一、论文地址
https://arxiv.org/pdf/2401.15077 EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
https://arxiv.org/pdf/2501.14818 Eagle 2: Building Post-Training Data Strategies from Scratch for Frontier Vision-Language Models
https://arxiv.org/pdf/2503.01840 EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test
二、论文解读
2.1 eagle-1
LLM推理阶段是受内存带宽限制的(所谓的memory-bandwidth bound。简单地说就是计算比IO操作快,所以每次推理的时间大部分其实是消耗在了数据搬移上,即把LLM的参数等从GPU搬到高速缓存上。显然这个问题的严重性会随着LLM规模的增大而增大。
传统的自回归解码是逐个token生成,每个解码步在生成下一个token都需要依赖前面已经生成的所有token,都需要重复搬移LLM的参数以及kv cache。也就是说,花了半天时间把计算需要的数据准备好,结果只出了一个token。
既然one-by-one很耗时,那么如果一次能生成多个token就能减少推理时间。假设生成长度是10,one-by-one需要解码10次,即LLM参数读取10次;假设一次可以生成5个token,那么只需要解码2次,只需要搬移LLM参数2次。在搬移所消耗的时间上,我们就可以变成以前的五分之一。投机解码就是这样一种通过缩短推理步骤来进行推理加速的解决方案。
投机解码核心思想是选择与目标模型同系列的参数量小几个数量级的LLM作为草稿模型,就能比较好地平衡推理速度以及推理精度,从而获得一定的加速比。但是,不是所有模型都能找到这样一个合适的草稿模型,而完全重新训练一个的代价又比较大,这种情况下又该怎么做呢?
论文EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty1,这篇论文提出一种构建轻量级草稿模型的方法,核心思想是利用目标模型的feature,并在feature层面进行自回归, 而不是 token 层面,从而保证生成质量实现加速。
各个加速方案的对比:

Eagle 核心思路
-
核心观点一:在特征层 (feature level) 进行自回归比在 token 层进行自回归更简单
-
解释:论文中的「特征」指的是 LLM 倒数第二层的输出,也就是在进入 LM Head 之前的隐藏状态 (hidden state)。相比于 token 序列,特征序列具有更强的规律性。
-
优势:在特征层进行自回归预测,然后通过 LM Head 得到 token,比直接预测 token 更容易,效果更好。
-
-
核心观点二:采样过程中的不确定性限制了特征预测的性能
-
解释:在文本生成过程中,LLM 的输出是带有随机性的,因为 LLM 会对 token 的概率分布进行采样。这种随机性导致特征序列的预测变得不确定。例如,给定相同的输入「I」,接下来可能出现「always」或者「am」,这就导致了特征预测的不确定性。
-
解决方案:EAGLE 通过引入一个时间步长提前的 token 序列来解决这个问题。也就是说,在预测当前特征时,不仅考虑之前的特征序列,还考虑之前已经采样的 token 序列。这样可以减少特征预测的不确定性。
-
-
EAGLE 的核心思想:
-
在特征层进行自回归:使用一个轻量级的自回归模型来预测目标 LLM 的特征序列,而不是直接预测 token。
-
解决不确定性:通过引入提前一个时间步的 token 序列来解决特征预测的不确定性。
-
总结:使用之前的 token 和 feature 信息,进行拼接得到一个组合feature, 通过一个训练的自回归预测头,预测下一个feature,然后将预测feature 通过 LLM 头,输出预测token, 如此不断的循环得到草稿树。再将草稿树使用Target LLM使用投机解码验证策略,一次前向推理,计算各个位置的概率分布,接受草稿树中概率分布小于Target llm 自身得到的概率分布位置的tokens, 从而保证了和Target llm严格一致的输出。
核心优势:通过feture的预测,避免使用草稿小模型的进行tokens的预测。因为 草稿小模型的规模非常小,完全由草稿小模型 在已经生成的token上来进行自回归,结果可能非常糟糕。一个如此小规模的模型拿什么去对齐 ,强行用的结果就是推理得快但大都推错,必然在验证阶段会被大量拒绝,等于做无用功。
-
Feature预测为什么更简单:
-
规律性:特征序列比 token 序列更具规律性。Token 序列是离散的,表示的是自然语言,而特征序列是连续的、高维的向量,它包含了更加抽象和结构化的信息。这种规律性使得在特征层进行自回归预测更加容易,因为更容易找到模式。
-
维度:特征的维度通常比 token 的词汇表大小要小,这降低了预测的难度。
-
语义:特征层已经包含了丰富的语义信息,而 token 层只是对这些信息的简单转换。在特征层进行自回归预测,可以直接利用这些语义信息,从而提高预测的准确性
-
实现方案
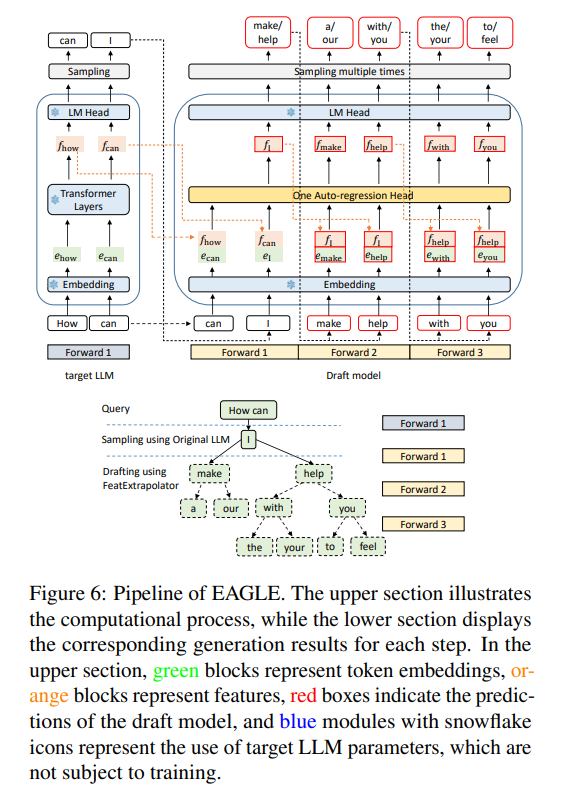
Eagle的模型结构非常简单,就三个模块:Embedding layer、Autoregression Head、LM Head。其中 Embedding layer、LM Head和target model共用,不用训练。下面看一看Eagle的输入和数据流。
EAGLE 的整体框架:
草稿阶段 (Drafting Phase):
输入:之前的特征序列和提前一个时间步的 token 序列。
处理过程:
-
将 token 序列转换为 embedding 序列。
-
将 embedding 序列和特征序列拼接在一起。
-
使用一个自回归头 (Autoregression Head) 来预测下一个特征。
-
使用 LM Head 将预测的特征转换为 token 的概率分布,并从中采样得到下一个 token。
-
将预测的特征和采样的 token 添加到输入序列中,继续进行自回归预测。
输出:一个由多个 token 组成的草稿树 (draft tree)。
验证阶段 (Verification Phase):
-
输入:草稿树。
-
处理:使用目标 LLM 对草稿树中的 token 进行验证 ,并根据验证结果决定是否接受或者拒绝这些 token。目标 LLM 运用树状注意力机制,通过单次前向传递计算树状结构草稿中每个 token 的概率 。在草稿树的每个节点,我们递归地应用推测采样 算法 来采样或调整分布(详见附录 A.2),这与 SpecInfer(Miao 等人,2023)一致,确保输出文本的分布与目标 LLM 的分布一致。同时,我们记录已接受的 token 及其特征,以供下一阶段的草稿使用。
-
具体验证过程:
-
前向传播:使用目标 LLM 对草稿树进行一次前向传播,得到每个 token 的概率分布。
-
验证:从根节点开始,逐层递归地对草稿树中的 token 进行验证。对于每个 token,计算其接受概率,接受概率取决于草稿模型和目标模型的输出概率。
-
接受/拒绝:如果某个 token 被拒绝,那么该 token 的所有子节点都会被丢弃。
-
重采样:如果某个 token 被拒绝,那么会根据目标模型的输出重新采样该 token。
-
合并:最终,被接受的 token 会被合并成一个序列,作为最终的输出。
-
-
输出:被接受的 token 序列。
损失函数
Eagle含三个模块,其中只有Autoregression Head需要训练,Eagle在feature层和token层进行自回归,那么自然地我们可以把我们的目标拆成两块儿,即feature准不准,token准不准:
-
针对feature准不准,可以比较从Autoregression Head出来的feature与从target model出来的对应feature相近程度,因为feature本身是一个向量,所以可以用L1 loss:
-

-
针对token准不准,可以比较LM_head由两个feature推理token的差异,所以可以用交叉熵损失,即:
-

- 最终的损失是这两个损失的加权和 ,其中权重系数平衡了这两个损失值的数量级差异。
实验结论
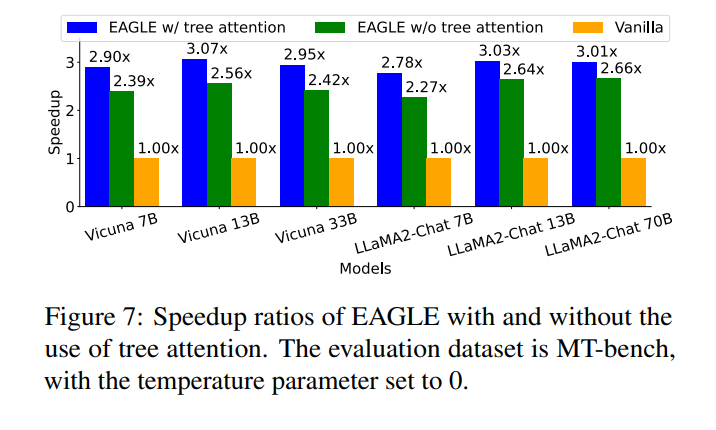
- EAGLE 是一种高效的投机采样框架,它通过在特征层进行自回归并解决采样过程中的不确定性,显著提高了 LLM 的推理速度。可以应用于多种 LLM 模型,并在各种任务中都表现良好。可以与其他加速技术相结合,进一步提升生成速度。训练成本较低,并且对训练数据不敏感。
三、系列eagle 论文简要概述
1. EAGLE-1:Speculative Decoding 加速框架
摘要
- EAGLE(Extrapolation Algorithm for Greater Language-model Efficiency) 是一个用于加速大语言模型自回归推理的无损推理加速机制,它通过预测特征(而非直接预测 token)来提升推理效率。(arXiv, Hugging Face)
工作机制
-
利用模型倒数第二层的特征向量作为输入,让一个轻量级插件 Auto-regression Head 预测下一个时刻的特征。
-
使用原模型冻结好的分类头从 predicted feature 输出 token。
-
在不修改模型和输出分布的前提下,实现推理速度显著提升(如 Vicuna 13B 上速度提升约 2.7--3.5 倍)
2. EAGLE-2:动态草稿树机制加速
创新点
- 引入 context-aware dynamic draft tree,通过草稿模型生成的置信度动态调整 speculated tokens 的验证结构。
EAGLE2 是在EAGLE-1 基础上的改进版本,专注于动态草稿树来提高推理速度,删除了一些草稿模型自己都认为不自信的结果, 直接输出结果。最后测试结果 EAGLE2 在无损的情况下会比 EAGLE1 快 20%-40%。
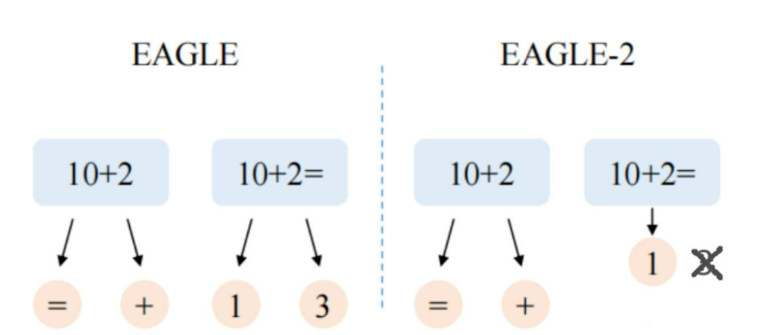
论文给出的 motivation 是因为发现草稿模型的接受率不仅依赖位置,是依赖于语境的,如果语境是动态变化的,那么原来 eagle1 中的静态树结构是不能适应的。
Eagle1 和 Medusa 在所有上下文中使用相同的静态草图树结构,在草图阶段的第 i 步,添加 k 个 candidate,但是 k 是固定的也就是静态的,构建好的 tree attention 再一次性运算,但是显然 k 在实际情况中不是固定的,而草稿小模型的作用应该可以把部分 k 去掉。这样可以进一步减少目标模型的 batch 大小,虽然都是一次前向推理就可以搞定整个 attention ,但是减小 batch 还是有意义的。
同时,因为 eagle1 中的草案模型置信度概率和草案令牌接受率的分布是非常接近的,所以 eagle2 里的置信度就可以直接使用了,动态调整草案树结构,增加接受令牌的数量。论文的基本逻辑就出来了,也挺妙的。
3. EAGLE-3:Training-Time Test 与多层特征融合
创新点
-
不再依赖单一特征预测,而是通过 training-time test 方法实现直接 token 预测,并通过融合多层语义特征来提高准确性与鲁棒性。
-
推理速度最高可达原始的 6.5 倍,比 EAGLE-2 再提升约 1.4×。(arXiv, Hugging Face)
总览表
|--------------|---------|----------------------------------|----------------------------|
| 模型/方法 | 方向 | 核心贡献 | 加速效果 / 优势 |
| EAGLE (v1) | 推理加速 | 特征级 speculative decoding,低成本加速推理 | 2.7×--3.5× 提速 |
| EAGLE-2 | 动态优化版本 | 引入置信度驱动草稿树结构动态调整 | 3×--4.2× 提速,比 v1 多 20--40% |
| EAGLE-3 | 提升模型融合 | 弃用特征预测,采用 token 预测结合融合多层特征 | 最快达 6.5×,比 v2 多 ~1.4× |
| Eagle Router | 多模型路由管理 | Training-free 路由,结合 ELO 排名选择最优模型 | 高效稳定,初始化 / 更新速度极快 |
四、附录
1 EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty https://arxiv.org/pdf/2401.15077