背景
当前我的im聊天系统的消息是存到mysql里的,虽然我做了分库分表:  但是本质上这么做是很low的,也并不能满足百万并发的设计目标。so 、调研了半天,我准备使用hbase 做消息存储,本文不介绍hbase是啥,只是单纯记录hadoop、hbase的安装过程。以作备忘。
但是本质上这么做是很low的,也并不能满足百万并发的设计目标。so 、调研了半天,我准备使用hbase 做消息存储,本文不介绍hbase是啥,只是单纯记录hadoop、hbase的安装过程。以作备忘。
一、安装前准备工作
注意: 由于hbase运行依赖hadoop集群中的hdfs分布式文件系统,所以 **先搭建hadoop的hdfs集群** 至于hadoop其他的组件 yarn MapReduce 这些暂时没用到 暂不关注。
我准备在三台centos7上安装hadoop的hdfs集群和hbase集群:
makefile
192.168.1.130(hostName: hadoop01) 主
192.168.1.131(hostName: hadoop02) 从
192.168.1.132(hostName: hadoop03) 从版本信息:
- Hadoop:TLS版本 3.3.5 (记录的是hadoop3.3.6的安装过程,后来铲了装的3.3.5)
- HBase: TLS版本2.6.1 hbass英文官网:hbase.apache.org/book.html#_...
hbase版本和jdk关系: 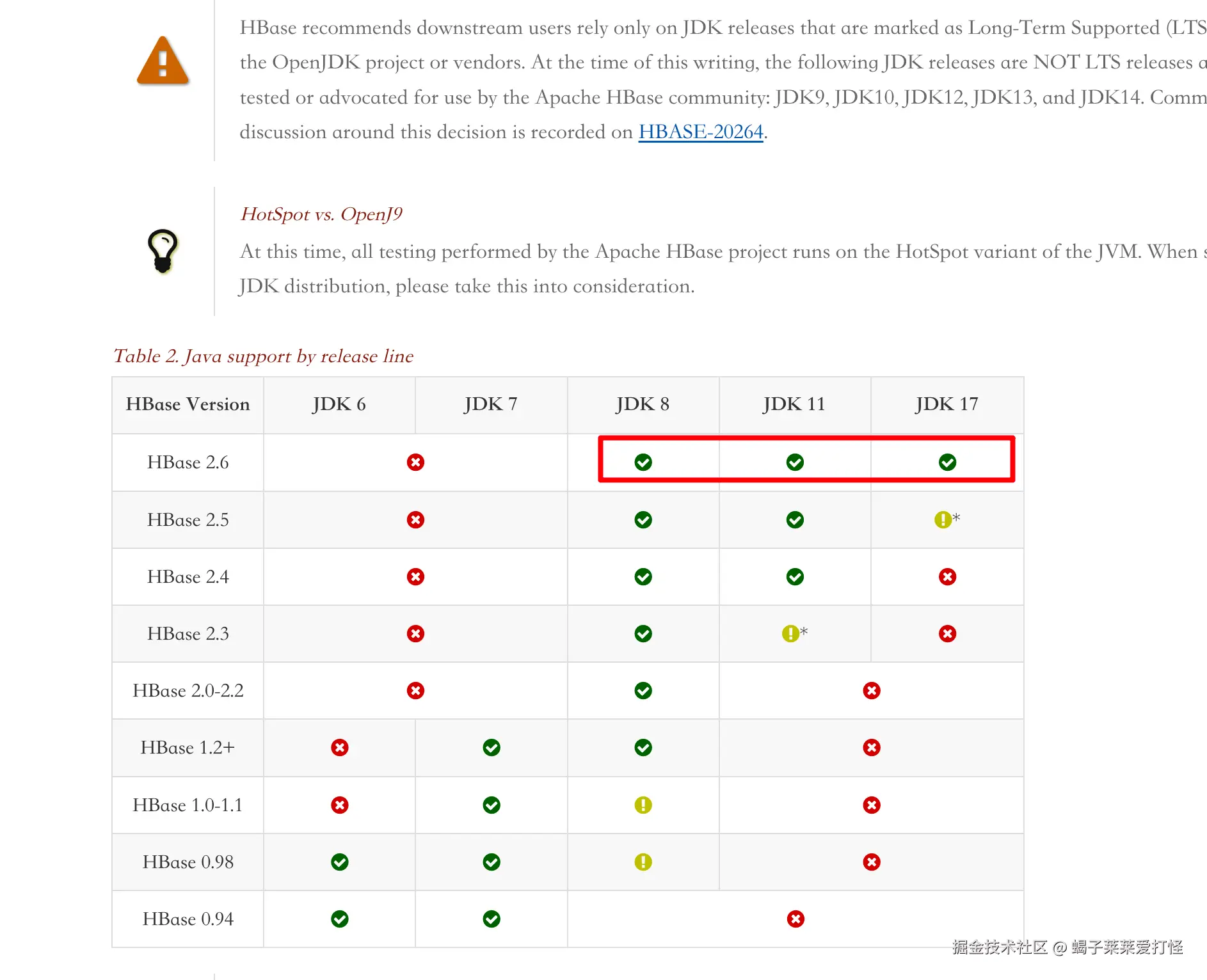
因为hadoop和hbase都依赖java环境所以需要确保java已经安装(我安装的jdk8) 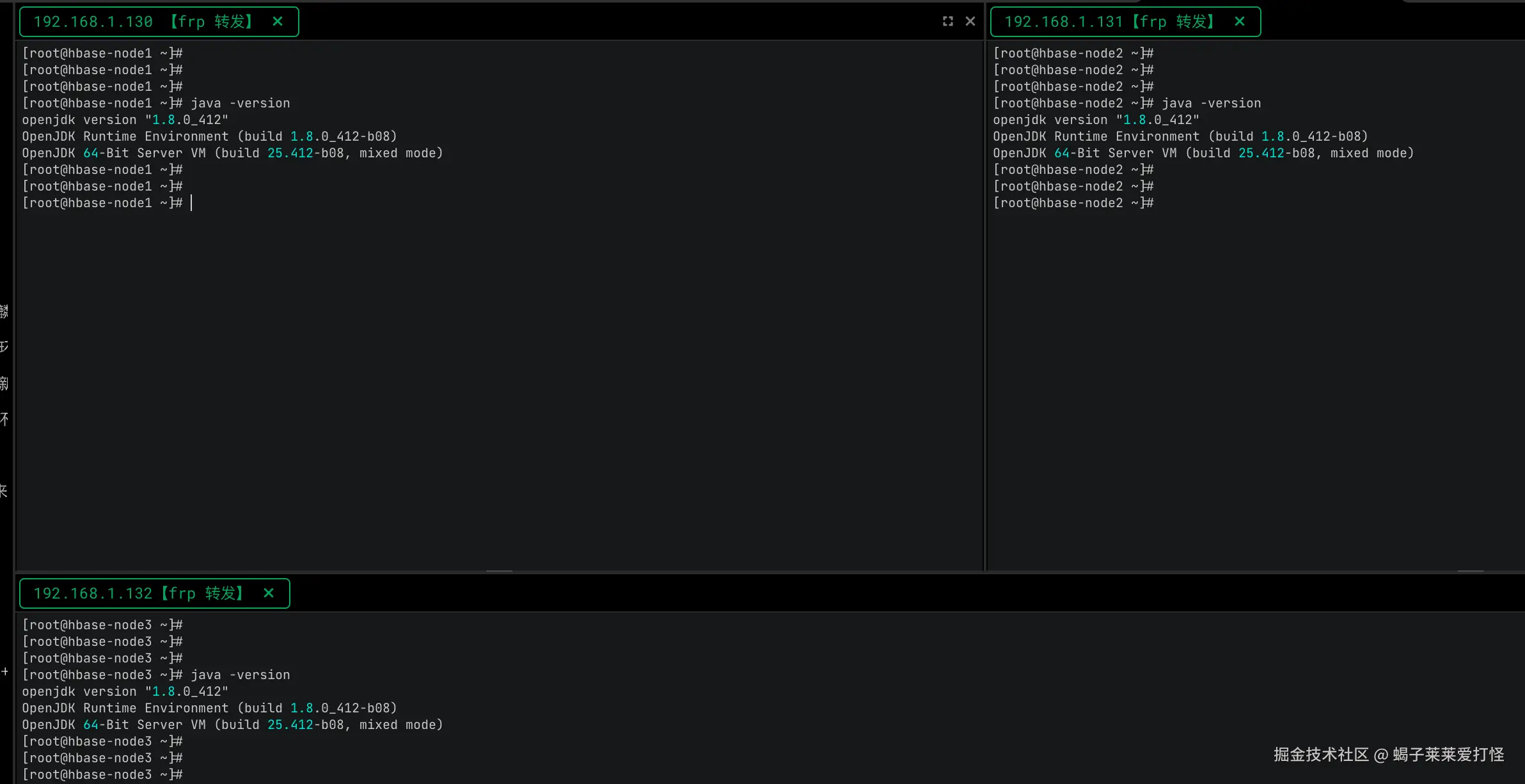
如果没有安装的使用以下命令安装:
shell
sudo yum install java-1.8.0-openjdk-devel如果机器上安装了多个 可以使用这个符号链接管理工具选择你要使用哪个版本(此命令会通过符号链接管理工具将/usr/bin/java的符号链接,指向用户选择的Java版本):
shell
sudo update-alternatives --config java如果我选择2的话我系统的 JAVA_HOME就会变成jdk11了 。 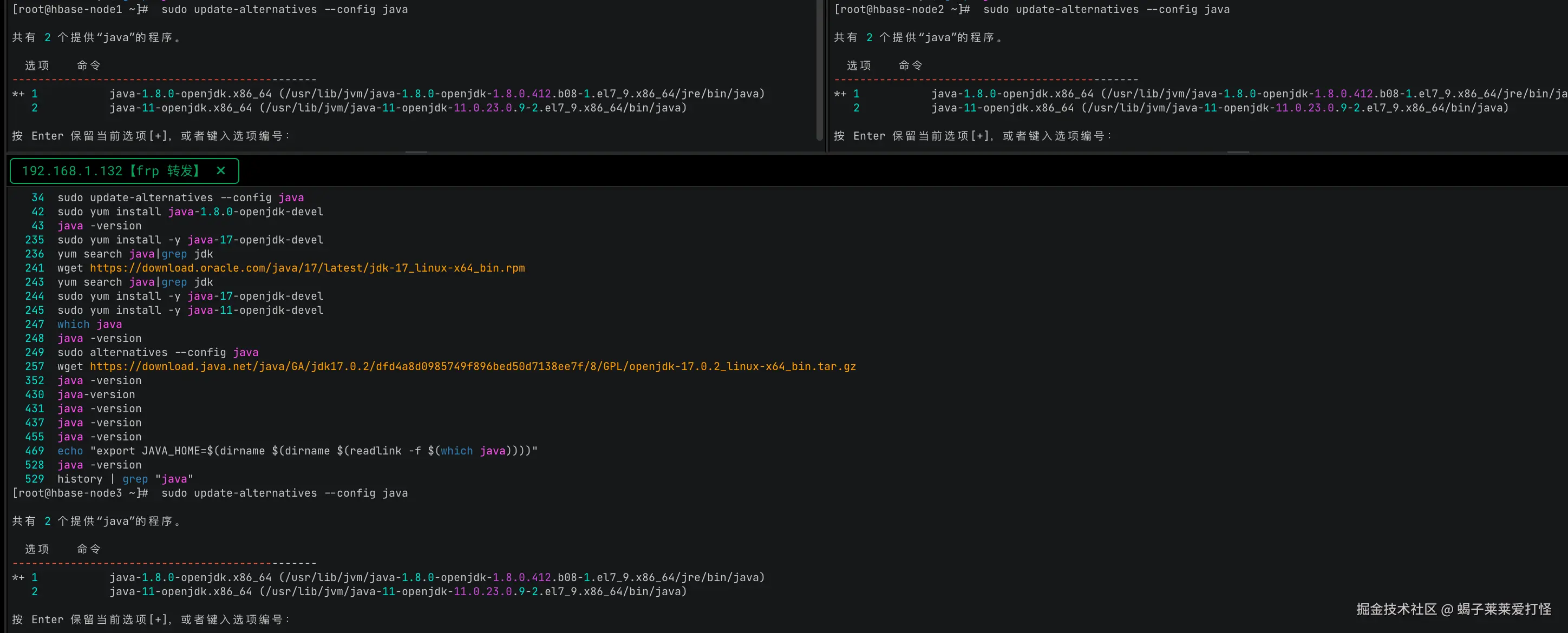
确保安装了jdk8后,下边开始安装hbase所需的hadoop环境并启动他的分布式文件系统 HDFS。
二、搭建hadoop的HDFS集群
配置hosts
在三台机器分别执行hosts配置,使得互相通过域名可以访问。
shell
cat >> /etc/hosts <<EOF
192.168.1.130 hadoop01
192.168.1.131 hadoop02
192.168.1.132 hadoop03
EOF配完重启下机器,验证下: 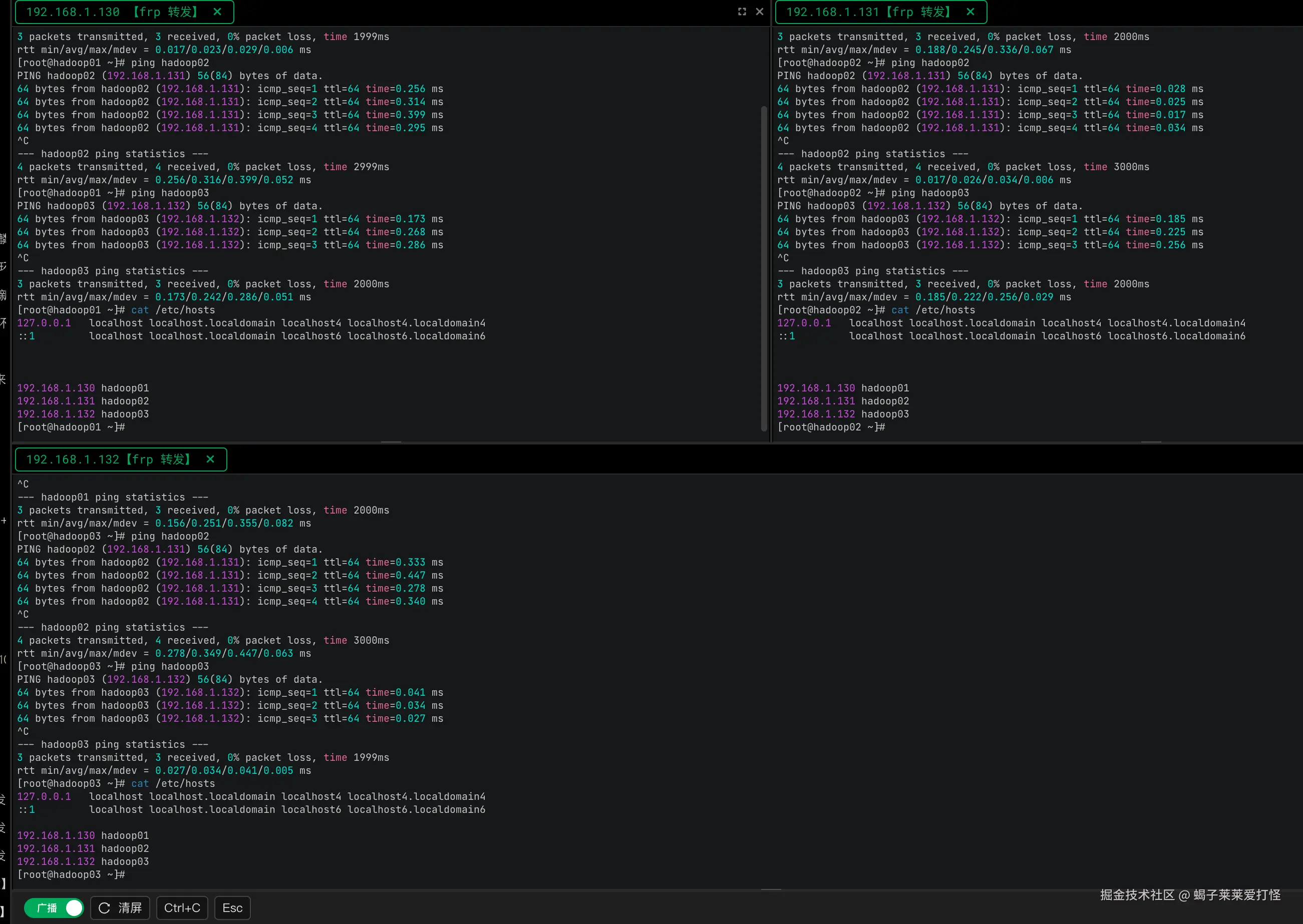
创建hadoop用户组和用户
hadoop用户组&用户创建(在三台机器上分别操作)
bash
# 用户组创建
groupadd hadoop
# 创建 hadoop 用户并加入组
useradd -g hadoop hadoop
# 设置密码
passwd hadoop设置hadoop用户ssh免密登录另外两个从节点
shell
su - hadoop
ssh-keygen -t rsa
ssh-copy-id hadoop@hadoop01
ssh-copy-id hadoop@hadoop02
ssh-copy-id hadoop@hadoop03过程如下: 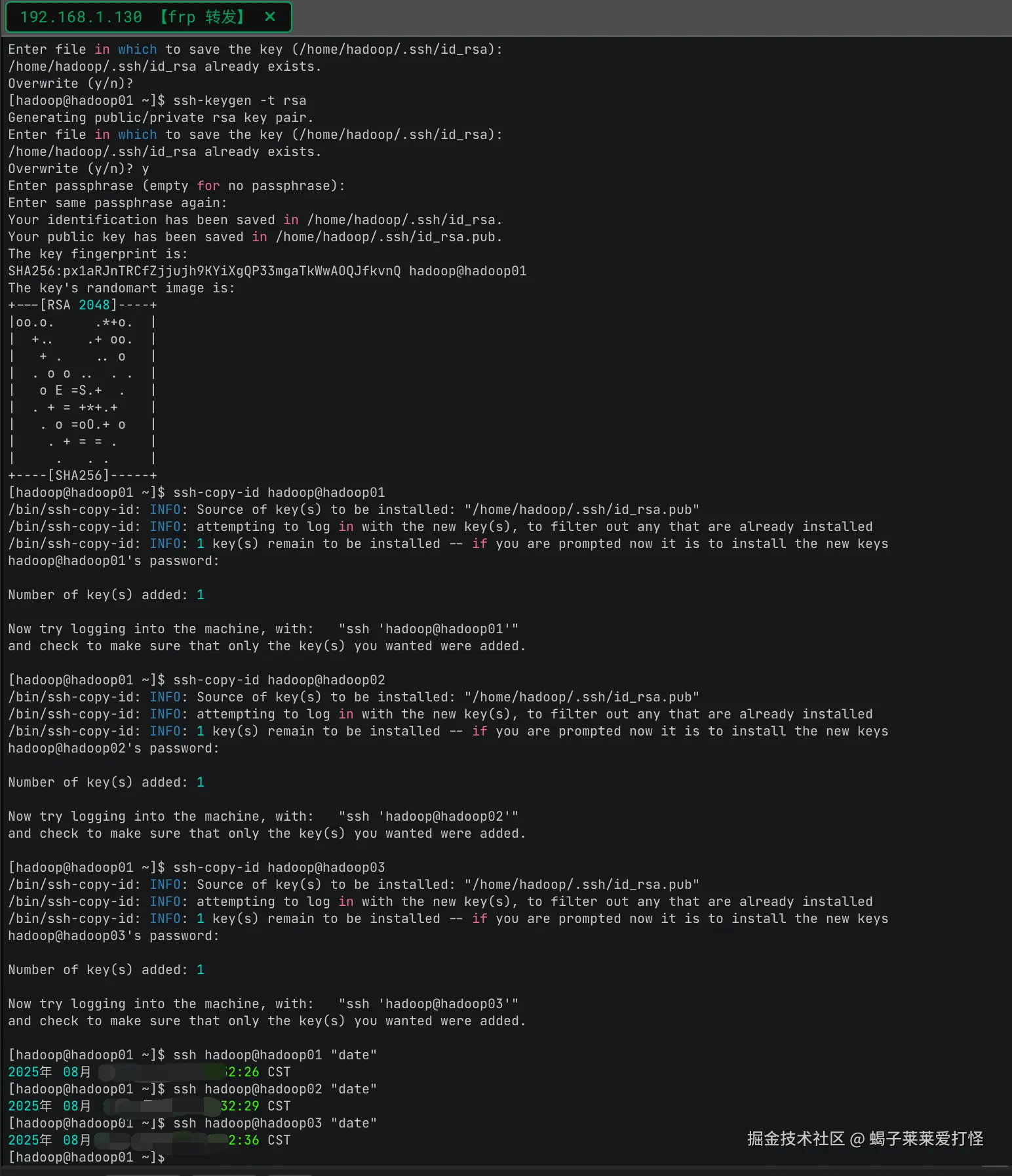
可以看到:
java
ssh hadoop@hadoop01 "date"
ssh hadoop@hadoop02 "date"
ssh hadoop@hadoop03 "date"都返回了当前时间,代表130节点可免密访问131 、132节点。
创建hadoop和hbase目录(在三台机器上分别操作)
bash
mkdir -p /home/hzz/{hadoop,hbase}
# 授权
chown hadoop:hadoop /home/hzz/hadoop之后进到 /home/hzz目录,下载hadoop 3.3.6 安装包:
ruby
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
# 解压:
tar -zxvf hadoop-3.3.6.tar.gz -C hadoop --strip-components=1我的思路是先配置130主节点 再scp到另外两个从节点,避免操作3次。 下边开始配置130主节点。
配置主节点hadoop
解压后开始配置130节点的hadoop(配完后 scp到另外两个从节点131 、132):
配置/home/hzz/hadoop/etc/hadoop/core-site.xml文件内容如下:
xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hzz/hadoop/tmp</value>
</property>
</configuration>配置/home/hzz/hadoop/etc/hadoop/hdfs-site.xml文件内容如下:
xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hzz/hadoop/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hzz/hadoop/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>配置/home/hzz/hadoop/etc/hadoop/workers文件内容如下:
hadoop01
hadoop02
hadoop03配置/home/hzz/hadoop/etc/hadoop/hadoop-env.sh文件
使用命令往
shell
echo "export JAVA_HOME=$(dirname $(dirname $(readlink -f $(which java))))" >> /home/hzz/hadoop/etc/hadoop/hadoop-env.sh/home/hzz/hadoop/etc/hadoop/hadoop-env.sh文件中追加内容如下: 
此时主节点hadoop就配好了,将整个目录scp到其他2个从节点
scp130主节点的hadoop到其他2个从节点
shell
scp -r /home/hzz/hadoop hadoop02:/home/hzz/
scp -r /home/hzz/hadoop hadoop03:/home/hzz/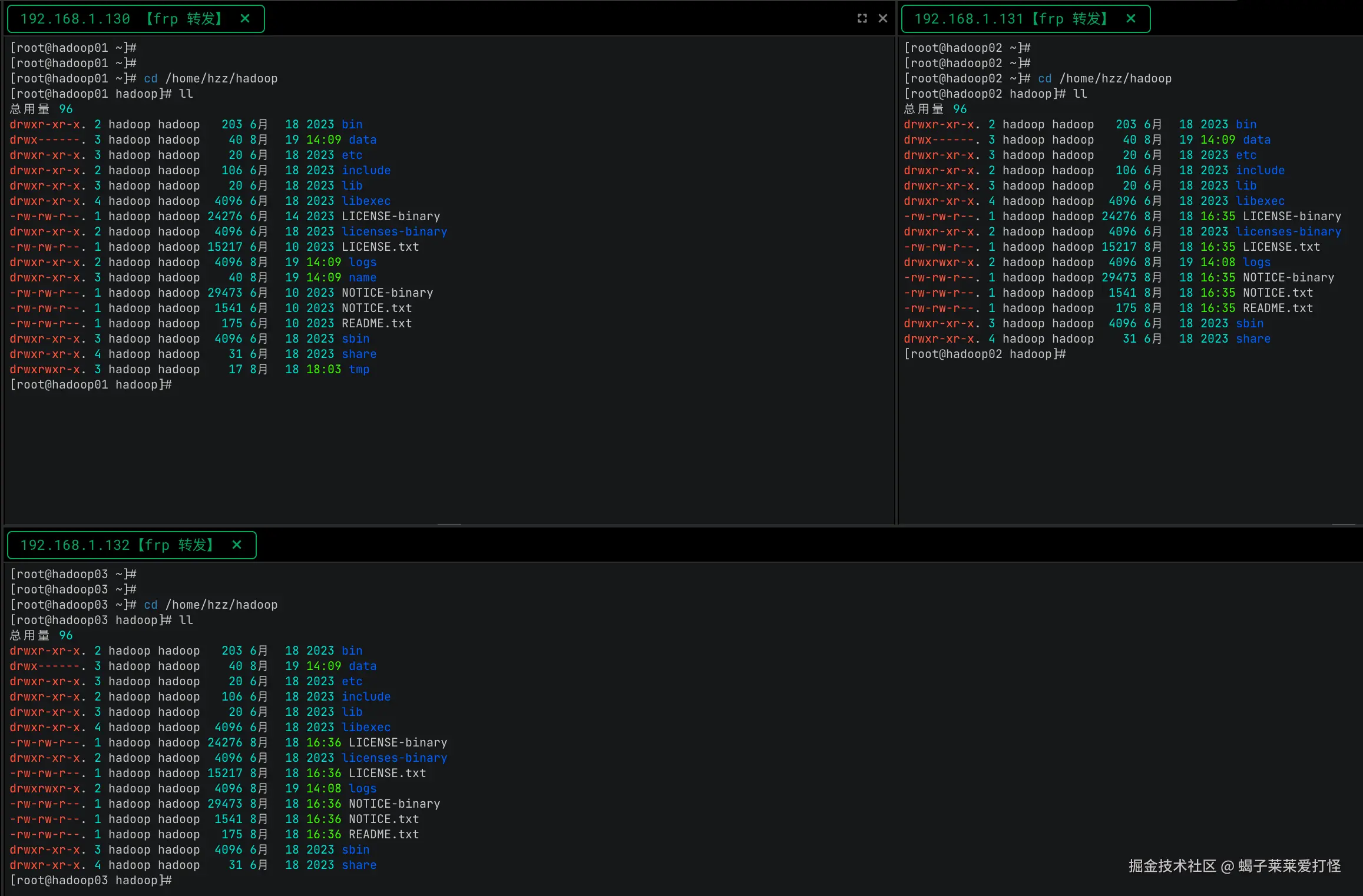
初始化HDFS集群的文件系统
由于我是首次安装,所以执行这个没问题,如果生产环境且之前有数据的话,那就不能这么简单粗暴了。
shell
su hadoop
/home/hzz/hadoop/bin/hdfs namenode -format -force
(注意如果后续有全量删除nameNode的文件的场景,那么可以执行这个命令 将会删除所有的文件系统数据,但是从节点的 data目录 需要手动rm -rf删除 否则从节点起不来)从下边提示来说 HDFS已经格式化/初始化成功: 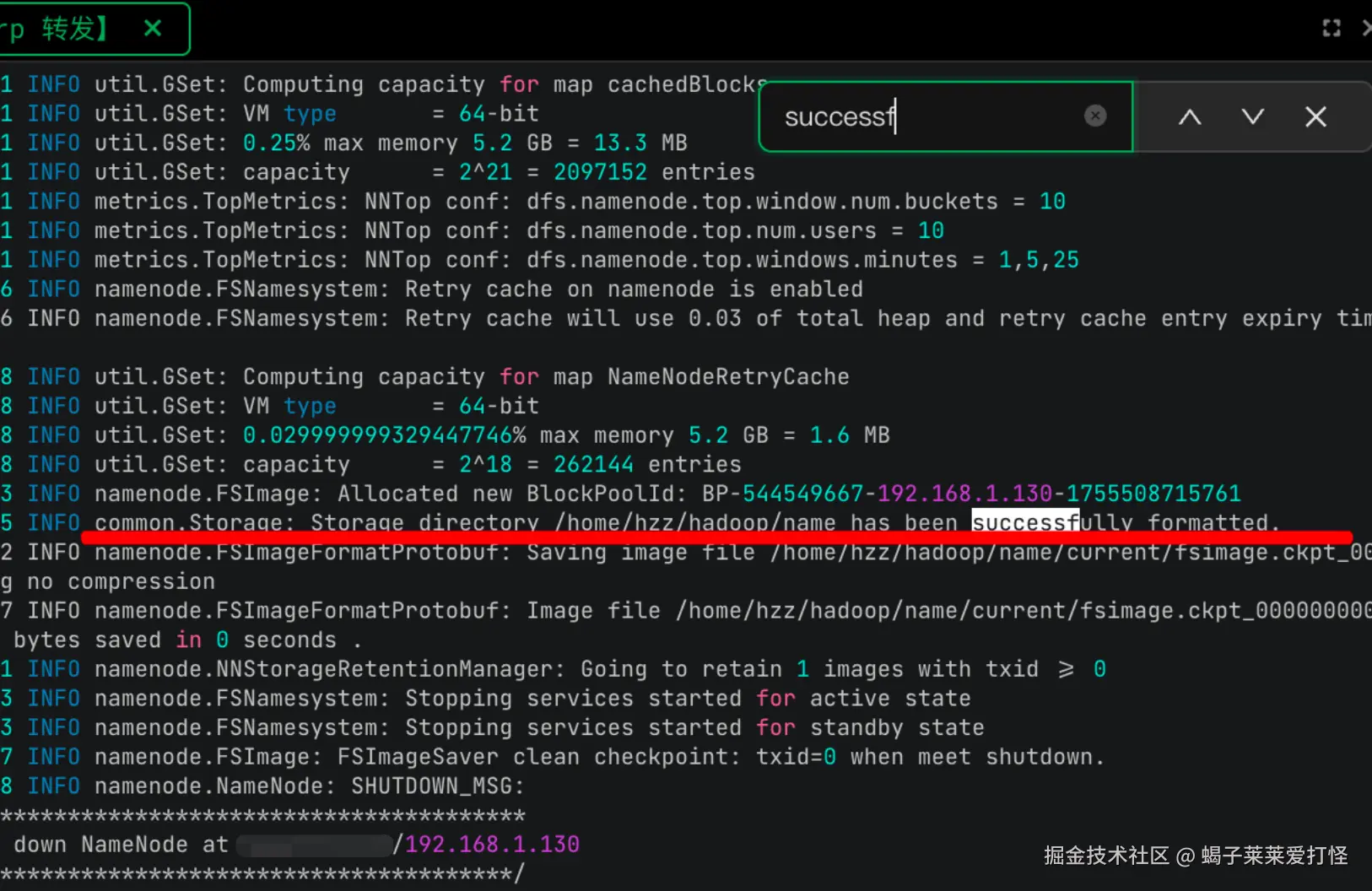
启动HDFS集群
shell
su hadoop
/home/hzz/hadoop/sbin/start-dfs.sh使用jps命令可以看到:
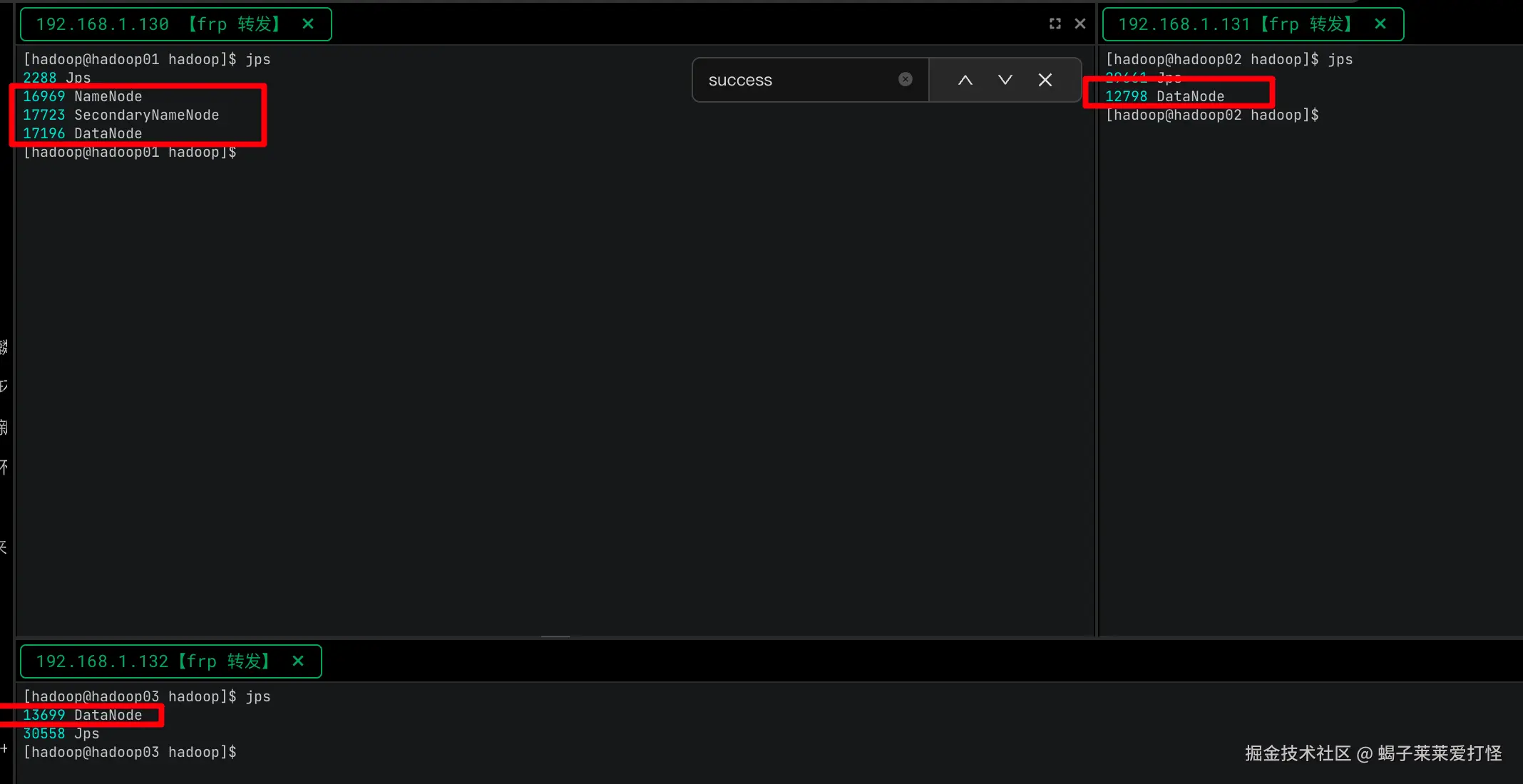
hadoop01, 已经启动了 NameNode、SecondaryNameNode、DataNode三个进程
hadoop02, 已经启动了 DataNode进程
hadoop03, 已经启动了 DataNode进程
下边简单介绍下HDFS 核心组件: NameNode、SecondaryNameNode、DataNode 都是干啥的。
HDFS 核心组件介绍: NameNode、SecondaryNameNode、DataNode介绍
NameNode
- 核心职责: 管理HDFS文件系统命名空间(目录结构)
维护文件块到DataNode的映射关系
处理客户端文件操作请求
- 关键端口: 9000:RPC通信端口
9870:Web UI端口
SecondaryNameNode
- 核心职责: 定期合并NameNode的编辑日志(edits)和镜像文件(fsimage)
减少NameNode重启时间
注意:SecondaryNameNode不是NameNode的热备份!
详述下SecondaryNameNode的作用和存在的意义:
markdown
SecondaryNameNode 的作用: 定期(默认每小时,由 dfs.namenode.checkpoint.period 控制,或当 edits 达到一定大小,由 dfs.namenode.checkpoint.txns 控制)执行以下步骤:
请求滚动 edits: SecondaryNameNode 通知 NameNode 暂停写入当前的 edits 文件,并开始写入一个新的 edits 文件(edits_inprogress_new)。
下载 fsimage 和 edits: SecondaryNameNode 通过 HTTP 从 NameNode 下载最新的 fsimage 和旧的 edits 文件(在步骤1中暂停写入的那个)。
在本地合并: SecondaryNameNode 在本地内存中将下载的 fsimage 加载,然后顺序重放下载的 edits 日志中的所有操作,生成一个新的、合并后的 fsimage(fsimage.ckpt)。
上传新 fsimage: SecondaryNameNode 将新生成的 fsimage.ckpt 文件上传回 NameNode。
替换与激活: NameNode 收到 fsimage.ckpt 后,将其重命名为新的 fsimage(如 fsimage_XXXXX),并用新的 edits_inprogress_new 替换旧的 edits 文件(作为新的 edits 起点)。旧的 fsimage 和 edits 文件被保留(可配置保留数量)。
效果: 大大减少了 NameNode 重启时需要重放的 edits 日志量,从而显著缩短 NameNode 的重启时间。同时控制了 edits 文件的大小DataNode
-
核心职责:
存储实际数据块(默认128MB/块)
定期向NameNode发送心跳报告执行数据块的创建/删除/复制
-
关键参数:
心跳间隔:3秒(可配置) 块报告间隔:6小时(可配置)
查看集群状态
命令查看当前集群节点状态:
shell
su hadoop
/home/hzz/hadoop/bin/hdfs dfsadmin -report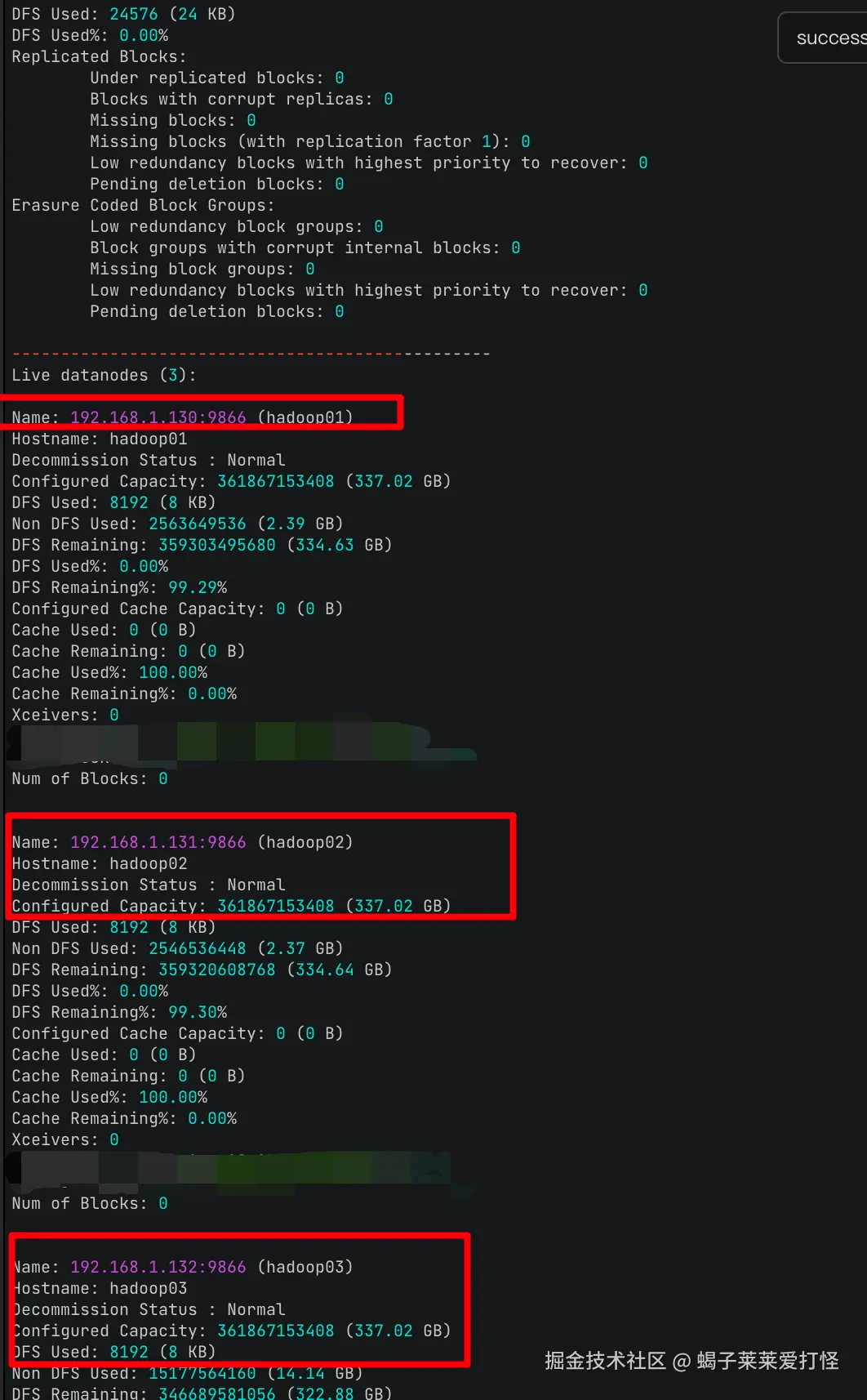
另外如果想直观些,可访问 192.168.1.130:9870的hadoop-webui 可以看到当前集群情况:
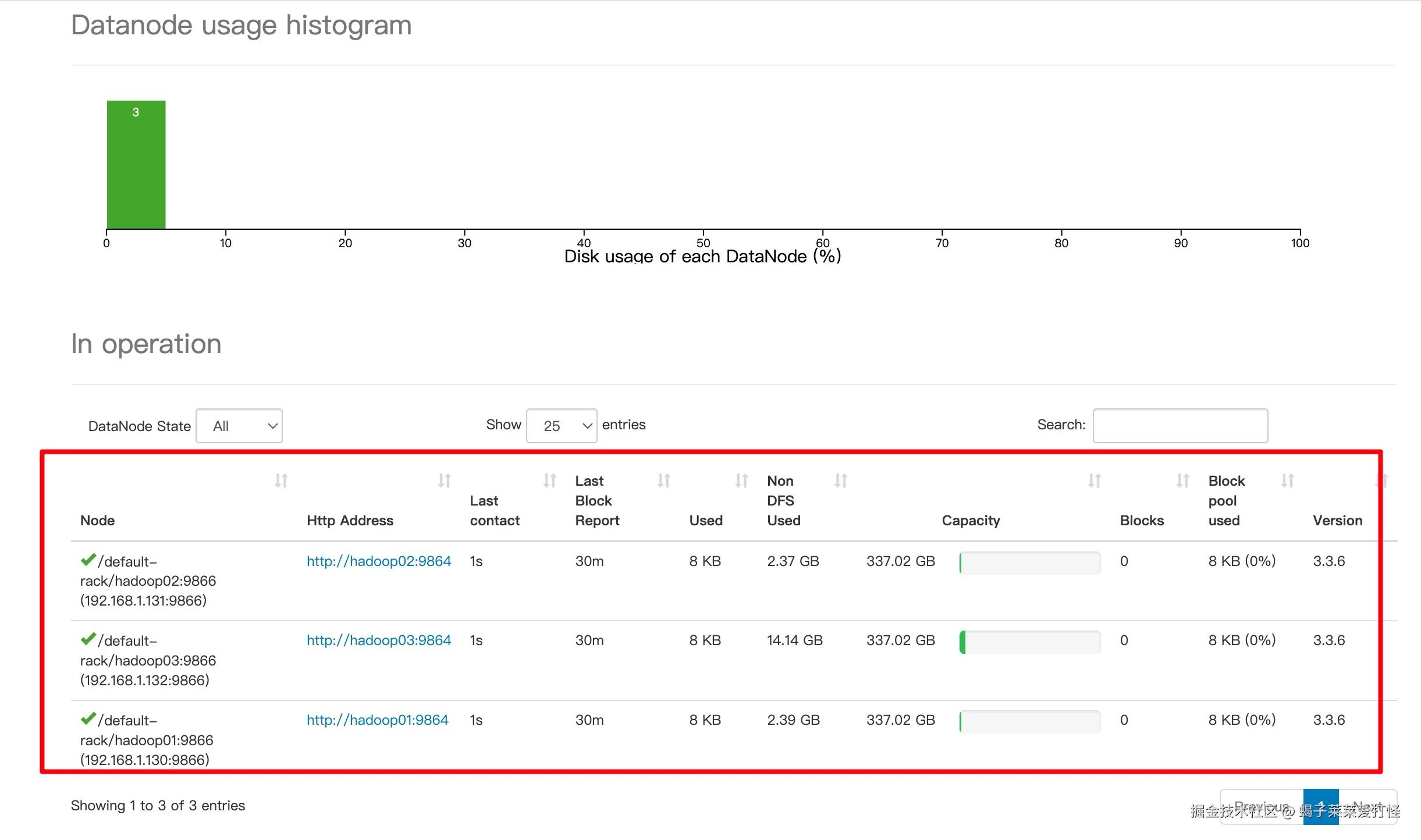
ok 现在 hadoop的hdfs文件系统集群准备好了,接下来搭建Hbase集群。
三、搭建Hbase集群
踩坑:
第一次搭建hbase时,我装的hbase是2.4.17版本,这版本hbase的lib中依赖的是2.1.x的hadoop包,而我上边安装的hadoop是3.3.6的 所以当我配置并启动hbase后,会报各种错误,比如:
以及这个错:
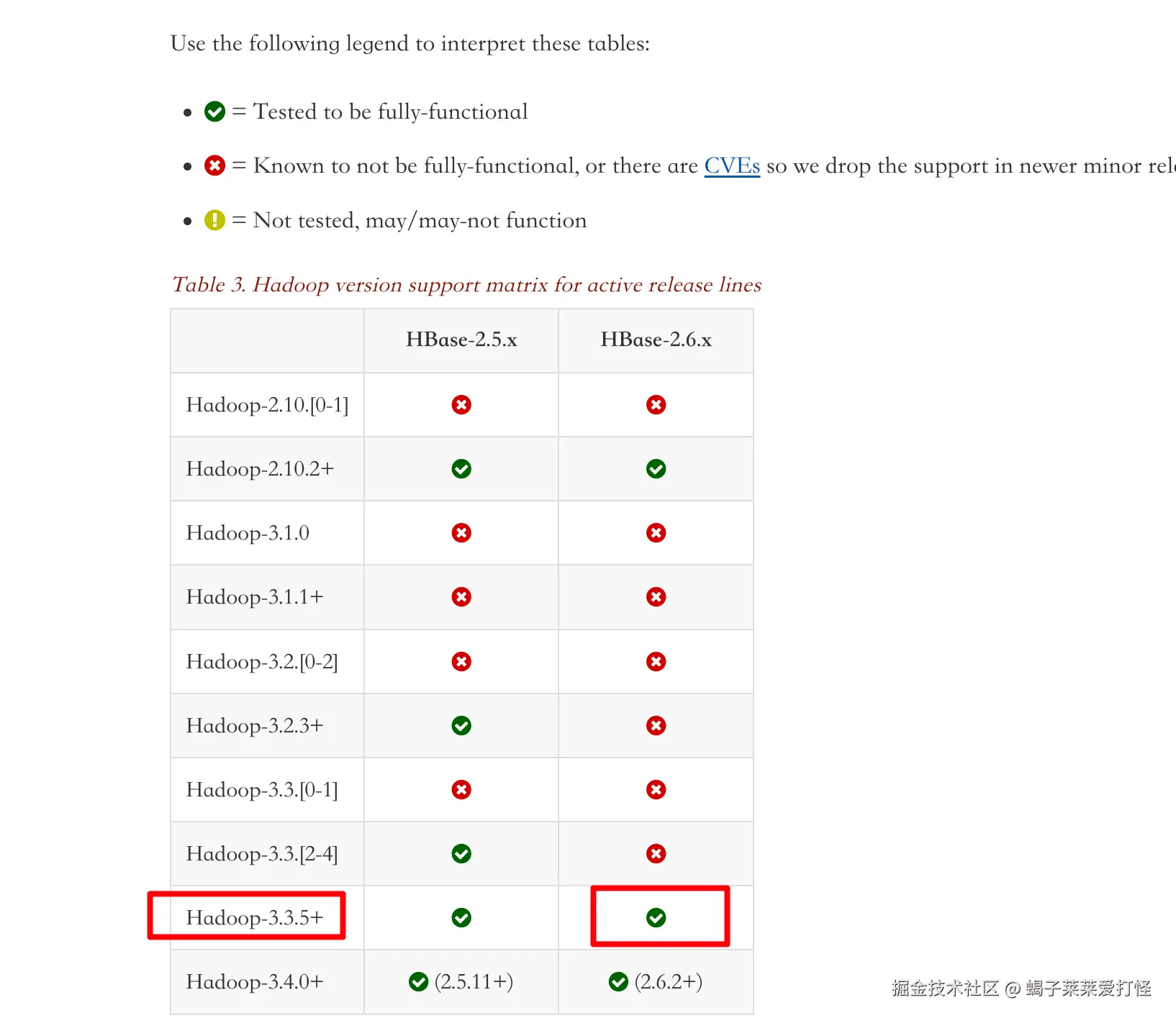
查了一圈,发现这应该属于历史原因,想解决的话需要手动替换掉hbase lib里边的hadoop包,但我觉得这么做不太靠谱(万一哪个漏掉了各种版本问题令我头疼),调研了下发现 hbase 2.6.1 lib里的hadoop是 3.3.5 ,所以我就铲掉 hadoop和hbase 重装。这样肯定完美兼容没有任何兼容问题了,另外官网看这俩也是兼容的。
hbase官网:hbase.apache.org/book.html#_...
我铲掉上边安装的hadoop3.3.6 ,重新安装hadoop3.3.5,这个安装和3.3.6安装一模一样唯一区别就是版本不一样,不做多余记录了。
hadoop 3.3.5安装成功后,下边开始安装hbase 2.6.1
安装hbase 2.6.1
ps: hbase我也给的hadoop账号权限
注意hadoop我们安装的3.x 下载hbase时也得下载这个带hadoop3后缀的: 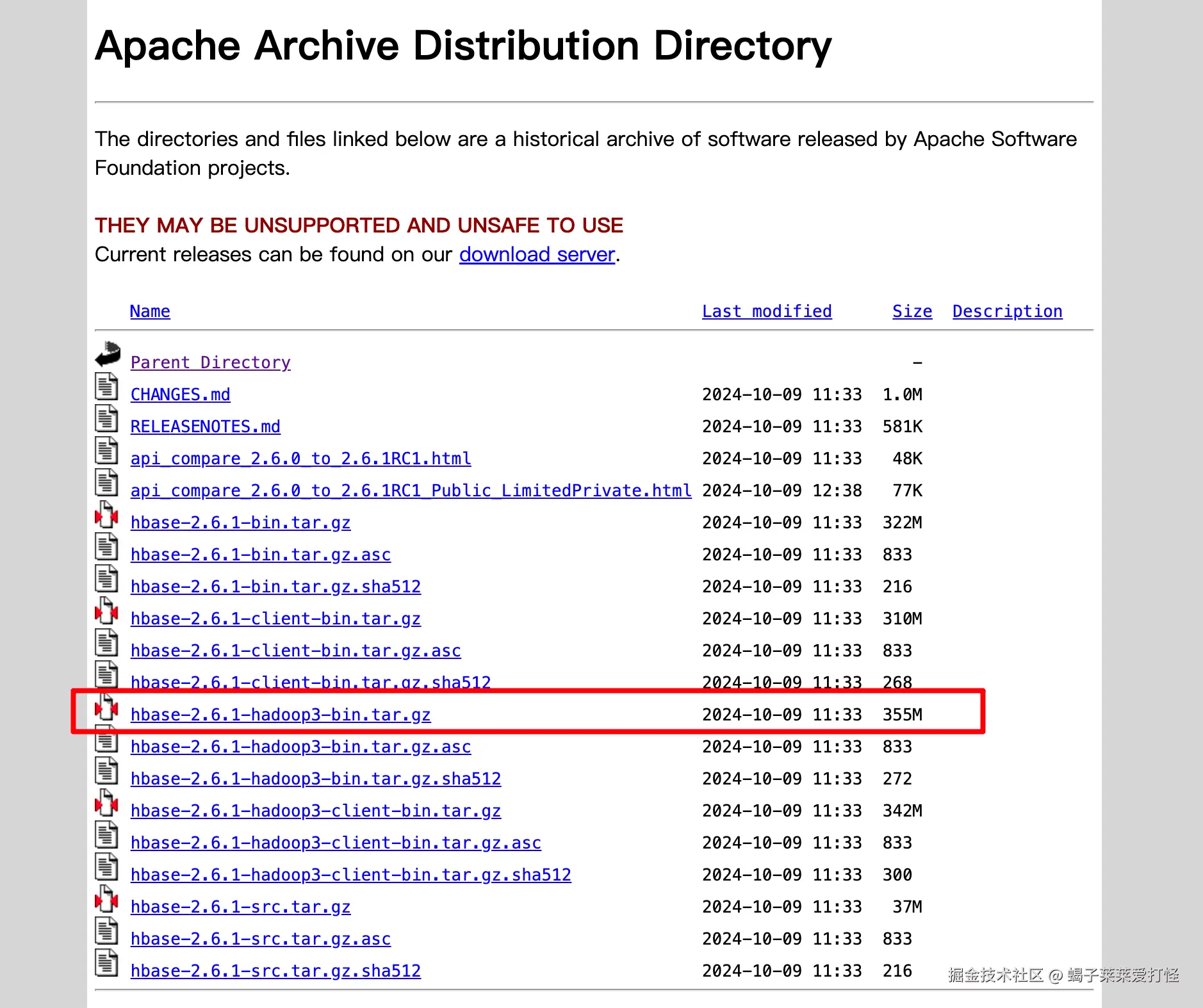
bash
cd /home/hzz
wget https://archive.apache.org/dist/hbase/2.6.1/hbase-2.6.1-hadoop3-bin.tar.gz
tar -zxvf hbase-2.6.1-hadoop3-bin.tar.gz -C hbase --strip-components=1配置HBase
配置 /home/hzz/hbase/conf/hbase-env.sh*
bash
echo "export JAVA_HOME=$(dirname $(dirname $(readlink -f $(which java))))" >> /home/hzz/hbase/conf/hbase-env.sh
echo "export HBASE_MANAGES_ZK=false" >> /home/hzz/hbase/conf/hbase-env.sh配置 /home/hzz/hbase/conf/hbase-site.xml
xml
<configuration>
<property>
<!-- 关键配置,让hbase使用hadoop的hdfs文件系统 -->
<name>hbase.rootdir</name>
<value>hdfs://hadoop01:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop02</value> <!-- 使用131的ZK -->
</property>
<property>
<name>hbase.regionserver.handler.count</name>
<value>30</value>
</property>
<!-- SSD优化 -->
<property>
<name>hbase.wal.storage.policy</name>
<value>HOT</value>
</property>
</configuration>配置 /home/hzz/hbase/conf/regionservers文件
text
hadoop01
hadoop02
hadoop03同步配置到另外两台从节点 hadoop02 hadoop03,并修改为hadoop用户和用户组
bash
scp -r /home/hzz/hbase hadoop02:/home/hzz/
scp -r /home/hzz/hbase hadoop03:/home/hzz/
# 在hadoop 01 hadoop02 hadoop03分别执行赋权
chown -R hadoop:hadoop /home/hzz/hbase在主节点hadoop01启动hbase集群
arduino
su hadoop
/home/hzz/hbase/bin/start-hbase.sh
验证hbase集群状态
/home/hzz/hbase/bin/hbase shell <<< "status" 
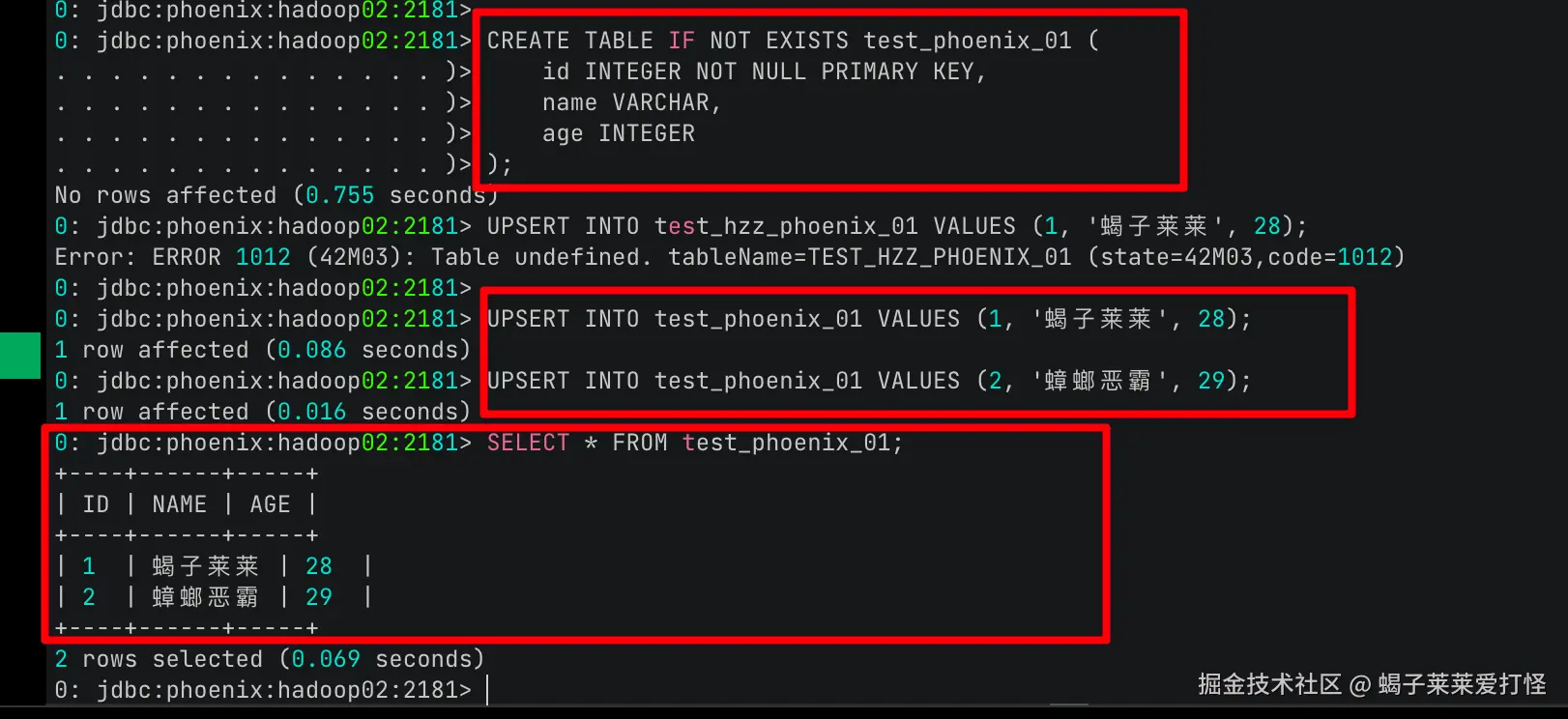
建表并插入数据试一下:
arduino
create 'test_table01', 'cf'
put 'test_table01', 'row1', 'cf:col1', 'value1'
get 'test_table01', 'row1'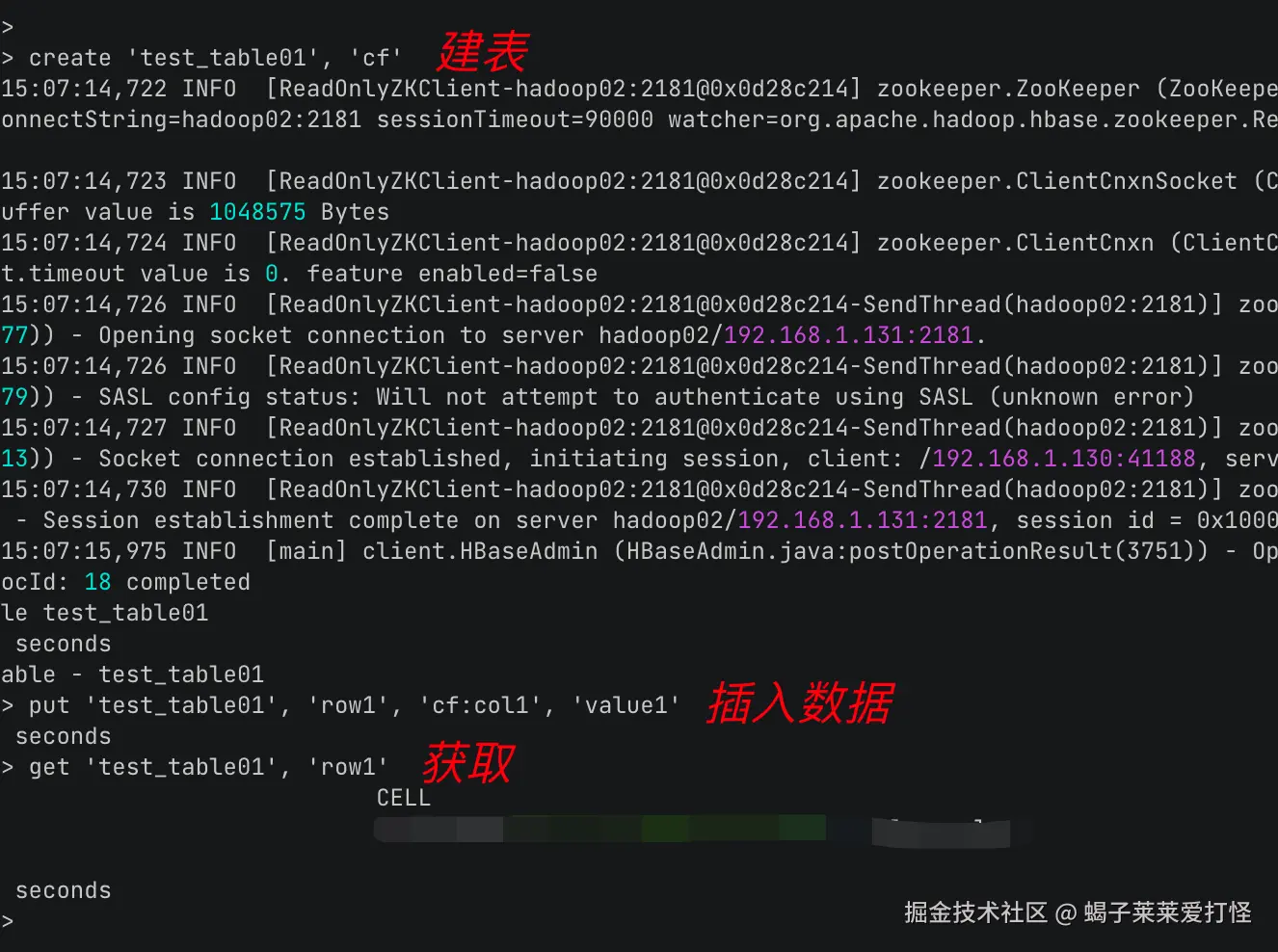
访问hbase的web-ui(192.168.1.130:16010)可以观察到各种详细信息: 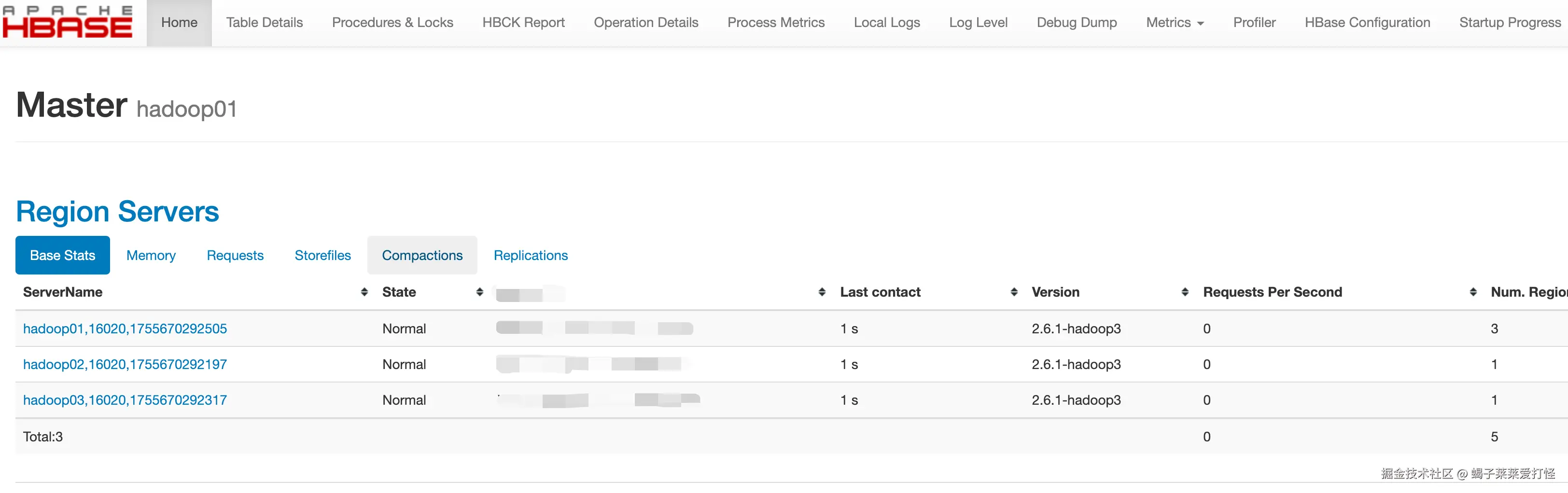
可以看到hbase集群已经成功运行。
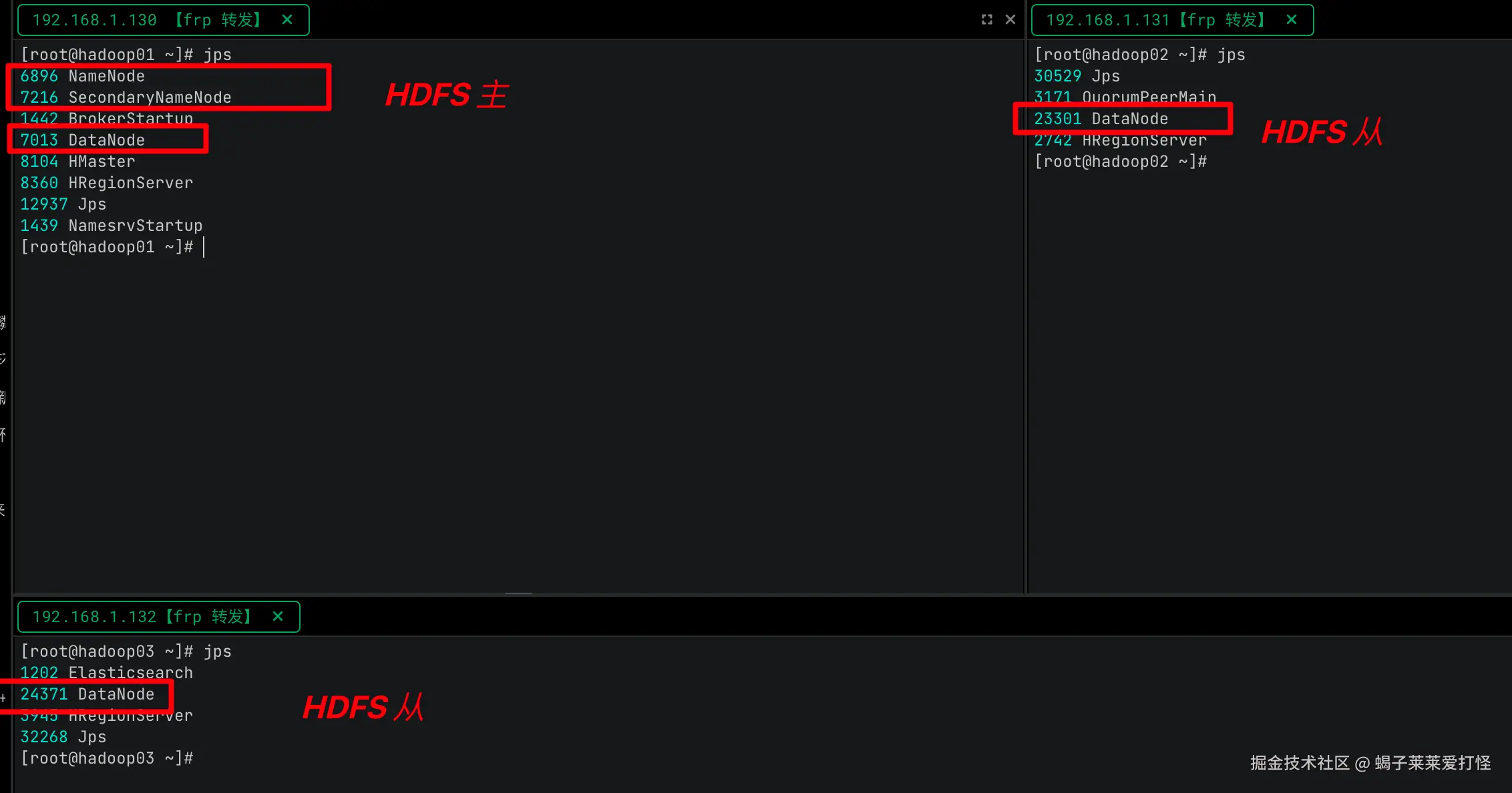
四、最终部署形态:
最终HDFS部署情况:
Hbase部署情况: 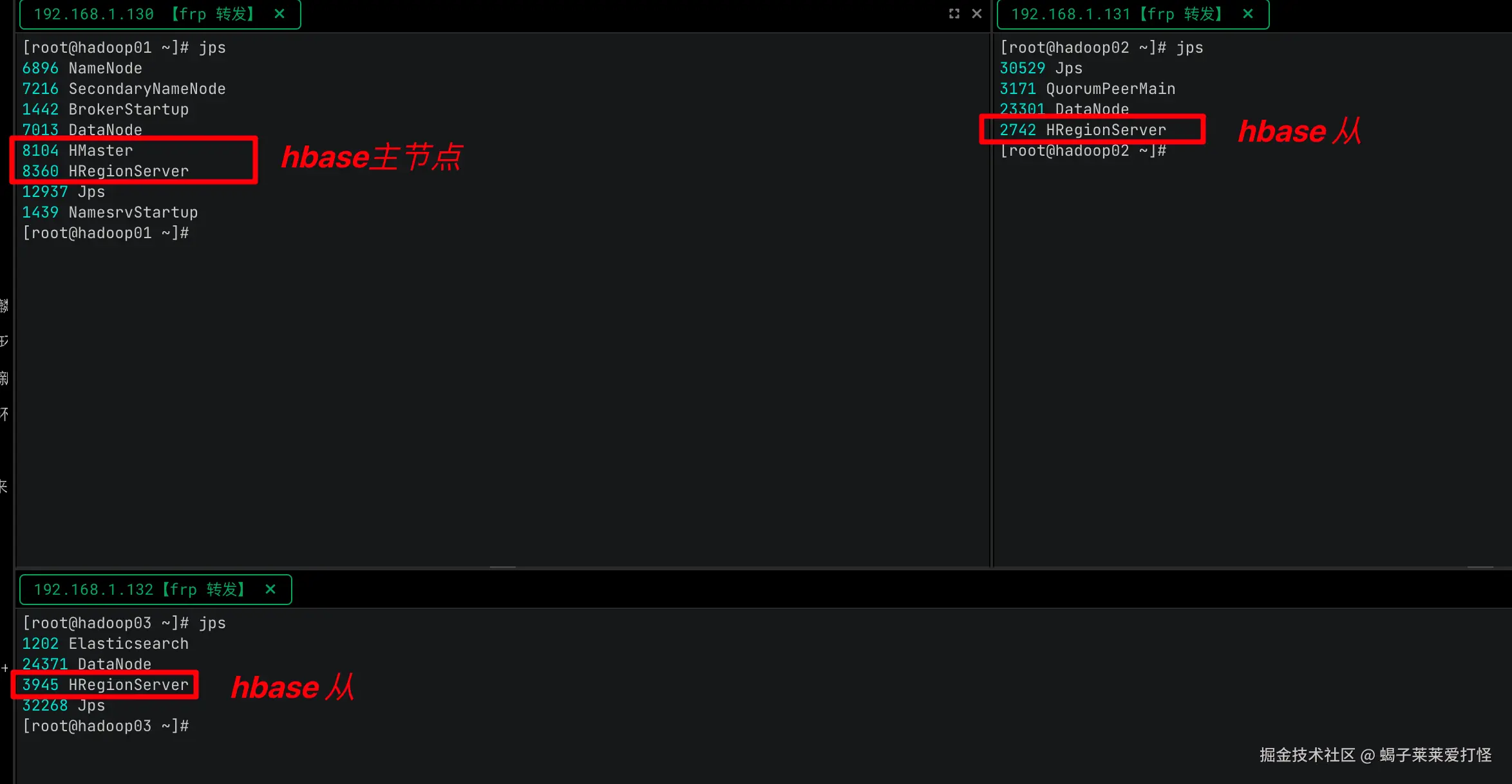
五、使用Phoenix当hbase的翻译官
phoenix可以提供类sql的语法,可以把他看做是一名"翻译官" 将hbase的语法 翻译为jdbc协议, 我去官网下载对应版本:
phoenix.apache.org/download.ht... 
bash
wget https://dlcdn.apache.org/phoenix/phoenix-5.2.1/phoenix-hbase-2.6-5.2.1-bin.tar.gz)他是个大而全的tar ,我们需要解压然后将其 的 phoenix-server-hbase-2.6-5.2.1.jar 拷贝到 hbase的lib目录:
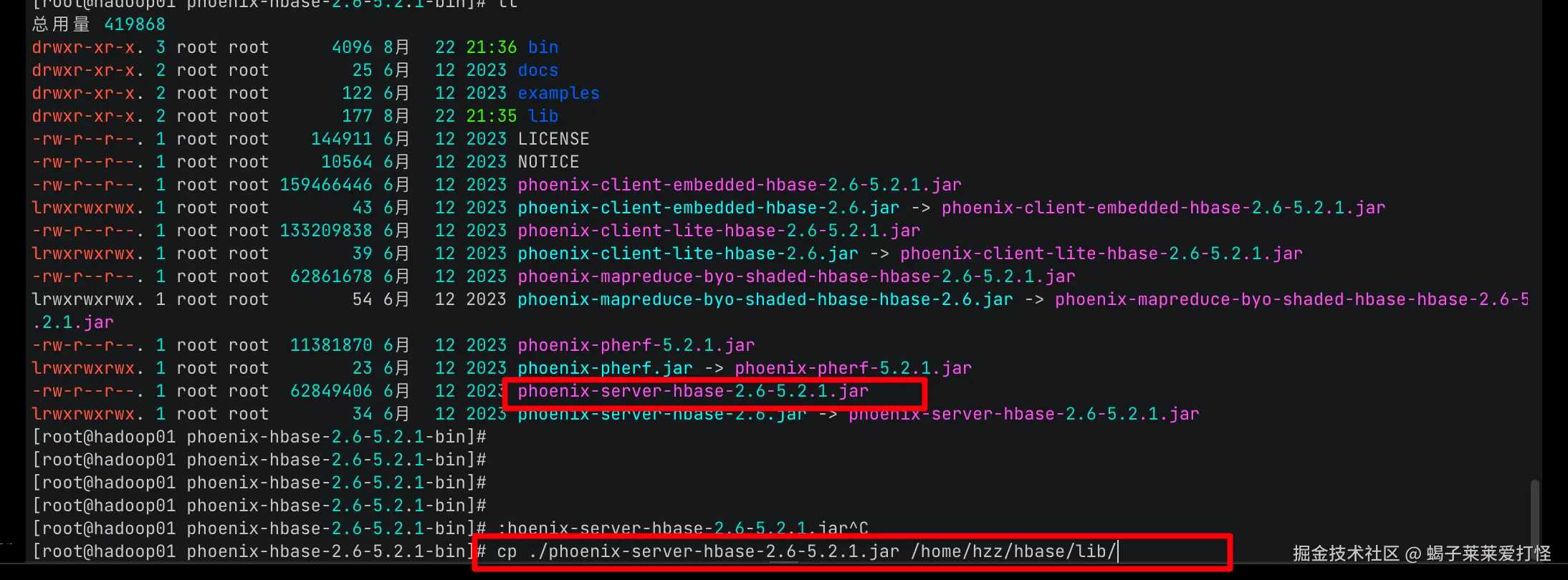
并 scp到另外两个从节点的hbase的lib目录:
bash
scp -r /home/hzz/hbase/lib/* hadoop02:/home/hzz/hbase/lib/
scp -r /home/hzz/hbase/lib/* hadoop03:/home/hzz/hbase/lib/然后停止hbase 重启hbase :
arduino
su hadoop
/home/hzz/hbase/bin/stop-hbase.sh
/home/hzz/hbase/bin/start-hbase.sh然后我们进入: /home/hzz/phoenix/phoenix-hbase-2.6-5.2.1-bin/bin 目录执行:
bash
./sqlline.py hadoop02:2181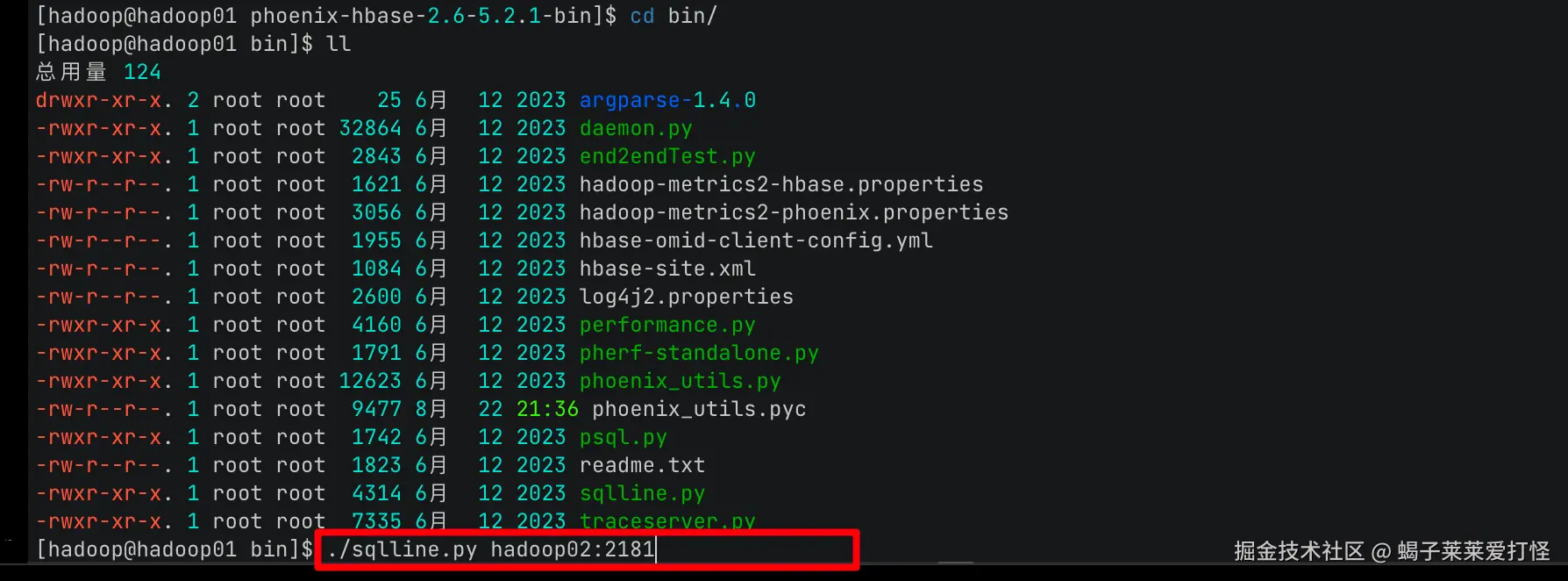

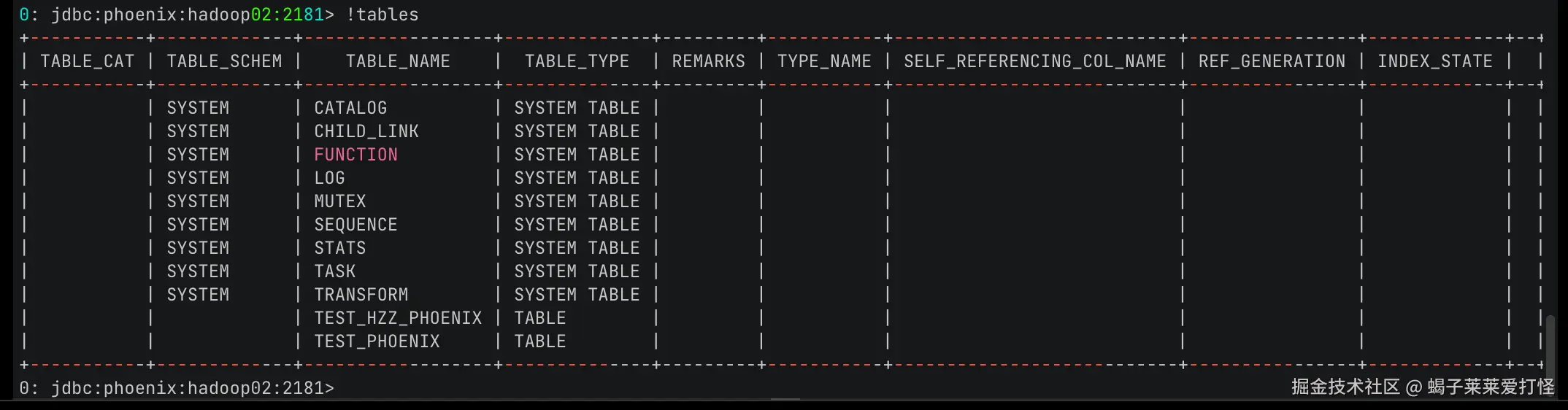
sqlline有对应的语法,和sql比较类似,需要时看看他的doc文档或者搜一下就好了: