DeepSeek-Math-V2解读:稠密Reward信号回归到RLVR
最近半年博主工作科研比较繁忙,有段时间没有写博客了,但并不代表博主没有更新相关技术,后续会补上更多科研信息。
今天详细解读一下前段时间发布的DeepSeek-Math-V2,DeepSeek-Math早在24年带有GRPO这个广为流传的RLVR技术,那么憋了一年后的V2版有什么看点呢?
最近一系列的RL算法都关注ORM,即只要结果正确就认为整个推理过程正确,这种方式在AIME、HMMT等一系列高难度的数学任务上被验证有效。但是其依然存在一些问题:
- 模型最终虽然可以给出正确答案,但是推理过程可能会存在逻辑错误;
- 仅靠结果作为反馈,很难适用于定理证明类等对推理过程准确性强依赖的任务;
因此,如何能够有效验证推理过程,对ATP类任务至关重要。主要动机包括:
- 即使没有参考解决方案,人类也能识别证明中的问题------这在解决开放性问题(即答案未知的任务)时至关重要。
- 如果经过大规模验证仍无法识别出任何问题,则该证明更可能有效。
- 识别有效问题所需的工作量可以作为证明质量的指标,并可用于优化证明生成。
基于Verifier,实现Proof Generator和Verifier协同更新: - 利用验证反馈优化证明生成;
- 扩展验证计算能力以自动标记难以验证的新证明,从而创建训练数据以改进验证器本身;
- 利用改进后的验证器进一步优化证明生成。此外,可靠的证明验证器能够教会证明生成器像验证器一样评估证明。这使得证明生成器可以迭代地改进其证明,直到无法识别或解决任何问题为止。
本质上,我们让模型明确地感知其奖励函数,并使其能够通过深思熟虑的推理而非盲目的试错来最大化该奖励。
本文提出DeepSeek-Math-V2,基于DeepSeek-V3.2-Exp-Base模型进行训练,并得到natural language theorem proving模型,该模型拿到了IMO25、CMO24的金牌、Putname上得到118/120分。
一、方法
Proof Verification
采用cold-start + RL的recipe来训练Verifier。Verfier的任务定义如下:
给定一个problem和proof,verifier输出三个等级得分:
- 1.0表示生成的proof完全正确;
- 0.5表示proof整体逻辑正确,但是包含一些细小的错误;
- 0表示整体步骤逻辑错误;
Cold Start数据构建
- 爬取AoPS、相关的数学olympiad数据、team selection task和post-2010相关涉及到proof的数据,总共17503个query;
- 使用DeepSeek-V3.2-Exp-Thinking模型生成proof,由于该模型并没有专门优化过proof,因此输出内容偏向于简短且包含逻辑错误的proof,因此,采用多轮迭代来进行改进;
- 按照algebra、number theory等领域进行随机采样,并采样一些proof,并邀请人工按照1.0-0.5-0三个等级来对proof进行打分;
为此,获得了可用于训练Verifier的RL数据集,每个数据包含problem、proof和对应人工的打分;
RL prompt数据的指令格式如下
text
## Instruction Your task is to evaluate the quality of a solution to a problem. The problem may ask for a proof of statement , or ask for an answer . If finding an answer is required , the solution hould present the answer , and it should also be a rigorous proof of that answer being valid .
Please evaluate the solution and score it according to the following criteria :
- If the solution is completely correct , with all steps executed properly and clearly demonstrated , then the score is 1
- If the solution is generally correct , but with some details omitted or minor errors , then the score is 0.5
- If the solution does not actually address the required problem , contains fatal errors , or has severe omissions , then the score is 0
- Additionally , referencing anything from any paper does not save the need to prove the reference . It ' s okay IF AND ONLY IF the solution also presents a valid proof of the reference argument ( s ) ; otherwise , if the solution omits the proof or if the proof provided is not completely correct , the solution should be scored according to the criteria above , and definitely not with a score of 1
Please carefully reason out and analyze the quality of the solution below , and in your final response present a detailed evaluation of the solution ' s quality followed by your score . Therefore , your response should be in the following format :
Here is my evaluation of the solution: ... // Your evaluation here. You are required to present in detail the key steps of the solution or the steps for which you had doubts regarding their correctness , and explicitly analyze whether each step is accurate : for correct steps , explain why you initially doubted their correctness and why they are indeed correct ; for erroneous steps , explain the reason for the error and the impact of that error on the solution .
Based on my evaluation , the final overall score should be: \\boxed {{...}} // where ... should be the final overall score (0, 0.5 , or 1 , and nothing else ) based on the above criteria
--
Here is your task input:
## Problem
{question}
## Solution
{proof}RL训练
基于DeepSeek-V3.2-Exp-SFT模型(在math、code等推理任务上进行SFT的模型)进行RL训练。RL的目标是让模型能够对proof生成proof analysis。Reward信号包含:
- Format:约束Verfier模型输出summary和proof score。如果模型输出包含"Here is my evaluation of the solution:"以及"Based on my evaluation, the final overall score should be:"和带有boxed的得分,则Format为1分;
- Score reward:Verifier模型输出的boxed中的打分假设为si′s_i'si′,人工标注的打分为sis_isi,reward则表示为Rscore(si′,si)=1−∣si′−si∣R_{score}(s_i', s_i)=1-|s_i'-s_i|Rscore(si′,si)=1−∣si′−si∣。即如果模型预测分数与人类打分完全一样,reward则为1,打分差异越大,reward越小,最小为0。
最终RL训练目标如下:
maxπϕE(Xi,Yi,si)∼Dv′(Vi′,si′)∼πϕ(⋅∣Xi,Yi)Rformat(Vi′)⋅Rscore(si′,si)\max_{\pi_{\phi}}\mathbb{E}{(X_i, Y_i, s_i)\sim\mathcal{D}{v'}(V_i', s_i')\sim\pi_{\phi}(\cdot|X_i, Y_i)}R_{format}(V_i')\\cdot R_{score}(s_i', s_i)πϕmaxE(Xi,Yi,si)∼Dv′(Vi′,si′)∼πϕ(⋅∣Xi,Yi)Rformat(Vi′)⋅Rscore(si′,si)
Meta-Verification
考虑到一个问题,假设Verifier在评估proof时,其在打分方面很容易预测正确(即预测打分能够与人类保持一致),但是生成的proof analysis可能会有问题,例如分析错误,或者臆想不存在的问题等情况;
因此提出meta-verification,来对verfier生成的proof analysis进行二次校验,确保verifier所分析的问题确实可靠。
Meta Verifer的prompt如下所示:
text
You are given a "problem", "solution", and "solution evaluation", and you need to assess the whether this " solution evaluation " is reasonable .
First , "solution evaluation" is generated to evaluate the quality of the " solution " , by prompting a verifier with the rules below ( these are not your rules ) :
'''
Please evaluate the solution and score it according to the following criteria :
- If the solution is completely correct , with all steps executed properly and clearly demonstrated , then the score is 1
- If the solution is generally correct , but with some details omitted or minor errors , then the score is 0.5
- If the solution does not actually address the required problem , contains fatal errors , or has severe omissions , then the score is 0
Additionally , referencing anything from any paper does not save the need to prove the reference . It ' s okay IF AND ONLY IF the solution also presents a valid proof of the reference argument ( s ) ; otherwise , if the solution omits the proof or if the proof provided is not completely correct , the solution should be scored according to the criteria above , and definitely not with a score of 1
'''
Next , I will introduce the rules for you to analyze the quality of the " solution evaluation ":
1. Your task is to analyze the "solution evaluation". You do not need to solve the " problem " , nor do you need to strictly assess whether the " solution " is accurate . Your only task is to strictly follow the rules below to evaluate whether the " solution evaluation " is reasonable .
2. You need to analyze the content of the "solution evaluation" from three aspects :
Step Restatement: In the "solution evaluation", certain behaviors of the " solution " may be restated . You need to return to the original text of the " solution " and check whether the " solution " actually has these behaviors mentioned in the " solution evaluation ".
Defect Analysis: "solution evaluation" may point out errors or defects in the " solution ". You need to carefully analyze whether the mentioned errors and defects are indeed valid .
Expression Analysis: Whether the "solution evaluation"'s expressions are accurate .
Score Analysis: Whether the final score given by the "solution evaluation " matches the defects it found . You need to analyze according to the scoring rules given above .
3. The most important part is **defect analysis **: In this part , your core task is to check whether the errors or defects of the " solution " pointed out in the " solution evaluation " are reasonable . In other words , any positive components about the " solution " in the " solution evaluation " , regardless of whether they are reasonable , are not within your evaluation scope .
- For example: If the "solution evaluation" says that a certain conclusion in the " solution " is correct , but actually this conclusion is incorrect , then you do not need to care about this point . All parts that the " solution evaluation " considers correct do not belong to your evaluation scope .
- Specifically: If the "solution evaluation" believes that the " solution " is completely accurate and has not found any errors or defects , then regardless of whether the " solution " itself is actually accurate , even if there are obvious errors , you should still consider its analysis of errors to be reasonable . ** Importantly**, for defects found by the "solution evaluation", you need to analyze two points simultaneously :
- whether this defect actually exists
- whether the "solution evaluation"'s analysis of this defect is accurate These two aspects constitute the analysis of defects. 4. About ** expression analysis**, if there are certain expression errors in the " solution evaluation " , even minor errors in details , you need to identify them . However , please note that identifying incorrect steps in the " solution " as correct steps does not constitute an ** expression error **. In practice , expression errors include but are not limited to:
- If the "solution evaluation" identifies some reasoning step(s) in the " solution " as incorrect , then it cannot further indicate that subsequent conclusion ( s ) depending on those reasoning step ( s ) are wrong , but can only indicate that subsequent conclusion ( s ) are " not rigorously demonstrated ."
- Typos and calculation errors made by "solution evaluation"
- Inaccurate restatement of content from "solution" 5. Finally , you need to present your analysis of the "solution evaluation " in your output and also rate its quality based on the rules below : First , if there is at least one unreasonable defect among the defects found by the " solution evaluation " , then you only need to do ** defect analysis **:
- If all defects found by the "solution evaluation" are unreasonable , then you should rate it with \(0\)
- If some defects found by the "solution evaluation" are reasonable and some are unreasonable , then your rating should be \(0.5\) Next , if the "solution evaluation" points out no errors or defects , or all defects found by the evaluation are reasonable , then you should do the following things :
- Analyze whether "expression errors" exist in the "solution evaluation " (** expression analysis **) or whether " solution evaluation " gives a wrong score according to the rules for " solution evaluation " (** score analysis **) . If yes , you should rate the " solution evaluation " with \(0.5\) ; if no , your rating should be \(1\)
Your output should follow the format below:
Here is my analysis of the "solution evaluation":
... // Your analysis here. Based on my analysis , I will rate the "solution evaluation" as: \\boxed {{...}} // where ... should be a numerical rating of the " solution evaluation " (0 , 0.5 , or 1 , and nothing else ) based on the criteria above .
--
Here is your task input:
## Problem
{question}
## Solution
{proof}
## Solution Evaluation
{proof analysis}Meta-Verifier也通过RL来进行训练,训练过程如下:
- 给定一个problem、proof,首先获得verifier生成的proof analysis和score;
- 邀请人类专家,对proof analysis进行打分,从而得到标注的数据集,每条数据包含problem、proof、proof analysis、proof score以及人类对analysis的打分结果;
- RL训练与Verifier一样,包含format和score reward
当训练完Meta-Verifier RL后,再次训练Verifier RL,此时Verifier RL除了format RformatR_{format}Rformat和score rewardRscoreR_{score}Rscore外,还添加Meta-Verifier的反馈得分RmetaR_{meta}Rmeta,最终Verifier RL的reward为:
RV=Rformat⋅Rscore⋅RmetaR_V=R_{format}\cdot R_{score}\cdot R_{meta}RV=Rformat⋅Rscore⋅Rmeta
在增强Verifier训练过程中,同时也融入Meta-Verifier的数据,为此最终的Verifier不仅可以对proof进行analysis和打分,也能过对proof analysis进行打分。
最终Verifier同时具备生成proof analysis和score,以及meta-verification的能力。
Proof Generator
Proof Generator RLVR
Verifier可以视为一个GRM(Generative Reward Model),在此基础上来训练Proof Generator。Proof Generator的RL训练可以视作最大化Verifier对其的打分:
maxπθEXi∼Dp,Yi∼πθ(⋅∣Xi)RY\max_{\pi_{\theta}}E_{X_i\sim\mathcal{D}p, Y_i\sim\pi{\theta}(\cdot|X_i)}R_YπθmaxEXi∼Dp,Yi∼πθ(⋅∣Xi)RY
Enhancing with Self-Verification
一般情况下,IMO、CMO等高难度题,Proof Generator模型通常难以一次性解决。
为此,参考之前的Self-verification,即将Verifier作为一个tool,模型在生成proof的时候,未必一次性能够成功,因此可以在Verifier的反馈下不断修改proof。
然而,在实践中发现一个问题,RL训练完的Proof Generator,一次性生成的proof可能依然存在错误,虽然Verifier能够清晰的指出错误并反馈给Generator,但Generator可能依然声称其证明没有问题。
换句话说,Proof Generator虽然会根据Verifier的反馈结果来更新proof,但不会像Verifier那样对自己的生成结果进行严格评估,从而容易出现"自以为是不理会"的情况。
为此,Proof Generator在RL训练时也有必要使用Verifier RL训练是所用的策略。
Proof Generator的prompt如下所示:
text
Your task is to solve a given problem. The problem may ask you to prove a statement , or ask for an answer . If finding an answer is required , you should come up with the answer , and your final solution should also be a rigorous proof of that answer being valid .
Your final solution to the problem should be exceptionally comprehensive and easy - to - follow , which will be rated according to the following evaluation instruction :
'''txt
Here is the instruction to evaluate the quality of a solution to a problem . The problem may ask for a proof of statement , or ask for an answer . If finding an answer is required , the solution should present the answer , and it should also be a rigorous proof of that answer being valid .
Please evaluate the solution and score it according to the following criteria :
- If the solution is completely correct , with all steps executed properly and clearly demonstrated , then the score is 1
- If the solution is generally correct , but with some details omitted or minor errors , then the score is 0.5
- If the solution does not actually address the required problem , contains fatal errors , or has severe omissions , then the score is 0 Additionally , referencing anything from any paper does not save the need to prove the reference . It ' s okay IF AND ONLY IF the solution also presents a valid proof of the
reference argument ( s ) ; otherwise , if the solution omits the proof or if the proof provided is not completely correct , the solution should be scored according to the criteria above , and definitely not with a score of 1
'''
In fact , you already have the ability to rate your solution yourself , so you are expected to reason carefully about how to solve a given problem , evaluate your method according to the instruction , and refine your solution by fixing issues identified until you can make no further progress .
In your final response , you should present a detailed solution to the problem followed by your evaluation of that solution .
- To give a good final response , you should try your best to locate potential issues in your own ( partial ) solution according to the evaluation instruction above , and fix them as many as you can .
- A good final response should just faithfully present your progress , including the best solution you can give , as well as a faithful evaluation of that solution .
- Only when you fail to locate any issues in your solution should you score it with 1.
- If you do notice some issues in your solution but fail to resolve them with your best efforts , it ' s totally ok to faithfully present the issues in your final response .
- The worst final response would provide a wrong solution but lie that it ' s correct or claim that it ' s correct without careful error checking . A better version should faithfully identify errors in the solution . Remember ! You CAN ' T cheat ! If you cheat , we will know , and you will be penalized !
Your final response should be in the following format:
## Solution // Your final solution should start with this exact same markdown title ... // Your final solution to the problem here. You should try your best to optimize the quality of your solution according to the evaluation instruction above before finalizing it here .
## Self Evaluation // Your evaluation of your own solution above should start with this exact same markdown title
Here is my evaluation of the solution: // Your analysis should start with this exact same phrase
... // Your evaluation here. You are required to present in detail the key steps of the solution or the steps for which you had doubts regarding their correctness , and explicitly analyze whether each step is accurate : for correct steps , explain why you initially doubted their correctness and why they are indeed correct ; for erroneous steps , explain the reason for the error and the impact of that error on the solution . You should analyze your solution faithfully . E . g . , if there are issues in your final solution , you should point it out .
Based on my evaluation , the final overall score should be: \\boxed {{...}} // where ... should be the final overall score (0, 0.5 , or 1 , and nothing else ) based on the evaluation instruction above . You should reach this score ONLY AFTER careful RE - examination of your own solution above
--
Here is your task input:
## Problem
{question}从prompt中可以发现,Proof Generator不仅需要生成proof,还需要像Verifier一样自己给出self-analysis和score。
在Self-verification增强训练过程中,首先让Proof Generator生成一个proof,以及self-analysis和score,此时的self-analysis和score与Verfier遵循相同的format和rubrics规则。
- 假设Proof Generator生成的proof表示为YYY,同时生成的self-analysis表示为zzz,score表示为s′s's′。
- Verfier对Proof Generator生成的Proof YYY也会给出一个得分,表示为sss;
- Meta-Verification对Proof Generator所生成的self-analysisZZZ会给一个meta score,表示为msmsms;
那么,对于Proof Generator的reward可以设计为:
其中
● RY=sR_Y=sRY=s
● Rz=Rscore(s′,s)⋅Rmeta(Z)R_z=R_{score}(s', s)\cdot R_{meta}(Z)Rz=Rscore(s′,s)⋅Rmeta(Z)
● Rmeta=msR_{meta}=msRmeta=ms
● Rscore(s′,s)=1−∣s′−s∣R_{score}(s', s)=1-|s'-s|Rscore(s′,s)=1−∣s′−s∣
● α=0.76,β=0.24\alpha=0.76, \beta=0.24α=0.76,β=0.24;
通过这个Reward,可以发现:
- Proof Generator生成的self-analysis首先需要符合format要求(0或1分);
- 如果Proof Generator自己生成的self-analysis和score越大,那么reward越高,且这部分在总的reward占比比较大(0.76);
- 确保Proof Generator生成的self-analysis要正确,这部分reward来自两方面,一方面是Proof Generator自己给出的score要与Verifier给出的score尽可能一样,差距越小,reward越大;另一方面,Proof Generator生成的self-analysis也要通过meta-verification的校验打分。
Proof Verification与Generation的协同优化
Verifier可以比较好得指导Generator生成高质量的proof,但是Verifier有时候会遇到问题,当Proof Generator生成的proof,Verifier无法在一次尝试内正确判断,最直接的做法是不断让人工介入来对这些proof进行标注,但比较耗时费力。
为此提出一个pipeline来尝试auto labeling verification数据:
- 对于每个Proof,使用Verfier生成 n 个独立的proof analysis。
- 对于每个proof analysis(得分 0 或 0.5),生成 m 个meta-verification,以验证已识别的问题。如果大多数meta-verification证实了proof analysis结果,则该proof analysis被认为是有效的。
- 对于每个proof,检查得分最低的proof analysis。如果至少有 k 个这样的proof analysis被认为是有效的,则将该proof标记为该最低分。如果在所有验证尝试中均未发现任何合法问题,则将该证明标记为 1。否则,该证明将被丢弃或提交给专家进行标注。
Proof Verification与Generation交替训练,最后两轮训练时则完全剔除掉人工标注环节。
二、实验
(1)训练细节
RL算法选择GRPO,进行多轮迭代训练。
- 对于每一轮,首先优化Verification,获得优化后的Verifier后,将该Verifier作为Proof Generator的初始化参数,并进行Generator优化;
- 从第二轮开始,每一轮的Verifier则是由上一轮优化完的Generator作为初始化(此时Generator是同时包含Verification、Meta-verification和proof generation能力),在verifier优化前会加入rejected fine-tuning(RFT)阶段。
(2)评测数据集
内部评测数据:91条
外部数据:
● IMO25(6条);
● CMO24(6条);
● Putnam24(12条);
● ISL24(31条);
● IMO-ProofBench(60条);
(3)评测方法
One-shot Generation
评估模型一次性输出proof的性能。每个problem生成8个proof,并分别送入verifier,并得到verification结果,每个proof都生成8次analysis,最终进行投票来判定proof是否正确。
in-house评测数据上的指标如下:
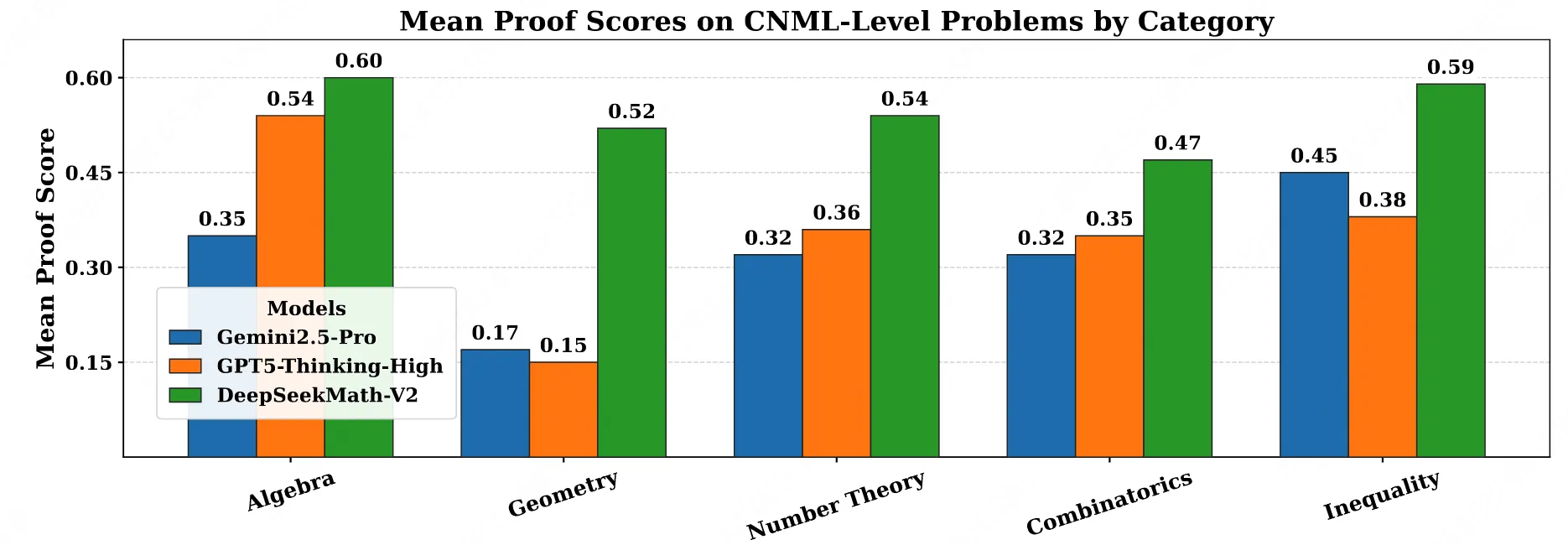
self-verification
带有self-verification的生成过程如下:
● 首先生成一个proof,以及对应的self-analysis;
● 基于problem、已经生成的proof以及self-analysis,进行re-prompt,并输入到Generator进行再次思考。
re-prompt如下所示:
text
{proof_generation_prompt}
## Candidate Solution(s) to Refine
Here are some solution sample(s) along with their correctness evaluation ( s ) . You should provide a better solution by solving issues mentioned in the evaluation ( s ) , or by re using promising ideas mentioned in the solution sample ( s ) , or by doing both .
{proof}
{proof analyses}
## Final Instruction Your final response should follow the format above , including a '## Solution ' section followed by a '## Self Evaluation ' section模型在推理时不断进行self-verification,直到自己给自己的score达到1分,或者达到轮次上限。
在评测时,对于每个problem,生成32条refinement轨迹,对于每条轨迹最终输出的proof,使用最终训练好的verifier进行32次评估,并取投票的结果作为proof的打分。
- pass@1:每个problem的32条轨迹,verifier所给的得分的均值;
- best@32:每个problem的32条轨迹中,根据generator自己生成的self-analysis的得分,取得分最高的轨迹,该轨迹对应verifier的得分;
实验如下图所示,可以发现: - 随着refinement的轮次增长,整体指标也在上升;
- Best@32始终大于Pass@1,说明通过self-analysis自己打分所挑选的proof更有效,也侧面说明generator的Self-analysis是可靠的
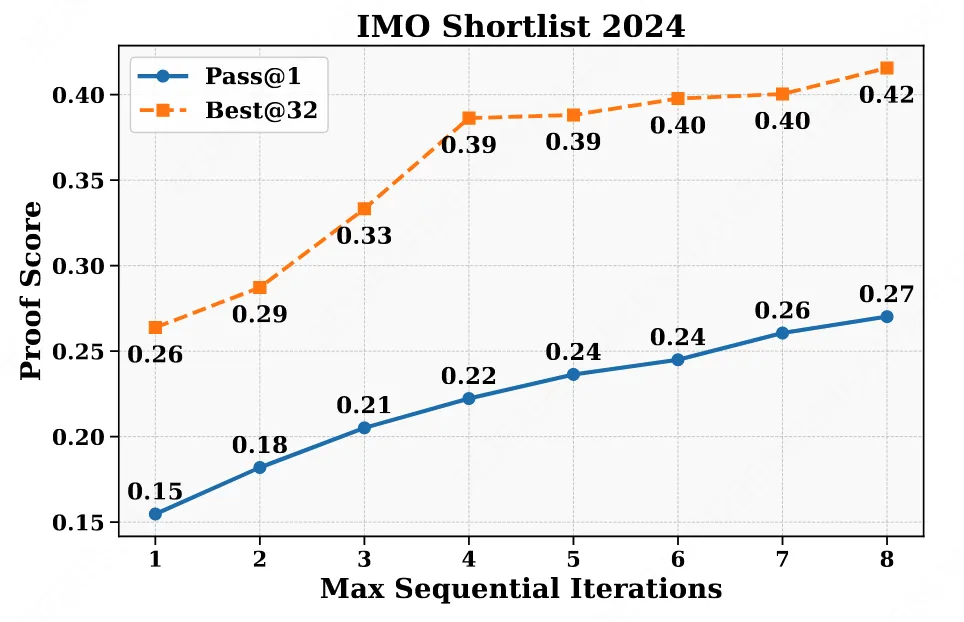
Hign-comput Search模式
该模式下是为了刷榜IMO、CMO榜单。扩展了验证和生成计算能力------利用广泛的验证来识别细微问题,并利用并行生成来探索不同的证明策略。
具体方法如下:
- 为每个problem维护一个候选proof pool,初始时包含 64 个proof,每个proof都生成了 64 个analysis。下面进行多轮的self-verification,随着refinement轮次进行,proof pool会不断新增更多的proof;
- 在每次refinement轮次中,根据平均验证得分选择 64 个得分最高的proof,并将每个proof与 8 个随机选择的analysis配对,优先考虑那些识别出问题的分析(得分为 0 或 0.5)。每个(proof,analysis)pair用于生成一个改进后的proof,然后将改进后的proof更新到pool中。此过程最多持续 16 次迭代,或者直到某个证明成功通过所有 64 次验证尝试,表明其正确性具有很高的置信度。所有实验均使用单个模型,即我们最终的Proof Generator,该模型同时执行Proof生成和Verification。