虚拟线程是自 Java 21 以来继 Lambda 表达式之后最重要的新特性之一。它们对并发代码的实现方式有重大影响。你可能知道,虚拟线程可以同时运行数百万个,这在 Java 1.0 以来的传统线程模型中是无法实现的。在深入了解虚拟线程之前,先了解一下现有线程的工作方式以及它们的局限性是很有必要的。
要跟随本章示例学习,你需要 Java 21 和一个你喜欢的 IDE。
现有线程模型
在 Java 21 中,我们得到了一个新类型的线程:虚拟线程。为了理解这些新线程为何如此颠覆性,并理解它们带来的好处,我们必须先了解 Java 21 之前的线程是如何工作的。旧线程并没有消失,我们仍然可以使用它们;只是 Java 21 新增了一种线程类型。
创建一个线程很简单,你可能在学校、业余项目或工作项目中写过类似这样的代码:
ini
Runnable task = () -> System.out.println("Hello, Reader!");
Thread thread = new Thread(task);
thread.start();这个示例展示了创建线程的简单方式,但在代码运行的幕后还有一些有趣的事情发生。当调用 Thread 构造方法时,Java 会请求操作系统(OS)创建一个操作系统线程,因为 Java 线程只是系统线程的一个轻量封装。每次调用 Thread 构造方法,应用程序都会请求 OS 创建线程。这看起来没问题,但创建线程是一个昂贵的操作,因为应用程序需要调用 OS,OS 还要创建系统资源并分配线程可以使用的内存。
线程内存分配因操作系统不同而异,但通常每个线程大约需要 1MB 内存。这在今天笔记本有 16GB 内存、服务器有 TB 级内存的情况下似乎不大,但它仍然限制了线程数量。为什么不默认分配更少的内存呢?问题在于应用程序在创建线程时无法预知这个线程会使用多少内存。线程的内存是 堆外内存 ,而且 JVM 无法在创建后调整它的大小。
使用线程
线程有很多用法,但先看看最常见的几种。
最简单的方式是每个任务创建一个线程。一个任务被定义为一段独立的工作单元。最简单的方式是为每个任务创建一个线程,任务完成后丢弃。例如:
ini
Runnable task1 = () -> System.out.println("This is task 1!");
Runnable task2 = () -> System.out.println("This is task 2!");
Runnable task3 = () -> System.out.println("This is task 3");
Thread thread1 = new Thread(task1);
Thread thread2 = new Thread(task2);
Thread thread3 = new Thread(task3);
thread1.start();
thread2.start();
thread3.start();每个任务都有自己的线程,任务完成后线程被丢弃并由垃圾回收器清理。这种方式简单,但非常浪费,因为每次都要请求 OS 创建线程、分配内存,然后在任务结束后丢弃。这样并没有很好地利用系统资源。
由于 Java 21 引入了虚拟线程,我们把以前的线程称为 平台线程(Platform Thread) ,因为它们由操作系统平台管理,而不是像虚拟线程那样由 Java 应用程序自己管理。
使用 ExecutorService
Java 5 引入了 ExecutorService,它鼓励我们使用线程池,而不是直接使用 Thread 类。ExecutorService 会创建一个线程池,可以向它提交任务。好处是我们不用自己管理线程重用,Java 会帮我们做到这一点。线程创建后会重复利用,避免频繁创建和销毁线程。
示例代码(Java 21 增强了 ExecutorService):
ini
Runnable task1 = () -> System.out.println("This is task 1!");
Runnable task2 = () -> System.out.println("This is task 2!");
Runnable task3 = () -> System.out.println("This is task 3!");
try(ExecutorService vte = Executors.newFixedThreadPool(3)){
vte.submit(task1);
vte.submit(task2);
vte.submit(task3);
}在 Java 21 中,ExecutorService 实现了 AutoCloseable,所以可以用 try-with-resources 自动关闭。当退出时,会等待所有线程执行完。
优点:线程池重用线程,性能更好。
缺点:
- 当线程被阻塞时,它不会去执行新任务,这在高并发 I/O 场景会导致 CPU 利用率低。
- 线程池中的线程数量有限,内存仍然是限制因素。
- ThreadLocal 变量泄漏问题:线程池复用线程时,如果任务使用了 ThreadLocal 且未清理,下一个任务可能会读取到上一个任务的数据,导致数据泄漏。
示例:
csharp
public class Main {
public static ThreadLocal<String> threadLocal = new ThreadLocal<>();
public static void main(String[] args) {
try (ExecutorService executor = Executors.newFixedThreadPool(1)) {
executor.submit(() -> {
threadLocal.set("Task 1 value");
System.out.println("Task 1: " + threadLocal.get());
});
executor.submit(() -> {
String value = threadLocal.get();
System.out.println("Task 2: " + value);
});
}
}
}输出:
arduino
Task 1: Task 1 value
Task 2: Task 1 value问题:第二个任务读取到了第一个任务的数据。
异步编程(Async Programming)
另一种方式是 异步编程 ,例如使用 Vert.x 框架。异步模型充分利用系统资源,不用担心线程数量限制。但它的问题是代码可读性差,容易陷入 回调地狱(Callback Hell) ,调试也更困难。
示例(HTTP Server):
vbscript
Vertx.vertx().createHttpServer().requestHandler(req -> req.response().end("Hello from async code!"))
.listen(8080, server -> {
if (server.succeeded()) {
System.out.println("Server started on port 8080");
} else {
System.err.println(server.cause());
}
});异步代码性能好,但可维护性差。
在 Java 21 之前,我们有三种主要方法:
- 直接使用 Thread:简单但资源浪费。
- ExecutorService:高效,但仍受线程数量限制,有 ThreadLocal 泄漏风险。
- 异步编程:性能好,但可读性和调试性差。
现在,Java 21 引入了 虚拟线程(Virtual Threads) ,它结合了易用性和高性能,解决了之前的很多问题。
虚拟线程
虚拟线程是 Thread 类的一种全新替代实现。别担心,我们熟悉的现有线程不会消失。从 Java 21 开始,我们得到了一种新的线程类型,它仍然可以运行一段代码作为一个工作单元,但它更加轻量。
正如我所说,虚拟线程是一种替代实现,而它最棒的地方在于 操作系统对此一无所知 。虚拟线程只是运行在你的应用程序内部的概念。当你创建虚拟线程时,不会调用操作系统,也不会为其分配兆字节级别的系统内存。因为虚拟线程只是一个类的简单实例,它可以直接将自己的栈帧存储在堆内存中,这带来了一个巨大的好处:内存可以动态调整大小!创建一个虚拟线程仅需几个字节。当虚拟线程需要更多内存时,它可以自行分配。因此,虚拟线程的栈是可调整大小的:需要更多时就分配,使用更少时就归还给应用程序。
那么,这些虚拟线程究竟有多"廉价"?我们来通过运行两个完全相同的应用程序做对比:一个使用 平台线程(Platform Threads) ,另一个使用 虚拟线程(Virtual Threads) 。应用程序的目标是创建一定数量的线程,并让每个线程执行相同的任务 ------ 休眠一段时间。为了测量内存占用,我使用了 Native Memory Tracking(NMT) 。应用代码如下:
typescript
import java.time.Duration;
import java.util.concurrent.Executors;
public class Main {
public static void main(String[] args) {
long pid = ProcessHandle.current().pid();
System.out.println("My PID is " + pid);
// try(var exc = Executors.newVirtualThreadPerTaskExecutor()){
try(var exc = Executors.newThreadPerTaskExecutor(Thread.ofPlatform().factory())){
for (int i = 0; i < 1000; i++) {
exc.submit(Main::sneakySleep);
}
}
}
private static void sneakySleep(){
try {
Thread.sleep(Duration.ofMinutes(2));
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}在 main 方法中,程序创建了一定数量的线程,并让它们都休眠两分钟。虽然这不是生产代码中会做的事,但它确实能显示创建这么多线程实例所需的内存量。
在两种线程类型之间切换 只需注释掉一行代码即可。为了查看内存占用,你需要在 VM 选项中添加:
ini
-XX:NativeMemoryTracking=detail你可以在 IDE 的运行配置中添加该选项。
在 图 1-1 中,你可以看到测试结果。
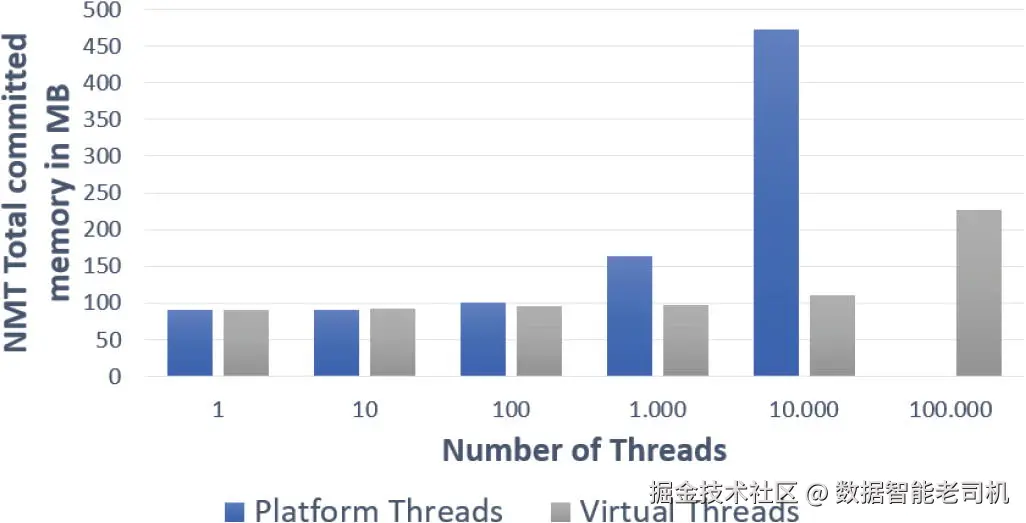
虚拟线程的结果可能会让你感到惊讶,尤其是当你看应用程序的前三次运行时。无论运行 1 个、10 个甚至 100 个线程,几乎没有区别。只有当应用程序创建了 100 个线程时,使用平台线程的版本才会多用一些内存。这告诉我们,如果你已有的应用程序使用线程且数量少于 100 个,那么为了这点内存使用的微小差异而重写代码并不值得。但当线程数量达到 1,000、10,000 和 100,000 时,虚拟线程与平台线程之间的差距开始扩大。当线程数达到 100,000 时,使用平台线程的应用程序抛出了内存溢出异常。这说明你可以创建比平台线程更多的虚拟线程。
使用 Thread 类创建虚拟线程非常简单。在 Java 21 中,Thread 类新增了一个静态构建器,可以用来创建单个虚拟线程:
ini
Runnable task = () -> System.out.println("Hello, World!");
Thread.startVirtualThread(task);以上代码即可创建一个虚拟线程。第一行定义了将在虚拟线程中运行的任务,第二行通过 Thread 类的静态方法 startVirtualThread 创建并启动虚拟线程。该方法接收一个 Runnable 参数,调用后线程立即运行,无需显式调用 start()。
你还可以使用 Thread.ofVirtual() 方法获取构建器,并设置线程的属性,例如:
- Name:线程名称
- InheritableThreadLocals :虚拟线程是否继承可继承的
ThreadLocal变量 - uncaughtExceptionHandler:未捕获异常的处理器
示例代码如下:
ini
Runnable task = () -> System.out.println("Hello, World!");
Thread.ofVirtual().name("vt1").start(task);
// 未启动的虚拟线程
Thread unstarted = Thread.ofVirtual().name("vt2").unstarted(task);
unstarted.start();第一个构建器创建了名为 vt1 的虚拟线程并立即运行任务,第二个构建器创建了名为 vt2 的虚拟线程但未启动,需要显式调用 start()。
通过虚拟线程构建器,还可以创建线程工厂(ThreadFactory),并在 ExecutorService 中使用。例如:
ini
ThreadFactory factory = Thread.ofVirtual().factory();
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(0, factory);
Callable<String> scheduledCallable = () -> {
System.out.println("Done");
return "Done";
};
scheduledExecutorService.schedule(scheduledCallable, 1, TimeUnit.SECONDS);这里我们创建了一个虚拟线程工厂并传入 newScheduledThreadPool,这样线程池在创建线程时将使用虚拟线程。
在 Java 21 中,Executors 提供了一个默认使用虚拟线程的执行器:Executors.newVirtualThreadPerTaskExecutor()。该执行器为每个任务创建一个虚拟线程,任务完成后线程会被丢弃,不会复用,因为虚拟线程创建的成本极低。示例如下:
ini
Runnable task = () -> System.out.println("Hello, World!");
try (ExecutorService vte = Executors.newVirtualThreadPerTaskExecutor()) {
vte.submit(task);
}如果要批量创建大量虚拟线程,可以这样写:
ini
Runnable task = () -> System.out.println("Hello, World!");
try (ExecutorService vte = Executors.newVirtualThreadPerTaskExecutor()) {
for (int i = 0; i < 1_000_000; i++) {
vte.submit(task);
}
}以上代码会提交 100 万个任务,每个任务运行在一个独立的虚拟线程中。这远远超过系统核心数,那么这些线程在实际系统上是如何运行的呢?
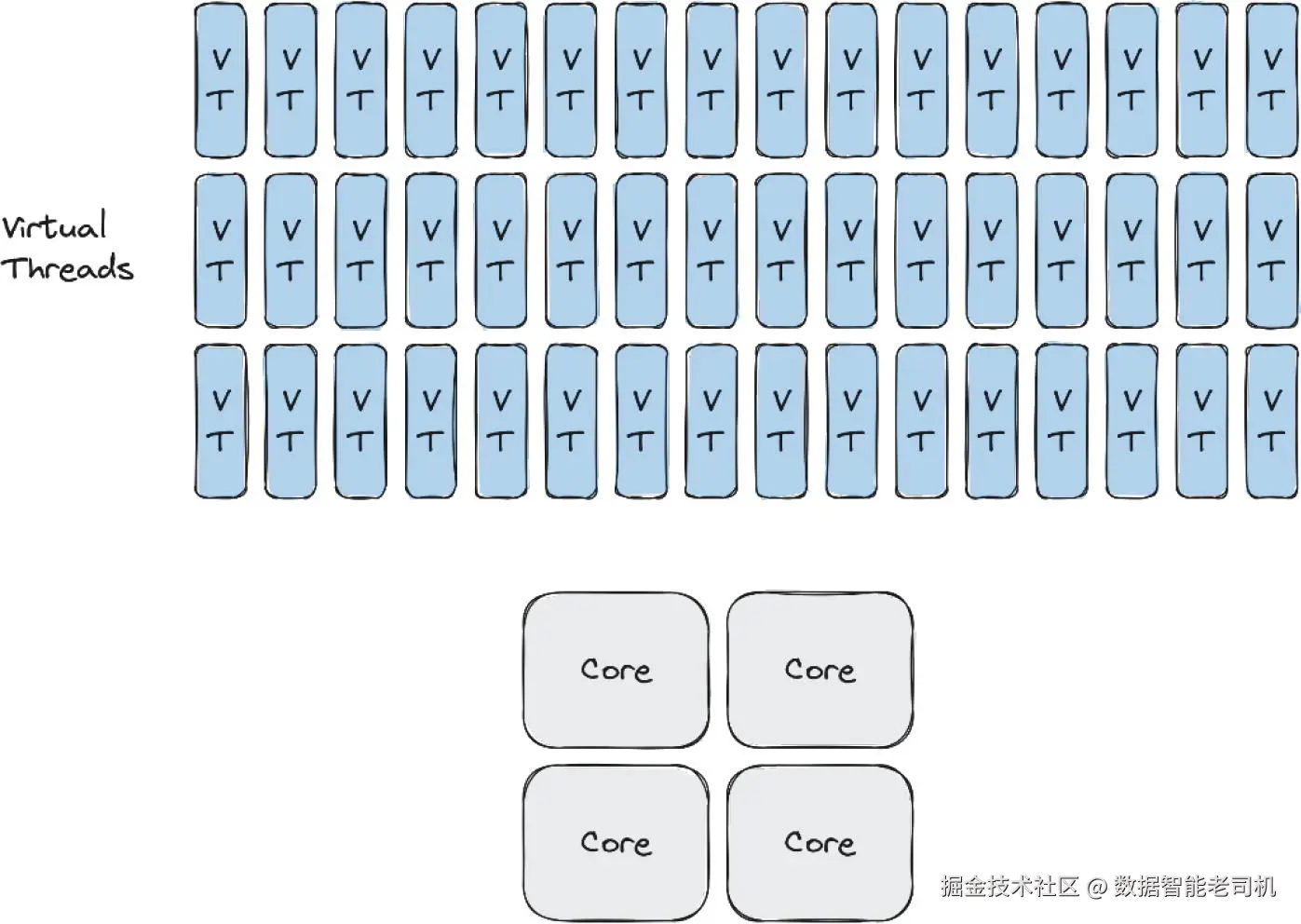
在前面的代码示例中,我们创建了一百万个线程。为了更直观地理解,请看图 1-2,我们创建的虚拟线程数量远远超过了可用的 CPU 核心数量。每个虚拟线程都需要在 CPU 核心上获得一定的时间才能真正运行其任务。虚拟线程的数量可以大大超过核心的数量。在下一节中,我们将看看系统资源是如何在所有这些虚拟线程之间共享的。
承载线程(Carrier Threads)
虚拟线程并不是直接运行在由操作系统管理的线程(平台线程)上,而是运行在所谓的"承载线程"上。承载线程本质上就是一个被指定用于运行虚拟线程的平台线程。它们之间的映射关系如图 1-3 所示。
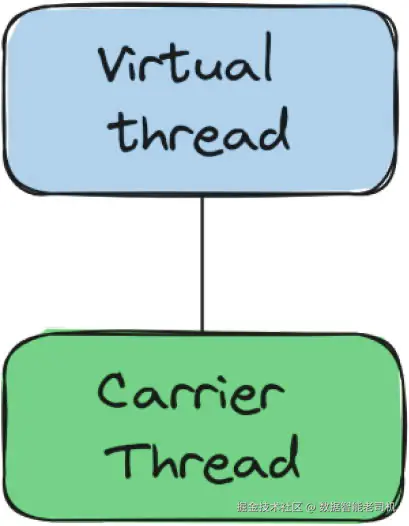
每个虚拟线程都会被分配到一个承载线程上运行。只有当虚拟线程被放置到承载线程上时,代码才会执行。每次创建虚拟线程时,它都会被添加到虚拟线程队列中,该队列中的线程最终会被调度到某个承载线程上执行。
为了更完整地展示这个过程,我们可以在之前的图示中加入虚拟线程队列以及操作系统线程(OS Threads),以呈现实际发生的情况。
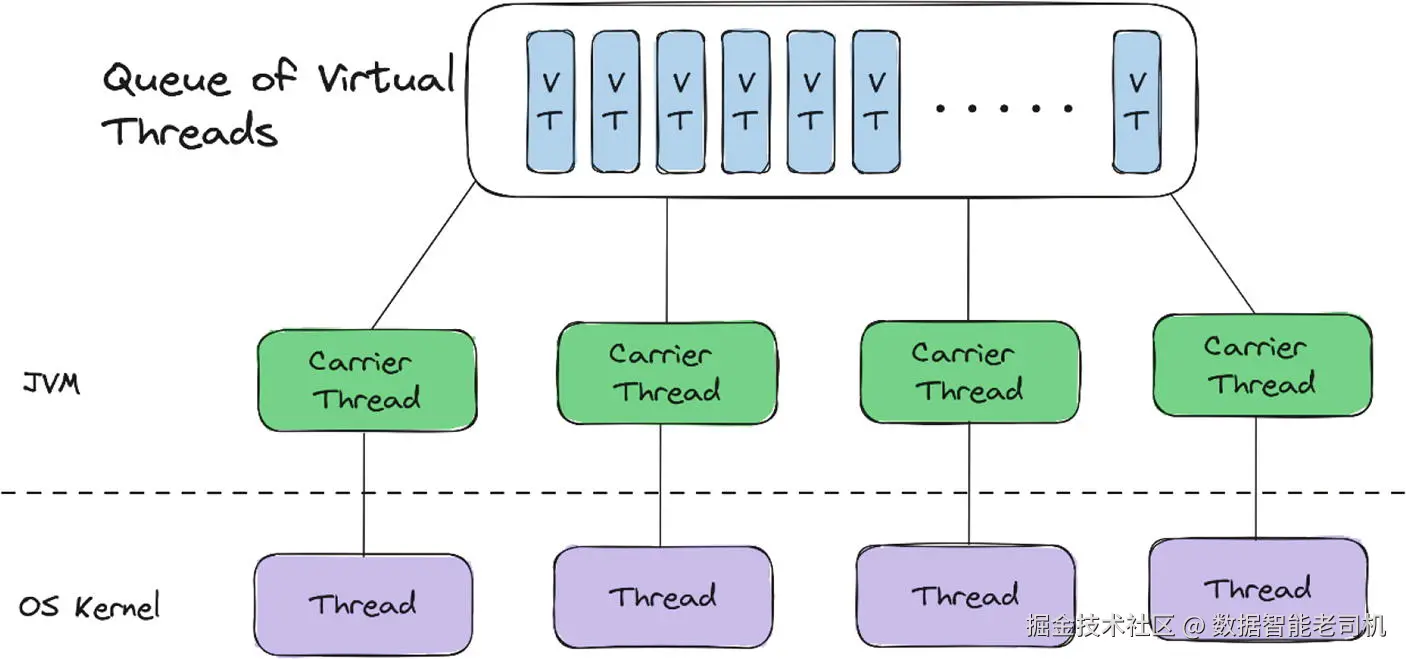
在图 1-4 中,你可以看到虚拟线程排在它们的队列中。它们按照先进先出(FIFO)的顺序被分配到承载线程上。承载线程来自一个专用的 ForkJoinPool,这些承载线程实际上就是平台线程,而平台线程本质上是系统线程的轻量封装。
默认情况下,你会得到与系统核心数相同数量的承载线程。如果你有一个四核系统,你将得到四个承载线程。你可以通过以下属性更改启动时的承载线程数量:
ini
jdk.virtualThreadScheduler.parallelism=5这个属性可以作为系统属性使用,或者作为 VM 启动参数传入应用程序。如果将此并行度值设置为 5,应用程序将有五个承载线程。如果你希望保留部分核心给其他进程,这个设置会很有用。你也可以将其设置为高于核心数的值,但这样承载线程就需要更频繁地共享核心,这可能会导致性能下降。因此,请务必测量应用程序的性能。
因为虚拟线程本质上运行在平台线程之上,它们不可能比普通平台线程更快。这是一个常见的误解,但现在你应该理解虚拟线程是如何完成任务的。
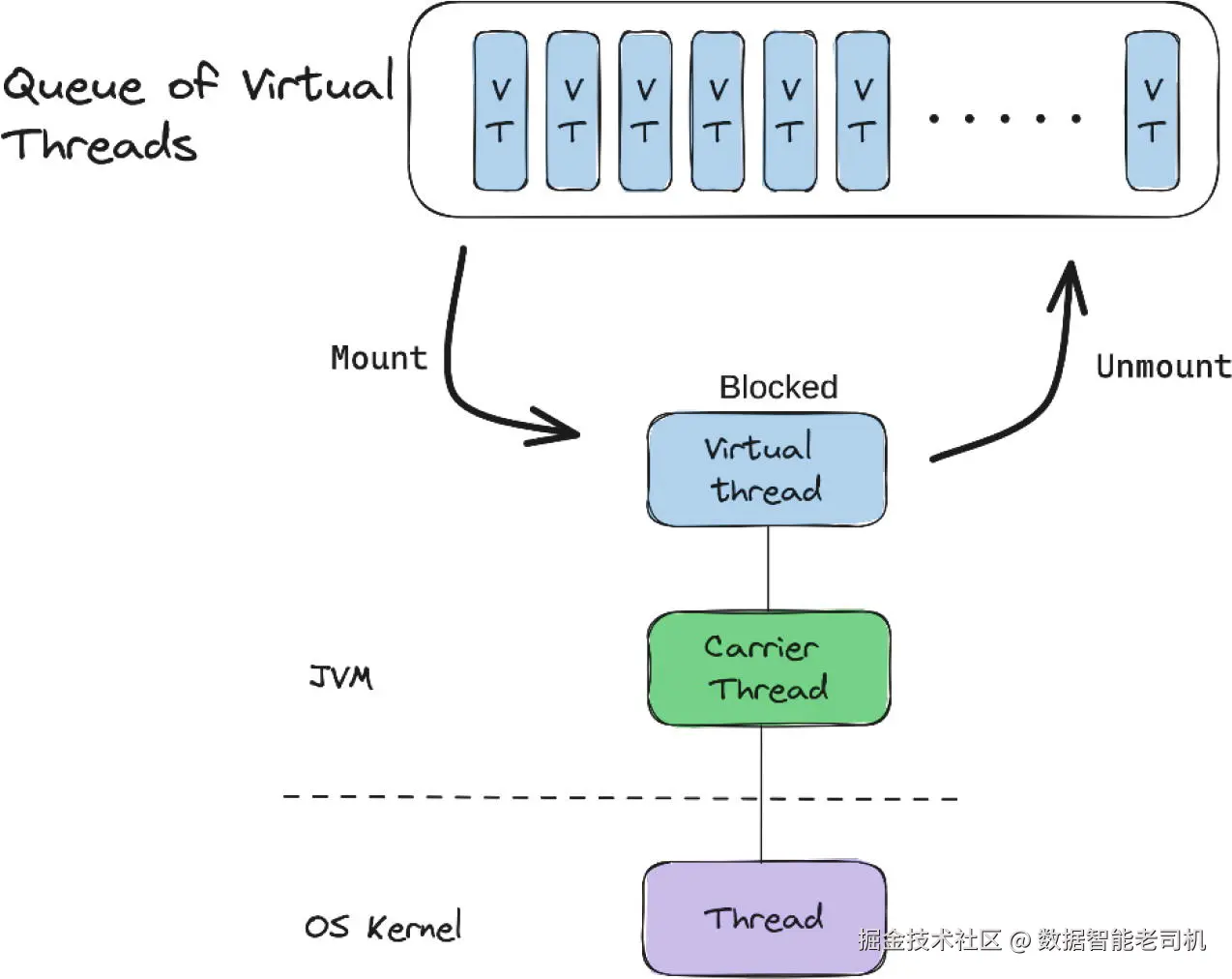
挂载和卸载(Mounting and Unmounting)
在上一节中,你了解到虚拟线程运行在承载线程上。承载线程执行来自虚拟线程的代码。但是,承载线程如何知道何时从一个虚拟线程切换到另一个虚拟线程呢?
虚拟线程会一直运行在承载线程上,直到它遇到一个阻塞方法。如果没有阻塞方法,虚拟线程会一直占用承载线程,基本上就变成了一个平台线程,并且还带有虚拟线程的开销。
将虚拟线程移入或移出承载线程的机制被称为 挂载和卸载(Mounting and Unmounting) 。当虚拟线程遇到阻塞方法(例如调用数据库)时,它会被卸载,这样承载线程就可以腾出位置运行一个新的虚拟线程。旧虚拟线程的栈帧会从承载线程的内存复制到堆中,而新虚拟线程的栈帧会从堆中复制到承载线程中。
这是虚拟线程的一大亮点。挂载和卸载过程确保了承载线程这种昂贵的资源始终在执行任务 。承载线程不再被阻塞、闲置,而是去运行一个新的虚拟线程,而被阻塞的虚拟线程则在堆中等待解除阻塞。虚拟线程非常擅长等待。当虚拟线程解除阻塞后,它会重新进入队列,等待再次被调度执行。图 1-5 展示了这一过程的完整循环。
固定(Pinned)的虚拟线程
Java 的某些特性目前还不能完全兼容虚拟线程。如果虚拟线程进入 synchronized 块 、调用 object.wait() ,或通过 Java Native Interface (JNI) 调用本地代码,虚拟线程就无法卸载(unmount)。此时,虚拟线程会绑定在某个 承载线程(carrier thread) 上,导致不仅虚拟线程被阻塞,连承载线程也被阻塞。当这种情况发生时,我们称虚拟线程被"固定(pinned)"在承载线程上。如果这种情况只持续很短时间,问题不大,但如果固定时间较长,会引发性能下降。
为了防止性能下降,JVM 会通过 创建额外的临时承载线程 来帮你缓解问题。这些新建的承载线程会运行新的虚拟线程,而原来的承载线程因阻塞暂时无法运行虚拟线程。当不再需要这些临时承载线程时,它们会被回收。默认情况下,承载线程池的最大大小为 256,你可以通过以下属性修改默认值:
ini
jdk.virtualThreadScheduler.maxPoolSize=256该属性可以作为 系统属性 或 VM 启动参数 传递。
如果你想检测虚拟线程是否被固定,可以使用以下属性(作为 VM 启动参数或系统属性):
ini
jdk.tracePinnedThreads=full或
ini
jdk.tracePinnedThreads=short这两个选项都会在虚拟线程被固定时输出日志,但信息量不同:
- short 模式只显示简要信息
- full 模式显示详细的调用堆栈信息
例如,下面这段代码会导致虚拟线程固定:
java
public class DemoPinnedThread {
public static void main(String[] args) throws InterruptedException {
Main main = new Main();
Thread thread = Thread.startVirtualThread(() -> DemoPinnedThread.causesPinning(0));
Thread thread1 = Thread.startVirtualThread(() -> DemoPinnedThread.causesPinning(1));
Thread thread2 = Thread.startVirtualThread(() -> DemoPinnedThread.causesPinning(2));
thread.join();
thread1.join();
thread2.join();
}
static synchronized public void causesPinning(int i) {
System.out.println("i = " + i);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}当 causesPinning 方法被调用时,虚拟线程会被固定,因为它在 synchronized 块 中执行了 Thread.sleep()。
在 full 模式下,输出会包含完整堆栈,例如:
less
i = 0
Thread[#31,ForkJoinPool-1-worker-1,5,CarrierThreads]
java.base/java.lang.VirtualThread$VThreadContinuation.onPinned(VirtualThread.java:185)
java.base/jdk.internal.vm.Continuation.onPinned0(Continuation.java:393)
java.base/java.lang.VirtualThread.parkNanos(VirtualThread.java:631)
...
org.example.DemoPinnedThread.causesPinning(DemoPinnedThread.java:24) <== monitors:1而 short 模式只显示简略信息:
ini
i = 0
Thread[#31,ForkJoinPool-1-worker-1,5,CarrierThreads]
org.example.DemoPinnedThread.causesPinning(DemoPinnedThread.java:24) <== monitors:1实战建议:
- full 模式 适用于排查 第三方库 导致的固定问题
- short 模式 适合你自己控制线程的情况
何时不该使用虚拟线程?
虚拟线程是 Java 的强大新特性,但并非万能,在以下场景中不建议使用:
① 不要对虚拟线程使用线程池
虚拟线程的设计目标是 廉价且可大量创建,如果你发现自己想对虚拟线程做池化,说明你的设计需要调整。例如:
ini
ThreadFactory factory = Thread.ofVirtual().factory();
try (ExecutorService vte = Executors.newFixedThreadPool(5, factory)) {
// 调用外部资源
}这种方式虽然能限制连接数,但不理想。更好的方式是使用 信号量(Semaphore) :
ini
public static void main(String[] args) {
Semaphore s = new Semaphore(10);
Runnable task = () -> {
try {
s.acquire();
// 调用外部资源
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
s.release();
}
};
try (ExecutorService vte = Executors.newVirtualThreadPerTaskExecutor()) {
for (int i = 0; i < 1000; i++) {
vte.submit(task);
}
}
}② 如果线程几乎不会阻塞,考虑用平台线程(OS 线程)
虚拟线程的优势在于 大量 I/O 阻塞场景 。如果线程 几乎不阻塞,平台线程反而更高效。
③ 如果线程频繁短暂阻塞,开销仍然存在
频繁阻塞会导致虚拟线程 频繁挂载/卸载(mount/unmount) ,虽然很快,但并非零成本。此类场景需要用 基准测试(JMH) 测量性能。
✅ 总结
- Java 21 引入虚拟线程,可实现 线程即任务(Thread-per-task) 模型
- 虚拟线程运行在 承载线程(carrier thread) 上,由 JVM 调度
- 遇到 synchronized、JNI、本地阻塞操作 时会导致 固定(pinning) ,影响性能
- 不要对虚拟线程池化,控制并发用信号量
- 适合 高并发 I/O 阻塞 场景,不适合 CPU 密集且无阻塞 的场景