前言
本系列分享前九篇分别讲述了
- LangChain&LangGraph的核心原理
- LangChain接入大模型的基本方法
- LangChain核心概念------链
- LangChain记忆存储与多轮对话机器人搭建
- LangChain接入工具基本流程
- LangChain Agent API快速搭建智能体
- LangChain多智能体浏览器自动化
- LangChain接入MCP实现流程
- LangChain从0到1搭建知识库
上篇文章我们使用LangChain从0到1手搓了一个RAG检索增强生成系统,实现了支持上传多个PDF文档,自动完成内容提取、文本切块、语义向量化、构建FAISS本地检索库并结合大模型进行问答的功能。本期分享是LangChain分享的最后一个项目(本期之后将分享LangGraph),我们将进一步丰富应用场景,结合所学的LangChain内置工具调用知识,完成一个CSV数据智能分析系统。
本系列分享是笔者结合自己学习工作中使用LangChain&LangGraph经验倾心编写,力求帮助大家体系化快速掌握LangChain&LangGraph AI Agent智能体开发的技能!大家感兴趣可以关注笔者掘金账号和系列专栏。更可关注笔者同名微信公众号: 大模型真好玩 , 每期分享涉及的代码均可在公众号私信: LangChain智能体开发获得。
一、环境搭建
本期实战内容我们同样通过Streamlit前端界面,结合LangChain框架实现一个通过自然语言指令分析CSV结构化数据d,包括统计查询、代码生成与图表绘制的数据智能分析系统。
项目的第一步还是要安装我们所需环境,在之前创建的anaconda虚拟环境langchainenv中执行如下命令安装相关依赖:
python
pip install langchain_experimental matplotlib tabulate
二、LangChain数据分析助手核心逻辑
- 引入相关依赖,编写如下代码。创建
langchain数据智能分析助手.py文件并写入如下代码。本项目自动生成数据分析代码并通过PythonAstREPLTool执行,使用pandas读取csv结构化数据,使用matplotlib绘制数据分析结果图。
python
import streamlit as st # 构建前端页面
import pandas as pd # 读取csv文件
from langchain.agents import create_tool_calling_agent, AgentExecutor
from langchain.chat_models import init_chat_model
from langchain_core.prompts import ChatPromptTemplate
from langchain_experimental.tools import PythonAstREPLTool # LagnChain内置工具,支持解析并执行Python代码
import matplotlib
import os- 设置向量模型和大语言模型,为保证Agent能力我们使用
DeepSeek-V3.1大语言模型,大家使用前需要申请DeepSeek的api_key,具体操作可见我的文章零门槛!手把手教你用VS Code + DeepSeek 免费玩转AI编程!(5分钟编写部署个人网站)。@st.cache_resource装饰器设置缓存防止多次初始化大模型。
python
# 初始化LLM
@st.cache_resource
def init_llm():
return init_chat_model(
"deepseek-chat", \
model_provider="deepseek",
api_key='你申请的DeepSeek api_key'
)- 初始化会话状态,与
streamlit网页交互的记录会保存在st.session_state中,csv_messages是存储历史对话信息的Python列表,df是存储pandas读取数据文件内容的变量。
python
def init_session_state():
if 'csv_messages' not in st.session_state:
st.session_state.csv_messages = []
if 'df' not in st.session_state:
st.session_state.df = None-
编写CSV处理核心逻辑,本质同样是LangChain构建智能体的三要素:工具 、模型 、提示词。
- 工具: 读取文件内容保存到
df变量中,同时构建PythonAstREPLTool代码执行工具并将df作为执行工具的内部变量方便代码引用。 - 大模型: 缓存的DeepSeek-V3.1大语言模型
- 提示词: 明确提示大模型可以访问df变量的数据,如果包含用户所给变量的数据则返回,没有则生成代码并执行生成数据。如果用户要求输入图片还需生成结果图片相关的代码。
三要素同样通过
create_tool_calling_agent和AgentExecutor构建智能体。(关于LangChain内部工具使用大家可参考我的系列文章:LangChain接入工具基本流程) - 工具: 读取文件内容保存到
python
# CSV处理函数
def get_csv_response(query: str) -> str:
if st.session_state.df is None:
return "请先上传CSV文件"
llm = init_llm()
locals_dict = {'df': st.session_state.df}
tools = [PythonAstREPLTool(locals=locals_dict)]
system = f"""给定一个pandas变量df, 回答用户的查询,以下是`df.head().to_markdown()`的输出供您参考,您可以访问完整的df数据框:
```
{st.session_state.df.head().to_markdown()}
```
一旦获得足够数据立即给出最终答案,否则使用df生成代码并调用所需工具。
如果用户要求制作图表,请将其保存为plot.png,并输出 GRAPH:<图表标题>。
示例:
```
plt.hist(df['Age'])
plt.xlabel('Age')
plt.ylabel('Count')
plt.title('Age Histogram')
plt.savefig('plot.png')
```
输出: GRAPH:Age histogram
问题:"""
prompt = ChatPromptTemplate.from_messages([
("system", system),
("placeholder", "{chat_history}"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"),
])
agent = create_tool_calling_agent(llm=llm, tools=tools, prompt=prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
return agent_executor.invoke({"input": query})['output']三、LangChain数据分析系统UI设计
- 完成核心逻辑的编写后,下一步我们编写主界面逻辑。本部分同样使用
streamlit库快速构建UI。左侧(宽度66.7%)包含聊天历史、输入框,输入框与csv_messages变量实时绑定,如果回答为图表或者表格会高亮展示。右侧(宽度33.3%)包含上传CSV存入session,显示预览,展示表结构/列类型,清除CSV/图像缓存的功能。
python
def main():
init_session_state()
# 主标题
st.markdown('<h1 class="main-header">🤖 LangChain 数据分析系统</h1>', unsafe_allow_html=True)
st.markdown(
'<div style="text-align: center; margin-bottom: 2rem; color: #666;">自动分析csv智能体系统</div>',
unsafe_allow_html=True)
col1, col2 = st.columns([2, 1])
with col1:
st.markdown("### 📈 数据分析对话")
# 显示数据状态
if st.session_state.df is not None:
st.markdown(
'<div class="info-card success-card"><span class="status-indicator status-ready">✅ 数据已加载完成</span></div>',
unsafe_allow_html=True)
else:
st.markdown(
'<div class="info-card warning-card"><span class="status-indicator status-waiting">⚠️ 请先上传CSV文件</span></div>',
unsafe_allow_html=True)
# 聊天界面
for message in st.session_state.csv_messages:
with st.chat_message(message["role"]):
if message["type"] == "dataframe":
st.dataframe(message["content"])
elif message["type"] == "image":
st.write(message["content"])
if os.path.exists('plot.png'):
st.image('plot.png')
else:
st.markdown(message["content"])
# 用户输入
if csv_query := st.chat_input("📊 分析数据...", disabled=st.session_state.df is None):
st.session_state.csv_messages.append({"role": "user", "content": csv_query, "type": "text"})
with st.chat_message("user"):
st.markdown(csv_query)
with st.chat_message("assistant"):
with st.spinner("🔄 正在分析数据..."):
response = get_csv_response(csv_query)
if isinstance(response, pd.DataFrame):
st.dataframe(response)
st.session_state.csv_messages.append(
{"role": "assistant", "content": response, "type": "dataframe"})
elif "GRAPH" in str(response):
text = str(response)[str(response).find("GRAPH") + 6:]
st.write(text)
if os.path.exists('plot.png'):
st.image('plot.png')
st.session_state.csv_messages.append({"role": "assistant", "content": text, "type": "image"})
else:
st.markdown(response)
st.session_state.csv_messages.append({"role": "assistant", "content": response, "type": "text"})
with col2:
st.markdown("### 📊 数据管理")
# CSV文件上传
csv_file = st.file_uploader("📈 上传CSV文件", type='csv')
if csv_file:
st.session_state.df = pd.read_csv(csv_file)
st.success(f"✅ 数据加载成功!")
# 显示数据预览
with st.expander("👀 数据预览", expanded=True):
st.dataframe(st.session_state.df.head())
st.write(f"📏 数据维度: {st.session_state.df.shape[0]} 行 × {st.session_state.df.shape[1]} 列")
# 数据信息
if st.session_state.df is not None:
if st.button("📋 显示数据信息", use_container_width=True):
with st.expander("📊 数据统计信息", expanded=True):
st.write("**基本信息:**")
st.text(f"行数: {st.session_state.df.shape[0]}")
st.text(f"列数: {st.session_state.df.shape[1]}")
st.write("**列名:**")
st.write(list(st.session_state.df.columns))
st.write("**数据类型:**")
# 修复:将dtypes转换为字符串格式显示
dtype_info = pd.DataFrame({
'列名': st.session_state.df.columns,
'数据类型': [str(dtype) for dtype in st.session_state.df.dtypes]
})
st.dataframe(dtype_info, use_container_width=True)
# 清除数据
if st.button("🗑️ 清除CSV数据", use_container_width=True):
st.session_state.df = None
st.session_state.csv_messages = []
if os.path.exists('plot.png'):
os.remove('plot.png')
st.success("数据已清除")
st.rerun()
if __name__ == '__main__':
main()- 在命令行激活
langchainenv环境,执行streamlit run langchain搭建pdf解析rag系统.py运行脚本,脚本运行成功会自动在8501开启服务,用户可打开浏览器访问。
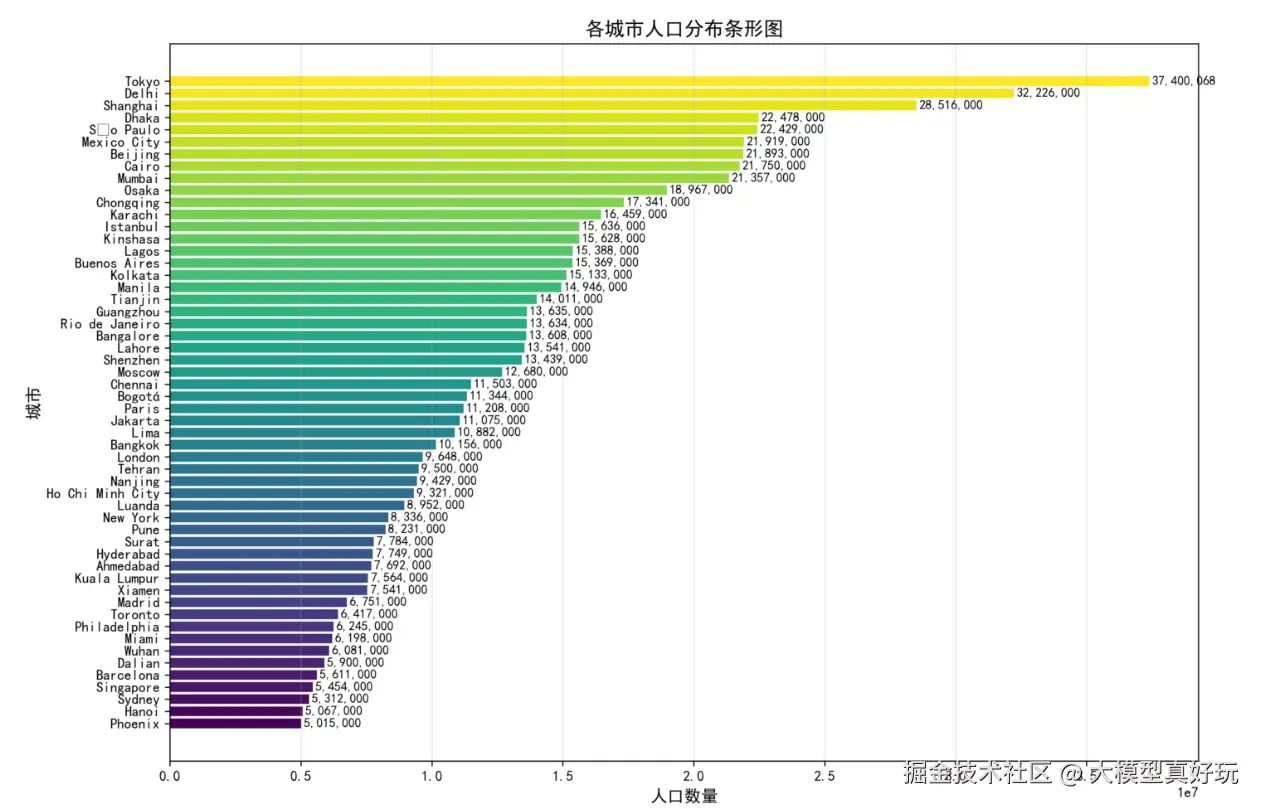
我们上传一份名为global_cities_data.csv的文件,文件内容是世界各大城市的基本情况统计表。可以看到右边栏已经显示成功文件的基本信息:

用户提问"请输出人口最多的城市及其人数,并绘制所有城市的人口条形图"检验智能体的效果,运行程序后,后台日志会显示智能体的执行过程: 读取所有城市人口数据->找出人口最多的城市->绘制图片并按指定格式输出。
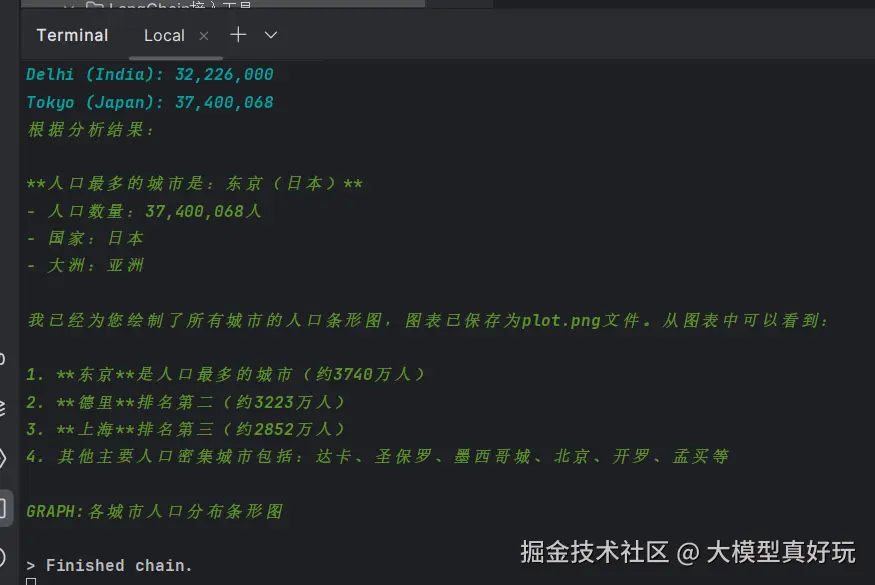
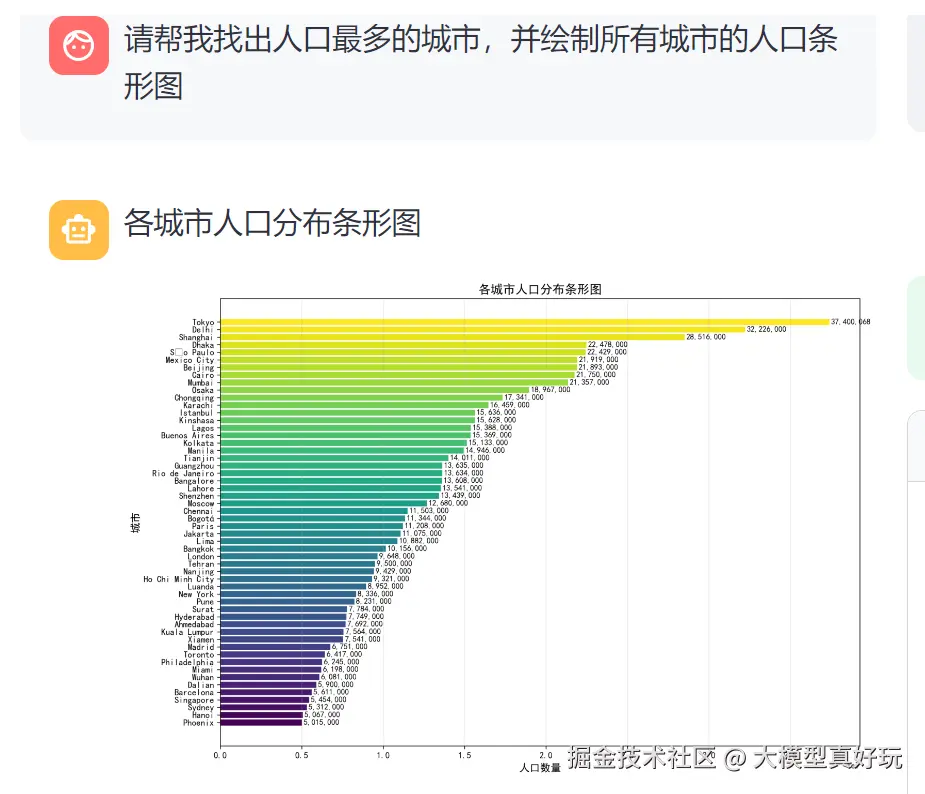
以上就是我们今天分享的全部内容,完整的项目代码大家可关注笔者同名微信公众号: 大模型真好玩 , 并私信: LangChain智能体开发获得。、
四、总结
本期分享我们通过Streamlit前端界面,结合LangChain框架搭建了CSV数据智能分析系统,通过自然语言指令分析结构化数据,支持CSV文件上传与DataFrame实时显示,还支持图表识别与自动展示。本项目旨在复习LangChain接入内部工具构建Agent的基本知识。本期内容是LangChain分享的最后一期内容。在当今大模型能力的飞速发展之下,LangChain的某些特性已不再适应当前多智能体的开发环境,但LangChain团队没有坐以待毙,而是积极开发了LLangGraph,重新定义多智能体的开发形式,下期分享我们就一起来学习LangGraph的相关内容吧!
本系列分享预计会有20节左右的规模,保证大家看完一定能够掌握LangChain&LangGraph的开发能力,大家感兴趣可关注笔者掘金账号和专栏,更可关注笔者的同名微信公众号:大模型真好玩 , 本系列分享的全部代码均可在微信公众号私信笔者: LangChain智能体开发 免费获得。