随着大语言模型(LLM)参数规模从十亿级增长到千亿、万亿级,如何在保持性能的同时节省算力,成为研究的核心问题。MoE(Mixture of Experts, 混合专家) 架构正是在这种背景下应运而生。
MoE 的核心理念是:
"模型的每个输入,只激活部分模块,让神经网络在每一次推理中'用一部分大脑'。"
这大大减少了计算量,同时还能保持甚至提升模型性能。
本文将带你深入理解 MoE 的设计理念、工作原理、主流实现方式、挑战和前沿进展。
所有相关源码示例、流程图、模型配置与知识库构建技巧,我也将持续更新在Github:LLMHub,欢迎关注收藏!
希望大家带着下面的问题来学习,我会在文末给出答案。
- MoE 为什么能做到"参数超大但推理成本不变"?这是不是违反直觉?
- 在同一个模型中,不同 token 为什么使用不同专家?模型怎么知道该选谁?
- 如果专家只是随机分工,那为什么 MoE 通常还能比等效的 dense 模型表现更好?
什么是 MoE?
MoE(Mixture of Experts)是一种稀疏激活(sparse activation)架构,其核心思想是:
在模型的某一层,不使用全部子网络(专家),而是选择其中一小部分"专家"来参与前向计算。
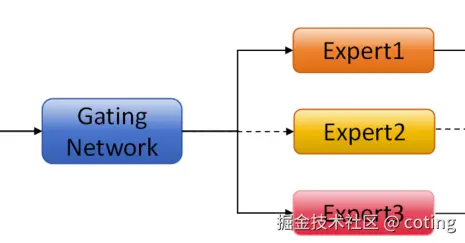
就像你问一个问题时,不需要每个专家都来回答,只要挑几个合适的专家来就行了。
MoE 的整体结构图
plain
┌────────────┐
│ Input │
└────┬───────┘
▼
┌────────────┐
│ Gating 函数 │ ◄── 控制选择哪些专家
└────┬───────┘
▼
┌────────┬────────┬────────┐
│ Expert1│ Expert2│ Expert3│...(通常有 4~64 个)
└────────┴────────┴────────┘
▼(只激活 Top-k 个)
┌────────────┐
│ 汇聚输出 │(加权或求和)
└────────────┘MoE 是怎么工作的?
在某个 MoE 层中,模型会包含多个Expert(专家子网络) ,以及一个Gating Network(门控网络):
步骤 1:输入 token
比如你有一个句子"Hello world",经过 embedding 后每个 token 是一个向量。
步骤 2:Gating 函数选择专家
门控网络对每个 token 决定要激活哪些专家,通常用 softmax/Top-k 策略。
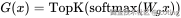
步骤 3:只激活 Top‑k 个专家
通常只激活 k=1 或 2 个专家(比如从 16 个专家中选择 2 个),大大节省计算量。
步骤 4:将输出聚合
被激活的专家对输入进行前向传播,其结果根据门控打分进行加权求和,得到最终输出。
为什么 MoE 能节省计算?
在标准 Dense 模型中,所有 token 都经过同样的参数层(比如全连接层)。
但在 MoE 中:
| 项目 | Dense 模型 | MoE 模型(k=2) |
|---|---|---|
| 层中总参数量 | 假设为 1 亿 | 可扩展到 10 亿(多个专家) |
| 每次前向计算参数 | 1 亿 | 仅用 2 亿中的 2×专家参数 |
| 计算成本 | 恒定 | 下降了 >80%(只激活一小部分) |
| 表达能力 | 通用 | 专家更具专业化,适应多任务 |
所以 MoE 的魔法在于:
计算成本 ≪ 模型规模,推理只用部分专家,效率远高于等效 Dense 模型。
MoE 的代表模型有哪些?
| 模型/组织 | 参数规模 | 特点 |
|---|---|---|
| Switch Transformer (Google, 2021) | 1T+ | k=1 极简 MoE,训练高效,稳定性好 |
| GLaM (Google) | 1.2T total, 97B active | 多专家 + 平衡分布,性能优于 dense GPT-3 |
| MT-MoE (Google) | 多任务翻译 | 各语言激活不同专家,专门化能力强 |
| Grok-1 (xAI, 2024) | ~314B total, sparse | 使用 MoE 架构,推理高效,训练开放 |
| DeepSpeed-MoE (微软开源) | 可扩展到 1000 亿参数以上 | 高性能、可定制 MoE 训练框架 |
| Mixtral (Mistral, 2023) | 12.9B dense, 47B total | k=2,极具竞争力,开源大模型代表之一 |
MoE 的主要优势
| 优势 | 解释 |
|---|---|
| 极大扩展模型容量 | 可构建上万亿参数模型而不会大幅增加计算成本 |
| 更强泛化和多任务能力 | 专家模块可以自动学习不同任务/风格/语境 |
| 可控制的推理成本 | 只需计算 Top‑k 个专家,提高效率 |
| 可共享结构 | 多语言、多任务可以共享一部分专家,重用能力强 |
MoE 架构面临哪些挑战?
| 问题 | 描述 | 解决方案(部分) |
|---|---|---|
| 负载不均衡(load imbalance) | 某些专家总被选中,部分专家闲置 | 使用 load balancing loss 强制均衡 |
| 训练不稳定 | Gating 函数梯度不稳定,容易震荡 | 使用 soft gating 或温度调控 |
| 内存碎片化 | 多专家分布在不同设备,通信开销大 | 使用模型并行、专家聚合技术(如 Tutel) |
| 多卡通信复杂 | 多机多卡时 Expert 分布难以优化 | 利用框架如 DeepSpeed-MoE、Tutel |
总结:为什么 MoE 是 LLM 架构演进的方向?
随着 LLM 越来越大,纯粹扩大 dense 模型规模已无法承受:
- 显存瓶颈、训练成本飙升
- 推理延迟增高,不适合边缘设备或 API 快速响应
而 MoE 提供了一种"稀疏计算、高容量"的结构范式,能够:
- 在推理时仅使用一部分专家
- 拥有超大参数空间和多样性
- 成为构建"模块化、专用化、节能型大模型"的重要路线
📚 推荐阅读
最后,我们回答一下文章开头提出的问题。
- MoE 为什么"巨大却高效"?
因为 MoE 每次只激活少数专家(通常是 Top‑1 或 Top‑2),大部分参数"休眠"。虽然总参数量可能高达数千亿,但每个 token 实际只经过一小部分网络,从而节省了大量计算。
- 为什么不同 token 会选不同专家?
模型中有一个 Gating Network(门控网络),它根据每个 token 的语义信息,动态选择最合适的专家模块。就像每个问题被分配给最懂它的专家,形成一种任务自适应路由机制。
- MoE 比 dense 模型更强的原因?
因为不同专家可以专注于不同的输入类型(如语法结构、语言风格、领域知识),这就像构建了一个"专家团队",每个子网络都被训练得更专精,整体上模型的泛化和鲁棒性都更强。
关于深度学习和大模型相关的知识和前沿技术更新,请关注公众号算法coting!
所有相关源码示例、流程图、模型配置与知识库构建技巧,我也将持续更新在Github:LLMHub,欢迎关注收藏!