目录
- [1、系统可用性:别只盯着"几个 9"](#1、系统可用性:别只盯着“几个 9”)
-
- 一、可用性的两种计算方式
- 二、时间维度:从"宕机时长"出发
- 三、请求维度:从"成功率"出发
- [四、几个 9,怎么定?](#四、几个 9,怎么定?)
- 五、回顾
- [2、SLI 与 SLO,稳定性的第一步](#2、SLI 与 SLO,稳定性的第一步)
-
- [一、SLI 和 SLO 是什么?](#一、SLI 和 SLO 是什么?)
- [二、如何选择合适的 SLI?](#二、如何选择合适的 SLI?)
- [三、如何设定合理的 SLO?](#三、如何设定合理的 SLO?)
- [四、SLO vs SLA](#四、SLO vs SLA)
- 五、回顾
1、系统可用性:别只盯着"几个 9"
在上一讲里我们聊到,SRE 是一套体系化工程,核心目标就是两个:提升 MTBF,降低 MTTR。说得直白一点,就是尽量减少故障发生,同时让系统出问题时能更快恢复。
那问题来了------我们到底用什么来衡量"系统稳定性"?业界最常见的答案就是:可用性(Availability)。
你肯定听过所谓的 "三个 9" (99.9%) 、"四个 9" (99.99%) 这些说法。听起来很炫,但要真正用好"可用性"这个指标,很多团队其实理解得并不一致。今天我们就花一节课,把"系统可用性"聊透。
一、可用性的两种计算方式
目前业界有两种主流计算方式:
-
时间维度
Availability = \\frac{Uptime}{Uptime + Downtime}
也就是系统运行的正常时间 / 总时间。
-
请求维度
Availability = \\frac{Successful , Request}{Total , Request}
也就是成功请求数 / 总请求数。
这两个公式都很简单,但背后的含义却不一样。
二、时间维度:从"宕机时长"出发
这是最常见的方式。比如说,一年 365 天,如果系统有 3.65 天不可用,那就是 99% 可用性。
下表是常见的"几个 9"和对应的故障时间:
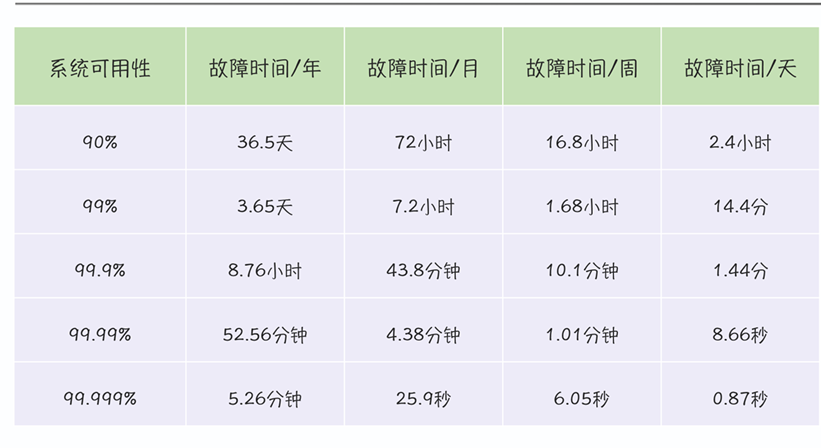
可以看到,从 99% 到 99.999%,差距非常大。比如 99.9%(三个 9) ,一年可以停机 8.76 小时;而 99.999%(五个 9) ,一年只能容忍 5 分钟 故障。
不过,时间维度的缺点也很明显:它只关注"大故障",但对那些频繁的小异常几乎无感。
想象一下,一个系统每天短暂抖动几秒钟,虽然总 Downtime 不多,但对用户体验来说其实很糟糕。这就是时间维度不够精细的地方。
三、请求维度:从"成功率"出发
为了更精细化,很多团队会用请求维度来算可用性。
举个例子:某系统一天有 100,000 次请求,如果失败 5001 次,成功率就是 94.999%,低于 95% 的阈值,那就算系统不可用。
这种方式的优点是更贴近用户感受:哪怕只有几秒钟的异常,如果影响了请求成功率,也会被记录下来。
所以总结一句话:
- 时间维度关注"宕机时长";
- 请求维度关注"用户体验"。
四、几个 9,怎么定?
那么,到底要定多少个 9 才算"合格"?
其实没有统一答案,要看三个因素:
-
成本
可用性越高,成本越高。要上"双活""多活",资源和运维投入都会翻倍。不是所有公司都能承担。
-
业务容忍度
核心业务(支付、交易)容不得闪失,至少要"三个 9"甚至"四个 9"。
非核心业务(评论、评分)则可以容忍低一些。
-
系统现状
不要一口气定得太高。比如现在只有 98%,那先冲到 99%,再逐步提升。目标太高反而打击团队信心。
五、回顾
- 两种可用性计算方式:时间维度、请求维度;SRE 更偏好请求维度,因为它覆盖了更多"不稳定"的情况。
- 几个 9 不是越多越好,要结合成本、业务重要性和系统现状来设定。
- 记住一句话:故障一定意味着不稳定,但不稳定不一定意味着故障。
把"系统可用性"这个指标聊清楚了,它是理解 SLI(服务等级指标) 和 SLO(服务等级目标) 的基础。
在 SRE 的实践中,我们不只是看系统有没有大故障,而是要更全面地衡量运行状态,把"不稳定"也纳入考虑范围。下一讲,我们就会正式进入
SLI/SLO 的世界。
2、SLI 与 SLO,稳定性的第一步
聊了"几个 9",但光有"几个 9"还不够,因为没有明确的指标和目标,我们就无法衡量和改进系统的稳定性。这就是为什么 SRE 强调 SLI 和 SLO。
上面复盘了系统可用性的两种计算方式:
- 时间维度:从宕机时长出发;
- 请求维度:从成功请求占比出发
并且我们说过,在 SRE 实践中,更推荐使用 请求维度,因为它更贴近用户体验。
那问题来了:如果要用请求维度来衡量稳定性,就需要回答两个问题:
- 我们到底监控哪些指标?
- 这些指标要达到什么目标,才算"稳定"?
这两个问题的答案,就是今天的主角:SLI 和 SLO。
一、SLI 和 SLO 是什么?
-
SLI(Service Level Indicator,服务等级指标)
我们用来衡量系统稳定性的指标。
-
SLO(Service Level Objective,服务等级目标)
给这些指标设定的目标值,比如"成功率 ≥ 99.95%"。
👉 举个例子:
在电商系统的购物车服务(trade_cart)中:
- "状态码非 5xx 的比例" 就是 SLI;
- "大于等于 99.95%" 就是 SLO。
一句话:SLO 是 SLI 要达到的目标。
二、如何选择合适的 SLI?
监控指标成百上千,哪些能做 SLI?我们要抓住两个原则:
-
能否直接反映主体的稳定性?
如果主体是应用层,就优先选择应用层的指标,而不是 CPU 使用率这种系统层指标。
-
是否与用户体验强相关?
成功率、延迟、错误率,这些用户能感知的指标优先。
快速选择方法:Google 的 VALET
Google 提供了一个非常实用的方法 ------ VALET:
- V (Volume 容量):QPS/TPS、吞吐能力
- A (Availability 可用性):请求成功率、任务成功率
- L (Latency 时延):响应速度,例如"95% 请求 ≤ 200ms"
- E (Error 错误率):错误码比例、业务异常
- T (Tickets 人工介入):人工干预次数
👉 VALET 是 SLI 选择的"快速备忘单",覆盖了最关键的五个角度。
三、如何设定合理的 SLO?
有了指标,还得设定目标。常见有两种方式:
-
单一条件
比如:Successful = (状态码非 5xx) & (时延 <= 80ms) Availability = Successful / Total
缺点是过于死板。
- 组合条件(推荐)
- SLO1:99.95% 请求状态码成功率
- SLO2:90% 请求时延 ≤ 80ms
- SLO3:99% 请求时延 ≤ 200ms
只有全部满足,系统才算达标。
👉 这种方式更灵活,也能避免平均值掩盖极端情况。
四、SLO vs SLA
这里要特别区分一下:
- SLO:工程目标,团队内部用来约束和改进。
- SLA(Service Level Agreement):商业承诺,对客户的合同保障,违约要赔偿。
所以:SLO 更细,SLA 更宽松。
五、回顾
- SLI 是指标,SLO 是目标;
- SLI 要能直接反映主体稳定性,并和用户体验挂钩;
- Google VALET 是快速识别 SLI 的方法论;
- 设定 SLO 时推荐组合条件,而不是单一条件;
- SLO 面向内部,SLA 面向外部。