作者:望宸
人工智能不仅仅关乎生产力,还关乎人际关系。
人与人工智能的关系通常分为两大类:有用的助手和虚构的角色。
ChatGPT、Gemini、Claude 和 Cursor 等助手在解决任务方面非常高效。它们的成功毋庸置疑,仅 ChatGPT 目前就拥有近 3 亿日活跃用户。然而,它们之间的关系仍然停留在交易层面,缺乏情感深度。
以 Character.ai、Talkie 和 MidReal 为代表的虚构角色,凭借引人入胜的叙事和情感共鸣吸引着用户。用户最初对这些虚构世界充满热情。然而,随着他们沉浸其中,长时间的沉浸往往会让他们感到空虚,与现实脱节,最终渴望逃离。这些本应安慰他们的关系,却反而放大了他们未解决的现实世界问题。
Macaron AI 定位的是第三种方式:哆啦A梦关系。通过长期记忆+强化学习的技术,将实用的解决方案与情感的温暖融为一体。
以上摘自 Macaron AI CEO Chen Kaijie 发表在 Macaron 官网的博客【1】,我们原封不动的搬运过来,旨在以最原生的方式,了解 Macaron AI 的初衷。本文将通过分析其在技术上的不同和若干用例,进一步挖掘 Macaron AI 的产品价值。
目录
01 6 个 Q&A,快速了解 Macaron AI
02 技术上,Macaron AI 有何不同03 2 个用例,实测 Macaron AI04 建议
6 个 Q&A,快速了解 Macaron AI
Macaron AI CEO Chen Kaijie 在推出 Macaron 之前,创立过 MidReal,是一个覆盖全球超过 300 万用户的 AI 故事讲述平台。还使用过 GPT-2 构建 AI 游戏代理,以及一家规模约为 150 万美元 ARR 的机器人公司。可见,该团队对 AI APP 有着较充分的认知和实践。
我们通过 Q&A 的方式,快速了解下 Macaron AI 的不同。
Q1:同样是对话界面,Macaron AI 的定位和其他通用智能体和陪护型智能体有什么不同?
A:大多数通用智能体定位生产力工具,帮用户写文档、查资料、总结信息。陪护型智能体提供情绪价值。而 Macaron AI 介于两者之间,强调长期陪伴、情感共鸣和主动帮助。
Q2:产品功能上,Macaron AI 有什么独特之处?
A:Macaron AI 引入了长期记忆(Deep Memory),并基于自然语言和对话,为用户生成各类小工具(Mini Apps):
- 记忆系统:它会长期记住用户的偏好、习惯、目标,甚至是情绪反应,并在后续对话中主动调用。比如用户之前提过"我在存钱准备旅行",下次再谈到消费,它就会提醒是否考虑预算。
- 自动生成的小应用:它能把用户的需求工具化,生成轻量化应用,比如账单分类、日程提醒、学习进度追踪,而不是仅仅给一段文字回答。这点和通义千问中的"发现智能体"很像,提供一个工具商店,也可以根据对话自行创建个性化工具,但 Macaron 是在强化学习驱动下自动生成,更贴近用户习惯。
Q3:Macaron AI 使用了哪些核心技术?
A:主要体现在三点:
- 长期记忆:Macaron "内建深度记忆",会智能地记忆用户的关键数据。
- 强化学习:不仅通过系统提示次微调模型输出,而是通过 RL 机制来动态优化:记什么、不记什么,什么时候调用记忆。
- 上下文分块处理:当输入或输出很长时,它会分块处理,并结合记忆生成结果,避免遗忘或跑题。
Macaron 的核心技术,可以理解为,都是围绕"记忆"这一产品的设计基石所展开的。
Q4:如何理解"内建深度记忆" ?
"内建深度记忆"意味着:记忆是系统架构的一部分,可以在对话上下文之外,主动决定什么时候写入 / 读取 / 忘掉,它和 Agent 的长期目标是紧密结合、共同优化,以实现 Macaron 最懂你的终极目标,不是单纯的上下文信息存储。
从官方披露的信息来看,"内建深度记忆":
- 默认启用:记忆是 Macaron 的设计基石。
- 选择性保存:通过 RL 判断哪些信息值得长期保留。
- 主动调用:在生成回应时,记忆会主动被嵌入进推理路径里,类似 Agentic Memory 的思路,我们可以把"内建深度记忆"理解为 Agentic Memory 的产品化落地。
从技术视角来看,Macaron AI 是把记忆作为核心逻辑,并和 RL 框架耦合紧密所打造的产品。
Q5:这种设计会给用户带来怎样的体验差异?
A:可以想象两个场景:
- 在 ChatGPT 上问:"帮我记一下生活开销。" 然后它可能询问要统计哪些开销、如何分类,最后提供一个表格。
- 在 Macaron 上说:"最近开销有点大。" 它可能会:
-
- 主动问你要不要分类统计开销;
-
- 自动生成一个"小账本工具";
-
- 下次你再聊消费时,它提醒你"餐饮已经占了 40%"。
这种体验差异,来自于 Macaron 的长期记忆 + 工具生成的机制。
Q6:用户可以删除特定的记忆吗?
A:记忆是 Macaron 的核心产品逻辑,官方未不提供删除单个回忆的选项,但是你可以尝试通过对话让 Macaron 忘记你说的某一点内容。这也是区别于其他提供记忆功能产品的不同点,例如 ChatGPT 考虑到用户隐私和数据安全,向用户提供了启用或禁用已保存记忆的选项。
技术上,Macaron AI 有何不同?
Macaron AI 目前公开的有关基础设施、算法方面的技术细节,还比较有限,主要是官方的一篇技术博客【2】。
成本优化
Macaron 通过自研的全同步强化学习 (All-Sync RL) 架构、LoRA 适配和自研的多卷积 DAPO 框架集成的协同作用,最大限度地减少 GPU 空闲时间,缩短训练时间。例如,之前需要 9 小时才能完成的典型步骤,现在只需1.5 小时即可完成。最终,在 DeepSeek 6710 亿参数的模型,仅使用 48 块 H100 GPU 就能完成训练,同等配置中通常需要 512 块。
记忆效果
采用自研的多卷积 DAPO 框架,取代标准的组策略优化 (GRPO),来构建记忆系统,该模型展现了在极长的生成序列中保持上下文和一致性的能力,并成功生成了完整的软件项目。例如,它生成了一个个性化的日常穿搭建议工具,该工具保留了用户偏好并与外部 API 正确集成。这种端到端的强化学习记忆方法代表了复杂、有状态代理开发领域的重大进步。
该记忆系统最初由 FireAct 验证。FireAct 是 Macaron 团队和 Karthik Narasimhan(原 GPT 论文合著者)、OpenAI 研究员姚舜宇,于 2023 年共同开展的一项研究。FireAct 首次通过实证证明,在复杂的推理任务中,通过强化学习对事后轨迹进行微调的智能体行为比基于提示的方法高出 77%。
处理长输入时,不像传统的 Long-Context LLM 直接输入所有内容,它用 Agentic Memory via RL,受单轮对话最大长度限制,分块结合记忆一步步处理。处理长输出时,也用 Agentic Memory via RL,结合问题和不断更新的记忆,逐步生成思考和最终答案。
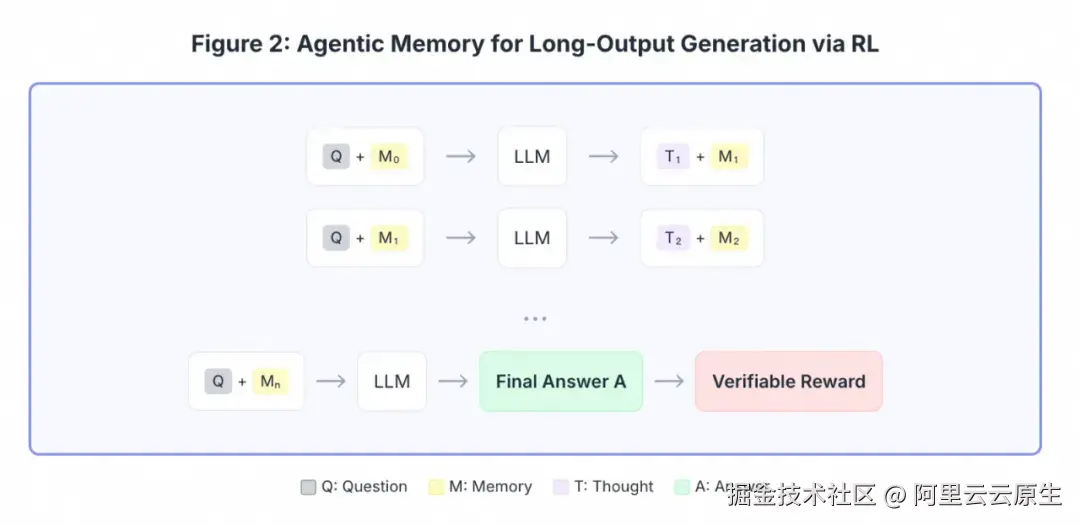
总结来看,Macaron 的记忆系统具备持久化、自我进化和优化的特点,即每次交互开始时,都会激活一个专门的记忆令牌(不同于标准的推理令牌),以触发实时检索、摘要和上下文更新。这个令牌不仅仅是回忆信息,还能帮助智能体根据学习到的奖励信号,决定要记住什么、何时更新以及如何运用记忆。
专有数据集
该数据集(超过 548 GB)收集自团队的上一个产品,互动故事平台 MidReal 上数百万次的用户互动,用于研究如何通过 RL 训练模型,使其更具吸引力、更好地推断隐性用户需求并建立更强大的信任。
通过精选代表这些互动中排名前 5% 的高质量子集,旨在进一步增强模型在记忆保留、工具利用和复杂对话技巧方面的能力。
Serverless
Macaron 生成的小工具均采用 Serverless 算力来支撑,算是经典的小程序场景。不同于微信、支付宝,企业来创建小程序。 Macaron 里的"小程序",是 C 端用户自然语言创建的小工具,量更大、流量更不可预估。因此 Serverless 算力,在成本上有巨大优势。
可见,若内建小工具或者说小程序,一旦成为 Personal Agent 这类产品形态的标配,Serverless 将在 AI Infra 中扮演更加重要的角色。
2 个用例,实测 Macaron AI
注册 Macaron 后,需要填写一些问题,比如"你最想如何度过完美的周末?"这些问题是 Macaron 找你聊天的开场白。
用例一:跑步助手
因为我在 onboarding 时,回答"你最想如何度过完美的周末?"的问题,选择了户外。因此,Macaron 一开始就会和聊户外的话题,然后非常主动的不断引导我,去制作一个工具。这应该是 Macaron 被 RL 后的效果,赋予了不同于通用智能体的性格、能力,以及更趋于制作小工具这一任务导向的特点。
于是,我提出了制作一个"跑步助手"的小工具,要求记录跑步距离、时长和配速,目的是想对比 Keep,看下其计数的准确度。目的是想看看 Macaron 的编程能力,尤其是公里数统计这一功能,不仅是简单的前端交互和本地计算。
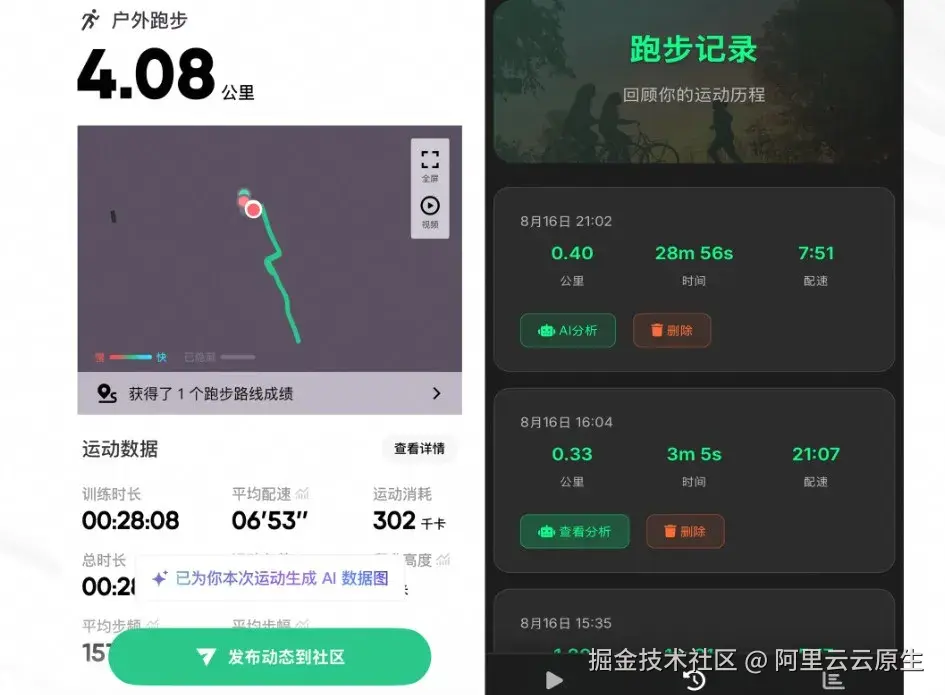
左一是 Keep,右一是 Macaron:
- 跑步时长:应该是直接调用手机的时间数据,所以差距较小。
- 公里数:因为需要对环境进行感知,面临 GPS 精度问题、传感器噪声、设备差异等挑战,需要进行不断的适配才能准确展示,因此两者差别很大
- 配速:基于跑步时长和公里数进行计算,因公里数的偏差导致配速偏差也大。
虽然数据准确度远不如 Keep,但是交互界面清晰、功能完备,还是不错的。随着底层模型编程能力的逐步提升,数据准确度会更高。
用例二:高温天气排行
这个用例是想测试 Macaron 的联网搜索能力,以及是否具备外部系统和数据的调用能力。
提示词:
1、覆盖中国省会、直辖市。
2、可选择具体日期查看温度排行榜。
3、按当天最高温进行计算,展示 TOP50 城市。
4、你可以用联网搜索或者调用第三方天气 API,无论哪一种,要保证排名是正确的。
Macaron 会有一个生成时间,一般是 15-20mins。这期间,他会继续和你沟通。可见对话和小工具的制作是异步的,使用的是两套大模型服务,对话做过 RL,小工具制作用的是底层模型的编码能力,底层算力大概率是 Serverless 形态,这种基于用户命令唤起的任务,天然适合 Serverless 算力。

结果如下:
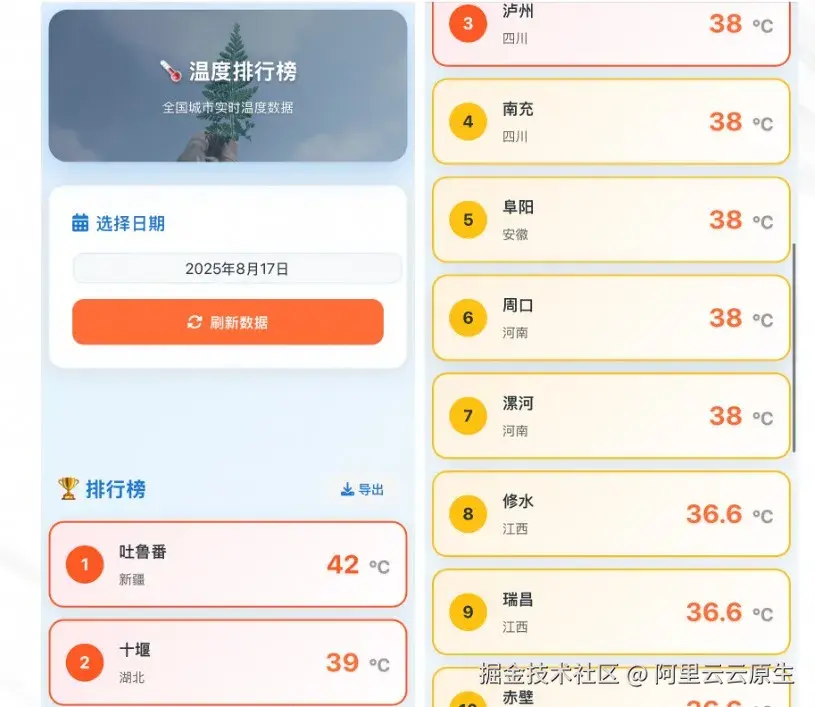
优点:
- 小工具的 icon 很"马卡龙"。
- 交互界面依旧有一定的交付标准,颜色配置不违和,界面不拥挤。
- 区分了前三城市和其他城市的颜色。
Macaron 可能利用 LoRA(低秩自适应),在小工具的交互界面和 icon 上做了增强,以获得稳定、视觉统一的效果。
缺点:
- 目标城市选错了,提示词要求是省会和市辖市,但是榜单中出现了其他城市。
- 对比苹果自带的天气 APP 和墨迹天气,温度数据有偏差,例如十堰、泸州的最高温分别是37摄氏度和35摄氏度,而最高温38度的杭州,却未在榜单中。
Macaron 生成小工具的编码能力,可能是底层大模型原生的,未做过增强和优化(若不符合事实,欢迎留言指正)。其技术博客中也未展示相关信息。
通过两个用例,我们对 Macaron 的产品能力有了大致的了解,对话能力很有特色,这是将记忆作为核心产品逻辑"所获的效果,如果用户有持续的耐心继续交流,相信会收获更多的小惊喜。小工具的效果,尤其在大模型联网搜索这一基础能力的增强上,还有不少的提升空间。
建议
整体上,个人觉得 Macaron 是非常创新的 Agent,提供了一种不一样的使用方式。我们和 Macaron 互动的越频繁、时间越长,收益会越多,粘性也会越大。这里提供两个小建议。
升级网关
当我第二天打开跑步助手的时候,出现了如下报错。可能是后端服务链路中的某一层返回了 404,例如:

- Nginx 反向代理配置错误:某种前端操作使得 location 路径匹配不到或代理转发 upstream 地址错误,导致 Nginx 找不到后端服务。
- 后端 API 服务未启动或挂掉:Nginx 正确配置,但对应的服务没有监听,返回 404。
- 网关/负载均衡层异常:网关路由未生效,或者 Pod 没有注册,导致 Nginx 无法找到目标。
- 静态资源路径问题:小程序可能请求某些静态文件(JS/CSS/图片),但 Nginx 没有对应目录或映射,返回 404。
无论是哪一种,本质是流量入口网关没有做到足够的服务可用性保障。如果整套后端是部署在 K8s 上,可以尝试迁移到 Higress 或其商业版上,在健康检查、重试 / 熔断 / 降级、灰度 / 多版本管理、可观测性上,提供增强服务。
引入更加成熟的编程能力
制作小工具是 Macaron 两大核心产品能力之一(另一个是基于 RL 的长期记忆能力)。因此,小工具的效果将很大程度上决定用户的留存和产品的传播。若引入更加成熟、稳定的编程能力,将极大地提升 Macaron 的产品体验。
2025杭州·云栖大会,来了!
9月24日至26日,杭州·云栖小镇
三场重磅主论坛
超110场聚合话题专场
40000平方米智能科技展区
点击此处免费注册领取云栖大会门票