背景意义
研究背景与意义
随着全球对森林资源的依赖日益加深,森林砍伐问题愈发凸显,成为生态环境保护和可持续发展面临的重要挑战之一。森林不仅是地球生态系统的重要组成部分,还是生物多样性保护的关键所在。森林的消失不仅导致了栖息地的破坏,还加剧了气候变化,影响了水循环和土壤质量。因此,及时、准确地监测森林砍伐情况,对于制定有效的环境保护政策和管理措施至关重要。
近年来,遥感技术的快速发展为森林监测提供了新的解决方案。通过卫星影像和无人机图像等遥感数据,研究人员能够获取大范围的森林覆盖信息。然而,传统的人工监测方法不仅耗时耗力,而且难以应对大规模数据的处理需求。因此,基于深度学习的自动化检测系统应运而生,成为提高森林砍伐监测效率的重要工具。
在众多深度学习模型中,YOLO(You Only Look Once)系列因其高效的实时目标检测能力而受到广泛关注。YOLOv11作为该系列的最新版本,具备更强的特征提取和分类能力,能够在复杂的自然环境中实现高精度的目标检测。通过对YOLOv11进行改进,我们可以更好地适应遥感图像的特点,提高对森林砍伐和森林区域的检测精度。
本研究将基于改进的YOLOv11模型,构建一个高效的遥感森林砍伐检测系统。我们将利用包含4400幅图像的Defo_forest数据集,该数据集专门针对森林砍伐和森林区域进行了标注,涵盖了两类重要的生态信息。通过对该数据集的深入分析和模型训练,我们期望能够显著提升森林砍伐的检测准确率,为相关决策提供科学依据,推动生态环境保护的可持续发展。
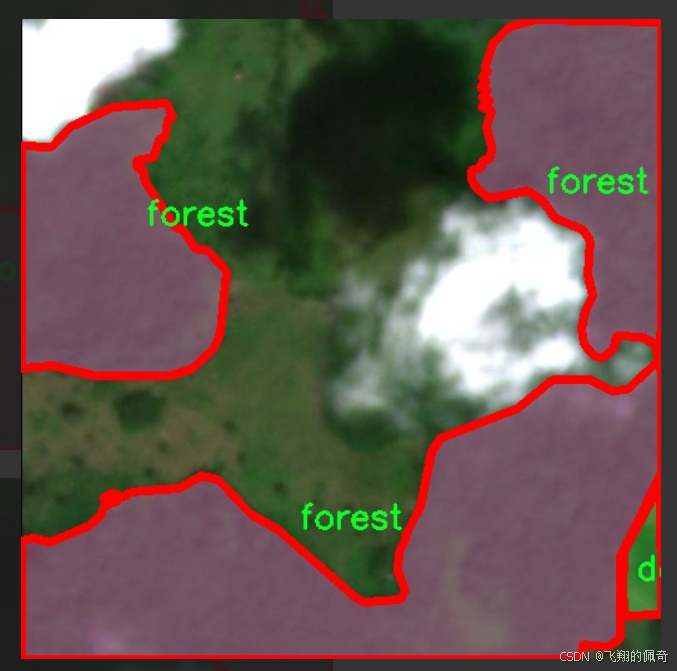
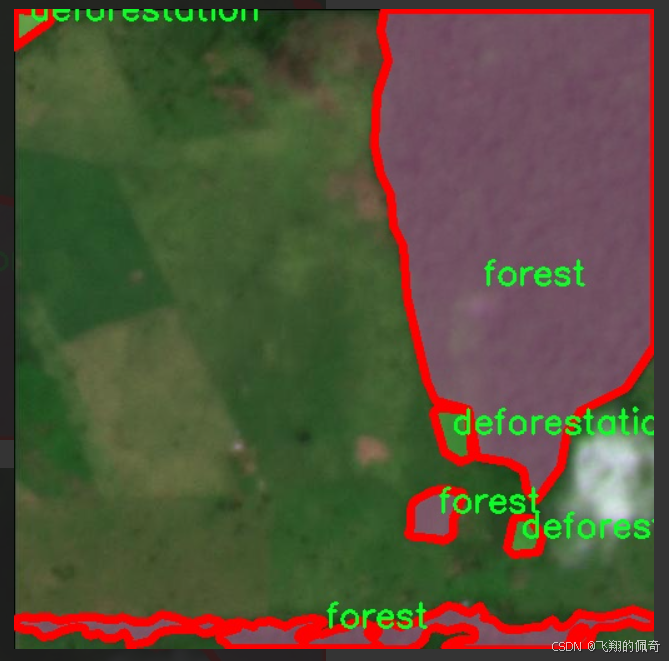
图片效果
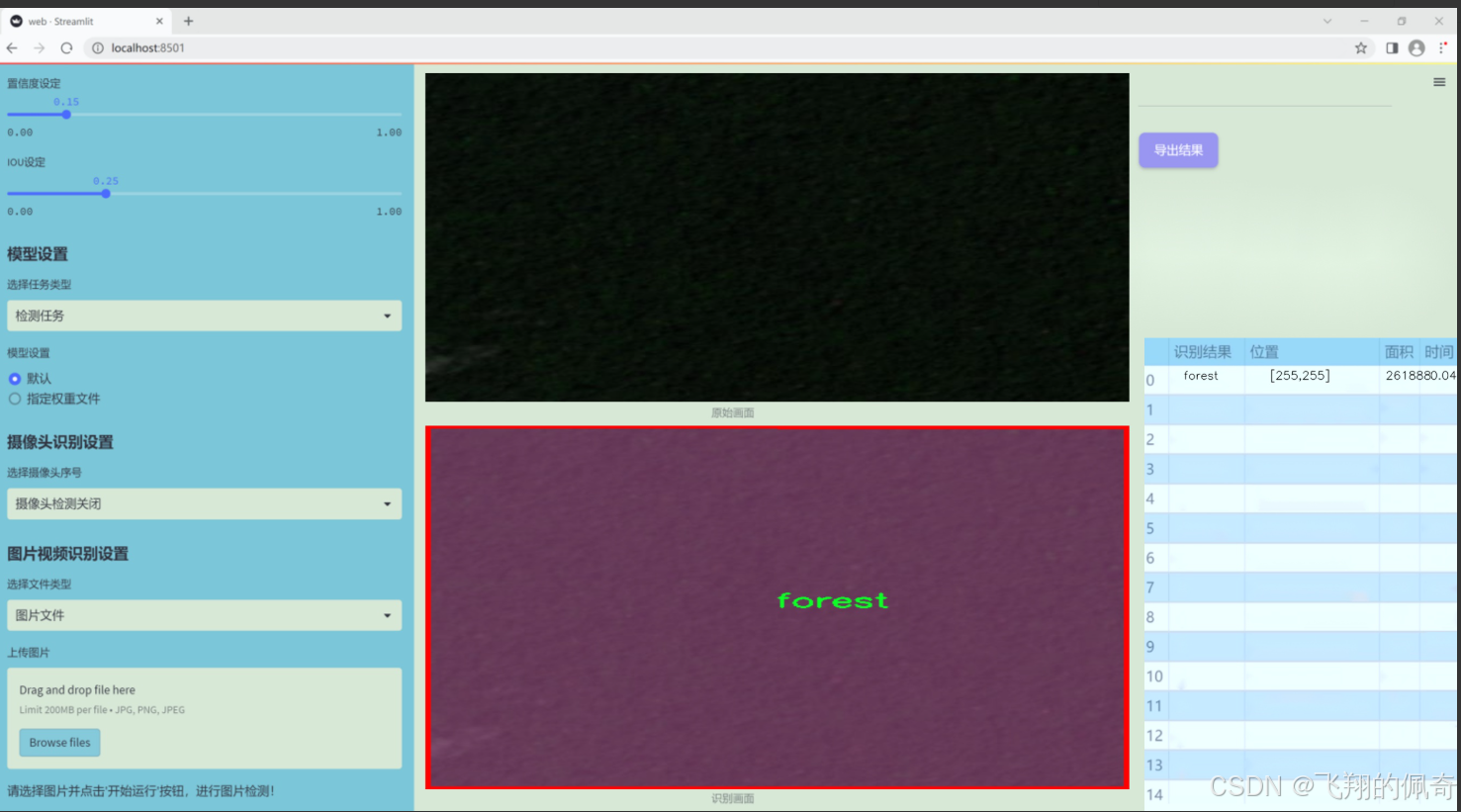
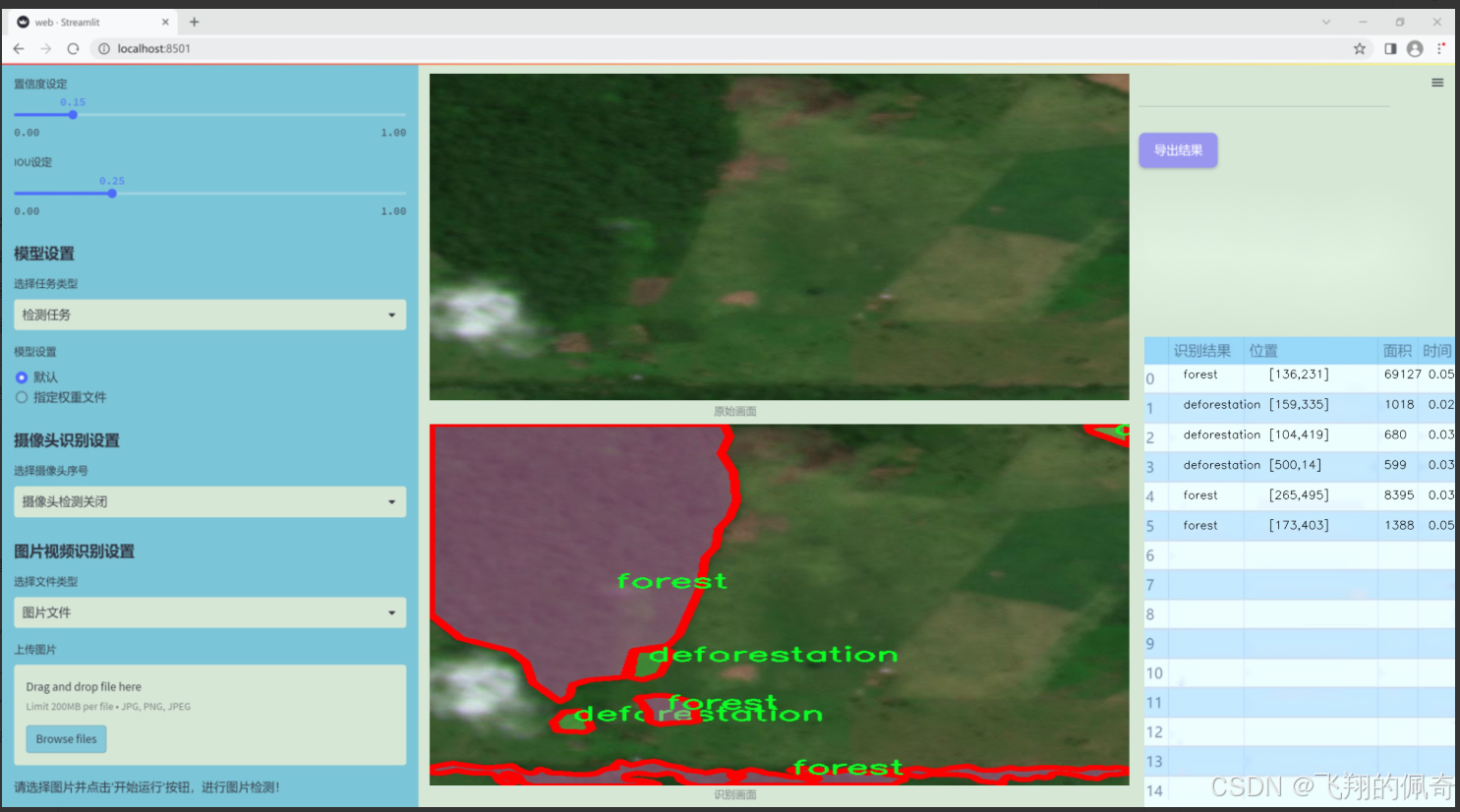
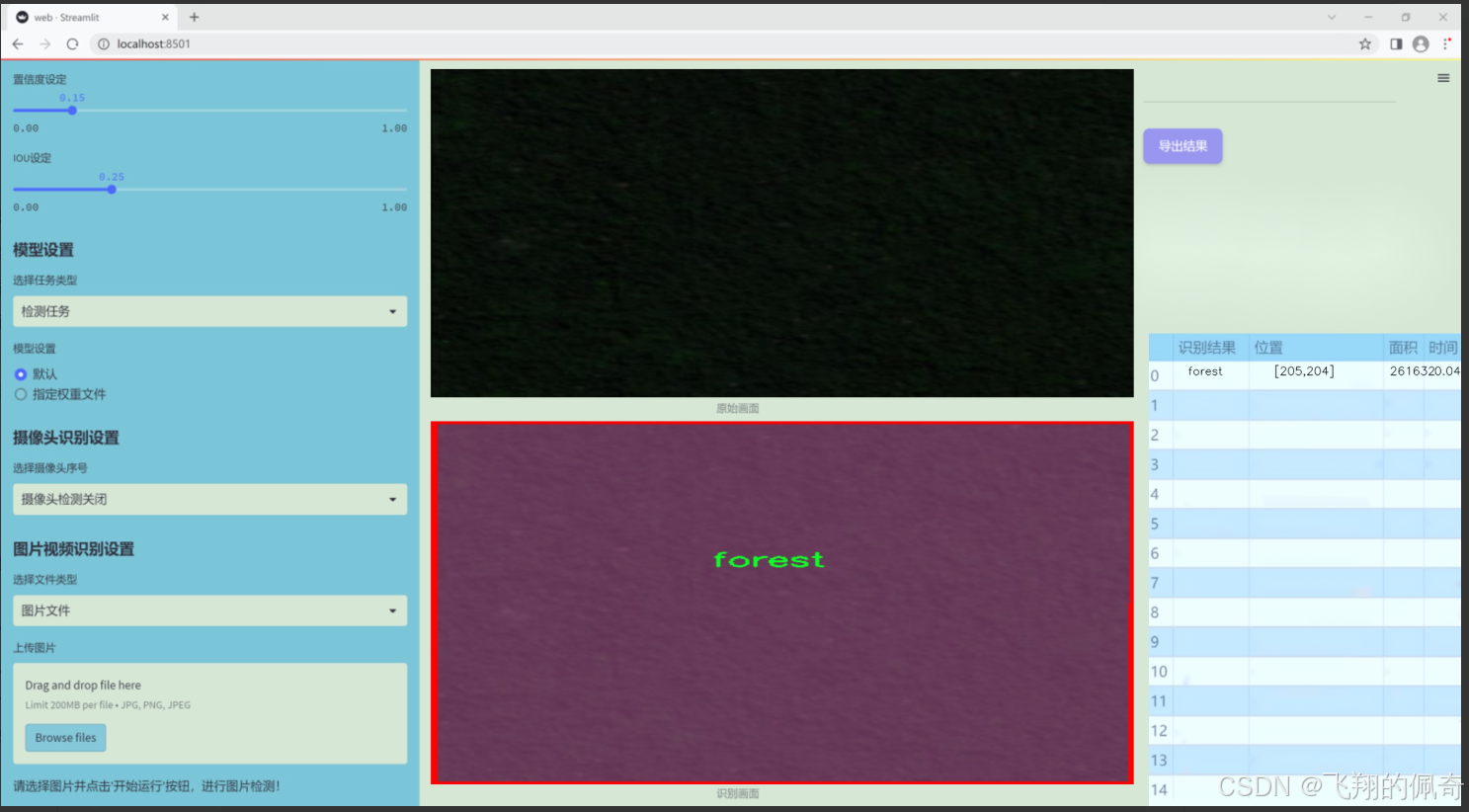
数据集信息
本项目数据集信息介绍
本项目所使用的数据集名为"Defo_forest",旨在为改进YOLOv11的遥感森林砍伐检测系统提供高质量的训练数据。该数据集专注于遥感影像中的森林砍伐现象,包含两大主要类别:砍伐(deforestation)和森林(forest)。通过对这两类的精确标注,数据集为模型的训练提供了清晰的目标,使其能够有效地区分被砍伐的区域与健康的森林覆盖。
在数据集的构建过程中,研究团队收集了来自不同地理区域的遥感影像,确保数据的多样性和代表性。这些影像涵盖了不同季节、不同气候条件下的森林景观,旨在增强模型的泛化能力。每幅影像经过精细的标注,确保每个像素的分类准确无误,从而为YOLOv11的训练提供了坚实的基础。
数据集的设计不仅关注于图像的数量,还特别注重图像的质量和多样性。为了确保模型能够适应不同的环境变化,数据集中包含了多种不同类型的森林生态系统,如热带雨林、温带森林和针叶林等。这种多样性使得模型在面对不同类型的森林砍伐时,能够展现出更强的适应性和准确性。
此外,数据集还包含了多种标注信息,例如砍伐的面积、砍伐的时间段等,这些信息将有助于深入分析森林砍伐的动态变化,进而为相关政策的制定提供数据支持。通过对"Defo_forest"数据集的深入挖掘与分析,本项目希望能够推动遥感技术在森林保护与管理中的应用,为实现可持续发展目标贡献力量。
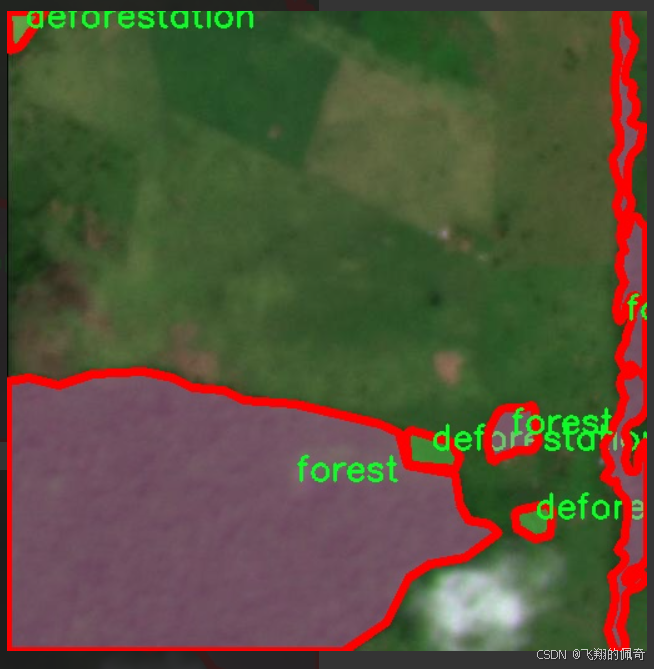


核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
from einops import rearrange
class LayerNorm2d(nn.Module):
"""二维层归一化类"""
def init (self, normalized_shape, eps=1e-6, elementwise_affine=True):
super().init ()
初始化LayerNorm,normalized_shape为需要归一化的形状
self.norm = nn.LayerNorm(normalized_shape, eps, elementwise_affine)
def forward(self, x):
# 将输入x的形状从 (B, C, H, W) 转换为 (B, H, W, C)
x = rearrange(x, 'b c h w -> b h w c').contiguous()
# 对转换后的张量进行归一化
x = self.norm(x)
# 将归一化后的张量形状转换回 (B, C, H, W)
x = rearrange(x, 'b h w c -> b c h w').contiguous()
return xclass CrossScan(torch.autograd.Function):
"""交叉扫描操作"""
@staticmethod
def forward(ctx, x: torch.Tensor):
B, C, H, W = x.shape
ctx.shape = (B, C, H, W)
创建一个新的张量,用于存储交叉扫描的结果
xs = x.new_empty((B, 4, C, H * W))
xs:, 0 = x.flatten(2, 3) # 原始顺序
xs:, 1 = x.transpose(dim0=2, dim1=3).flatten(2, 3) # 旋转90度
xs:, 2:4 = torch.flip(xs:, 0:2, dims=-1) # 反转
return xs
@staticmethod
def backward(ctx, ys: torch.Tensor):
B, C, H, W = ctx.shape
L = H * W
# 反向传播计算
ys = ys[:, 0:2] + ys[:, 2:4].flip(dims=[-1]).view(B, 2, -1, L)
y = ys[:, 0] + ys[:, 1].view(B, -1, W, H).transpose(dim0=2, dim1=3).contiguous().view(B, -1, L)
return y.view(B, -1, H, W)class SelectiveScanCore(torch.autograd.Function):
"""选择性扫描核心操作"""
@staticmethod
@torch.cuda.amp.custom_fwd
def forward(ctx, u, delta, A, B, C, D=None, delta_bias=None, delta_softplus=False, nrows=1, backnrows=1, oflex=True):
确保输入张量是连续的
if u.stride(-1) != 1:
u = u.contiguous()
if delta.stride(-1) != 1:
delta = delta.contiguous()
if D is not None and D.stride(-1) != 1:
D = D.contiguous()
if B.stride(-1) != 1:
B = B.contiguous()
if C.stride(-1) != 1:
C = C.contiguous()
# 处理输入维度
if B.dim() == 3:
B = B.unsqueeze(dim=1)
ctx.squeeze_B = True
if C.dim() == 3:
C = C.unsqueeze(dim=1)
ctx.squeeze_C = True
ctx.delta_softplus = delta_softplus
ctx.backnrows = backnrows
# 调用CUDA核心的前向函数
out, x, *rest = selective_scan_cuda_core.fwd(u, delta, A, B, C, D, delta_bias, delta_softplus, 1)
ctx.save_for_backward(u, delta, A, B, C, D, delta_bias, x)
return out
@staticmethod
@torch.cuda.amp.custom_bwd
def backward(ctx, dout, *args):
u, delta, A, B, C, D, delta_bias, x = ctx.saved_tensors
if dout.stride(-1) != 1:
dout = dout.contiguous()
# 调用CUDA核心的反向函数
du, ddelta, dA, dB, dC, dD, ddelta_bias, *rest = selective_scan_cuda_core.bwd(
u, delta, A, B, C, D, delta_bias, dout, x, ctx.delta_softplus, 1
)
return (du, ddelta, dA, dB, dC, dD, ddelta_bias, None, None, None, None)def cross_selective_scan(
x: torch.Tensor,
x_proj_weight: torch.Tensor,
dt_projs_weight: torch.Tensor,
A_logs: torch.Tensor,
Ds: torch.Tensor,
out_norm: torch.nn.Module,
nrows=-1,
backnrows=-1,
delta_softplus=True,
to_dtype=True,
force_fp32=False,
ssoflex=True,
):
"""交叉选择性扫描操作"""
B, D, H, W = x.shape
D, N = A_logs.shape
K, D, R = dt_projs_weight.shape
L = H * W
# 交叉扫描
xs = CrossScan.apply(x)
# 计算双重投影
x_dbl = torch.einsum("b k d l, k c d -> b k c l", xs, x_proj_weight)
dts, Bs, Cs = torch.split(x_dbl, [R, N, N], dim=2)
dts = torch.einsum("b k r l, k d r -> b k d l", dts, dt_projs_weight)
# HiPPO矩阵
As = -torch.exp(A_logs.to(torch.float)) # 计算A的值
Bs = Bs.contiguous()
Cs = Cs.contiguous()
Ds = Ds.to(torch.float) # 将Ds转换为浮点数
delta_bias = dt_projs_bias.view(-1).to(torch.float)
# 选择性扫描
ys: torch.Tensor = SelectiveScan.apply(
xs, dts, As, Bs, Cs, Ds, delta_bias, delta_softplus
).view(B, K, -1, H, W)
# 合并结果
y: torch.Tensor = CrossMerge.apply(ys)
# 归一化输出
y = out_norm(y).view(B, H, W, -1)
return (y.to(x.dtype) if to_dtype else y)class SS2D(nn.Module):
"""SS2D模块"""
def init (self, d_model=96, d_state=16, ssm_ratio=2.0, act_layer=nn.SiLU, dropout=0.0):
super().init ()
self.in_proj = nn.Conv2d(d_model, d_model * ssm_ratio, kernel_size=1)
self.act = act_layer()
self.out_proj = nn.Conv2d(d_model * ssm_ratio, d_model, kernel_size=1)
self.dropout = nn.Dropout(dropout)
def forward(self, x: torch.Tensor):
x = self.in_proj(x)
x = self.act(x)
x = self.dropout(x)
x = self.out_proj(x)
return xclass VSSBlock_YOLO(nn.Module):
"""VSSBlock_YOLO模块"""
def init (self, in_channels: int, hidden_dim: int, drop_path: float):
super().init ()
self.proj_conv = nn.Conv2d(in_channels, hidden_dim, kernel_size=1)
self.ss2d = SS2D(d_model=hidden_dim)
self.drop_path = DropPath(drop_path)
def forward(self, input: torch.Tensor):
input = self.proj_conv(input)
x = self.ss2d(input)
x = input + self.drop_path(x) # 残差连接
return x代码核心部分说明:
LayerNorm2d: 实现了二维层归一化,用于对图像数据进行归一化处理。
CrossScan: 实现了交叉扫描操作,生成不同方向的特征图,方便后续处理。
SelectiveScanCore: 实现了选择性扫描的前向和反向传播逻辑,核心用于处理输入数据的选择性扫描。
cross_selective_scan: 结合了交叉扫描和选择性扫描的操作,处理输入数据并进行投影。
SS2D: 实现了一个简单的SSM(状态空间模型)模块,包含输入投影、激活函数和输出投影。
VSSBlock_YOLO: 组合了输入投影、SSM模块和残差连接,形成YOLO模型中的一个重要模块。
这些核心部分共同构成了一个用于视觉任务的深度学习模型,利用状态空间模型和选择性扫描等技术来提高模型的性能。
这个程序文件 mamba_yolo.py 是一个实现了 YOLO(You Only Look Once)目标检测模型的 PyTorch 代码。文件中定义了多个类和函数,主要用于构建和训练深度学习模型,特别是涉及到视觉任务的模型。以下是对代码的详细讲解。
首先,文件导入了一些必要的库,包括 torch 和 torch.nn,以及一些用于张量操作的工具,如 einops 和 timm。这些库提供了深度学习所需的基本功能。
接下来,定义了一个 LayerNorm2d 类,继承自 nn.Module,用于实现二维层归一化。该类在 forward 方法中对输入张量进行维度重排,以适应 LayerNorm 的输入格式。
autopad 函数用于自动计算卷积操作的填充,以确保输出与输入具有相同的空间维度。它根据给定的卷积核大小和膨胀因子计算所需的填充。
接下来的几个类 CrossScan、CrossMerge 和 SelectiveScanCore 实现了交叉扫描和选择性扫描的功能。这些功能主要用于处理输入特征图,以便在模型中进行更高效的特征提取和信息融合。CrossScan 类负责将输入张量的不同维度进行组合,而 CrossMerge 则用于将处理后的张量合并回原始形状。SelectiveScanCore 则实现了选择性扫描的前向和反向传播,主要用于加速模型的训练过程。
cross_selective_scan 函数是一个封装函数,整合了选择性扫描的各个部分,处理输入特征图并应用相关的权重和偏置。它还支持不同的归一化操作,以便在模型的不同阶段进行特征标准化。
SS2D 类是一个核心模块,结合了选择性扫描和卷积操作。它的构造函数定义了输入和输出的维度、卷积核大小、激活函数等参数。forward 方法实现了数据的前向传播,包括输入的投影、卷积操作和选择性扫描。
RGBlock 和 LSBlock 类分别实现了残差连接和局部自适应归一化的功能。这些模块用于构建更复杂的网络结构,增强模型的表达能力。
XSSBlock 和 VSSBlock_YOLO 类则是更高级的模块,结合了前面定义的所有功能。它们在构造函数中定义了多个子模块,并在 forward 方法中实现了复杂的前向传播逻辑。
SimpleStem 类用于模型的初始特征提取,定义了一个简单的卷积网络结构。VisionClueMerge 类则实现了特征图的合并操作,通常用于多尺度特征融合。
整体来看,这个文件实现了一个复杂的深度学习模型,结合了选择性扫描、卷积操作和多种归一化技术,旨在提高目标检测任务的性能。代码结构清晰,模块化设计使得各个部分易于理解和维护。
10.4 SMPConv.py
以下是经过简化和注释的核心代码部分,主要包括 SMPConv、SMPCNN、SMPCNN_ConvFFN 和 SMPBlock 类的实现。注释详细解释了每个部分的功能和逻辑。
import torch
import torch.nn as nn
import torch.nn.functional as F
定义一个相对位置的函数,生成相对坐标
def rel_pos(kernel_size):
tensors = torch.linspace(-1, 1, steps=kernel_size) for _ in range(2)
kernel_coord = torch.stack(torch.meshgrid(*tensors), dim=-0) # 生成网格坐标
kernel_coord = kernel_coord.unsqueeze(0) # 增加一个维度
return kernel_coord
定义自定义卷积层
class SMPConv(nn.Module):
def init (self, planes, kernel_size, n_points, stride, padding, groups):
super().init ()
self.planes = planes
self.kernel_size = kernel_size
self.n_points = n_points
self.init_radius = 2 * (2/kernel_size) # 初始化半径
# 生成相对位置坐标
kernel_coord = rel_pos(kernel_size)
self.register_buffer('kernel_coord', kernel_coord) # 注册为缓冲区
# 权重坐标初始化
weight_coord = torch.empty(1, n_points, 2)
nn.init.trunc_normal_(weight_coord, std=0.2, a=-1., b=1.)
self.weight_coord = nn.Parameter(weight_coord)
# 半径参数初始化
self.radius = nn.Parameter(torch.empty(1, n_points).unsqueeze(-1).unsqueeze(-1))
self.radius.data.fill_(value=self.init_radius)
# 权重初始化
weights = torch.empty(1, planes, n_points)
nn.init.trunc_normal_(weights, std=.02)
self.weights = nn.Parameter(weights)
def forward(self, x):
kernels = self.make_kernels().unsqueeze(1) # 生成卷积核
x = x.contiguous()
kernels = kernels.contiguous()
# 根据输入数据类型选择合适的卷积实现
if x.dtype == torch.float32:
x = _DepthWiseConv2dImplicitGEMMFP32.apply(x, kernels)
elif x.dtype == torch.float16:
x = _DepthWiseConv2dImplicitGEMMFP16.apply(x, kernels)
else:
raise TypeError("Only support fp32 and fp16, get {}".format(x.dtype))
return x
def make_kernels(self):
# 计算卷积核
diff = self.weight_coord.unsqueeze(-2) - self.kernel_coord.reshape(1, 2, -1).transpose(1, 2) # 计算差值
diff = diff.transpose(2, 3).reshape(1, self.n_points, 2, self.kernel_size, self.kernel_size)
diff = F.relu(1 - torch.sum(torch.abs(diff), dim=2) / self.radius) # 计算加权差值
# 生成卷积核
kernels = torch.matmul(self.weights, diff.reshape(1, self.n_points, -1)) # 计算卷积核
kernels = kernels.reshape(1, self.planes, *self.kernel_coord.shape[2:]) # 调整形状
kernels = kernels.squeeze(0)
kernels = torch.flip(kernels.permute(0, 2, 1), dims=(1,)) # 翻转卷积核
return kernels定义一个简单的卷积块
class SMPCNN(nn.Module):
def init (self, in_channels, out_channels, kernel_size, stride, groups, n_points=None):
super().init ()
padding = kernel_size // 2
self.smp = SMPConv(in_channels, kernel_size, n_points, stride, padding, groups) # 使用自定义卷积
self.small_conv = nn.Conv2d(in_channels, out_channels, kernel_size=5, stride=stride, padding=2, groups=groups) # 小卷积
def forward(self, inputs):
out = self.smp(inputs) # 通过自定义卷积
out += self.small_conv(inputs) # 加上小卷积的输出
return out定义卷积前馈网络
class SMPCNN_ConvFFN(nn.Module):
def init (self, in_channels, internal_channels, out_channels, drop_path):
super().init ()
self.drop_path = nn.Identity() if drop_path <= 0 else nn.Dropout(drop_path) # 跳过路径
self.pw1 = nn.Conv2d(in_channels, internal_channels, kernel_size=1) # 1x1卷积
self.pw2 = nn.Conv2d(internal_channels, out_channels, kernel_size=1) # 1x1卷积
self.nonlinear = nn.GELU() # 激活函数
def forward(self, x):
out = self.pw1(x) # 通过第一个卷积
out = self.nonlinear(out) # 激活
out = self.pw2(out) # 通过第二个卷积
return x + self.drop_path(out) # 残差连接定义SMPBlock
class SMPBlock(nn.Module):
def init (self, in_channels, dw_channels, lk_size, drop_path, n_points=None):
super().init ()
self.pw1 = nn.Sequential(nn.Conv2d(in_channels, dw_channels, kernel_size=1), nn.ReLU()) # 1x1卷积 + ReLU
self.pw2 = nn.Conv2d(dw_channels, in_channels, kernel_size=1) # 1x1卷积
self.large_kernel = SMPCNN(in_channels=dw_channels, out_channels=dw_channels, kernel_size=lk_size, stride=1, groups=dw_channels, n_points=n_points) # 大卷积
self.drop_path = nn.Identity() if drop_path <= 0 else nn.Dropout(drop_path) # 跳过路径
def forward(self, x):
out = self.pw1(x) # 通过第一个卷积
out = self.large_kernel(out) # 通过大卷积
out = self.pw2(out) # 通过第二个卷积
return x + self.drop_path(out) # 残差连接代码说明:
SMPConv:自定义卷积层,使用相对位置编码和动态卷积核生成。支持 FP32 和 FP16 数据类型。
SMPCNN:结合自定义卷积和小卷积的网络结构。
SMPCNN_ConvFFN:前馈网络,包含两个 1x1 卷积和一个激活函数,支持残差连接。
SMPBlock:包含多个卷积层和跳过路径的块,使用大卷积和小卷积组合。
该代码主要用于构建一种新型的卷积神经网络,利用动态卷积核和残差连接来提高模型的表达能力。
这个程序文件 SMPConv.py 实现了一种特殊的卷积神经网络模块,主要包含了几个重要的类和函数,旨在通过改进的卷积操作来提升网络的性能。
首先,文件导入了必要的库,包括 PyTorch 和一些自定义模块。特别是,文件尝试导入 depthwise_conv2d_implicit_gemm 中的两个类,这些类用于高效的深度可分离卷积实现。
rel_pos 函数用于生成相对位置的坐标张量,基于给定的卷积核大小。这些坐标在后续的卷积操作中会被用到。
SMPConv 类是文件的核心部分,继承自 nn.Module。在初始化方法中,它接收多个参数,如输出通道数、卷积核大小、点数、步幅、填充和分组数。它计算并注册了卷积核的坐标,并初始化了权重坐标和半径参数。forward 方法中,输入数据经过 make_kernels 方法生成的动态卷积核进行卷积操作,支持 FP32 和 FP16 数据类型。
make_kernels 方法负责根据权重坐标和卷积核坐标计算出实际的卷积核。它通过计算坐标之间的差异并应用 ReLU 激活函数来生成最终的卷积核。
radius_clip 方法用于限制半径的范围,确保其在一个合理的区间内。
接下来,get_conv2d 函数根据输入参数决定返回自定义的 SMPConv 或标准的 nn.Conv2d。如果满足特定条件,则使用 SMPConv,否则使用常规卷积。
enable_sync_bn 和 get_bn 函数用于控制和获取批归一化层,支持同步批归一化。
conv_bn 和 conv_bn_relu 函数用于构建包含卷积层和批归一化层的序列模型,并可选择性地添加 ReLU 激活函数。
fuse_bn 函数用于将卷积层和批归一化层融合,以优化模型的推理速度。
SMPCNN 类是一个组合卷积模块,结合了 SMPConv 和一个小卷积层。它在前向传播中将两者的输出相加,以增强特征提取能力。
SMPCNN_ConvFFN 类实现了一个前馈网络,包含两个逐点卷积层和一个 GELU 激活函数。它使用 DropPath 技术来实现随机丢弃路径,以增强模型的泛化能力。
最后,SMPBlock 类结合了逐点卷积和大卷积核的特性,构成了一个完整的模块,适用于更复杂的网络结构。它通过前向传播将输入经过一系列卷积和激活操作后,与原始输入相加,形成残差连接。
总体而言,这个文件实现了一种灵活且高效的卷积模块,适用于深度学习中的各种任务,尤其是在图像处理和计算机视觉领域。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论 啦 、查看👇🏻获取联系方式