目录
[1. 项目背景](#1. 项目背景)
[2. 名词解释](#2. 名词解释)
[3. DeepSeek、ChatCPT、Gemini使用](#3. DeepSeek、ChatCPT、Gemini使用)
[3.1 产品和模型](#3.1 产品和模型)
[3.2 DeepSeek使用](#3.2 DeepSeek使用)
[3.3 ChatGPT](#3.3 ChatGPT)
[3.4 Gemini](#3.4 Gemini)
[4. 为什么学习通过API使用大模型](#4. 为什么学习通过API使用大模型)
[5. 项目演示](#5. 项目演示)
[6. 项目架构](#6. 项目架构)
1. 项目背景
从1994年接入互联网至今,中国互联网的发展历经了PC时代、移动互联网时代,尤其是在移动互联网时代进行了大量的海量数据、技术积累、以及硬件算力的巨大提升,之前不温不火的人工智能,伴随着ChatGPT的横空出现。
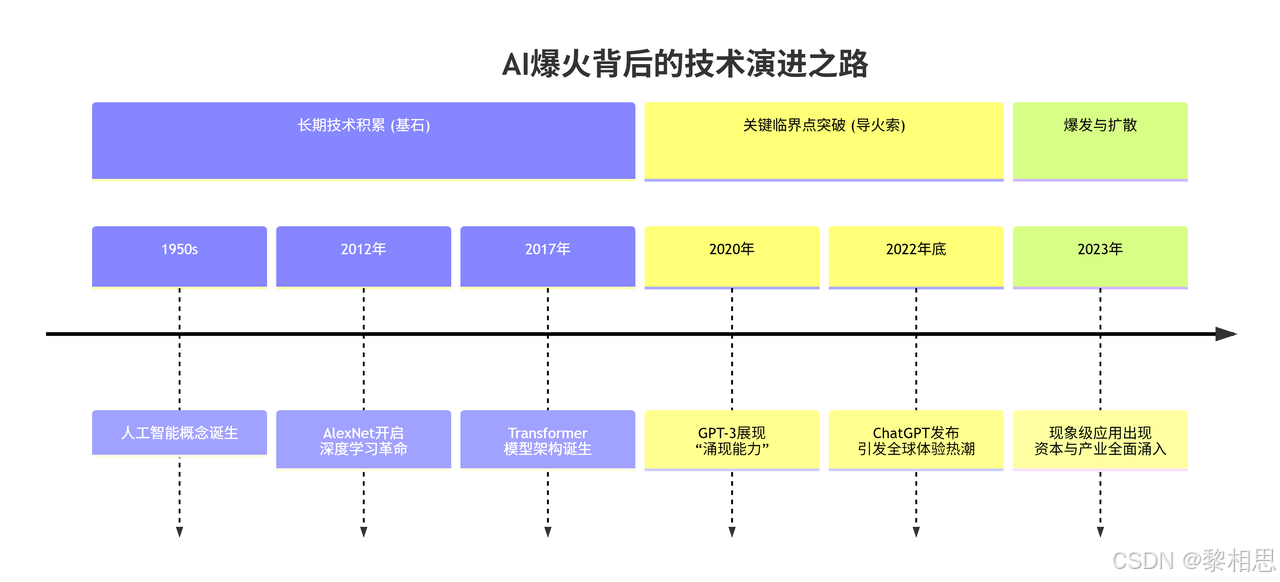
迎来了今天AI的爆火,各种大模型、智能体应用等如雨后春笋版涌现出来,AI在更进一步进入普通人的生活。现在各个厂商也在积极拥抱Al,作为程序员我们决不能停留在简单使用DeepSeek、ChatGPT这种大模型级别的产品,而应该去学习大模型应用背后的相关技术,将模型接入到我们程序中来,让AI为自己服务,提高生产效率。本项目就带领大家从底层学习如何接入大模型,这也是进行大模型开发的第一步。
本项目目标旨在:
- 掌握大模型相关的一些基础知识
- 掌握官网提供大模型的API接口的学习
- 掌握C++下远程接入大模型思路及技术实现
- 掌握C++下本地接入大模型的思路及技术实现
- 开发一套语言聊天大模型应用
2. 名词解释
有些同学可能对大模型了解不是很多,此处将项目中涉及到大模型相关名词提前解释,其他一些名词会在项目中详细给大家介绍:
【模型-Model】
此处模型专指AI领域的模型。可以简单理解成一个从大量数据中学习规律、用于进行预测的数学函
数,只是该函数参数巨多、无比复杂。
可以简单类比成一个正在学说话的小孩。
小孩通过耳朵输入海量的语音数据,比如:家人的口头教学、日常生活对话、读绘画本,通过眼睛去认识各种物品,比如家庭日用品、交通工具、动物、花花草草等,小孩通过大人的耳传身教不断学习成长,慢慢地就能听懂大人的指令,甚至模仿大人行为等,建立起自己的语言规则。
比如他发现,我们经常将"吃"和"饭饭"、"水果"连在一起,"睡觉觉"和"床"连在一起,
当给孩子说:宝宝太晚了,我们一起上床
宝宝就会说:睡觉觉~~~
【大模型-Large Model】
大模型就是AI里的超级学霸,参数巨多、知识量爆炸的AI模型,像吃了百科全书+全网数据的"六边形战士"。一个既能看懂你的照片(视觉),又能听懂你的指令(语音)还能用文字回答你的模型,就是大模型。大体现在:
。参数海量:GPT-3有1750亿个参数,而早期模型参数不到一百万。
。训练数据恐怖:吃掉整个互联网文本(书籍、论文、网页、代码...)
。训练一次GPT-3~190万度电(够5000个家庭用1年)
【大预言模型-Large Language Model-LLM】
大语言模型就是AI界的"超级话痨",是一个吃掉整个互联网的文本,能读会写、知识渊博的AI大脑,专门处理人类语言,比如聊天、协作、翻译、编程等,但可能会胡说八道。
将整个互联网的数据喂给大模型后,大模型会通过神经网络分析词语之间的关系,例如将"猫"、"喵喵叫"、"毛茸茸"词归类到一起,但是它并不理解,当人类在提问的时候它会推测出最可能得回答。
大模型的局限性
。可能会出现"幻觉"
。没有真正"理解"
。偏见与安全风险
【提示词-Prompt】
- 角色设定Role
"你是⼀个具有⼗年以上C++后端开发的架构师,请帮我设计类似微信的聊天软件"
问题描述
- 任务描述
"⽤200字总结导致拖延症原因"
- 格式约束
"请按要点分条列出,每条不超过15字"
【上下文-Content】
AI在对话或任务中临时记住的信息,像人类聊天时不会突然失忆,能联系前后文理解意思。
用户:推荐⼀部科幻电影
AI:《星际穿越》用户:为什么推荐这部?
AI(结合上下文):因为它的硬核科学设定和感人父女情...
模型不会记住所有上下文信息,超出部分会被丢弃,就想内存满了自动覆盖。
比如GPT-4最多能记住128k tokens,大约10万字。
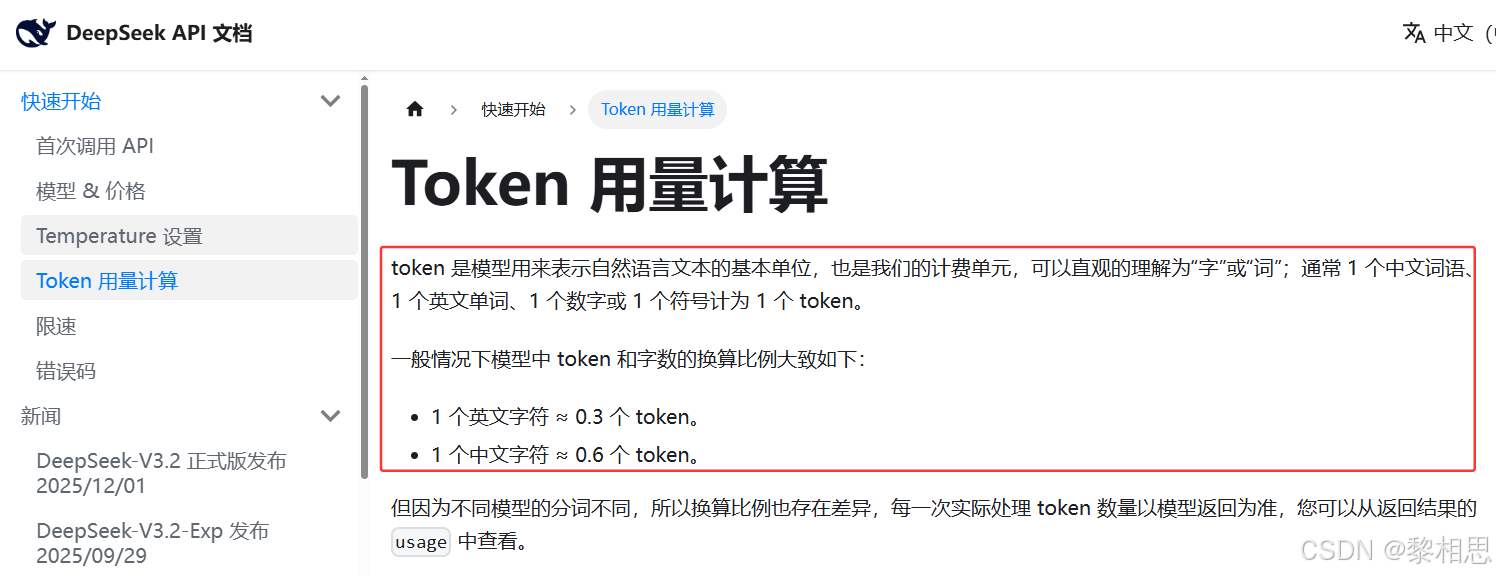
【token】
token是模型用来表示自然语言文本的基本单位,可直观理解为®"字"或"词";通常1个中文词
语、1个英文单词、1个数字或1个符号计为1个token。
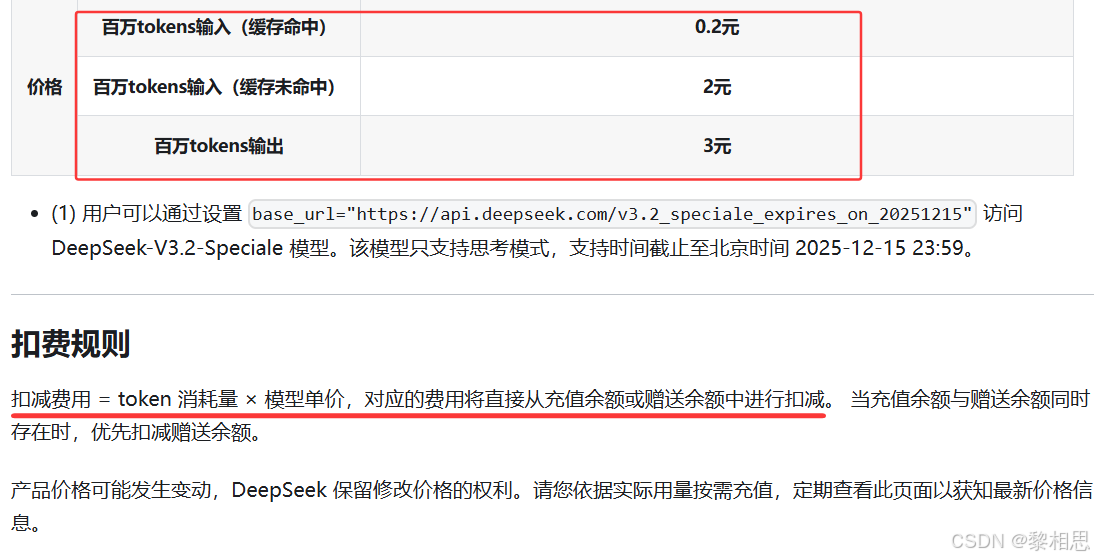
不同模型中关于token的计算方式可能稍有差异。下面是DeepSeek官网中关于公布的token的计算方式以及收费:
3. DeepSeek、ChatCPT、Gemini使用
3.1 产品和模型
DeepSeek、ChatGPT、Gemini并不是大模型,而是基于某个大模型开发出来的大模型应用产品。
大模型具有大量参数(数十亿甚至百亿)的人工智能模型,它学习了海量知识,掌握了理解自然语言、逻辑推理、写作、编程等底层通用能力,是一个拥有巨大潜力的"大脑"。
大模型产品是基于具体大模型开发出来的应用或服务,这些产品将大模型的能力封装成用户友好的界面或工具,提供给最终用户进行使用。比如DeepSeek官网提供的能和用户聊天的网页服务,实际就是DeepSeek-V3.1模型装上了一个聊天界面,让用户低成本使用大模型提供的服务,你问大模型问题,大模型将理解你的问题后将自己回答输出给你。
比如:DeepSeek是深度求索公司开发的,基于DeepSeek-V3.1模型的产品。
3.2 DeepSeek使用
deepseek官网:DeepSeek | 深度求索
以前打开DeepSeek官网,显示如下页面

DeepSeek-V3和DeepSeek-R1对比
|----------|-------------------|---------------------|
| 特性 | DeepSeek-V3 | DeepSeek-R1 |
| 工作模式 | 快速响应,对答如流 | 慢慢推理,追求准确 |
| 思考方式 | 直接给出答案 | 一步步展示推理过程 |
| 像什么人 | 只是渊博的万事通 | 严谨的老教授或侦探 |
| 擅长领域 | 日常聊天、信息查询、翻译创作写作等 | 复杂数学逻辑、逻辑推理、编程、算法题等 |
| 准确性 | 日常回答准确性高 | 复杂问题准确性高 |
一句话总结:V3是"快",适合大多数日常任务;R1是"稳",专啃硬骨头,处理复杂问题。
如果需求是日常使用、快速获取信息、内容创作,DeepSeek-V3更适合。如果是需要严密逻辑推理、解决复杂问题,比如钻研艰难的数学题、进行复杂算法研究,并愿意为更深入的思考付出一些等待时间,DeepSeek-R1这个"大学霸"会更适合。
官方最近将模型升级到DeepSeek-V3.1,移除了R1独立选项 ,DeepSeek-V3.1整合了原本R1的"深度思考"推理能力,用户可以通过"深度思考 "开关来切换快速响应模式 (原V3模式)和深度推理模式(原R1模式)。

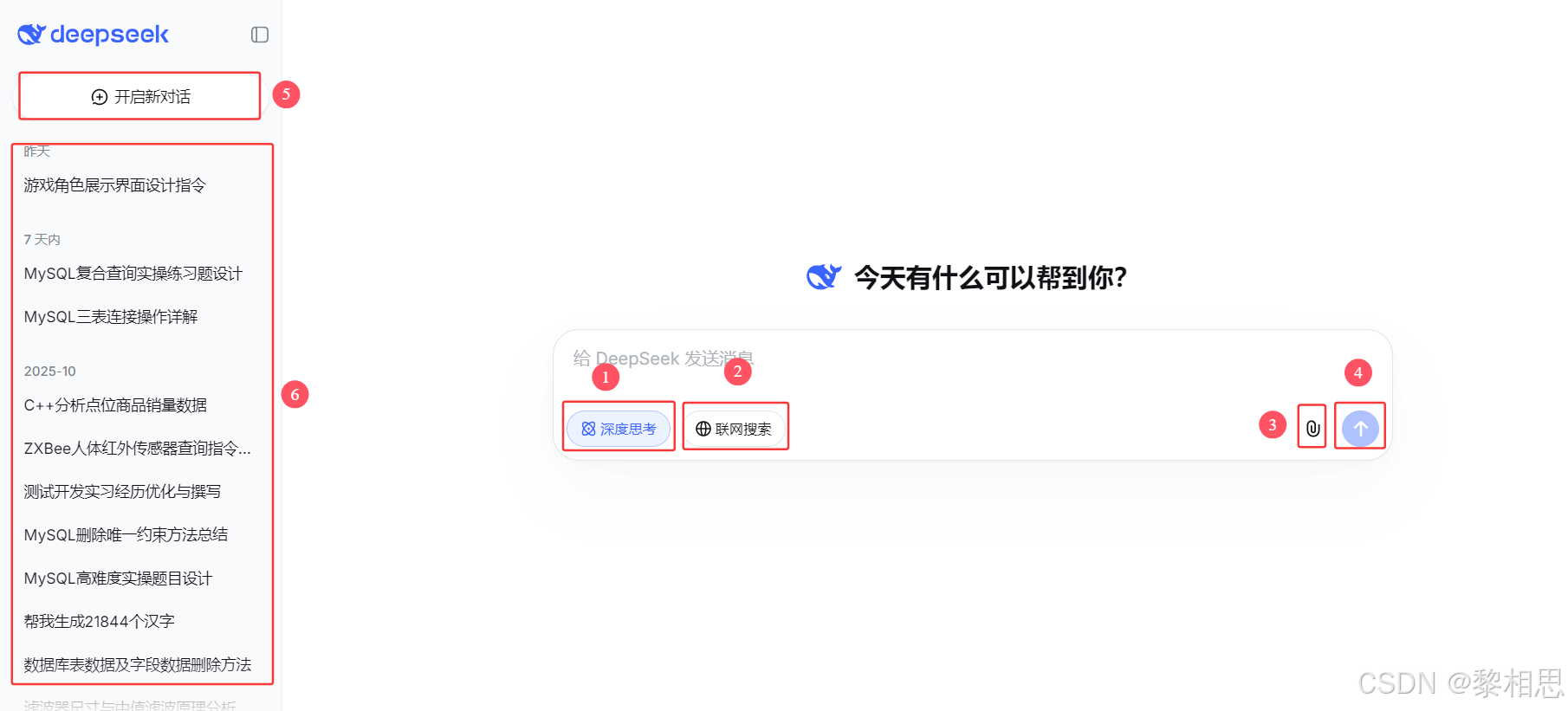
- 深度推理模式和快速响应模式开关,默认未选中为快速响应模式,选中之后切换到深度思考模式。
- 未选中时仅使用模型预训练知识,开启后可获取最新信息,注意联网搜索模式下不支持上传文件。
- 未选中时无法上传文件,仅通过文本输入和模型交互,开启后支持上传PDF、Word、Excel等文件,模型会读取文件内容并根据内容回答问题,目前暂不支持图片。
- 输入用户提示词之后,发送给模型,让模型思考回答开新一轮对话。比如切换一个新话题、当对话边的混乱,模型开始"胡言乱语"时。
- 开新一轮对话。比如切换一个新话题、当对话边的混乱,模型开始"胡言乱语"时。
- 支持会话管理。可以点击任意一条之前的会话记录,快速回到该次会话中,继续之前会话,就想看书时返回之前章节一样。会话名称一般是第一次问题的开头命名。
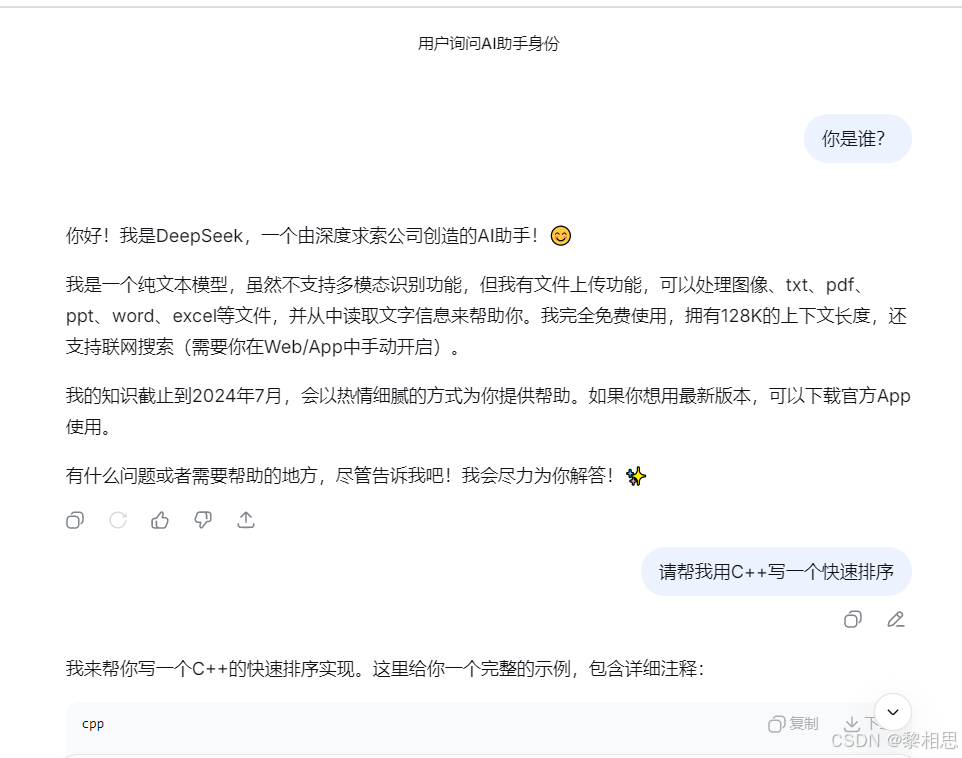
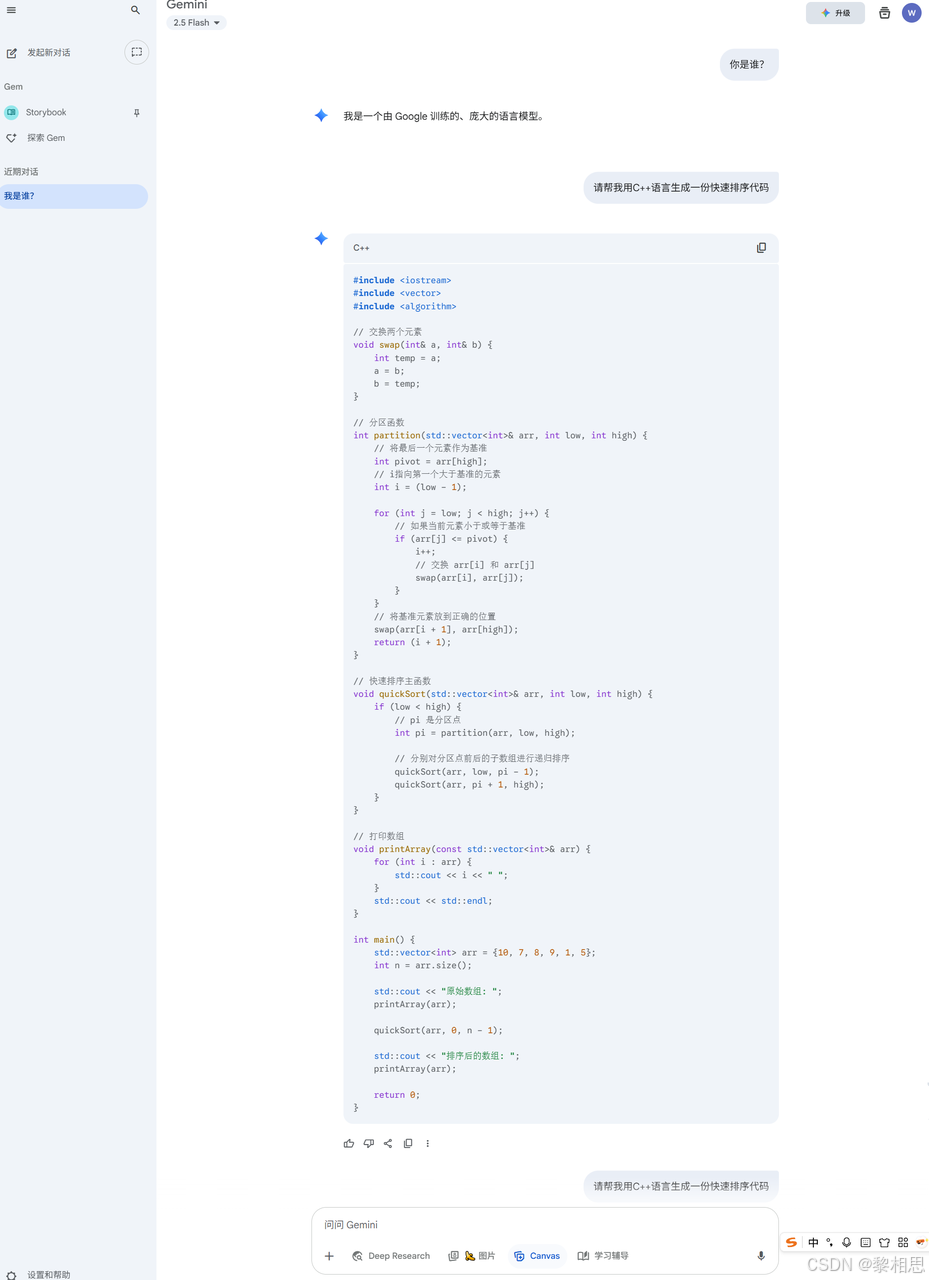
3.3 ChatGPT
ChatGPT,从名字中看Chat是聊天的意思,GPT是什么意思?
GPT是 Generative Pre-trained Transformer 的缩写。
Generative(生成式): 它能生成内容(文字、代码图像等),不是简单检索
Pre-trained(预训练): 在大模型文本数据上先进行通用训l练,再针对具体任务做微调
Transformer:一种深度学习框架,是目前大语言模型的核心技术,擅长处理序列数据,比如自然语言。
GPT就是基于深度学习框架的一种大语言模型系列,比如:GPT-4、GPT-5。ChatGPT就是基于GPT模型的聊天式人工智能助手,是一个产品。
GPT-4可以处理文字和图片输入,刚开始主要是文字版(GPT-4-turbo),后来逐步开放图像输入,比如识别图片中文字、分析图表等,但输出主要是文字。GPT-5是一个完整的多模态模型,输入可以是文字、图片、音频、视频帧等,输出可以是文字、语音、甚至可以配合Sora生成视频。
官网:OpenAI
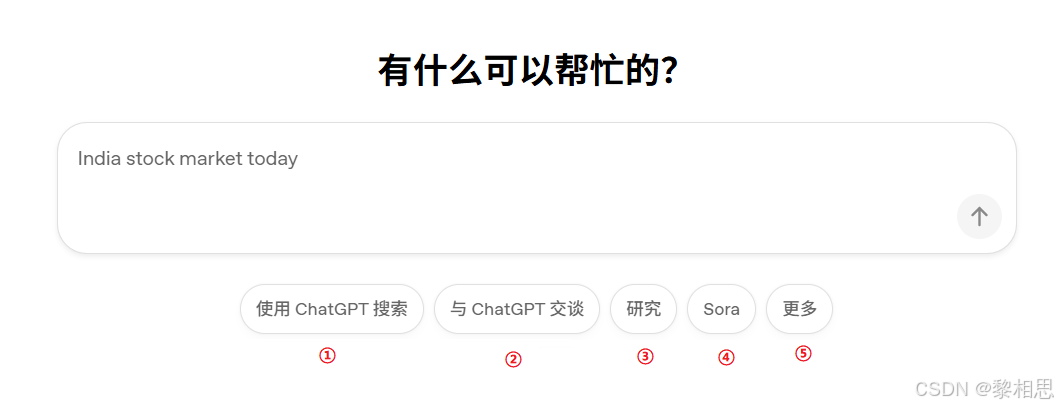
①使用ChatGPT搜索:选中之后会先调用"联网搜索"获取网页,再把结果交给ChatGPT进行总结和会话
②与ChatGPT交谈:标准聊天模式,主要用来对话、问答、写作、编程等
③研究:自动查资料并生成结构化且带引用的研究报告
④Sora:Sora是生成视频的模型,输入文字即可生成视频内容,和GPT系列不同
3.4 Gemini
官网:https://gemini.google.com/app
gemini翻译过来是双子座,双子座标志是两个并排站立的人物,象征则会二元性、合作以及强大的力量。
Google在开发Gemini时,将Google DeepMind和Google Research的"Brain"团队合并,这两个团队的合作被视为"双子",共同致力于打造这个野心勃勃的多模态AI模型。
还有一个说法是致敬NASA(美国国家航空航天局)的双子座计划,该计划是阿波罗登月计划之前的关键一步,旨在测试宇航员长时间太空飞行和太空对接等技术,这项开创性计划的巨大努力和对未来成功的莫定,与开发大语言模型的艰难任务产生了共鸣,因此团队使用了"Gemini"名字。
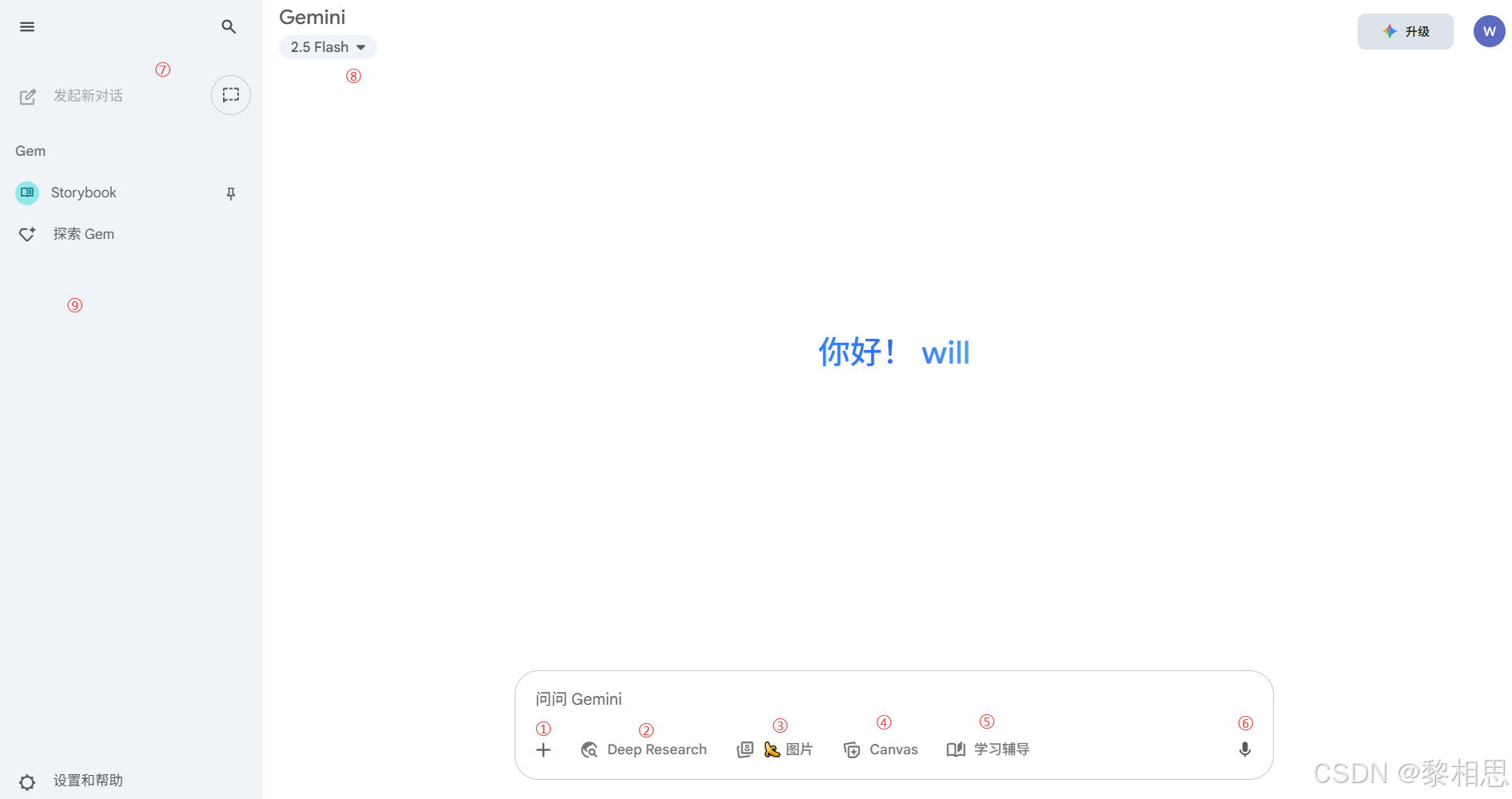
①上传文件,支持文本、图片、视频等不同格式文件,让大模型进行理解并进行各种操作,比如总结文档关键内容,分析表格数据等
②DeepResearch:对问题进行更深入全面的信息检索和分析,一般在处理复杂或专业性强的问题时非常有用
③图片生成:根据用户的提示词,Gemini会使用lmagen模型生成一幅符合描述的图片
④创建文档和应用:启用之后Gemini会根据用户输入需求,使用Canvas生成文档初稿,用户可以实时调整和优化
⑤像一个私人导师,能用多种方式来辅助学习,比如总结提炼核心要点、生成学习材料等。
⑥支持语音输入
⑦发起新一轮对话和临时对话,临时对话不会显示在会话记录中,临时会话系统仅保留72小时;发起新一轮对话会开启一个全新的聊天会话
⑧模型切换,目前支持gemini-2.5-flash和gemini-2.5-pro,或升级其他模型。gemini-2.5-flash擅长
处理快速、简单的人物,比如基础问答、生成简短内容等,速度非常快;gemini-2.5-pro擅长处理复杂、需要深度推理的任务,比如复杂数学题、编程等
⑨支持会话管理
4. 为什么学习通过API使用大模型
既然各个大模型厂商已经提供了类似DeepSeek、ChatGPT、Gemini这样的大模型服务了,开箱即用非常香,在日常学习工作中已经收获颇丰,为什么还要学习手动接入大模型?
我认为有以下几点原因:
- 了解更多大模型知识,提高自己竞争力
使用官方大模型服务就像开车,会操作就行,目的是到达终点;调用API就像学习汽车原理、保养和改装,能让你造出更适合任务的专用车,甚至将发动机装到飞机、轮船上。前者是大模型产品的使用者,后者已经摇身成为大模型应用的创造者。
- 构建自己的应用
API允许你将大模型的"大脑"与你自己的程序、网站、数据库等连接起来,实现通用机器人无法完成的任务,解锁无限可能性。比如:开发智能编程助手提高日常开发效率、构建自动化工作流(自动处理邮件、生成报告、分析数据等)、构建垂直领域应用(为法律、医疗、教育等领域开发专业的问答工具)
- 职业发展
大模型应用越来越广泛,许多公司都在将大模型能力渐渐接入到自己的产品中,在AI原生应用开发领域,大模型应用开发相关岗位也越来越多,会使用API集成大模型的能力,能让你在求职中更具竞争力,更好的适应行业的发展趋势。
- 学术研究
有些考研的学生,研究的课题可能和人工智能相关,掌握API接入大模型技术后,可以为自己量身定制大模型应用以进行实验和数据分析,验证自己的研究假设。
因此,作为一名计算机专业的学生,或者将来从事计算机方向开发工作,学习通过API方式使用大模型是非常有价值的,不仅能帮助你更好地理解和使用大模型,还能给未来职业发展打下坚实基础。
5. 项目演示
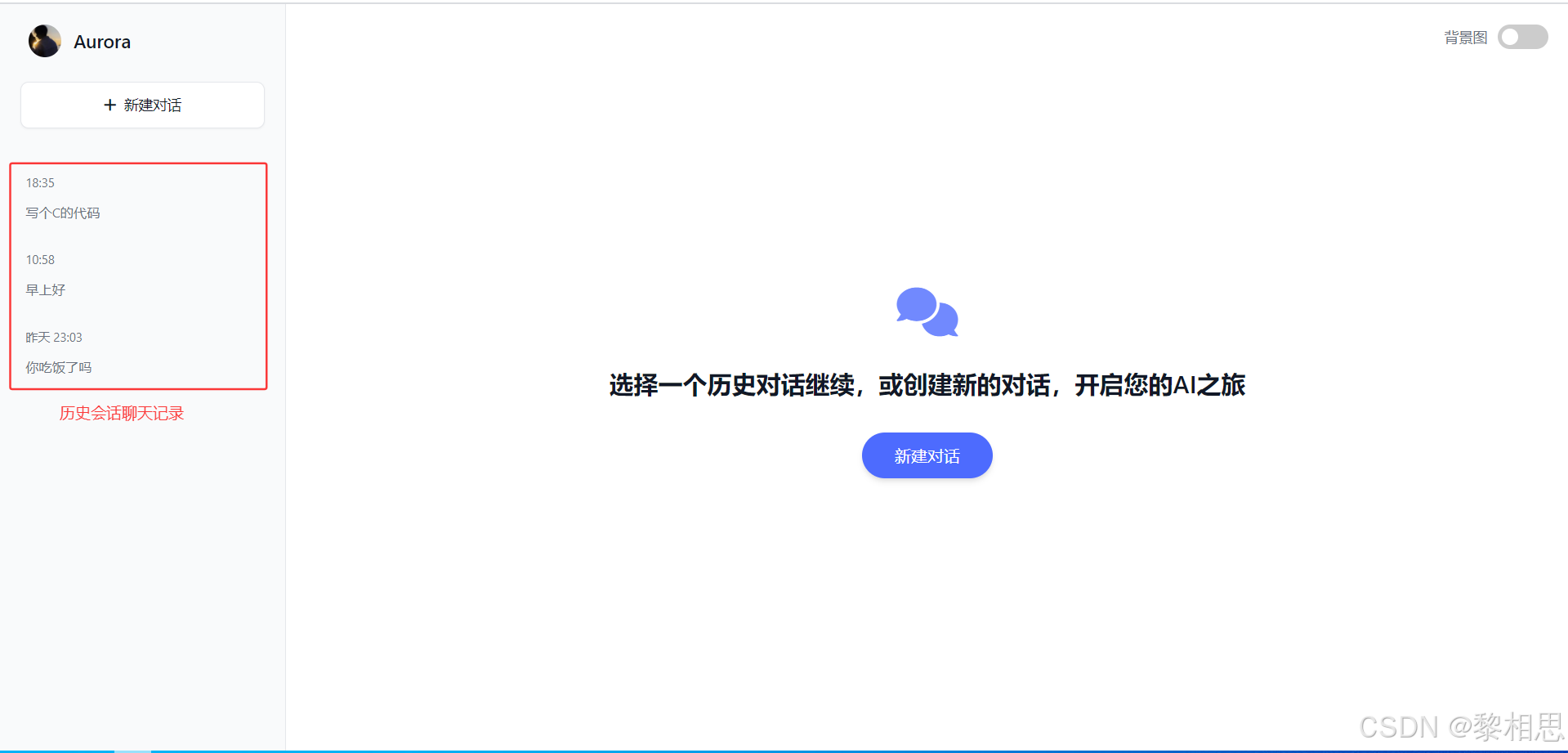
- 获取会话列表
- 新建会话
- 获取支持模型
- 发送消息
- 获取指定会话的历史聊天记录
- 删除会话
【主界面】
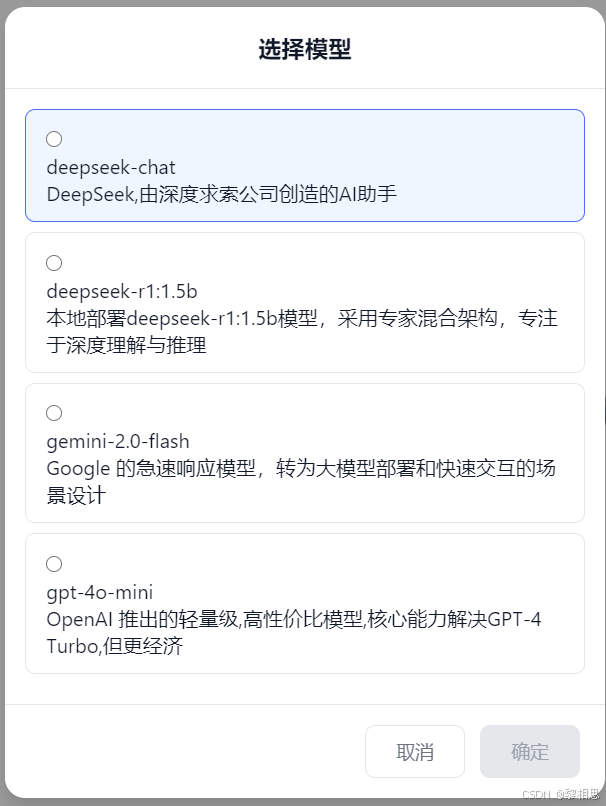
【模型选择】
【开始会话】

6. 项目架构
项目的系统架构图如下:
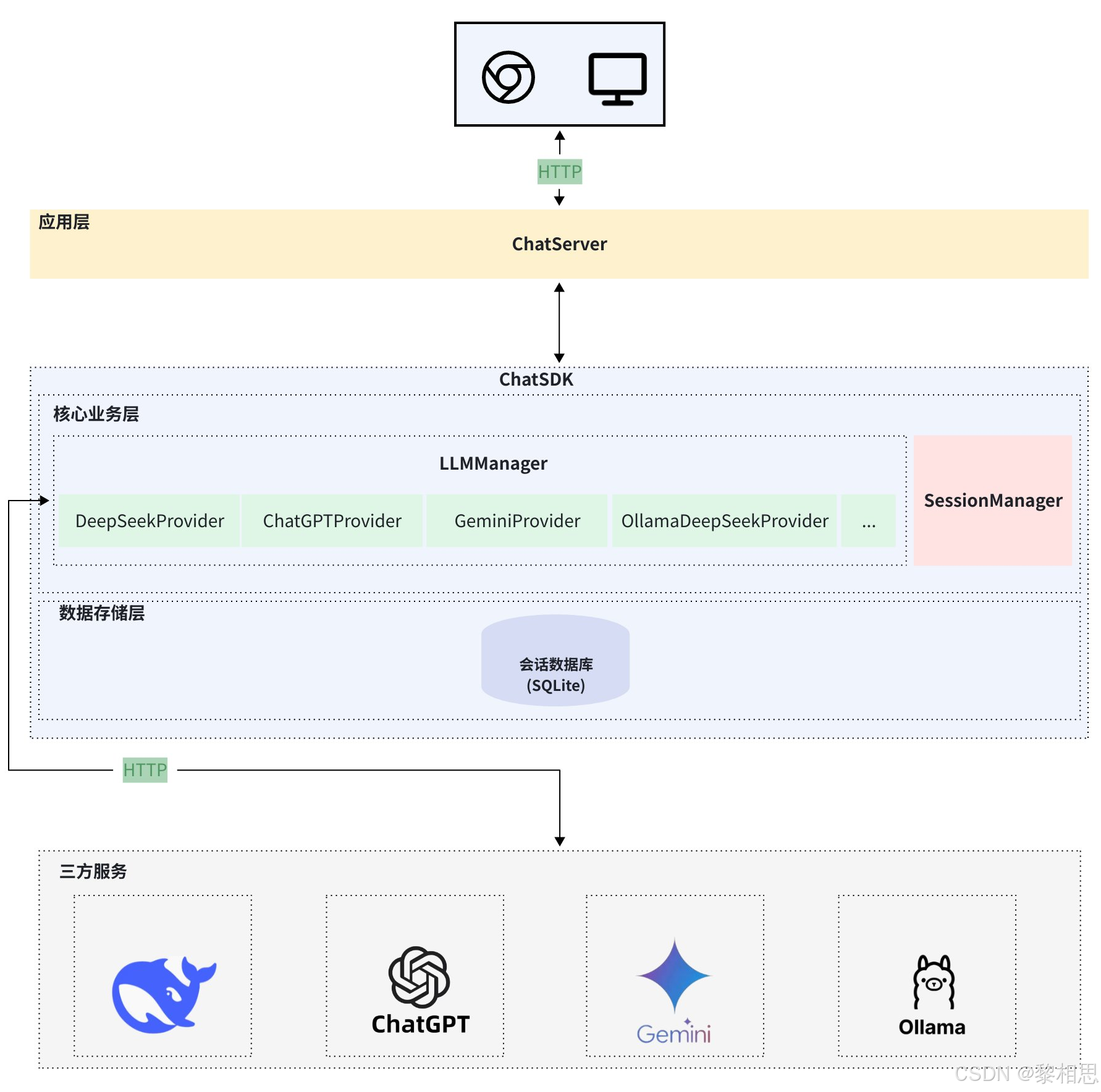
系统架构图说明如下:
**应用层:**用户使用ChatSDK库来封装自己的应用层服务,比如实现智能聊天机器人
**ChatSDK:**封装大模型管理库,包括大模型管理、Session管理以及数据存储。
- 大模型管理:负责管理并接入各种不同大模型,目前已接入deepseek-v3、gpt-4o-mini、gemini-2.0-flash等云端大模型;支持接入本地大模型,并向外提供统一接口,用户可以通过提供的接口接入自己需要大模型。
- 会话管理:支持会话管理,用户可以获取获取会话列表、历史消息等
- 数据存储层:支持会话记录的持久化存储,方便查看历史会话。
**三方服务:**对于接入的云端模型,最终由ChatSDK将用户消息转发给三方服务器,模型回复后将结果返回给应用层。对于本地部署大模型,ChatSDK会将用户消息发送给本地安装的Ollama服务器,由Ollama服务器和三方模型服务器对接,Ollama将模型的回复返回给ChatSDK,由ChatSDK将结果返回给应用层。
下面是本项目中使用的第三方库和工具:
|----|-------------|-------------------------------------|
| 序号 | 第三⽅库/⼯具 | 描述 |
| 1 | cpp-httplib | 轻量级的C++ HTTP 客⼾端/服务器库 |
| 2 | spdlog | ⾼性能、超快速、零配置的 C++ ⽇志库 |
| 3 | jsoncpp | ⾼性能的json库,⽤于序列化&反序列化 |
| 4 | sqlite | 轻量级嵌⼊式关系型数据库,⽀持标准SQL语句 |
| 5 | gflags | 定义和解析命令⾏参数的C++库 |
| 6 | gtest | 跨平台的C++单元测试框架 |
| 7 | curl | ⼀款强⼤的命令⾏⼯具,⽀持HTTP、HTTPS、FTP等多种协议 |
| 8 | apifox | ⼀款集API调试、Mock数据⽣成、⾃动化测试等功能于⼀体的协作⼯具 |
| 9 | CMake | ⼀次配置,跨平台⽣成任何构建系统的元构建⼯具 |
| 10 | ollama | ⼀个可以让你在本地电脑上轻松下载、运⾏和操作各种⼤型语⾔模型的强⼤⼯具 |