1、多维数据
推理引擎中会接触到多种类型的数据格式,比如NHWC、NCHW等,那这些数据格式该如何理解,它们的物理排布又是怎么样的呢?
首先,NHWC四个维度分别是怎么样的呢?
- H,高度
- W,宽度
- C,channel,假设一张图片,宽高很容易理解,图片中的一个像素会有raba等不同分量,C即是指不同的分量,针对一般图片而言,C等于4
- N,batch,可以简单理解为图片的数量
如果N = 2, C = 16, H = 5, W = 4,那么NCHW、NHWC两种格式的数据排布分别如下:
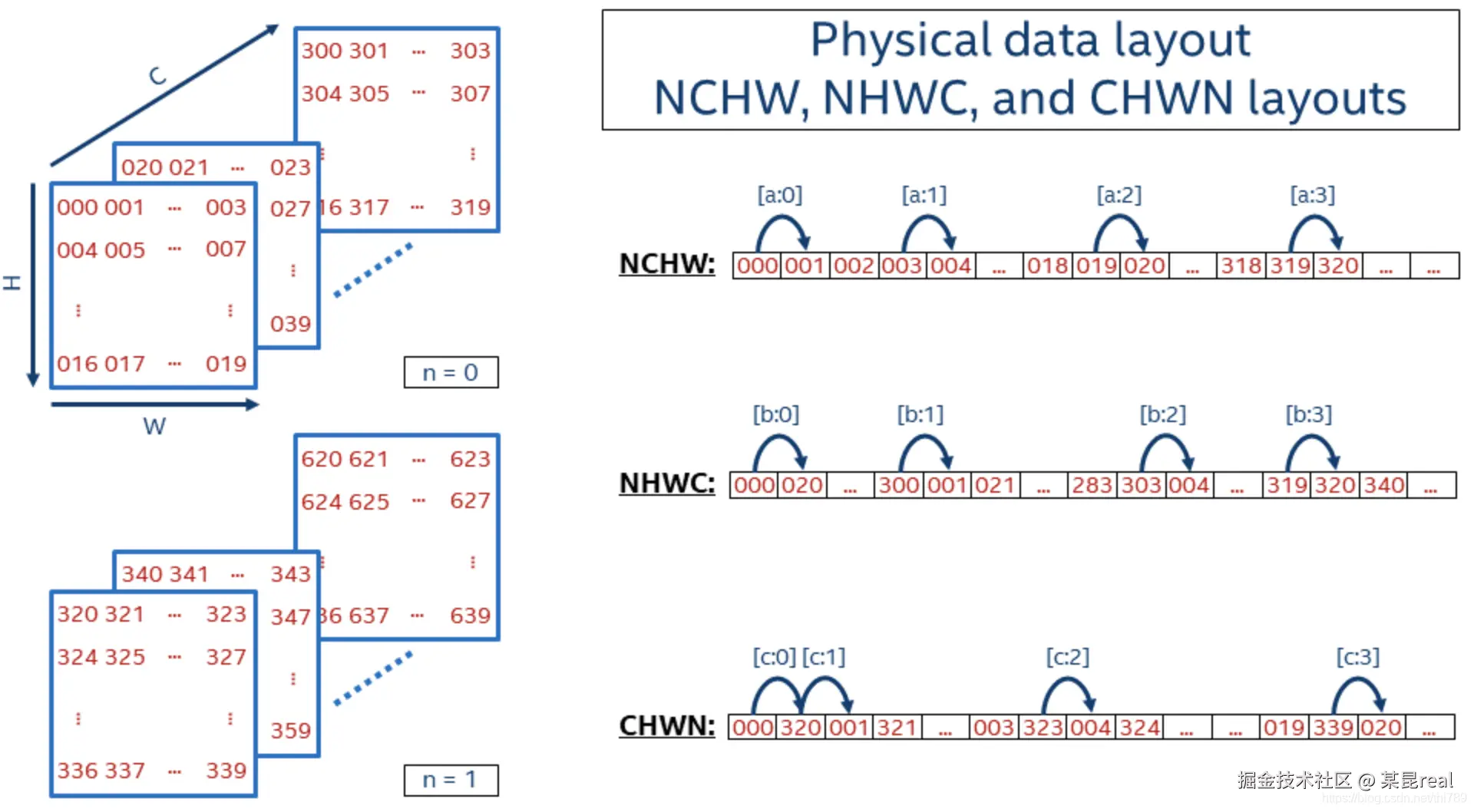
首先,不管是什么格式的数据,它们的物理排布,其实都是一维数组,就像是二维数组,其实也是一维数组实现的,排布也是一维数组。
其次,不论是何种格式,都是先排最后一个维度的数据,如上图,NHWC是一种比较费解的格式,但它其实也是先取最后一个维度C的16个数据,取完所有的16个C的数据,再把倒数第二个数组W移动一位,继续取所有C,即NHWC取数据,是按 C W H N的逆序取的。
举个例子,假设针对格式为NCHW,范围内的任意nchw,那它在一维数组的哪个位置呢?
ini
int stride_n = C * H * W * D,
stride_c = H * W * D,
stride_h = W * D,
stride_w = D;
int index = n * stride_n + c * stride_c + h * stride_h + w提个小问题,如果要把NCHW的数据转换成NHWC格式的数据,该怎么转呢?其实非常简单,对于索引固定的数据,nchw,它在一维数组中的位置是可知的,那同样的索引,nhwc,在一维数组中的位置也是可知的,赋值即可
2、image
在推理引擎中,要处理多维数据,那么核函数中是使用image更好,还是使用其它类型的数据更好呢?
一般而言,image数据有如下好处:
- 硬件加速缓存,GPU会为image数据提供纹理缓存
- 较为高效的内存方式模式,通道打包,一次可以存取4个通道数据
这种特性,比较好处理NCHW这种多维数据。所以一般推理引擎的核函数中,也是用image来处理数据。但它也有缺点,它的缺点就是数据格式较复杂,理解难度高
现在问题来了,要使用image处理张量数据,假设张量数据格式为NHWC,但image只有宽高两个维度,那要怎么对应的呢?
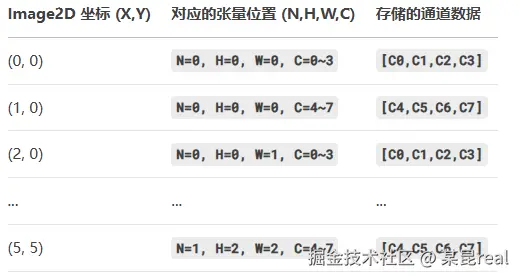
假设张量形状为 [N=2, H=3, W=3, C=8],其逻辑布局如下(以 N=0 为例):
| H/W | W=0 W=1 W=2 |
|---|---|
| H=0 | C0,C1,C2,C3,C4,C5,C6,C7 ... (共 3x8=24 个通道值) |
| H=1 | ... |
| H=2 | ... |
- 每个
(H,W)位置有 8 个通道值(C=0~7),内存中是连续的。 - N 维度 :不同批次的数据在物理内存中是连续存储的(
N=0后紧跟N=1)。
因为N和H是具有内存连续性的,同时W和C也是有内存连续性的,将N和H合并,W和C合并。
ini
image.h = N * H
image.w = W * C / 4为什么C要除以4呢,因为image天然有ragb四个通道
另外为什么一定要NH合并,WC合并呢,不能是其它数据合并吗?其实主要是从性能上考虑,WC、NH它们在内存上有连续性
注意,因为C/4可能出现0,必须确保C是4的倍数,如果不是,则需要补齐,C/4可以理解为C对4向上取整
以 N=2, H=3, W=3, C=8 为例,合并之后,image2d_t 的布局如下:
如果已经知道image中的x和y,那么怎么推算张量中的位置呢?

注意,最终的c值无法反推了,因为合并只是合并C4,而不是C,只能反推得到C4。
注意,如果使用image处理张量数据,NHWC的格式更适合image处理。而NCHW不适合image处理,因为image一次性就会取4个通道数据,契合NHWC。
3、最大池化算子实践
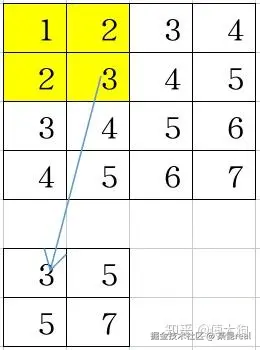
最大池化的计算方式比较简单,计算方式如下图所示:
现在要使用opencl的方式实现,核函数使用image处理数据,输入的数据的格式为NHWC
java
__kernel void max_pooling(
__read_only image2d_t input,
__write_only image2d_t output,
int out_img_width, int out_img_height,
int width, int height,
int kW, int kH,
int strideW, int strideH,
int outW, int outH, int channel_4
) {
int x = get_global_id(0);
int y = get_global_id(1);
// 边界检查
if (x >= out_img_width || y >= out_img_height) {
return;
}
int w_out = x / channel_4;
int c4 = x % channel_4;
int h_out = y % outH;
int n = y / outH;
int h0 = h_out * strideH;
int w0 = w_out * strideW;
printf("x %d, y = %d, w_out = %d, c4 = %d, h_out = %d, n = %d\n", x, y, w_out, c4, h_out, n);
float4 maxv = (float4)(-FLT_MAX);
const sampler_t sampler = CLK_NORMALIZED_COORDS_FALSE |
CLK_ADDRESS_CLAMP |
CLK_FILTER_NEAREST;
for(int kh = 0; kh < kH; ++kh) {
for(int kw = 0; kw < kW; ++kw) {
int h = h0 + kh;
int w = w0 + kw;
int scrX = c4 * width + w;
int scry = n * height + h;
float4 v = read_imagef(input, sampler, (int2)(scrX, scry));
maxv = max(maxv, v);
}
}
int dst_x = c4 * outW + w_out;
int dst_y = n * outH + h_out;
write_imagef(output, (int2)(dst_x, dst_y), maxv);
}- 首先,注意上面根据x、y反推张量位置的计算方式,和此前说法一致
- h0和w0,是输出窗口的起始位置,关于最大池化位置计算公式,大家可以自行百度,通过上述公式可以得到当前池化窗口的起始w和h值
- 然后就是遍历池化窗口宽高了,遍历找到当前窗口的最大值,找到之后再写入对应的位置
- 写入位置,也是image的位置,这里又涉及到从张量位置转换为x/y值