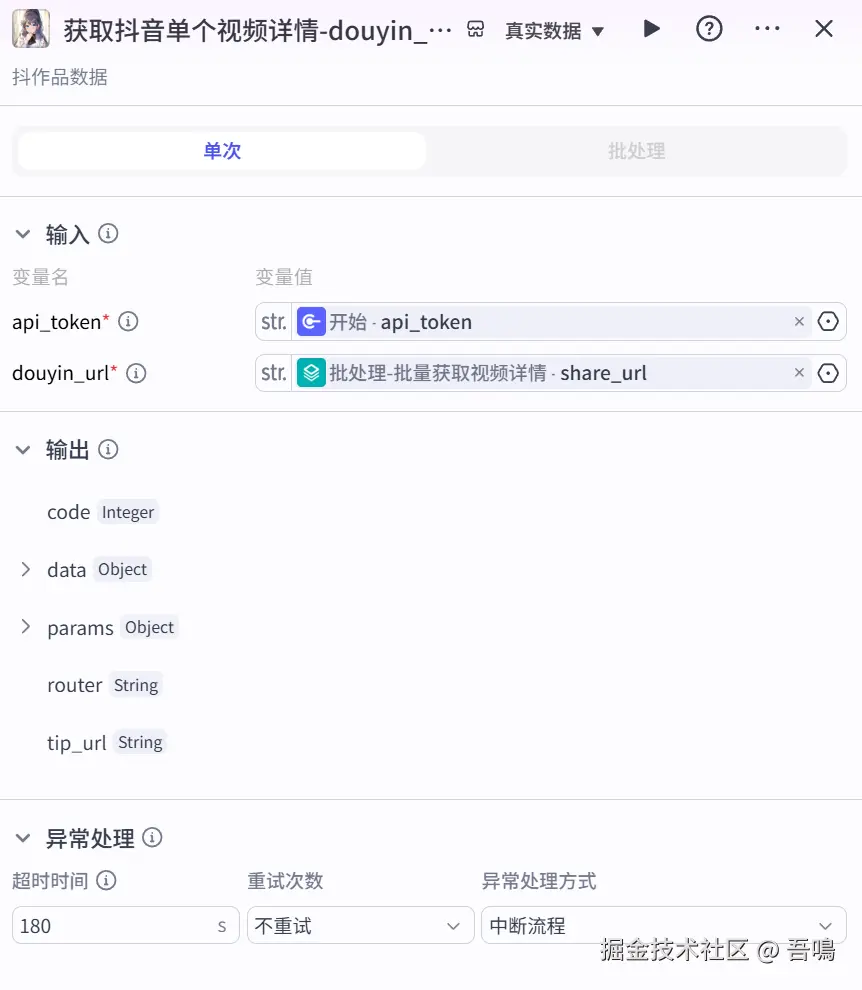
获取抖音单个视频详情
这个节点用于获取单个视频的详情,这个节点使用了"视频搜索"插件的"douyin_data"工具。参数如下:
- api_token:速推token,引用"开始"节点的"api_token"
- douyin_url:视频链接,应用"批处理-批量获取视频详情"的"share_url"
视频下载
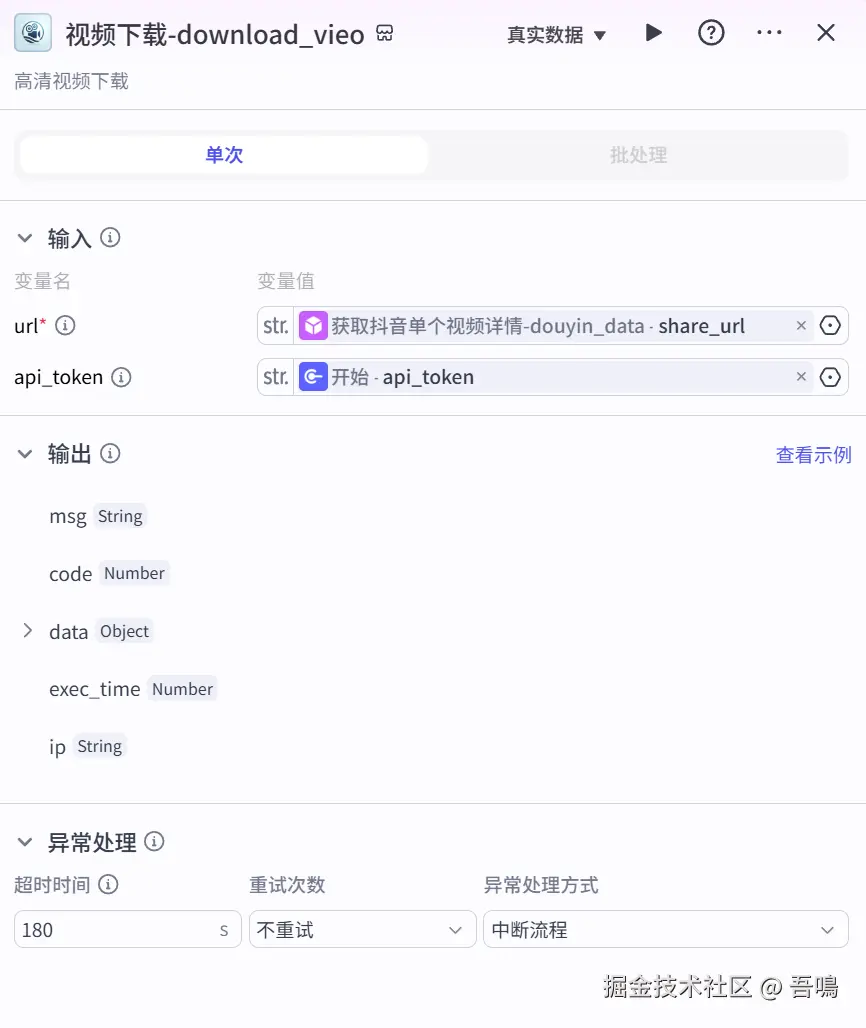
这个节点用于下载视频,它主要使用到了"视频下载"插件的"download_vieo"工具。它的参数如下:
- url:视频地址,引用"获取抖音单个视频详情"节点输出的"share_url"
- api_token:速推api_token,引用"开始"节点的"api_token"
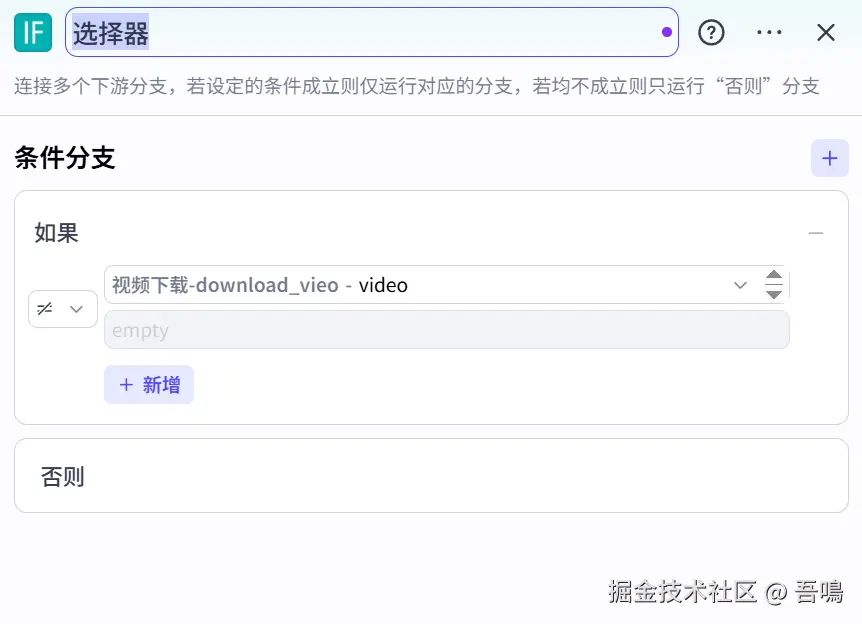
选择器
这个节点主要用于判断视频链接是否为空,空的话则不执行"提取视频字幕"节点,它主要是扣子官方的"选择器"节点类型。它的参数如下:
- 选择"视频下载"节点输出的"video",条件选择"不为空"
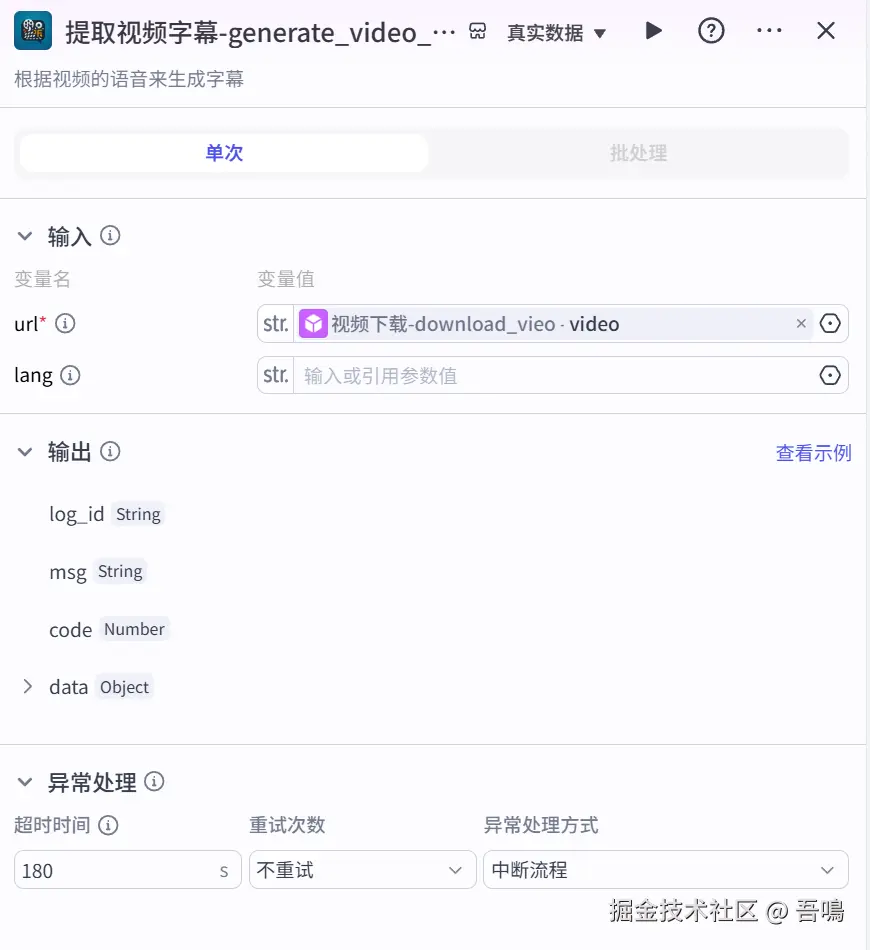
提取视频字幕
这个节点用来提取视频的字幕信息,它用到了"提取视频字幕"插件的"generate_video_captions_sync"工具,它的参数如下:
- url:视频地址,引用"视频下载"的"video"
- lang:语言,默认"汉语"
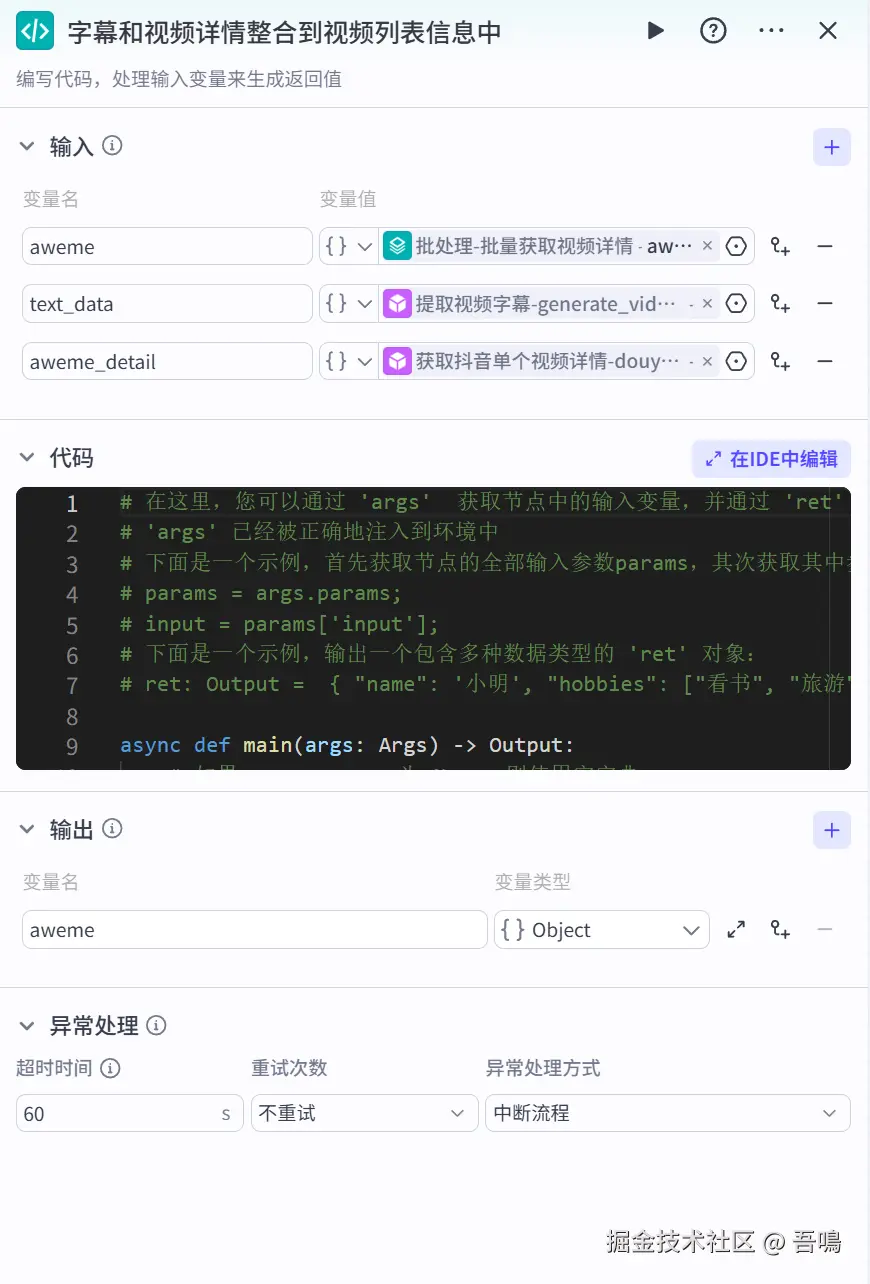
字幕和视频详情整合到视频列表信息中
这个节点通过Python代码,把视频详情和字幕信息,整合到视频列表中。这里使用到了扣子官方的"代码"节点类型。它的参数如下:
- aweme:单个视频信息,引用"批处理-批量获取视频详情"的"aweme_list"
- text_data:视频字幕信息,引用"提取视频字幕"的"data"
- aweme_detail:视频详情信息,引用"获取抖音单个视频详情"的"aweme_detail"
- 代码:和源码包一起打包好放在了文末,感兴趣自取
四、大模型做账号定位分析
这部分内容根据前面提取到的视频详情和文案信息,把这些信息交给大模型来做账号定位分析,输出一份完整的报告。下面会对这部分使用到的节点做详细的解读。
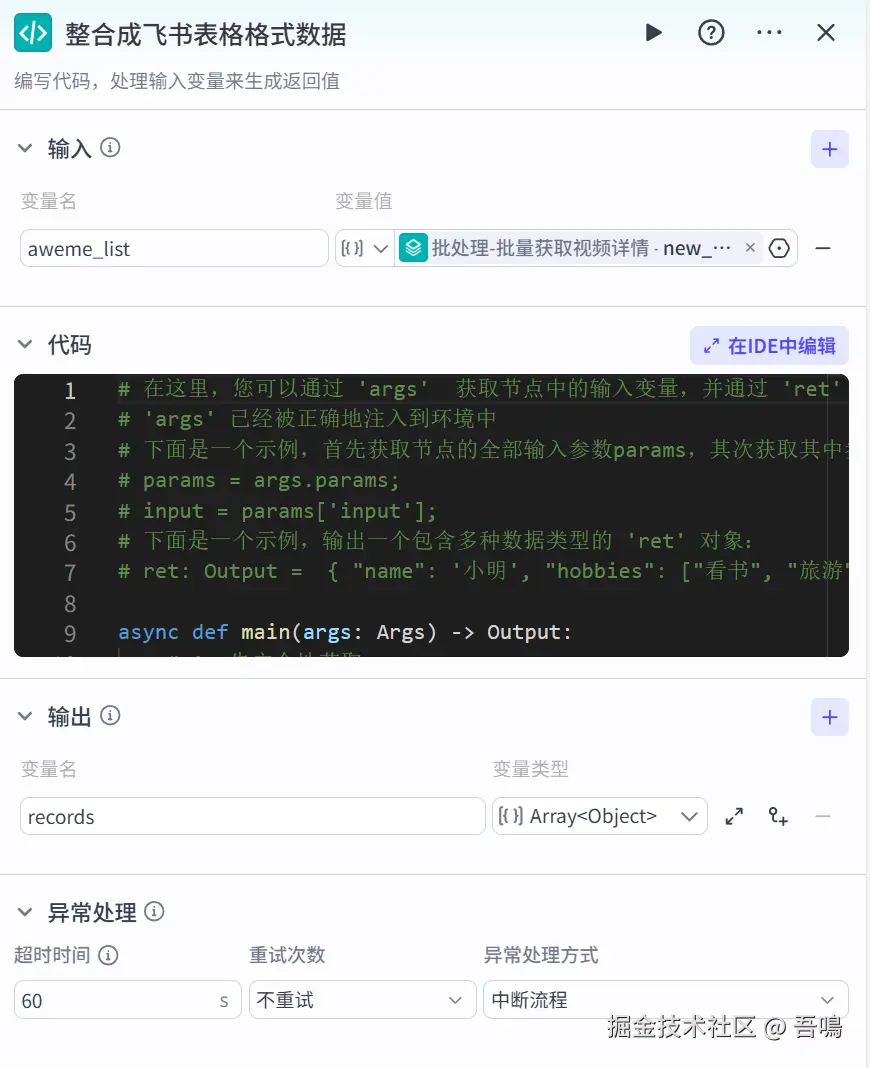
整合成飞书表格格式数据
这个节点主要是把前面提取到的视频信息转成飞书表格的形式,便于交给大模型来做定位分析,这个节点使用到了扣子官方的"代码"节点类型。详细参数如下:
- aweme_list:视频信息列表,引用"批处理-批量获取视频详情"的"new_aweme_list"
- 代码:已经打包好放到了文末,感兴趣自取
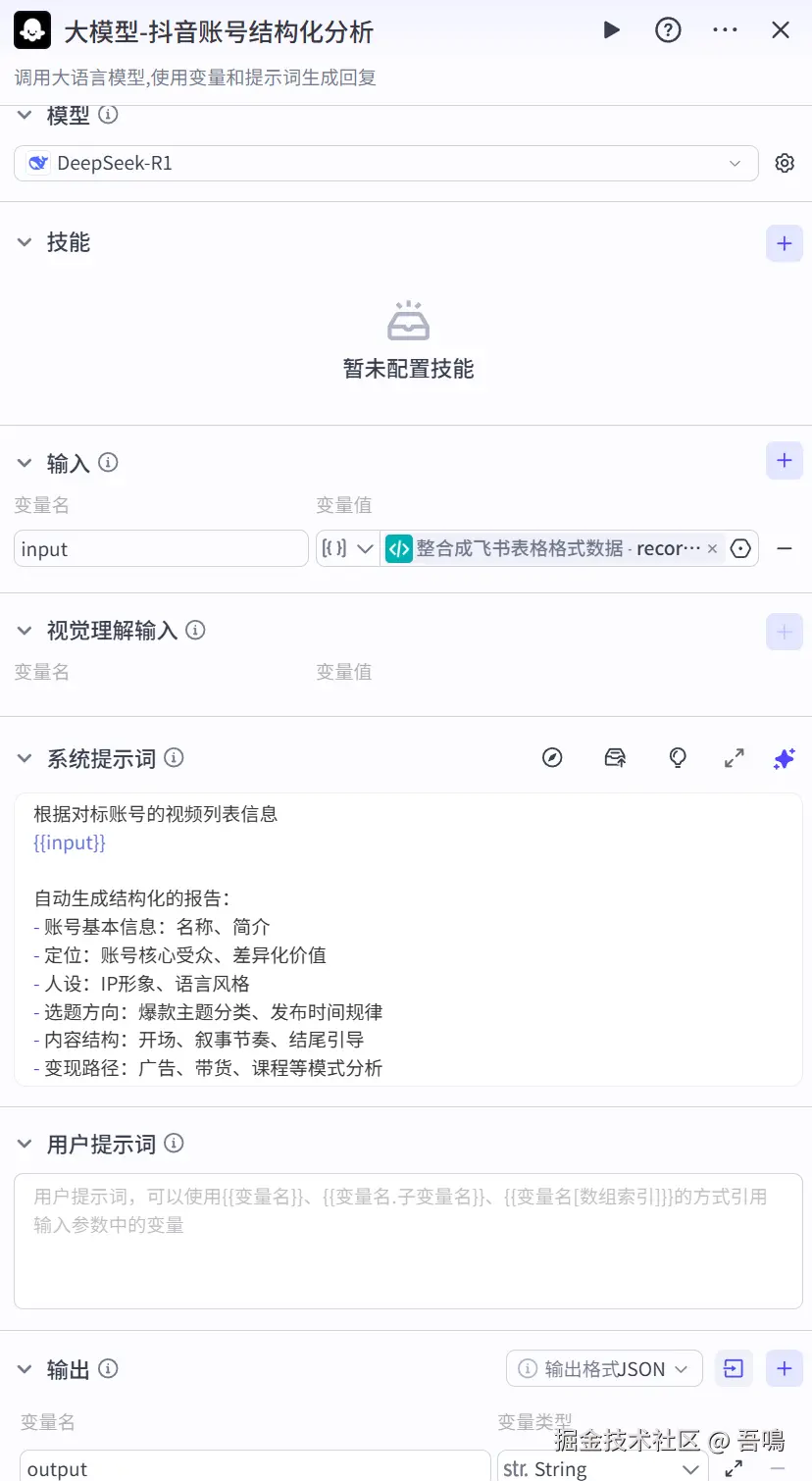
大模型-抖音账号结构化分析
这个节点根据输入的视频信息做账号定位分析,主要使用到了扣子官方的"大模型"节点类型。参数如下:
- 模型:选择"DeepSeek-R1"
- 输入:
-
- input:视频列表列表,引用"整合成飞书表格格式数据"的"records"
- 提示词:已经打包好放到了文末,感兴趣自取
- 输出:
-
- output:分析后的报告结果
五、分析结果写入飞书
这部分用于把对标账号定位分析后的结果写入到飞书文档中,这部分主要使用到了"飞书云文档"插件。这部分就只有这一个节点,后面的就是结束节点了,下面对这两个节点做下详细的解读。
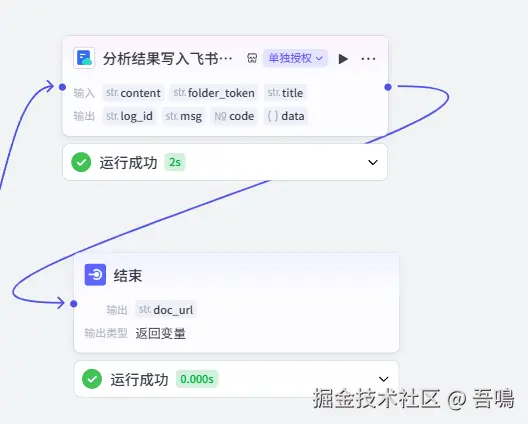
分析结果写飞书
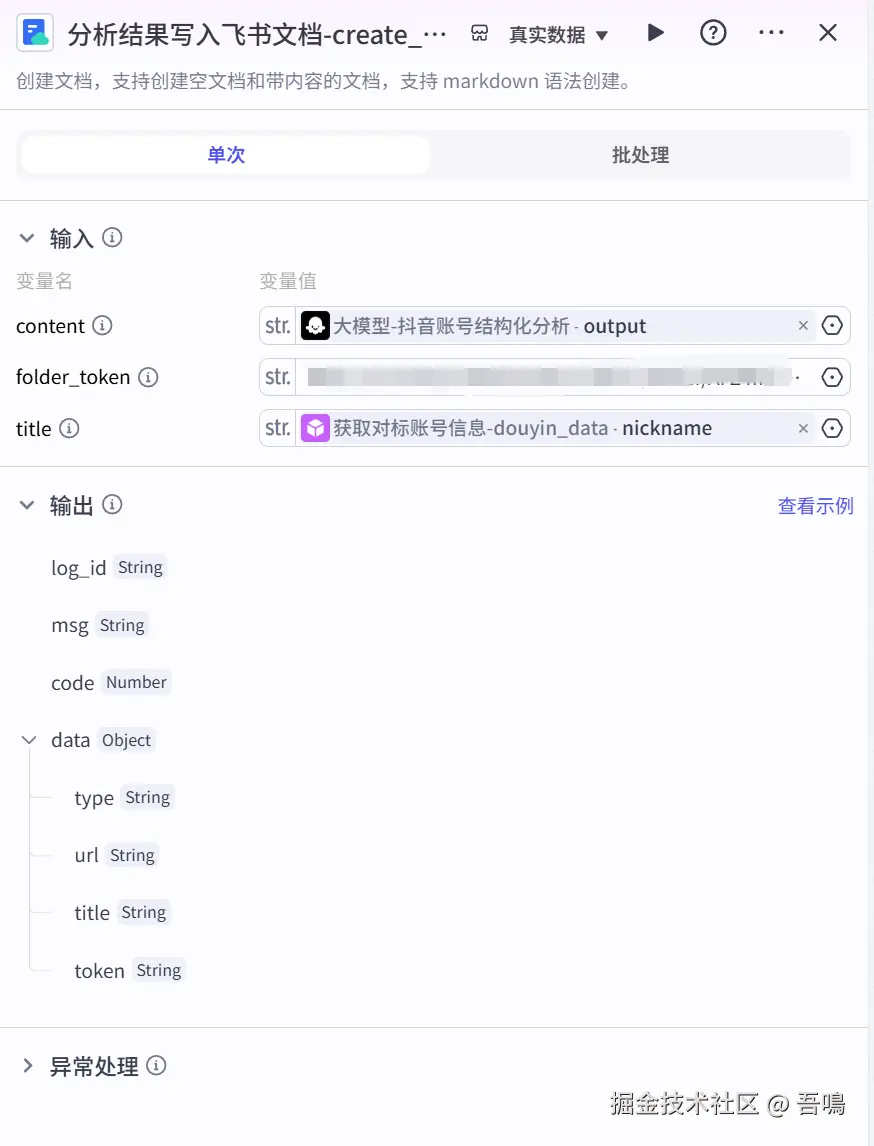
这个节点是使用了"飞书云文档"插件的"create_document"工具,它的参数如下:
- content:文档内容,引用"大模型-抖音账号结构化分析"的"output"
- folder_token:飞书文件夹地址,可以到飞书文档文件夹下拷贝地址
- title:文档名称,引用"获取对标账号信息"的"nickname"
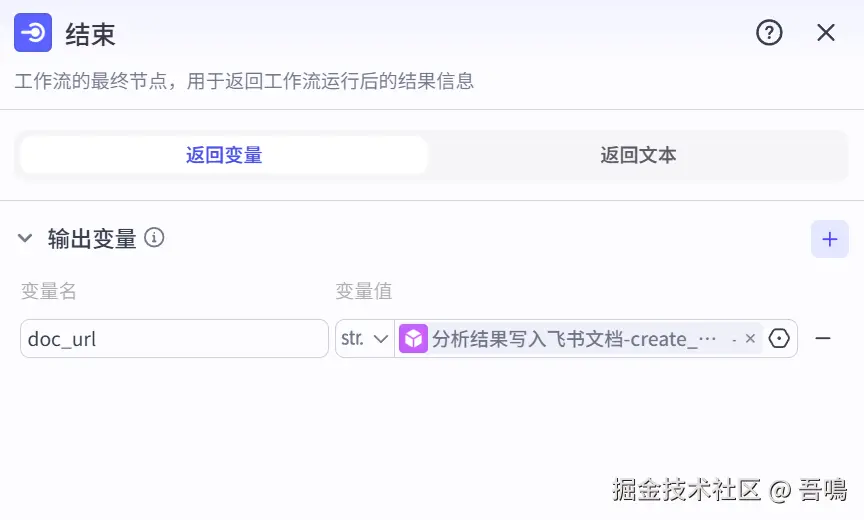
结束
- doc_url:飞书文档地址,浏览器打开即可。引用"分析结果写入飞书文档"的"url"
今天的分享就到这里,如果您觉得有收获的话,可以给个一键三连,您的鼓励是吾鳴持续输出的最大动力。有什么疑问也可以打在评论区,吾鳴会第一时间回复。

这个扣子工作流的源码、提示词都已经打包好,创作不易,感兴趣的朋友可以一键三连 ,评论区评论"抖音账号分析" 领取。