结构化并发(Structured Concurrency)是 Project Loom 发布的第二项成果,就在我们在第 1 章介绍的虚拟线程之后。本章我们将:
- 了解什么是结构化并发
- 通过示例使用结构化并发
- 深入了解 StructuredTaskScope 提供的底层 API
- 创建自定义的 StructuredTaskScope 实现
- 了解结构化并发的替代方案
什么是结构化并发?
结构化并发让你可以通过明确的分支点(将执行拆分为多个任务)以及结果重新合并的点来推理并发代码。它对于并发的意义,就像 for 循环和 if 分支对于结构化编程的意义一样。结构化并发允许你将并发操作的生命周期限制在特定的作用域内。在结构化编程中,如果我们有一个 if 语句,那么在 if 块内部定义的变量的生命周期仅限于该块,它们无法泄露到 if 块之外。对于结构化并发也是一样:作用域之外,这些操作不存在,从而保证不会有"游离"的执行线程,避免内存泄漏或无谓的 CPU 消耗。
要充分理解结构化并发的威力和易用性,我们需要先看看它的对立面------非结构化并发是什么。
非结构化并发
先来看一下 Java 中的非结构化并发。以下示例使用了天气 API,我们尝试获取纽约的当前天气、天气预报和历史数据,通过向 ExecutorService 提交三条独立请求实现:
kotlin
try (ExecutorService es = Executors.newVirtualThreadPerTaskExecutor()) {
var currentFuture = es.submit(this::getCurrent);
var forecastFuture = es.submit(this::getForecast);
var historyFuture = es.submit(this::getHistory);
return new Result(currentFuture.get(),
forecastFuture.get(),
historyFuture.get());
}如果其中某个请求失败怎么办?我们可能无法满足用户请求,因为并非所有数据都可用。但我们无法终止另外两个请求,尽管我们永远不会使用它们的结果。
同样,如果用户决定取消请求,我们也无法取消提交给 ExecutorService 的三个任务。
事情会根据哪个线程先启动以及哪个线程抛出异常而变得更加复杂,但线程泄漏仍然可能发生。
通过 ExecutorService 执行的任务通常被视为非结构化任务。它们是独立调用的,并且与同一 ExecutorService 启动的其他任务没有直接关系。
结构化并发
了解了非结构化并发后,我们来看看结构化并发如何改进它。结构化并发的核心思想是:一个任务可以包含子任务,而子任务本身又可以包含子任务,因此实际上形成了一棵树状的任务结构。该结构的生命周期绑定于定义它的代码块。在 Java 的结构化并发 API 中,这称为 StructuredTaskScope,我们将在下一节详细介绍。当这个作用域关闭时,保证所有任务和子任务要么已完成,要么已被取消。
StructuredTaskScope
StructuredTaskScope<T> 是位于 java.util.concurrent 包中的结构化并发 API 的核心类。它是一个小型 API,仅包含 6 个公共方法和 2 个受保护方法:
csharp
public <U extends T> Subtask<U> fork(Callable<? extends U> task);
public StructuredTaskScope<T> join();
public StructuredTaskScope<T> joinUntil(Instant deadline);
public void close();
public void shutdown();
public boolean isShutdown();
protected void ensureOwnerAndJoined();
protected void handleComplete(StructuredTaskScope.SubTask<? extends T> subTask);StructuredTaskScope 基本示例
下面是一个使用 StructuredTaskScope 的基础示例,仅用于说明。实际中,你更可能使用 StructuredTaskScope 的直接子类,它们对 handleComplete 方法有不同实现,或者你也可以自己编写子类(后面会讲到)。一般情况下不必自定义子类,但如果现有实现不满足需求,你可以自由创建自己的实现。
dart
try (var scope = new StructuredTaskScope<String>()) {
Supplier<String> currentSubtask = scope.fork(this::getCurrent);
Supplier<String> forecastSubtask = scope.fork(this::getForecast);
Supplier<String> historySubtask = scope.fork(this::getHistory);
scope.join();
return new Result(currentSubtask.get(),
forecastSubtask.get(),
historySubtask.get());
}从结构上来看,它可以表示为一棵树状的任务结构。
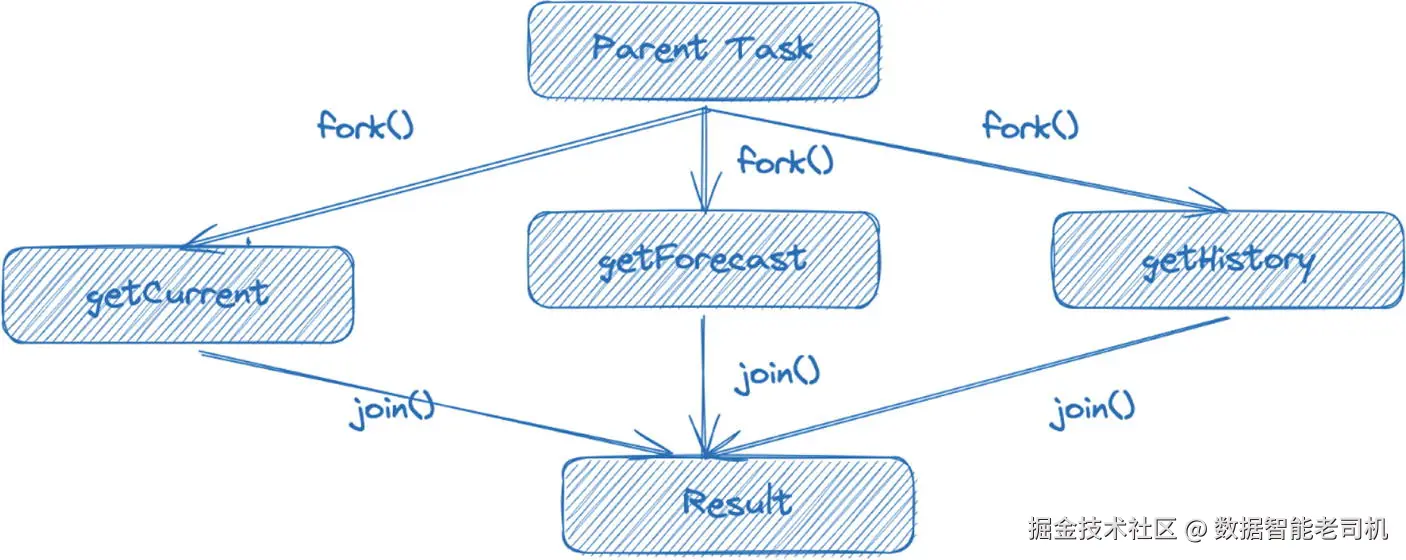
让我们拆解一下这里发生的事情。首先,我们在 try-with-resources 块中创建了一个新的 StructuredTaskScope。这是很重要的,因为 StructuredTaskScope 实现了 AutoCloseable 接口。该接口保证了在 try-with-resources 块执行完毕后,运行时会自动调用 StructuredTaskScope 的 close 方法。
接下来,我们通过将要执行的方法传递给 fork 方法,指定希望并发执行的三个任务。注意,fork 方法会返回一个 SubTask 对象,不过推荐将其强制转换为 Supplier,因为 SubTask 实现了 Supplier 接口。
最后,我们调用 join 方法。这会使当前线程等待作用域内的所有任务完成,或者作用域被关闭。
当所有任务完成后,线程继续执行,我们可以调用子任务的 get() 方法来获取结果。
由此可见,结构化并发的一般流程如下:
- 创建任务作用域(task scope),作为所有子任务的根。
- 在该作用域中创建任意数量的子任务。
- 创建作用域的线程加入该作用域(同时隐式加入所有子任务)。
- 创建作用域的线程阻塞,直到所有子任务完成。
- 创建作用域的线程处理可能的错误。
- 创建作用域的线程在完成后关闭作用域(自动完成)。
子任务(Subtasks)
我们需要进一步了解 join 方法返回的 Subtask<T> 接口,它也位于 java.util.concurrent 包中。
乍一看,join 方法似乎返回一个 Supplier<T>,这在本质上是正确的,因为 Subtask 实现了 Supplier<T> 函数式接口。语言设计者更倾向于将 join 的结果强制转换为 Supplier 而不是 SubTask。
Subtask 本身是一个接口,更准确地说是一个 sealed 接口 。Sealed 接口允许更精细地控制哪些类可以实现它。在 Subtask 的情况下,只允许一个类实现它:SubtaskImpl。
csharp
public sealed interface Subtask<T> extends Supplier<T> permits SubtaskImpl有人可能会说,如果只允许一个子类,那么接口不如直接实现为 final 类。但使用接口保留了未来扩展的可能性------将来只需在 permits 中加入新的类即可,而 final 类无法做到这一点。这是一个很好的示例,说明如何为未来扩展保持开放而不必现在就担心。
Subtask 持有一个枚举 State,表示子任务结果的状态,有三种可能值:
UNAVAILABLE:尚未完成,或任务作用域关闭后完成SUCCESS:已完成,结果可用FAILED:完成时抛出异常,结果不可用
当子任务状态为 SUCCESS 时,可以通过调用 get() 获取结果;如果尚未完成或失败,则调用 get() 会抛出 IllegalStateException。
如果状态为 FAILED,可以通过 exception() 方法获取执行期间抛出的异常;如果尚未完成或已成功完成,调用 exception() 也会抛出 IllegalStateException。
SubtaskImpl 是唯一允许实现 Subtask 接口的类,定义如下:
csharp
private static final class SubtaskImpl<T> implements Subtask<T>, Runnable可以看到,它实现了 Runnable 接口。当 StructuredTaskScope 的 fork() 方法被调用时,它会接收一个 Callable,然后创建 SubtaskImpl 实例,并在 run() 方法中调用 call() 执行任务并获取结果,同时记录异常以便后续获取。
默认使用虚拟线程
结构化并发中的任务默认由 虚拟线程 支持。在上一章中,你已经了解了虚拟线程相比平台线程的诸多优势。因此虚拟线程作为默认选项也不足为奇。
StructuredTaskScope 的默认构造函数如下:
csharp
public StructuredTaskScope() {
this(null, Thread.ofVirtual().factory());
}当然,你也可以使用平台线程,只需调用不同的构造函数:
arduino
public StructuredTaskScope(String name, ThreadFactory factory)如果想使用平台线程,可以这样:
csharp
public StructuredTaskScope() {
this(null, Thread.ofPlatform().factory());
}不过除非有充分理由,否则不推荐使用平台线程。
处理超时
到目前为止,join 方法会等待任务完成,不管需要多长时间。但通常你希望限制等待时间,此时可以使用 joinUntil 方法,提供一个 Instant 类型的最大等待时间:
java
public StructuredTaskScope<T> joinUntil(Instant deadline)
throws InterruptedException, TimeoutException结构化并发策略(Structured Concurrency Policies)
正如前文所述,StructuredTaskScope 并非设计为直接使用。它提供了两个子类实现两种并发设计模式:Invoke All 和 Invoke Any 。这些模式并不新鲜,在 Java 8 的 ExecutorService 中就已经存在,但行为可能因线程池类型和容量不同而有所差异。结构化并发确保任务的行为和作用域定义明确。
Invoke All 模式
Invoke All 是最常用的模式,允许启动多个子任务,然后等待所有任务成功完成,或任意子任务抛出异常。
该模式由 StructuredTaskScope 的静态内部类 ShutdownOnFailure 实现。如果任意子任务抛出异常,则认为无法提供有效结果,整个作用域关闭------因此命名为 ShutdownOnFailure。
之前的示例可以改写为使用 ShutdownOnFailure 策略:
kotlin
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) { // 1
Supplier<CurrentWeather> currentSubtask = scope.fork(this::getCurrent); // 2
Supplier<Forecast> forecastSubtask = scope.fork(this::getForecast);
Supplier<History> historySubtask = scope.fork(this::getHistory);
scope.join(); // 3
scope.throwIfFailed(); // 4
return new Result(currentSubtask.get(), // 5
forecastSubtask.get(),
historySubtask.get());
}流程解析:
- 创建一个类型为
ShutdownOnFailure的StructuredTaskScope。 - fork 三个子任务。
- 调用
scope.join(),让拥有作用域的线程等待所有子任务完成或抛出异常。 - 当线程继续执行(所有子任务完成或取消)时,通过
scope.throwIfFailed()检查是否有异常抛出。 - 此时可以安全调用子任务的
get()方法,因为确认没有异常发生。
注意我们将作用域定义为 StructuredTaskScope.ShutdownOnFailure。ShutdownOnFailure 是 StructuredTaskScope 内的静态 final 类,它重写了受保护方法 handleComplete(Subtask) 来实现与 ShutdownOnSuccess 不同的行为:
typescript
@Override
protected void handleComplete(Subtask<?> subtask) {
if (subtask.state() == Subtask.State.FAILED
&& firstException == null
&& FIRST_EXCEPTION.compareAndSet(this, null, subtask.exception())) {
super.shutdown();
}
}一旦第一个子任务失败,StructuredTaskScope 就会调用 shutdown(),取消所有仍在执行的子任务,并等待所有子任务取消完成后再关闭上下文,无需手动干预,极大简化了代码。
这种模式通常用于需要同时获取多组相互关联的数据。例如,客户详情页包含客户地址、未完成订单列表、最近完成订单列表、欠款余额及退货列表。
通过结构化并发,我们可以并发获取这些信息,同时仍保证在继续执行前所有信息已被获取。它提供了一种非常易于阅读、理解和推理的顺序式代码流。
Invoke Any 模式
与 Invoke All 模式相反,Invoke Any 模式是一种竞赛(race):最先返回结果的任务获胜。其思路是同时启动多个任务,一旦任意任务返回结果,仍在执行的其他任务将被取消。如果第一个结果是异常,则所有其他任务也会被取消,最终的执行结果就是这个异常。
示例代码如下:
kotlin
try (var scope = new StructuredTaskScope.ShutdownOnSuccess<>()) { // 1
scope.fork(this::getWeatherData); // 2
scope.fork(this::getOpenWeatherData);
scope.join(); // 3
return scope.result(); // 4
}在这个示例中,我们从两个不同的 API 获取天气数据。我们并不在意具体使用哪个 API,而是选择响应最快的那个。这意味着每次调用该方法时,返回的数据可能来自不同的 API,重点是速度,而不是具体数据。
类似的情境也可以应用于导航,例如从 A 点到 B 点获取路线。可以向多个提供商(如 Google Maps 和 Apple Maps)请求路线,并使用最先响应的结果。
代码流程解析:
- 创建类型为
ShutdownOnSuccess的StructuredTaskScope。 - fork 子任务,不需要保存它们的返回值引用,因为最多只有一个结果可用,API 会帮我们保存该结果。
- 调用
scope.join(),等待第一个结果返回。 - 返回结果,通过
scope.result()获取。如果没有结果(没有子任务成功完成),默认会抛出ExecutionException。可以通过重写带参数的result()方法自定义异常:
php
public <X extends Throwable> T result(Function<Throwable, ? extends X> esf) throws X一旦任意子任务返回结果,StructuredTaskScope 会自动取消其他子任务,无需手动干预,非常方便。
自定义策略实现
假设我们计划去滑雪,希望确保所选地区有雪。可以创建一个自定义任务作用域,遍历若干可能的城市,查询天气 API 是否有雪。
自定义 SnowPolicy 示例:
scala
public class SnowScope<T> extends StructuredTaskScope<T> {
private List<T> results = Collections.synchronizedList(new ArrayList<>());
@Override
protected void handleComplete(Subtask<? extends T> subtask) {
if (subtask.state() == Subtask.State.SUCCESS) {
T result = subtask.get();
results.add(result);
}
}
public List<T> results() {
return this.results;
}
}只有成功返回的任务会被计入返回结果。
使用示例:
scss
public class CustomPolicyExample {
private static final String API_KEY = "YOUR API KEY";
public static void main(String... args) throws Exception {
if (args.length == 0) {
System.out.println("Usage: java CustomPolicyExample <space-separated list of cities>");
System.exit(0);
}
new CustomPolicyExample().run(List.of(args));
}
private void run(List<String> cities) throws Exception {
try(var scope = new SnowScope<CityWeather>()) {
for (var city : cities) {
scope.fork(() -> getWeather(city));
}
scope.join();
scope.results().stream()
.filter(e -> e.current().condition().text().contains("snow"))
.collect(Collectors.toList())
.forEach(System.out::println);
}
}
private CityWeather getWeather(String city) throws Exception {
var uri = StringTemplate.STR."http://api.weatherapi.com/v1/current.json?key={API_KEY}&q={city}";
var request = HttpRequest.newBuilder()
.uri(new URI(uri))
.GET()
.build();
try(var client = HttpClient.newHttpClient()) {
var response = client.send(request, HttpResponse.BodyHandlers.ofString());
CityWeather cw = new Gson().fromJson(response.body(), CityWeather.class);
return cw;
}
}
}程序从命令行接收城市列表,创建自定义作用域,对每个城市调用 fork,执行 getWeather 方法,然后调用 join 等待所有任务完成,最后筛选出包含"snow"的结果。
注意,我们使用 Gson 解析 API 返回的 JSON 数据,需要在 API_KEY 字段中设置自己的 API 密钥。
结构化并发的替代方案
结构化并发并非全新概念,Java 已经有一些替代实现。在 JEP-428(最初描述结构化并发的 Java Enhancement Proposal)中提到,其目标 不是 替换 java.util.concurrent 中的任何并发构造,也不是定义 Java 的最终结构化并发 API。
常见的替代方案包括:
- Completable Futures
- 响应式编程(Reactive Programming)
Completable Futures
Completable Futures 是 Java 8 引入的,提供了异步实现的 Future 接口,并允许操作链式调用。它基于 CompletionStage 概念,一个阶段(stage)可以被另一个阶段触发。
示例:
ini
private void run() throws Exception {
CompletableFuture<String> hello = CompletableFuture.supplyAsync(() -> "Hello");
CompletableFuture<String> world = CompletableFuture.supplyAsync(() -> "World!");
CompletableFuture<String> result = hello.thenCombine(world, (a, b) -> a + "," + b);
System.out.println(result.get());
}这里定义了两个 CompletionStage,第三个阶段组合前两个阶段的结果并执行函数,最终调用 get() 获取值。
最初的结构化并发设计中,fork 操作返回的是 Future,后来改为 Subtask,因为 fork 的结果已经是最终值,而 CompletableFuture 更适合用于尚未完成的异步计算。
响应式编程
响应式编程是近年来流行的编程范式,基于 2013 年发布的 Reactive Manifesto,核心特性包括:响应性(Responsiveness)、弹性(Resilience)、弹性伸缩(Elasticity)、消息驱动(Message-driven)。
概念包括:生产者(Producers)、消费者(Consumers)、处理器(Processors)、流(Streams)。
基本思路是响应事件而非等待事件,以非阻塞方式处理异步数据。
Java 中常用框架:
- RxJava
- Project Reactor
- Akka
- Spring Reactive Streams
示例:
typescript
import reactor.core.publisher.Flux;
import reactor.core.scheduler.Schedulers;
public class ReactiveExample {
public static void main(String[] args) {
Flux<String> flux = Flux.just("R", "e", "a", "c", "t", "i", "v", "e"); // 1
flux
.map(s -> s.toUpperCase()) // 2
.publishOn(Schedulers.parallel()) // 3
.subscribe(System.out::println); // 4
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}流程:创建数据流(1)、处理(2)、发布(3)、订阅(4)。
缺点:
- 学习曲线陡峭,需要不同思维方式
- 增加应用复杂性,难以推理程序流程
- 异步和并发行为使调试困难
总结
本章介绍了 Java 的结构化并发 API,讲解了主要组件及基本流程,展示了默认策略及自定义策略的实现,并对比了 Completable Futures 和响应式编程作为替代方案。结构化并发结合虚拟线程,使并发编程更易编写、调试和理解,同时避免了响应式编程的一些复杂性。