Agentic RAG 是当前 LLM 应用中一个非常火热的方向。与传统 RAG 不同它让模型在推理过程中自主决定要不要检索、什么时候检索。这样就相当于给模型一套工具让它自己判断该用哪个。
目前训练 Agentic RAG 的主流做法是结果监督强化学习:只在推理结束后给一个标量奖励:对就是对、错就是错,而过程中完全没有任何反馈。
这种方式有几个明显的问题:
模型必须跑完整个推理链才能拿到分数,中途即使跑偏了也没法纠正;奖励信号极其稀疏,模型根本不知道哪些步骤有用、哪些是在浪费时间;而且单一的全局分数太粗糙了,没法告诉模型到底是哪个环节出了问题,想做细粒度优化几乎不可能。
DecEx-RAG 的核心思路
DecEx-RAG 把 RAG 建模成一个马尔可夫决策过程(MDP),分成决策和执行两个阶段。
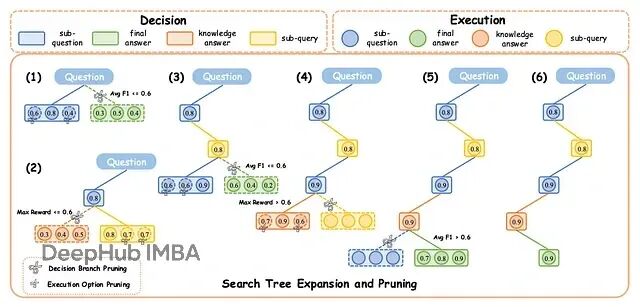
图1:DecEx-RAG 框架示意图,展示搜索树的扩展与剪枝过程
决策阶段解决两个问题:该停还是该继续?如果继续的话用内部知识还是去检索外部信息?每一步模型都要做出终止决策 σₜ 和检索决策 δₜ。
执行阶段关注的是生成质量。不管是子问题还是最终答案,都要求高质量输出。这个阶段用过程级奖励来优化。
而剪枝策略是 DecEx-RAG 的一大亮点:搜索树扩展太快会导致计算量爆炸所以需要动态剪枝,每一层做多次 rollout 模拟不同决策,把结果汇总成中间奖励;超过一半样本认为该停就停;如果内部知识生成的答案分数够高,直接跳过检索。
实测效果也是相当不错的,平均扩展时间从 743.2 秒压缩到 134.9 秒,快了将近 6 倍性能却几乎没有损失。
MDP 建模的技术细节
状态 S 是增量构建的,每一步都在历史中累积原始问题、子问题和对应的答案或检索文档。动作 A 包含两部分:终止决策 σₜ 决定继续还是停止,检索决策 δₜ 决定用内部知识还是发子查询拿外部文档。状态转移 P 也直接:停止就输出答案,不停就把新的子问题和结果加进历史继续走。
奖励 R 的计算方式是对给定(状态,动作)对做多次 rollout,然后取正确性分数的均值:
R(sₜ, aₜ) = (1/n) × Σ v(rolloutᵢ)
这里有两个设计值得注意,子问题和子查询是分开优化的,因为措辞上的微小差异可能导致检索结果天差地别。另外决策和执行被解耦了:决策数据用于提升效率,执行数据用于改善输出质量。
剪枝机制
生成过程监督数据非常耗时,DecEx-RAG 的剪枝机制在这里起了关键作用。
终止通过采样投票决定:每一步多次采样模型决策超过 50% 同意停止就终止迭代,而分支评分则是对每个子问题做 rollout 模拟,算平均分,只留表现最好的分支进入下一层。还有一个省算力的设计就是如果纯靠内部知识的答案分数超过预设阈值,检索直接跳过。

图2:三种扩展方法对比。k 为每个决策的执行分支数,n 为 rollout 次数,l 为层深。
理论上这种剪枝把复杂度从指数级拉到了线性级。在实际测试中单问题扩展时间从 743.2 秒降到 134.9 秒,6 倍提速而且可以保证性能不降。
训练流程
第一步是监督微调(SFT):从搜索树中抽取根到叶的最优推理链用来做标准监督学习。模型输入是推理步骤序列,输出是下一个最佳动作------可能是子问题、答案或子查询。
第二步是直接偏好优化(DPO):剪枝前模型会生成多组候选决策和执行结果,把这些配对保存下来用于偏好训练,让模型学会区分好的和不够好的选择。
实验结果
测试在六个开放域问答数据集上进行:HotpotQA、2WikiMultiHopQA、Bamboogle、PopQA、Natural Questions(NQ)、AmbigQA。
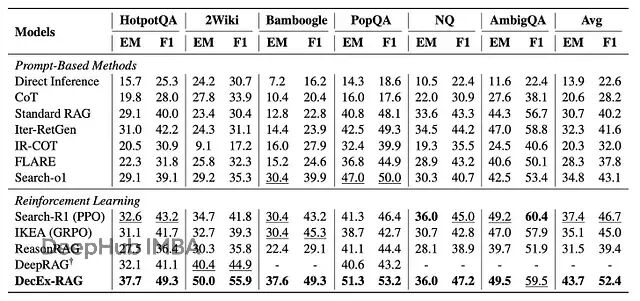
图3:DecEx-RAG 与基线方法在六个数据集上的表现。最佳/次佳分数分别用粗体/下划线标注
DecEx-RAG 拿下了最好成绩,平均 EM 43.7、F1 52.4,在所有基线中领先。
复现所需的工程细节
策略模型方面,检索相关决策用 Qwen2.5--7B-Instruct,其他决策步骤跑在 Qwen3--30B-A3B 上。知识库是 2018 年的维基百科转储,训练数据从 HotpotQA 抽了 2,000 条,WikiMultiHopQA 抽了 1,000 条。
总结
DecEx-RAG 最值得肯定的地方在于把推理过程结构化了。决策和执行的分离、分层剪枝的引入,把搜索复杂度从指数级压到近乎线性,对效率和扩展性都是实质性的改进。
不过也有一些可以改进的地方,比如当前系统依赖硬编码的启发式规则:"超过半数 rollout 投票停止就停"、"内部答案超过固定阈值就跳过检索"。这类规则在噪音或不确定性较大时容易出问题,可能会遇到过于激进提前终止或者过于保守浪费计算的情况。一个可能的改进方向是学习信息价值(VOI)函数,根据不确定性或预期收益动态决定是否继续检索而不是靠写死的阈值。
用多次 rollout 的平均 EM/F1 作为奖励信号,逻辑上没问题但存在一个不匹配:模型可能中间步骤一塌糊涂,最后碰巧蒙对了答案,照样拿高分。这样一来过程中的错误就没机会被纠正,不过增加 rollout 次数可以缓解这个问题,但成本会快速上升。更稳健的做法是引入双值基线或值加权 rollout,减少对最终结果的过度拟合。
论文:
https://avoid.overfit.cn/post/7c93c6c1703f491e8d68f8156abecfef
作者:Florian June