系统架构设计师大数据架构设计理论与实践(十九)
一.传统数据处理系统的问题
1.传统数据库的数据过载问题
传统应用的数据系统架构设计时,应用直接访问数据库系统。当用户访问量增加时,数据库无
法支撑日益增长的用户请求的负载,从而导致数据库服务器无法及时响应用户请求,出现超时的错
误。
解决方案:
1)增加异步处理队列,通过工作处理层批量处理异步处理队列中的数据修改请求
2)建立数据库水平分区,通常建立Key分区,以主键/唯一键Hash值作为Key
3)建立数据库分片或重新分片,通常专门编写脚本来自动完成,且要进行充分测试
4)引入读写分离技术,主数据库处理写请求,通过复制机制分发至从数据库
5)引入分库分表技术,按照业务上下文边界拆分数据组织机构,拆分单数据库压力
2.大数据的特点
体量大,时效性强
大数据处理技术分类:
1)基于分布式文件系统Hadoop
2)使用Map/Reduce或Spark数据处理技术
3)使用Kafka数据传输消息队列及Avro二进制格式
3.大数据利用过程
过程:采集,清洗,统计,挖掘
二.大数据处理系统架构分析
1.大数据处理系统面临挑战
1)如何利用信息技术等手段处理非结构化和半结构化数据
2)如何探索大数据复杂性,不确定性特征描述的刻画方法及大数据的系统建模
3)数据异构性与决策异构性的关系对大数据知识发现与管理决策的影响
2.大数据应具有的属性和特征包括
鲁棒性和容错性,低延迟,横向扩展(通过增强机器性能扩展),通用,可扩展,即席查询(用户按照自己的要求查询),最少维护和可调试
三.典型的大数据架构
1.Lambda架构
同时处理离线和实时数据的,可容错的,可扩展的分布式系统
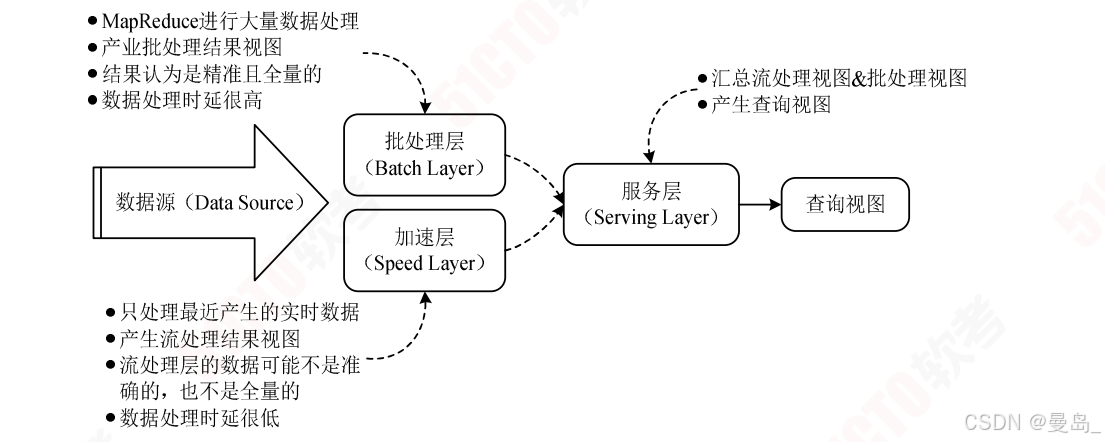
1)批处理层:存储主数据集,主数据集具有原始,不可变,真实的特征。
批处理层周期性地将增量数据转储至主数据集,并在主数据集上执行批处理,生成批视图
架构实现方面可以使用Hadoop HDFS或Hbase存储主数据集,再利用Spark或MapReduce执行周期批处理,之后使用MapReduce创建批视图
2)加速层:处理增量实时数据,生成实时视图,快速执行即席查询。架构实现方面可以使用Hadoop HDFS或Hbase存储实时数据,利用Spark或Storm实现实时数据处理和实时视图
3)服务层:响应用户请求,合并批视图和实时视图中的结果数据集得到最终数据集。具体来说就是接收用户请求,通过索引加速访问批视图,直接访问实时视图,然后合并两个视图的结果数据集生成最终数据集,响应用户请求,架构实现方面可以使用Hbase或Cassandra作为服务层,通过Hiva创建可查询的视图
Lambda架构优缺点:
优点:容错性好,查询灵活度高,弹性伸缩,易于扩展
缺点:编码量大,持续处理成本高,重新部署和迁移成本高
相似模式:事件溯源模式,命令查询分离职责模式
2.Kappa架构
在Lambda上删除Batch Layer,数据通道以消息队列替代
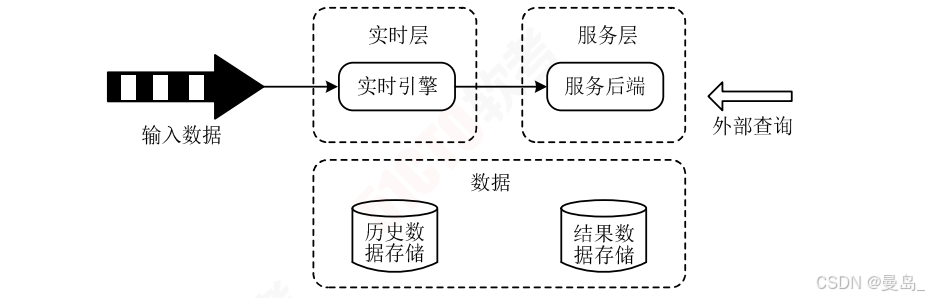
1)实时层:该层核心功能是处理输入数据,生成实时视图。采用流式处理引擎逐条处理输入数据,生成实时视图。架构实现方式是采用Apache Kafka回访数据,然后采用Flink或Spark Streaming进行处理
2)服务层:使用实时视图中的结果数据集响应用户请求,实践中使用数据湖中的存储作为服务层
优点:离线和实时处理代码进行了统一,方便维护
缺点:消息中间件有性能瓶颈,数据关联时处理开销大,抛弃了离线计算的可靠性
Kappa架构常见变形是Kappa+架构,混合分析系统Kappa架构
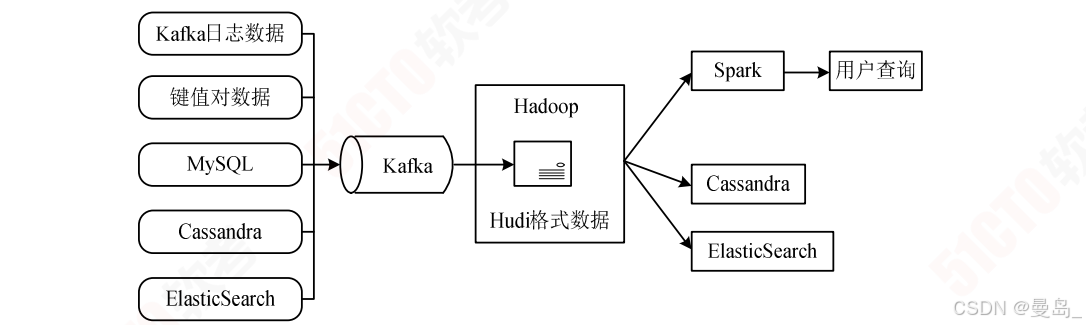
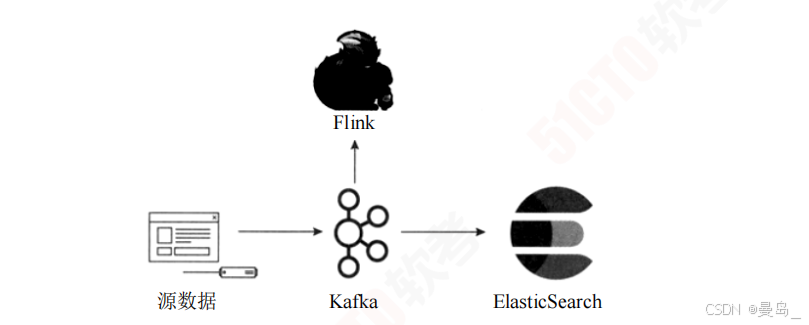
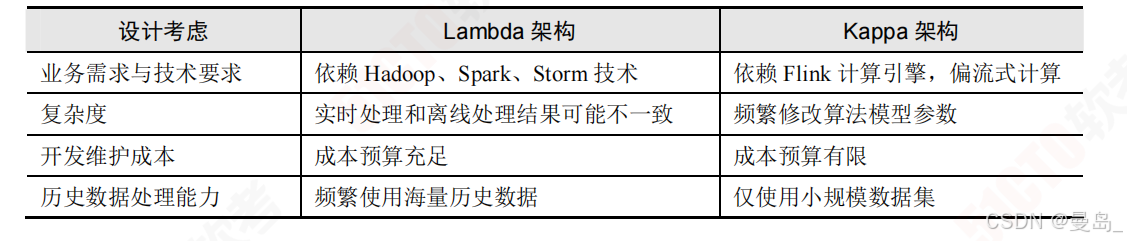
3.Lambda架构和Kappa架构的对比

4.影响Lambda架构和Kappa架构选择的决策因素
四.大数据架构的实践
1.大规模视频网络
某网采用以Lambda架构搭建的大数据平台处理里约奥运会大规模视频网络观看数据,平台架构设计如图
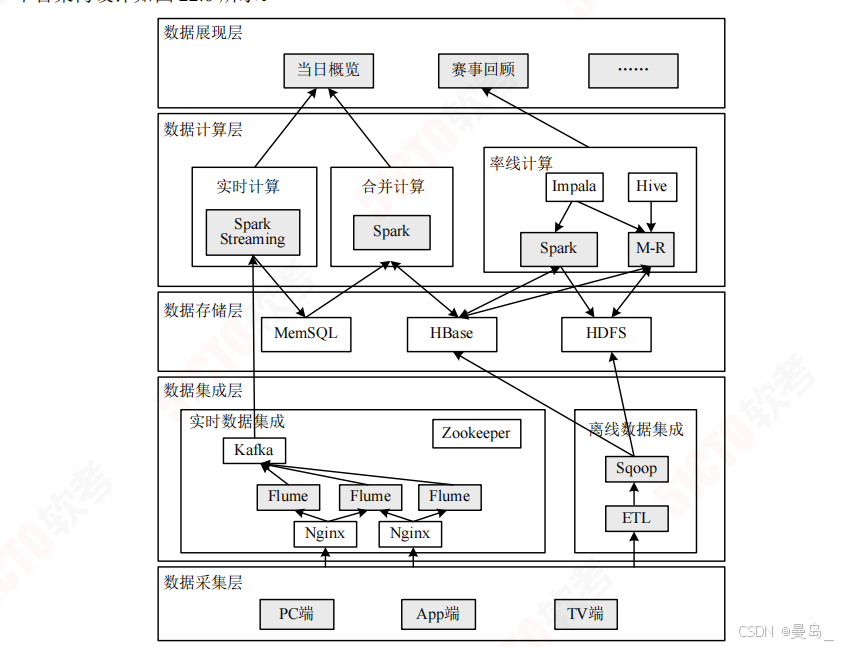
数据计算层:离线计算,实时计算,合并计算
1)离线计算部分:存储持续增长的批量离线数据,周期性使用Spark和Map/Reduce批处理,批处理结果更新到批视图之后使用Impala或者Hive建立数据仓库,结果写入HDFS
2)实时计算部分:Spark Streaming,只处理实时增量数据,将处理后的结果更新到实时视图
3)合并计算部分:合并批视图和实时视图中的结果,生成最终数据集,将最终数据集写入Hbase数据库中用于响应用户的查询请求
2.广告平台
某网基于Lambda架构的广告平台。批处理层,加速层,服务层
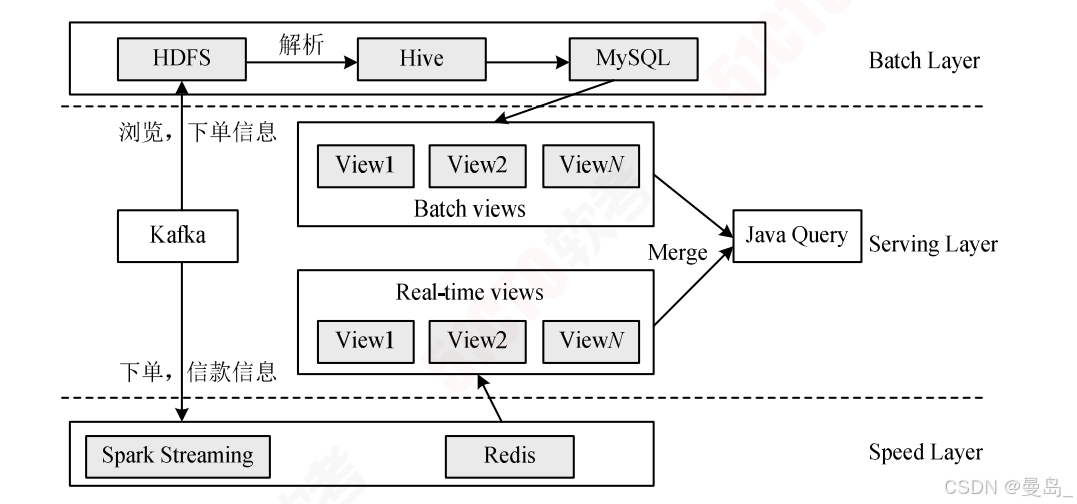
1)批处理层:每天凌晨将Kafka中浏览,下单等消息同步到HDFS中,将HDFS中数据解析为Hive表,然后使用HQL或Spark SQL计算分区统计结果Hive表,将Hive表转储到MySQL中作为批视图
2)加速层:使用Spark Streaming实时监听Kafka下单,付款等消息,计算每个追踪链接维度的实时数据,将实时计算结果存储在Redis中作为实时视图
3)服务层:采用Java Web服务,对外提供HTTP接口,Java Web服务读取MySQL批视图表和Redis实时视图表
3.公司智能决策大数据系统
某证券公司智能决策大数据系统是一个基于Kappa架构的实时日志分析平台
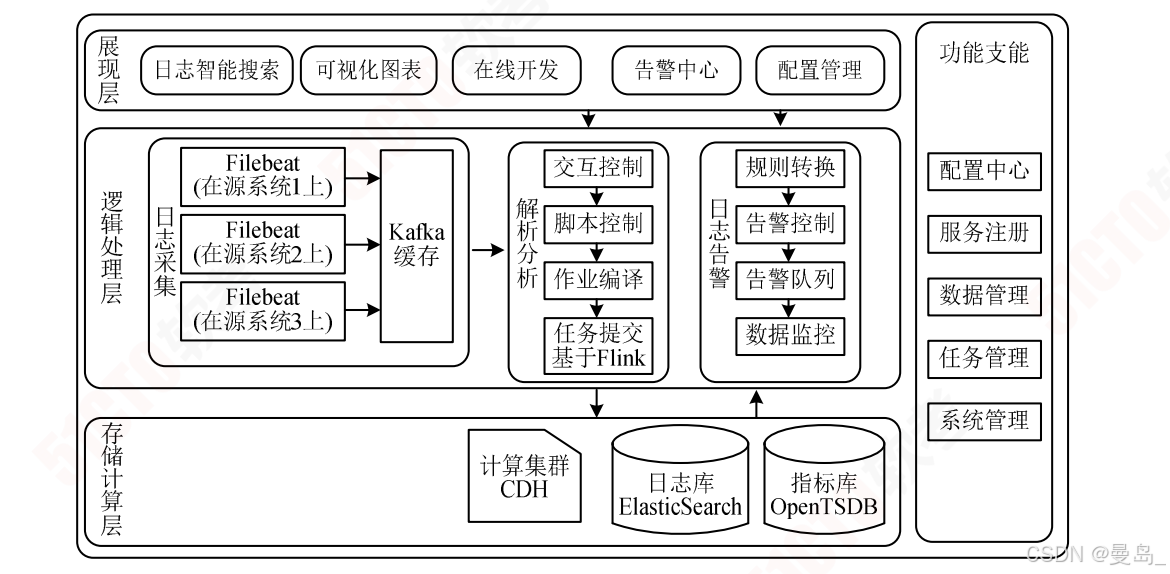
1)日志采集:用统一的数据处理引擎Filebeat实时采集日志并推送给Kafka缓存
2)日志清洗解析:利用基于大数据计算集群的Flink计算框架实时读取Kafka消息并进行清洗,解析日志文本转换成指标
3)日志存储: 日志转储到ElasticSearch日志库,指标转储到OpenTSDB指标库
4)日志监控:单独设置告警消息队列,保持监控消息时序管理和实时推送
5.电商智能决策大数据系统
基于Kappa架构,统一数据处理引擎Funk实时处理流数据,存储到数据仓库工具Hive与分布式缓存Tair中,供后续决策服务的使用
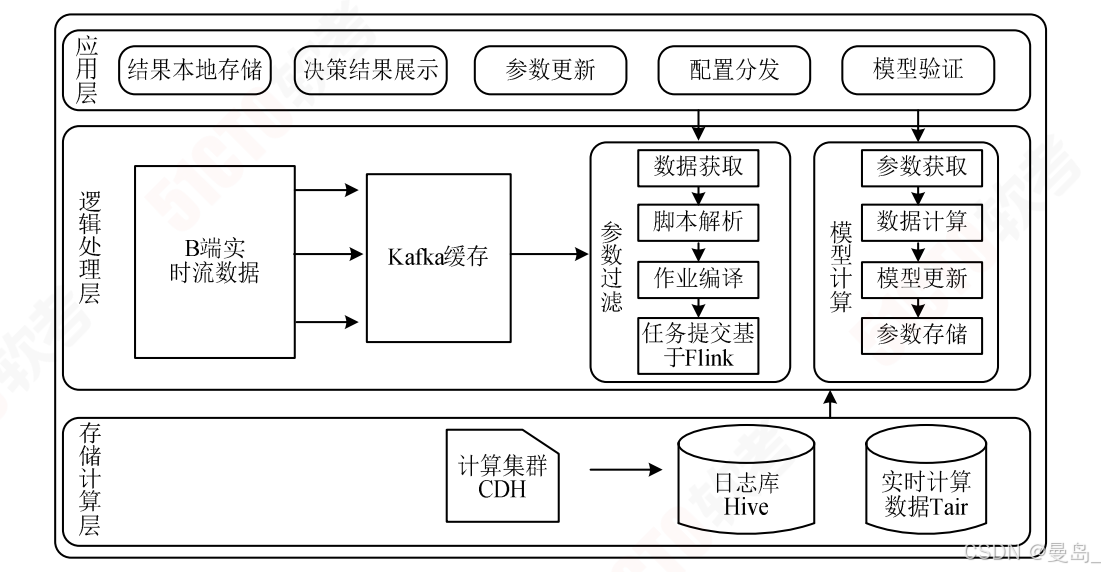
实时处理过程如下:
1)数据采集:B端实时采集用户点击,下单,广告曝光,出价等数据推送给Kafka缓存
2)数据清洗聚合:由Flink实时读取Kafka消息,按需过滤参与业务需求的指标,将聚合时间段的数据转换成指标
3)数据存储:Flink将计算结果转储至Hive日志库,将模型需要的参数转储至实时计算数据库Tair缓存,然后后续决策服务从Tair中获取数据进行模型训练
,广告曝光,出价等数据推送给Kafka缓存
2)数据清洗聚合:由Flink实时读取Kafka消息,按需过滤参与业务需求的指标,将聚合时间段的数据转换成指标
3)数据存储:Flink将计算结果转储至Hive日志库,将模型需要的参数转储至实时计算数据库Tair缓存,然后后续决策服务从Tair中获取数据进行模型训练