一、概述
1.1、背景描述
在多轮对话系统中,意图识别作为核心的流程入口节点,承担着理解用户真实需求的关键职责。其核心任务是从用户输入的对话内容(包括文本、语音等多种形式)中分析并判断用户的核心目的或意图,为后续的对话编排、业务处理和服务分发提供准确的决策依据。
意图识别在整个对话流程中发挥着多重作用:引导对话流程-基于识别结果动态调整对话策略和话术;提高对话效率-快速定位用户需求,减少无效交互轮次;增强用户体验-提供精准的个性化服务和响应
1.2、难点识别
1.2.1、意图理解
意图理解的目的是识别用户在当前轮次 话语中表达的核心目标或请求。在实际应用中,主要面临以下技术挑战:
1.2.2、意图澄清
当系统无法确定 用户的意图时,需要主动发起询问以明确用户的真实意图或获取缺失的关键信息。常见的策略包括:
1. 话术引导设计
- 意图识别不仅是技术问题,更需要设计合理的业务流程话术引导
- 将用户意图与业务流程进行映射和转化,为问题选择最适合的工作流
- 设计标准化的话术模板,提高澄清效率
2. 对话轮次控制
- 结合话术引导,严格控制对话轮次数量,避免过度交互
- 例如:设置引导话术"请问您要购买什么手机?例如您可说'购买最新款苹果'",在此场景中仅需提取2轮上下文即可完成意图识别
3. 实体信息提取
- 结合命名实体识别(NER)技术,提取关键业务实体,辅助意图判断和澄清
4. 追问式澄清
- 基于当前识别结果,设计针对性的追问话术
- 例如:"用户:买苹果" → "客服:请问您要买的是最新款苹果手机吗?"
5. 置信度阈值管理
- 结合意图识别的置信度分数,设置不同级别的澄清策略
- 低置信度时触发澄清流程,高置信度时直接进入业务处理
基于上述策略,可以构建一个意图澄清工作流:
二、方案设计
2.0、常见做法
| 手段 | 做法 | 优点 | 局限 | 适用范围 |
|---|---|---|---|---|
| 基于规则 | 依赖关键词词表、正则表达式、模板匹配、状态机等手段 | 实现简单、可解释性强、时延极低、上线快速 | 扩展性差、难以覆盖长尾表达,维护成本随业务增长线性甚至指数上升 | 固定逻辑、高风险意图(例如:"转人工"等)的强制触发 |
| 向量召回 | embedding 向量化后使用多路检索排序召回知识 | 鲁棒于同义改写和口语变体,可解释(可回显邻近样本),易与知识库融合 | 对域内 embedding 质量与检索参数敏感;需要构建高质量候选库与更新机制 | 多表达、模板较多的咨询类意图 |
| 深度学习(小模型分类) | 文本分类框架(如 RoBERTa、ALBERT 等) | 高吞吐、低时延、可控性强、精度稳定 | 对数据覆盖与类间边界敏感;冷启动阶段对长尾、噪声、上下文依赖弱 | 对实时性与成本敏感的线上主分类器 |
| 大语言模型 | 通过预训练大模型进行 zero/few-shot 推理,或对指令模型进行有监督微调 | 泛化好、对复杂语义和上下文推理能力强、开发门槛低 | 时延与成本较高;对提示词与格式敏感;在数据不足时可能出现幻觉或偏置 | 复杂意图澄清、兜底回退、标注辅助与数据清洗、低流量长尾类 |
2.1、模型选型与阶段评测
实践上采用"模型 + 规则 + 向量召回"的融合方案。为此,我们针对意图识别进行了三阶段评测:
- 大语言模型直接进行意图识别(适用于对性能不敏感、标注数据量大且质量高的场景)
- 大模型标注/改写 + 小模型微调(依赖大模型标注与清洗质量)
- 大模型标注与人工复核、数据增广 + 小模型微调(线上主力方案)
评测数据集(阶段性实验口径):
多轮对话 4k 条;上下文窗口 3 轮;平均输入 token ≈ 500;意图数 8 类。
| 模型 | 训练/推理方式 | 训练数据量 | 意图数 | 准确率 | 平均响应时间 | 幻觉率 | 备注 |
|---|---|---|---|---|---|---|---|
| bert-base-chinese | Fine-tune | 4k | 8 | 95% | 8ms | 不存在 | 线上主力候选 |
| PaddleNLP | Fine-tune | 4k | 8 | 94% | 18ms | 不存在 | 依实现而异 |
| Qwen3-0.6B-Instruct | LoRA-SFT(无提示词) | 4k | 8 | 76.4% | 135ms | 1.33% | 数据量不足导致部分意图出现幻觉 |
| Qwen3-0.6B-Instruct | 全参 SFT(无提示词) | 4k | 8 | 93.1% | 61ms | 0 | ------ |
| Qwen3-0.6B-Instruct | 全参 SFT(有提示词) | 4k | 8 | 92.8% | 90ms | 1/1440 | ------ |
结论:
- 性能敏感场景:优先选择 BERT/RoBERTa 等小模型分类器。
- SFT 优于 LoRA:在本数据规模下,全量 SFT 对小模型精度与稳定性提升更明显。
- 提示词使用:对经全量 SFT 的指令模型,在本任务格式下可不额外使用提示词,例如:
json
[
{"role": "user", "content": "[\"用户:有东西要修。\", \"客服:请问您要修的东西是什么?\", \"用户:三楼连廊上有个灯坏了。\""},
{"role": "assistant", "content": "区域报修"}
]- 数据敏感性:部分高频意图可达 97%+;一旦数据不足或分布不均,准确率显著下降。bert预计要达到最佳效果,至少需要 1-2 万高质量样本,并控制类间配比与噪声。
2.2、系统架构与流程
整体可以采用"规则前置 + 小模型主分类(1、2级分类) + 置信度分层处理 + 向量检索(3、4级分类) + LLM 澄清/兜底"的融合流水线:
2.3、一些实施细节
- 上下文策略:按意图簇配置不同的上下文窗口大小(如 N=3/5);
- 类不平衡:过采样长尾类、欠采样头部类;采用类权重或 Focal Loss;
- 阈值与拒识:对"其他/无意义/打招呼"设置动态阈值,低置信触发澄清或转人工,降低恶劣误判;
- 质控与监控:线上数据混淆矩阵、意图命中率、拒识率、转人工率、人工抽检准确率;
- A/B 与灰度:按渠道/入口放量,评估转人工率、异常挂断率、一次解决率与满意度。
三、数据标注及数据增广
高质量、覆盖全面且边界清晰的数据,是决定意图识别效果的关键因素。本章给出从"标注规范---上下文与噪声---数据增广---灰度指标"的工程化实践。
下图展示从数据准备到模型上线的完整闭环生命周期:
3.1、数据标注
3.1.1、准备工作
以智能客服系统 agent 的意图识别节点为例,首先基于咨询、投诉、报修等业务流程,梳理人机对话的标准话术和流程,并完成以下准备:
- 明确非业务类意图:会话终止、询问完成、无意义、打招呼、转人工等;
- 剔除非模型范畴:沉默控制、敏感词匹配、系统故障兜底、情绪识别等由独立模块处理;
- 定义上下文窗口策略,按话术阶段配置不同范围,示例;
- 初始阶段未识别咨询意图:近 2 轮上下文;
- 追问/确认阶段:近 4-5 轮上下文,避免遗漏初始 Query;
- 设计标签体系:主任务采用"层级化单标签"(一级/二级/三级);必要时引入"属性标签"(如噪声类型、是否含实体、新/老车型等)辅助分析,避免与主任务混淆;
- 明确标签定义与边界:为每一意图提供正负样例、相邻意图边界与冲突判定准则。
3.1.2、标注流程
- 预标注 + 人工复核:先由模型(小模型/大模型)预标注,后进行人工双盲标注+异常case复核,提高效率并降低偏置;
- 数据清洗:
- 去重与近重复折叠(相似度阈值/聚类);
- 剔除格式异常/无效文本;
- 大模型辅助清洗"脏数据"(无意义/噪声/越界问题等);
- 体系与粒度:
- 主任务为"单标签多类分类"(单轮选择一个主意图);
- 属性任务为辅助标签(噪声类型/是否含实体等),用于分析与采样;
- 多数据源融合:标准话术语料、人机对话、人人对话、小短语(口语化)、噪声样本、LLM 生成与改写;
- 覆盖与多样性:基于 embedding 簇类做分层抽样,控制问法多样化,提高长尾覆盖;
- 双盲与一致性:同一条样本两人独立标注,异常case第三方复核;定期评估一致性;
- Badcase 回流:
- 针对高频误判意图定向补标与过采样;
- 围绕混淆对构造近邻难例(边界/对抗式样本)。
分阶段标注建议:
- 初标:从线上抽取代表性样本标注;
- 二次标注:对低覆盖意图扩大时间窗并粗筛后标注;
- Badcase 回流:聚焦常见混淆意图补标与增广;
- 灰度上线后持续回流与复核。
示例(意图覆盖差异的标注提示):
- 公区维修:花园、楼宇、门庭、地库等场景的灯具、地面、公共设施、绿化等的维修;
- 业主放行:未上牌车辆放行、亲友临时访问放行等; 两类意图覆盖范围差异大,需分别确保各自场景的样本覆盖与多样性。
3.1.3、噪声与上下文处理
- 噪声类型:
- 用户口误、ASR 转写错误(如"闸机"->"炸鸡", "保安"->"报案");
- 环境噪音干扰(夹杂非语义片段/强噪声);
- 是否纳入训练:建议保留约 8%-10% 噪声样本以提升鲁棒性,并进行噪声类型标注;
- 上下文策略:
- 对"追问、咨询"等上下文敏感意图,使用较大窗口(3-5 轮);
- 对语义自足的咨询类场景(如"咨询物业缴费")适度缩小窗口以降低噪声引入;
- 对意图切换/多意图场景:选择主意图,辅以"需澄清/拒识"策略,避免误判。
3.1.4、质检与一致性保障
分布监控:基于 embedding 监控样本分布 与分类边界,避免极端不平衡;必要时重采样与配比校正。在这里采用embedding模型对语义进行聚类分析,仅做示例如下:
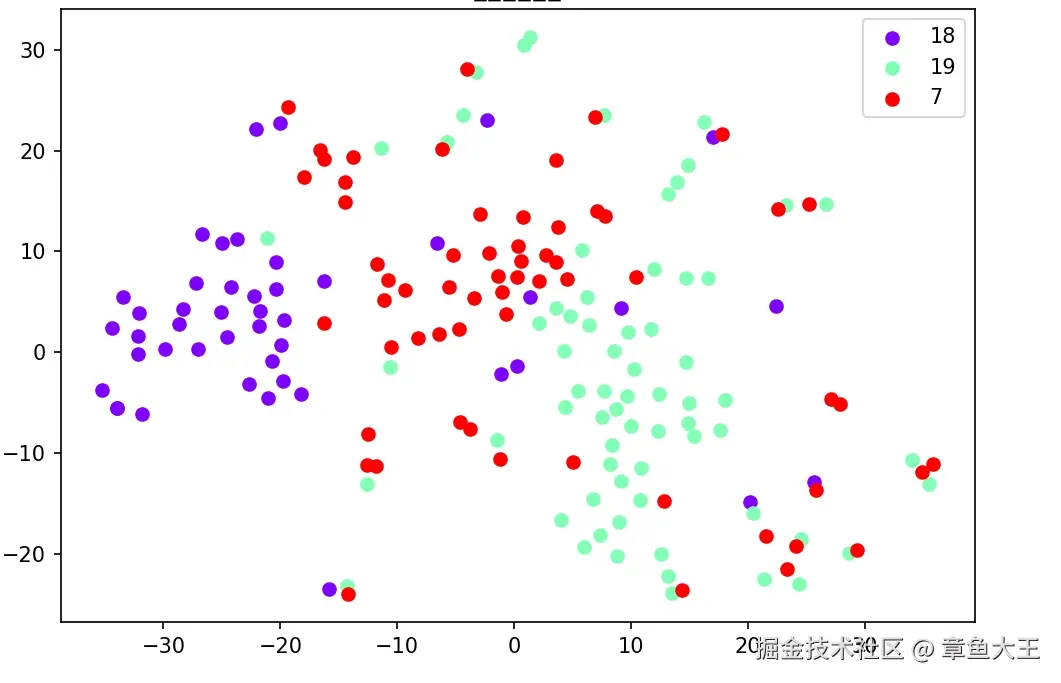
3.2、数据增广
3.2.1、人人对话与人机对话差异(冷启动)
许多智能客服从"人人对话"迁移而来。上线前需将人人对话转化为人机标准话术体系:
- 使用大模型改写人人对话为标准机器人话术;
- 将用户 Query 与标准话术组合构造多轮样本;
- 为每种话术模板生成口语化表达与实体变体,弥合"人人---人机"差异。
3.2.2、噪声增强
- 合成 ASR 错误:同音/近音替换、错别字、断词、丢标点;
- 环境噪声混叠:TTS 合成语音 + 背景噪声/混响后再 ASR;
- 标签策略:噪声样本可维持原意图或标注为"无意义/需澄清",按设计目标确定占比(此场景比例约 8%-10%)。
3.2.3、语义多样化与实体替换
- 同义改写、模板扩展、slot 替换(品牌/型号/地区/时间等);
- 边界样本构造:靠近混淆意图的句式,强化判别边界;
- 过采样与分层抽样:对长尾意图有节制过采样,结合聚类结果做多样化控制。
3.4、灰度策略与指标
- 放量策略:按渠道/入口/用户群体灰度;
- 指标口径:转人工率、异常挂断率、一次解决率、满意度、拒识率、人工复审命中率;
- 兜底与反馈:低置信度触发澄清或转人工;badcase 自动归集→去重→复审→重标→再训练的闭环。
4、实现与结果
4.1、代码实现
bert 训练代码
python
import numpy as np
from datasets import load_dataset, ClassLabel
from sklearn.metrics import f1_score, accuracy_score
from transformers import AutoModelForSequenceClassification
from transformers import AutoTokenizer
from transformers import Trainer, TrainingArguments
# 文件读取意图库
label_names = []
with open("./label.txt", "r", encoding="utf-8") as f:
lines = f.readlines()
for line in lines:
label_names.append(line.strip())
train_file = "./dataset/train.jsonl"
test_file = "./dataset/dev.jsonl"
model_id = "../bert-base-chinese"
# 加载数据集
def load_data():
# 创建 Dataset 对象
data_files = {"train": train_file, "test": test_file}
squad_it_dataset = load_dataset("json", data_files=data_files)
return squad_it_dataset
def train():
raw_dataset = load_data()
print(f"Train dataset size: {len(raw_dataset['train'])}")
print(f"Test dataset size: {len(raw_dataset['test'])}")
print(f"Label names len: {len(label_names)}")
# Load Tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.model_max_length = 512
# Tokenize dataset
raw_dataset = raw_dataset.rename_column("label", "labels") # to match Trainer
class_label = ClassLabel(names=label_names)
raw_dataset = raw_dataset.cast_column("labels", class_label)
# Tokenize the dataset
def tokenize(batch):
return tokenizer(batch['text'], padding='max_length', truncation=True, return_tensors="pt", max_length=512)
tokenized_dataset = raw_dataset.map(tokenize, batched=True, remove_columns=["text"])
print(tokenized_dataset["train"].features.keys())
# Prepare model labels - useful for inference
labels = tokenized_dataset["train"].features["labels"].names
num_labels = len(labels)
label2id, id2label = dict(), dict()
for i, label in enumerate(labels):
label2id[label] = str(i)
id2label[str(i)] = label
print(label2id, id2label)
# Download the model from huggingface.co/models
model = AutoModelForSequenceClassification.from_pretrained(
model_id, num_labels=num_labels, label2id=label2id, id2label=id2label
)
# Define training args
training_args = TrainingArguments(
output_dir="checkpoint",
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
gradient_accumulation_steps=2,
learning_rate=2e-5,
num_train_epochs=20,
bf16=False, # bfloat16 training
optim="adamw_torch_fused", # improved optimizer
# logging & evaluation strategies
logging_strategy="steps",
logging_steps=10,
eval_strategy="epoch",
save_strategy="epoch",
save_total_limit=2,
load_best_model_at_end=True,
label_smoothing_factor=0.1, # 标签平滑
metric_for_best_model="f1", # 基于f1指标选择最佳模型
lr_scheduler_type="cosine_with_restarts", # 使用余弦退火调度器
warmup_ratio=0.1, # 10% 的训练步数用于预热
weight_decay=0.01, # 增强正则化
max_grad_norm=1.0, # 添加梯度裁剪
)
# Create a Trainer instance
label_list = list(label2id.values())
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["test"],
compute_metrics=lambda pred: compute_metrics(pred, label_list),
)
trainer.train()
model.save_pretrained('./finetune_model')
tokenizer.save_pretrained('./finetune_model')
def compute_metrics(eval_pred, all_labels):
logits, true_labels = eval_pred
# 单次计算预测结果
pred_labels = np.argmax(logits, axis=1)
# 计算指标
f1 = f1_score(
true_labels,
pred_labels,
labels=all_labels, # 指定所有可能标签
average="weighted",
zero_division=0 # 处理未出现类别
)
accuracy = accuracy_score(true_labels, pred_labels)
return {
"f1": f1,
"accuracy": accuracy
}
if __name__ == "__main__":
train()bert 部署运行代码
python
import logging
import os
import time
from flask import Flask, jsonify
from flask import request
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
app = Flask(__name__)
app.json.ensure_ascii = False
model_name_or_path = os.getenv('MODEL_PATH')
# 加载模型
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = AutoModelForSequenceClassification.from_pretrained(
model_name_or_path, num_labels=29
)
model.to(device)
# 构造返回结构
def build_response(code, message, data):
response_data = {
'code': code,
'message': message,
'data': data
}
return jsonify(response_data)
@app.route('/text/intention/identify', methods=['POST'])
def text_intention_identify():
try:
get_data = request.get_json()
text = get_data.get('text')
res = get_result(text, top)
return build_response(0, "ok", res)
except Exception as e:
return build_response(-1, str(e), None)
# 获取模型识别结果
def get_result(text, top):
if len(text) > 512:
text = text[-512:]
test_encodings = tokenizer([text], truncation=True, padding=True, max_length=512, return_tensors="pt")
inputs = {key: value.to(device) for key, value in test_encodings.items()}
outputs = model(**inputs)
logits = outputs.logits
# 获取分数前top的标签
max_values, _ = torch.max(logits, dim=1, keepdim=True)
stable_logits = logits - max_values
probs = torch.softmax(stable_logits, dim=1)
topk_probs, topk_indices = torch.topk(probs, k=top, dim=1)
batch_probs = topk_probs.tolist()
batch_indices = topk_indices.tolist()
results = []
for sample_probs, sample_indices in zip(batch_probs, batch_indices):
sample_result = []
for prob, idx in zip(sample_probs, sample_indices):
sample_result.append({
"label": model.config.id2label[idx],
"score": prob
})
results.append(sample_result)
return results[0]
if __name__ == '__main__':
app.run(host='0.0.0.0', port=9001, threaded=True)4.2、结果
评测数据集(线上口径):
多轮对话 1.2w 条;上下文窗口 3 轮;平均输入 token ≈ 500;意图数 30 类。
为了留有进步空间,使用同一数据集,对大语言模型也同步进行微调->测试,得到综合结果如下:
| 模型 | 部署条件 | 平均响应时间 | 准确率 | 备注 |
|---|---|---|---|---|
| bert-base-chinese | 单卡(4090 24G)节点 * 2 | 并发:800 37ms 并发:1 16ms | 97.2%,关键场景99%+ | |
| qwen2.5-0.6b(sft、无提示词) | 双卡(4090 24G)节点 * 1 | 并发:1 61ms 并发:10 90ms | 90.1% | |
| qwen3-0.6b | - | 55ms | 90.8% | |
| qwen3-1.7b | - | 78ms | 94.2% | |
| qwen3-4b | - | 120ms | 94.8% |
有如下结论:
- bert模型在现有场景,准确率达到96-98%左右的准确率,重点场景98-99%高准确率;
- 大语言模型在1.7b尺寸在能够综合准确率及性能的要求获得较好的成果;
- 大语言模型在标注过程中,随着数据集质量和数量的提高,持续提高准确率,因此,在标注数据集逐渐补充完备后,可以考虑使用大语言模型替换掉bert模型。