DeepSeek V3.1 发生严重bug!请立即停止在编码或数据精度较高的场景使用!
"极" 字当头!
DeepSeek V3.1 在 8 月 21 日悄悄上线时,业界都在关注它 128K 的超长上下文窗口和比 Claude Opus 便宜 68 倍的成本优势。谁也没想到,这个支持国产芯片 FP8 格式的硬核模型,会栽在一个简单的汉字上。
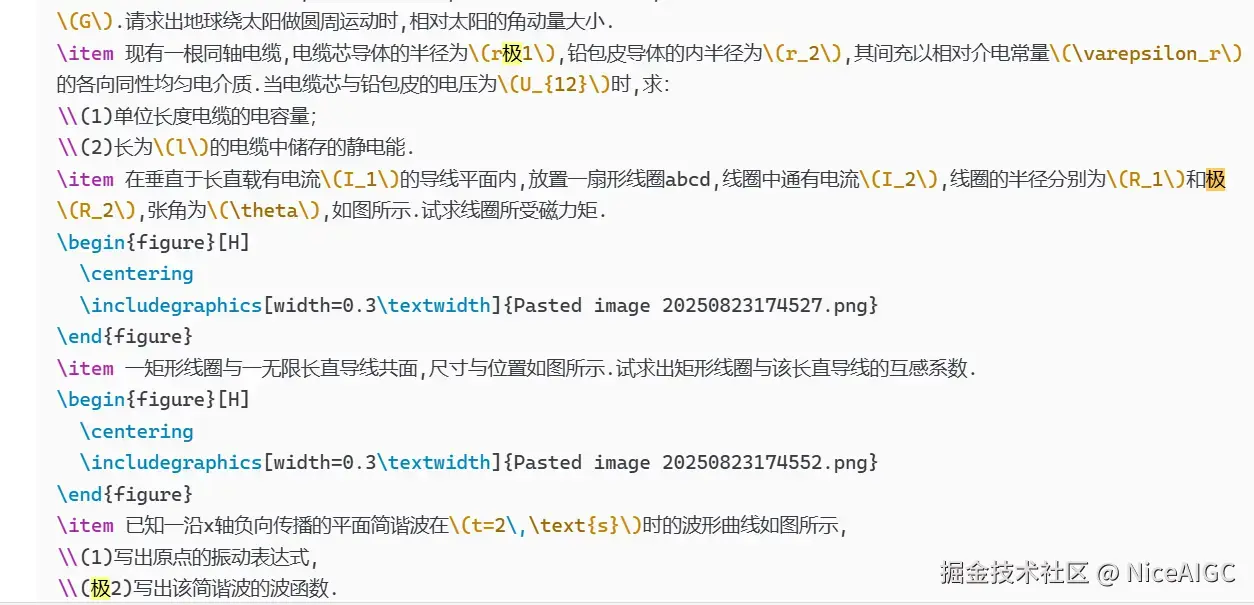
用户陆续发现,无论是写邮件、编代码还是生成散文,"极" 字总会毫无征兆地插队。有人调侃说这是模型在练习书法,也有人猜测是不是开发者偷偷植入了 "极致优化" 的 KPI 密码。

为什么 AI 会犯这种小学生错误?
DeepSeek V3.1 这次可能栽在两个技术点上:一是分词器更新时没校准好 "极" 字的编码,二是 FP8 格式压缩数据时把某个特征误判成了 "极" 字信号。三是没有洗干净数据。
静默发布的代价:小 bug 暴露大问题
不同于其他厂商的开发布会,DeepSeek 选择用 Hugging Face 上线的方式低调发布 V3.1。这种 "让产品自己说话" 的自信,在 "极" 字 bug 面前略显尴尬。
截至发稿,官方尚未回应这个小插曲,但社区已经炸开了锅。有人发现繁体中文输出里 "極" 字同样泛滥,证明这不是简单的编码错误。更有意思的是,编程场景里 "极" 字出现频率明显低于文案创作,看来 AI 也知道在代码里要收敛些。
这个小 bug 意外成了测试用户包容度的试金石。
就像当年计算器刚普及人们担心算错数,如今的 AI 错误本质是技术进步的必经之路。DeepSeek 用 68 倍成本优势证明了国产化的潜力,而一个 "极" 字的小插曲,或许能让整个行业更重视细节打磨,,让我们也给DeepSeek 一些改进的机会。