1. 概述
使用 Gemini 结合 Python 脚本从多份表中提取所需数据更新到对应表中。
2. 准备
将所有数据汇总到的 data.xlsx 文件,其中 Sheet0 是待处理的表,其余表为更新数据源。
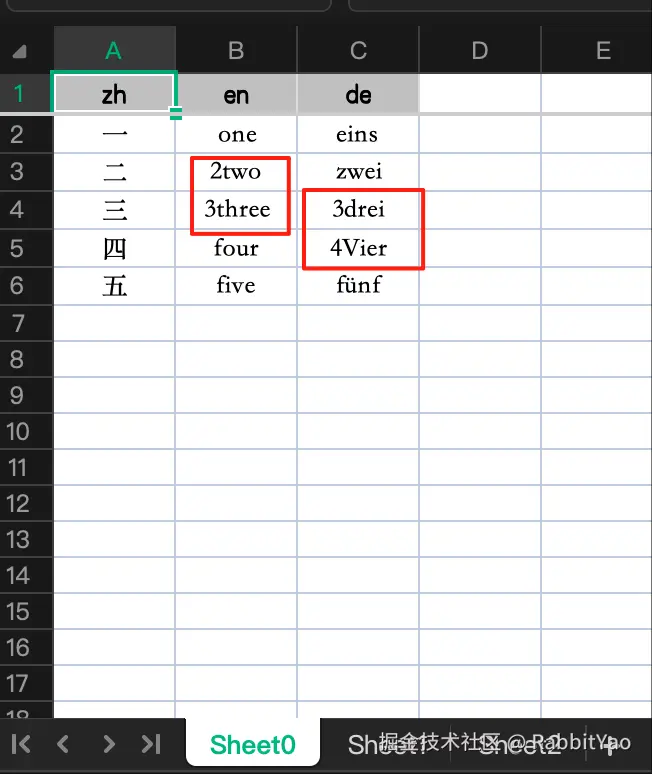

Sheet0、Sheet1 中 标红位置 为待更新 错误数据。

Sheet2 中包含剩余正确数据。
3. 向 Gemini 提问
提问内容:
使用 Python 找出 除了 Sheet0 之外其他所有 Sheet 中 zh 列 中完全相同的字符串的项,最新相同项所在行的的其他列项数据与 Sheet0 中对应列名列项数据比对,不相同的项则直接覆盖 Sheet0 中对应项,更新过的项背景标记为黄色
得到的回答:
python
import openpyxl
from openpyxl.styles import PatternFill
import os
def sync_excel_data(file_path):
file_dir, file_name = os.path.split(file_path)
file_base, file_ext = os.path.splitext(file_name)
# 保存更新后的 DataFrame 到新文件(或覆盖原文件)
output_file_path = os.path.join(file_dir, f"{file_base}_updated{file_ext}")
"""
同步 Excel 工作表数据到 Sheet0。
参数:
output_file_path (str): Excel 文件的路径。
"""
try:
workbook = openpyxl.load_workbook(file_path)
except FileNotFoundError:
print(f"错误:找不到文件 {file_path}")
return
# 设置黄色填充样式
yellow_fill = PatternFill(start_color="FFFF00", end_color="FFFF00", fill_type="solid")
# 获取 Sheet0
if 'Sheet0' not in workbook.sheetnames:
print("错误:文件中不存在名为 'Sheet0' 的工作表。")
return
sheet0 = workbook['Sheet0']
# 创建一个字典来存储 Sheet0 的数据,以便快速查找
sheet0_data = {}
header = [cell.value for cell in sheet0[1]] # 假设第一行是表头
try:
zh_col_index = header.index('zh')
except ValueError:
print("错误:'Sheet0' 中没有 'zh' 列。")
return
for row in sheet0.iter_rows(min_row=2):
zh_value = row[zh_col_index].value
if zh_value is not None:
sheet0_data[zh_value] = [cell for cell in row]
# 累计更新单元格个数
updated_count = 0
# 遍历除 Sheet0 以外的所有工作表
for sheet_name in workbook.sheetnames:
if sheet_name == 'Sheet0':
continue
print(f"正在同步工作表:{sheet_name}...")
current_sheet = workbook[sheet_name]
# 获取当前工作表的 'zh' 列索引
try:
current_header = [cell.value for cell in current_sheet[1]]
current_zh_col_index = current_header.index('zh')
except ValueError:
print(f"警告:工作表 '{sheet_name}' 中没有 'zh' 列,跳过。")
continue
# 遍历当前工作表的数据行
for row in current_sheet.iter_rows(min_row=2):
zh_value_to_match = row[current_zh_col_index].value
if zh_value_to_match in sheet0_data:
sheet0_row = sheet0_data[zh_value_to_match]
# 遍历所有列,比对并同步数据
for col_index, sheet0_cell in enumerate(sheet0_row):
# 确保索引在当前行范围内
if col_index < len(row):
current_sheet_cell = row[col_index]
# 忽略 'zh' 列,只比对其他列
if current_header[col_index] != 'zh' and sheet0_cell.value != current_sheet_cell.value:
last_value = sheet0_cell.value
sheet0_cell.value = current_sheet_cell.value
sheet0_cell.fill = yellow_fill
updated_count += 1
print(f"更新单元格 {last_value} -> {current_sheet_cell.value}")
# 保存更改
try:
workbook.save(output_file_path)
print(f"数据更新完成,共更新了 {updated_count} 个单元格,新文件已保存为:{output_file_path} ")
except Exception as e:
print(f"错误:保存文件时出错 - {e}")
# 示例调用
if __name__ == '__main__':
# 替换 'data.xlsx' 为您的文件路径
input_path = 'data.xlsx'
sync_excel_data(input_path)优化提问:
优化上面的提问文案
得到的回答:
方案一:简洁明了型
使用 Python 找出并更新 Excel 文件中重复的数据。
具体需求:
- 在 Sheet0 之外的所有工作表中,找到与 Sheet0 中 "zh" 列完全相同的项。
- 将最新找到的相同项所在行的其他列数据,与 Sheet0 中对应的数据进行比对。
- 如果数据不一致,则用最新的数据覆盖 Sheet0 中的旧数据。
- 将所有更新过的单元格背景标记为黄色。
方案二:项目需求型
项目目标:Python 脚本自动同步 Excel 工作表数据。
需求详情:
- 数据比对 :遍历 Excel 文件中除 Sheet0 以外的所有工作表。
- 匹配条件 :以 "zh" 列作为唯一标识,找到与 Sheet0 中完全匹配的行。
- 内容同步 :如果匹配行的其他列数据与 Sheet0 不符,则覆盖 Sheet0 中的数据。
- 可视化标记:自动将所有被更新的单元格填充为黄色,以便识别。
方案三:更口语化、直接型
帮我用 Python 写个脚本,来整理我的 Excel 表。
我想让它做三件事:
- 先看 Sheet0,然后去检查其他所有表格。
- 只要在其他表格里找到 "zh" 列和 Sheet0 里一模一样的项,就把那一行的数据拿过来。
- 对比一下,如果其他列的数据不一样,就用新数据把 Sheet0 里的旧数据换掉,并且把改过的地方涂成黄色。
4. 使用 Python 执行脚本
得到输出文件 data_updated.xlsx
