名人说:博观而约取,厚积而薄发。------苏轼《稼说送张琥》
创作者:Code_流苏(CSDN) (一个喜欢古诗词和编程的Coder😊)目录
- [一、什么是DeepSeek V3.1?为什么这么火🚀](#一、什么是DeepSeek V3.1?为什么这么火🚀)
- [1. 发布时间线回顾](#1. 发布时间线回顾)
- [2. 核心创新点](#2. 核心创新点)
- 二、技术原理揭秘:一个模型如何拥有两个大脑?
- [1. 混合推理架构详解](#1. 混合推理架构详解)
- [2. 参数精度的黑科技](#2. 参数精度的黑科技)
- 三、性能表现:真的能打过Claude吗?
- [1. 编程能力测试](#1. 编程能力测试)
- [2. 搜索和推理能力](#2. 搜索和推理能力)
- [3. 效率提升的秘密](#3. 效率提升的秘密)
- 四、上手体验:如何玩转V3.1的双重人格?
- [1. 官方体验入口](#1. 官方体验入口)
- [2. 使用技巧](#2. 使用技巧)
- [3. API使用示例](#3. API使用示例)
- 五、商业化策略:免费午餐要结束了?
- [1. 价格调整时间表](#1. 价格调整时间表)
- [2. 开源策略持续](#2. 开源策略持续)
- 六、未来展望:智能体时代真的来了吗?
- [1. 技术趋势分析](#1. 技术趋势分析)
- [2. 给开发者的建议](#2. 给开发者的建议)
- 总结
很高兴你打开了这篇博客,更多AI知识,请关注我、订阅专栏《AI知识图谱》,内容持续更新中...
大家好👋,我是流苏
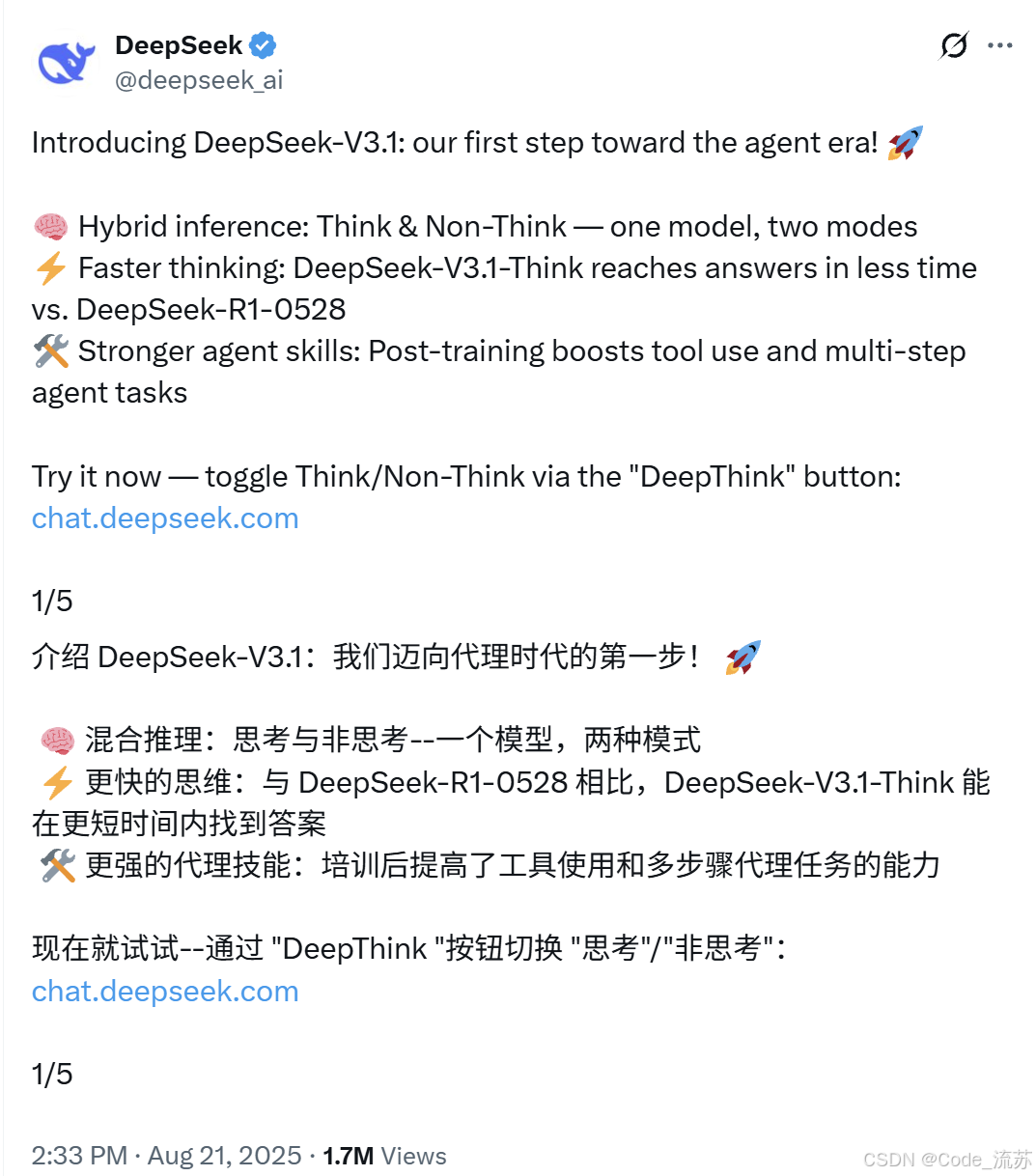
2025年8月21日,国产AI再次刷屏! DeepSeek低调发布V3.1,混合推理架构让人眼前一亮,成本降低60倍,据说性能部分超越Claude?这到底是什么神仙操作,是如何设计的,我们一起来看看!
一、什么是DeepSeek V3.1?为什么这么火🚀
还记得今年年初DeepSeek R1横空出世,让全球AI圈都震惊的场面吗?现在,DeepSeek又来"搞事情"了!
DeepSeek V3.1 可以说是DeepSeek家族的"集大成者",它最牛的地方就是实现了"一个模型,两种大脑"的神奇操作。
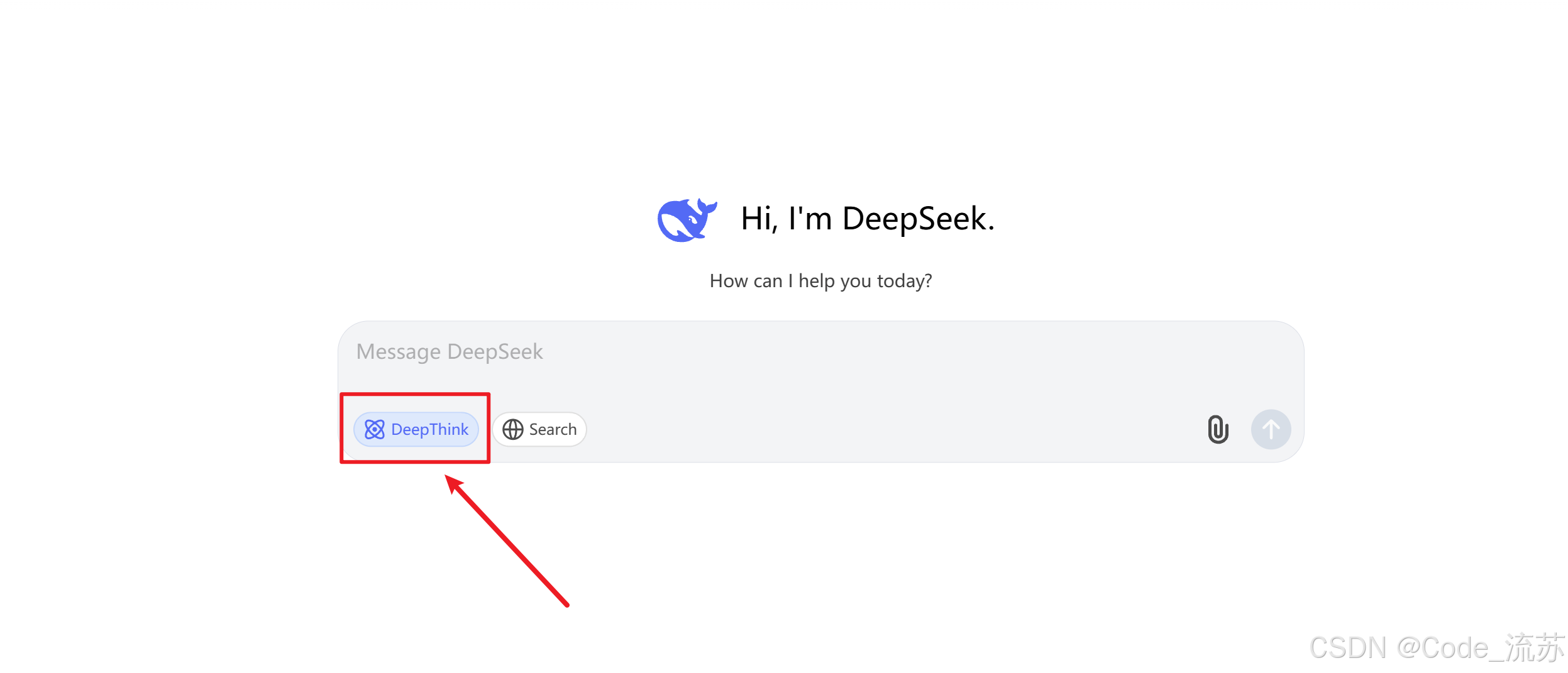
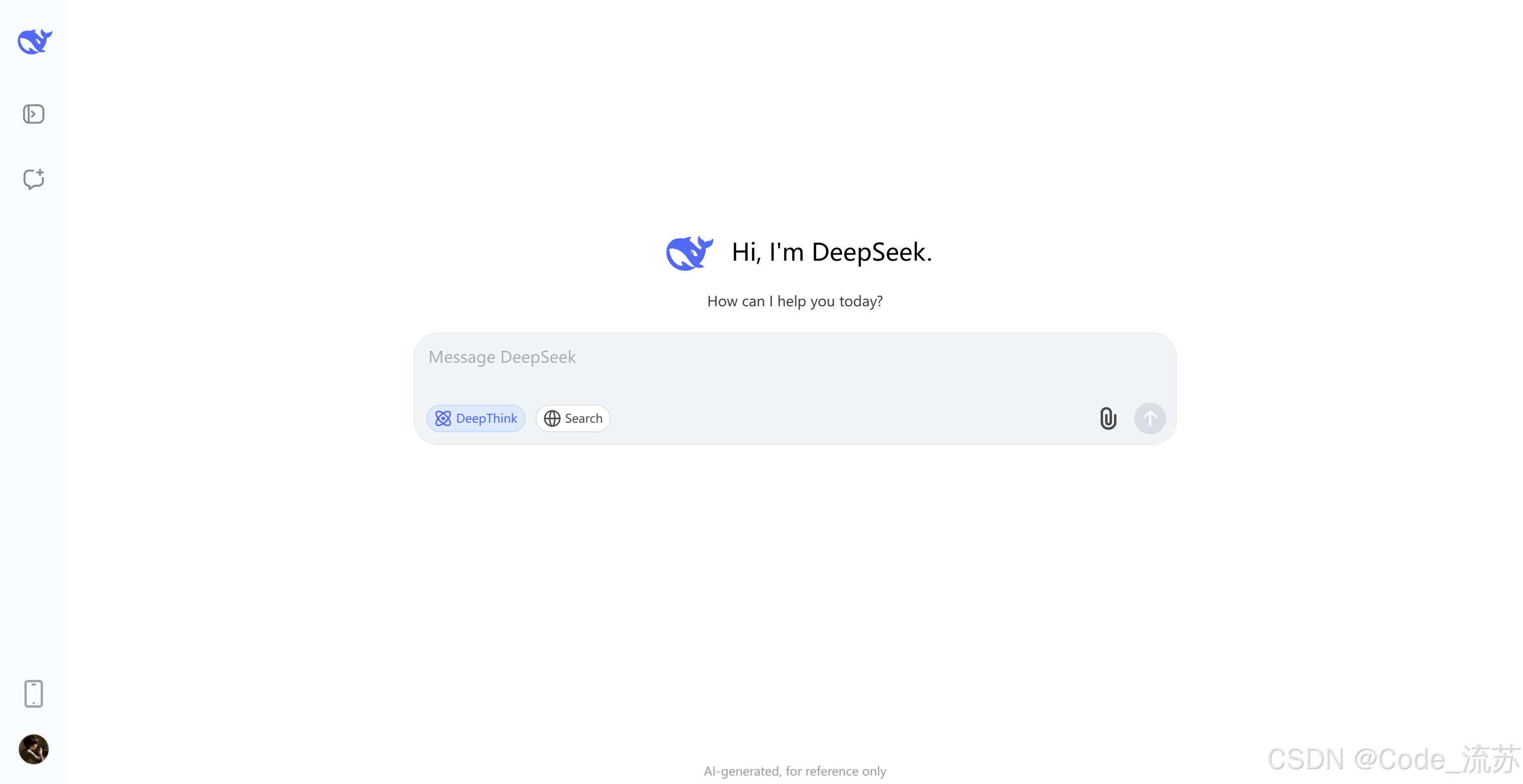
在官网对话聊天框下方可以看到,现在已经出现了DeepThink模式,打开DeepThink就会进入思考模式,关闭就是非思考常规模式。
官网: https://chat.deepseek.com/
1. 发布时间线回顾
- 8月20日晚:DeepSeek悄悄上线V3.1
- 8月21日下午:正式宣布发布
- 发布当天:直接冲上HuggingFace(HF)趋势榜第三名
HF首页 :https://huggingface.co/deepseek-ai/DeepSeek-V3.1
2. 核心创新点
想象一下,如果你的大脑可以随时在"快思考"和"慢思考"之间切换,会是什么感觉?V3.1就做到了这一点:
- 🧠 快思考模式:日常聊天、快速问答
- 🤔 慢思考模式:复杂推理、深度分析
这种混合推理架构 让一个模型可以"因题制宜",该快的时候快,该深的时候深!
二、技术原理揭秘:一个模型如何拥有两个大脑?
1. 混合推理架构详解
传统的AI模型就像是"单核处理器",只有一种工作模式。而V3.1更像是"双核处理器":
传统模型:问题 → 单一推理 → 答案
V3.1模型:问题 → 选择模式 → 快思考/慢思考 → 答案技术实现机制:
- API端点分离 :
deepseek-chat(快思考)+deepseek-reasoner(慢思考) - 统一模型架构:底层共享685B参数,上层分化推理路径
- 智能切换 :用户可通过 "深度思考(DeepThink)" 按钮随时切换

2. 参数精度的黑科技

官推评论区,官方运营特意强调:V3.1使用了UE8M0 FP8 Scale参数精度,这听起来很技术,其实就是为了后面使用国产芯片做准备:
- 🎯 专门为国产芯片优化:提前适配下一代国产AI芯片
- ⚡ 计算效率更高:更少的存储空间,更快的计算速度
- 💡 前瞻性布局:为国产硬件生态建设贡献力量
三、性能表现:真的能打过Claude吗?
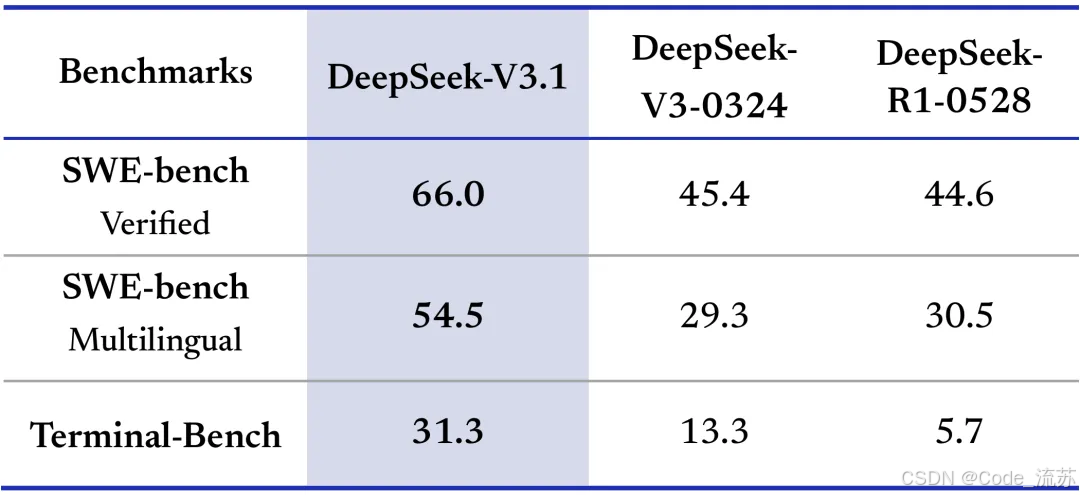
1. 编程能力测试
在AiderPolyglot多语言编程测试中,V3.1交出了令人惊艳的成绩单,成本优势惊人:完成同样的编程任务,V3.1编程性能比Claude 4高1%,成本要低68倍。

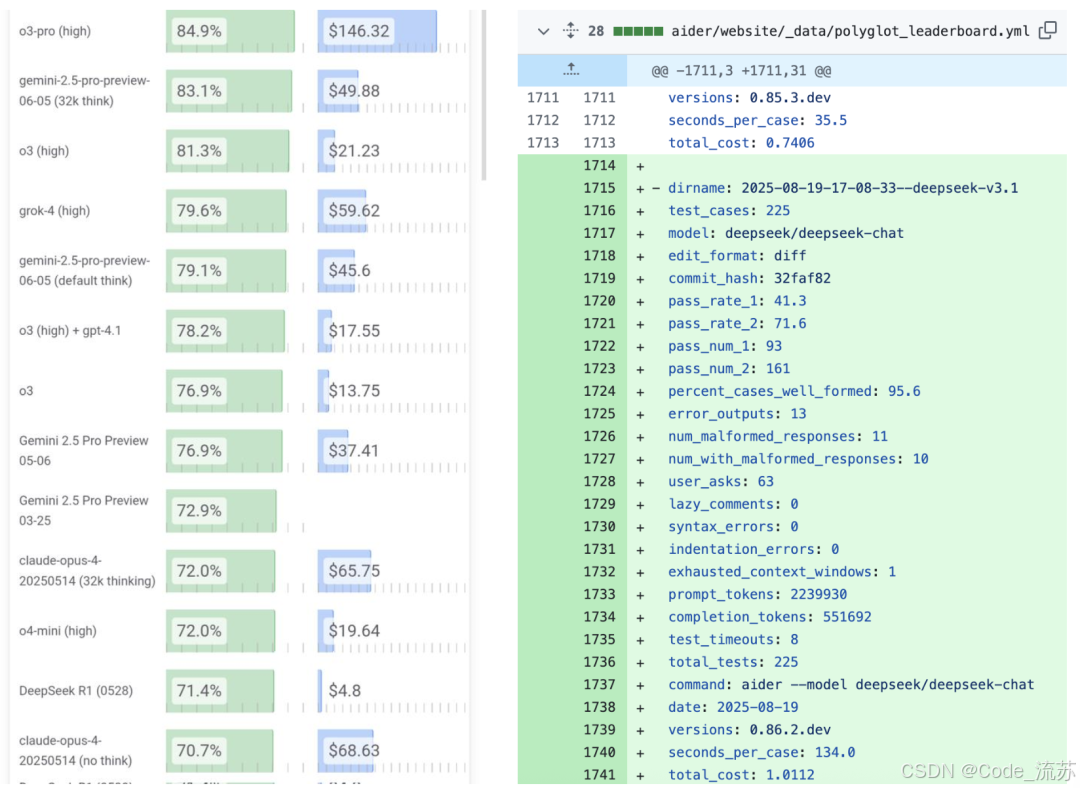

对于编程智能体,相对于前代的能力提升明显,这也是官方说的迈向Agent时代的第一步中的一部分!
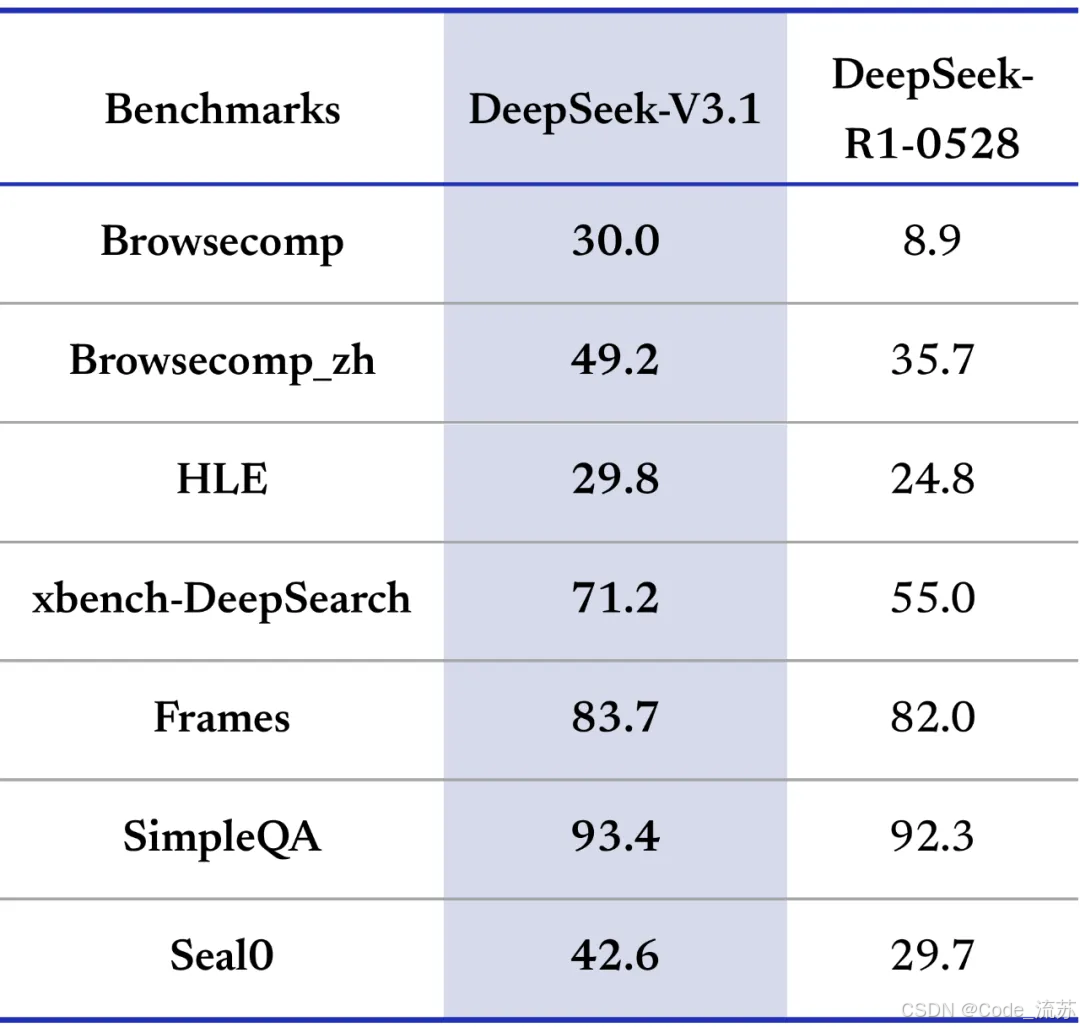
2. 搜索和推理能力
在复杂搜索测试中,V3.1展现出了强大的多步推理能力:
- browsecomp测试:需要多步推理的复杂搜索,大幅领先前代
- HLE测试:多学科专家级难题,性能显著提升
- Terminal-Bench:命令行环境复杂任务,表现出色
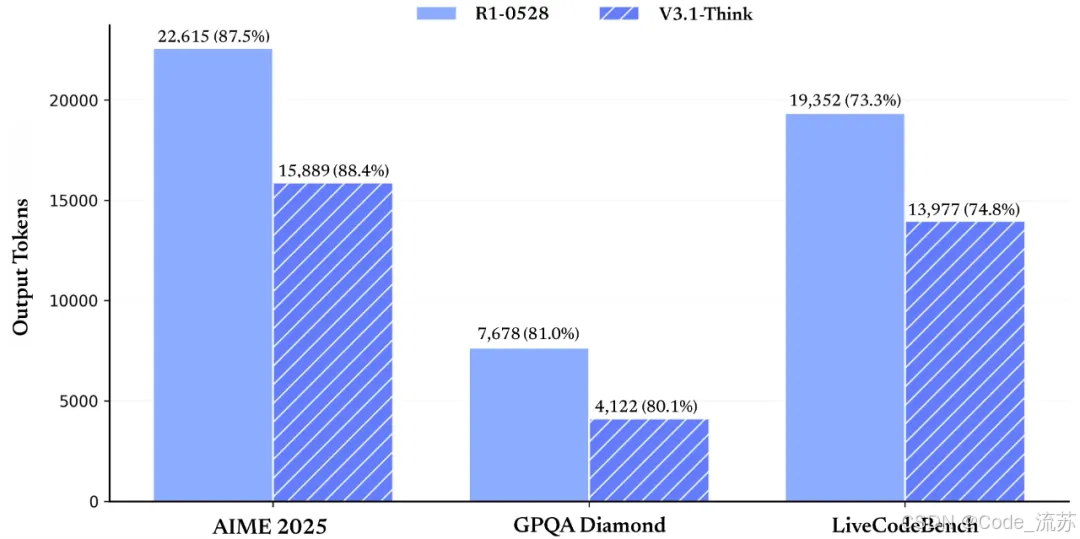
3. 效率提升的秘密
思考效率革命性提升:
- Token消耗量减少20%-50%
- 保持相同任务表现的同时,"思考"更快了
- 相比V3-0324版本,整体token使用量下降13%
四、上手体验:如何玩转V3.1的双重人格?
官推中,官方运营特别回复,目前已在各平台更新,只是新模型自我认知为DeepSeek-V3。

1. 官方体验入口
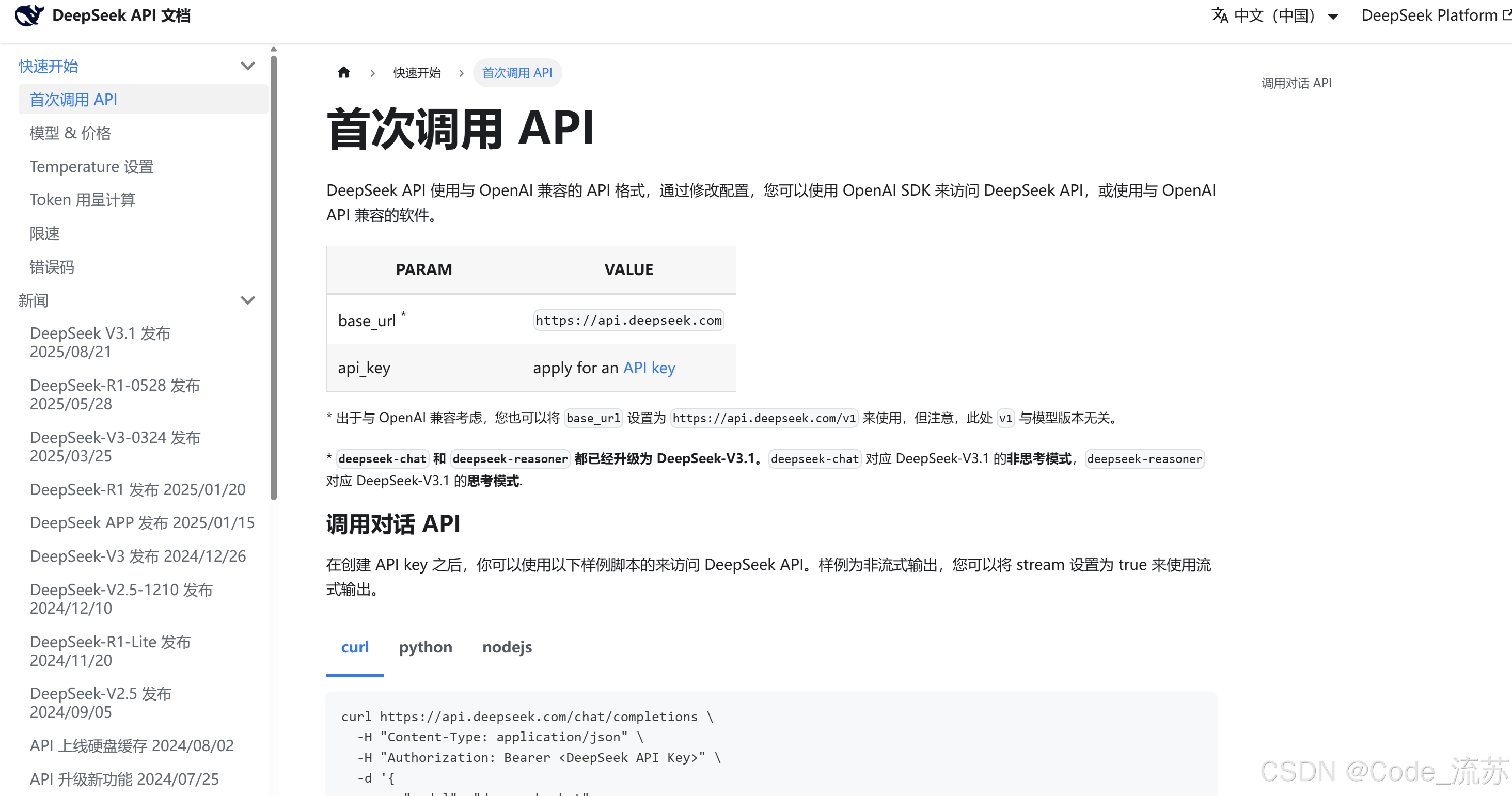
- 网页版 :https://chat.deepseek.com
- 移动App:已同步升级到V3.1
- API接口:支持128K上下文窗口
2. 使用技巧
1️⃣何时使用快思考模式?
取消这里的选择即可。

适用场景:
- 日常闲聊
- 快速问答
- 简单代码解释
- 翻译任务
2️⃣何时切换到慢思考模式?
这里选择即可。

适用场景:
- 复杂数学问题
- 逻辑推理题
- 多步骤编程任务
- 深度分析报告
3. API使用示例
python
# 快思考模式
response = client.chat.completions.create(
model="deepseek-chat", # 快思考
messages=[{"role": "user", "content": "写个Hello World"}]
)
# 慢思考模式
response = client.chat.completions.create(
model="deepseek-reasoner", # 慢思考
messages=[{"role": "user", "content": "证明哥德巴赫猜想"}]
)五、商业化策略:免费午餐要结束了?

1. 价格调整时间表
重要时间节点:2025年9月6日凌晨
新定价标准:
- 输入:0.5元/百万tokens(缓存命中),4元/百万tokens(缓存未命中)
- 输出:12元/百万tokens
- 取消夜间时段优惠(之前夜间可享受50%-75%折扣)

2. 开源策略持续
尽管商业化加速,DeepSeek依然坚持开源路线:
开源地址:
- Hugging Face:https://huggingface.co/deepseek-ai/DeepSeek-V3.1

开源范围:


六、未来展望:智能体时代真的来了吗?
1. 技术趋势分析
V3.1的发布释放了几个重要信号:
1️⃣混合推理将成为标配
- 单一模式已经不能满足复杂需求
- "因题制宜"的智能分配将成为主流
- 效率和效果的平衡是关键
2️⃣Agent能力成为核心竞争力
- 工具调用能力不断增强
- 多步骤任务执行更加可靠
- 自主决策能力持续提升
2. 给开发者的建议
1️⃣适合使用V3.1的场景:
- 成本敏感的商业应用
- 需要频繁工具调用的智能体开发
- 中文优化要求较高的项目
2️⃣需要谨慎考虑的场景:
- 对推理准确性要求极高的任务
- 需要最前沿性能的科研项目
总结
DeepSeek V3.1的发布标志着AI模型设计理念的重要转变:从单一模式向混合架构演进,从通用能力向智能体特化发展。
虽然在某些方面还有提升空间,但其成本优势、开源策略和本土化特色让它在AI生态中占据了重要地位。对于国产AI来说,这不仅是技术实力的展现,更是向智能体时代迈进的重要一步。
最后的最后:如果你还在犹豫要不要试试V3.1,建议趁着9月6日价格调整前,先体验一波!说不定你会发现,这个"双重人格"的AI比你想象的更有趣呢~
📝 本文参考资料:DeepSeek官方发布公告、Hugging Face模型页面、社区测试数据
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)