免责声明:此篇文章所有内容皆是本人实验,并非广告推广,并非抄袭。如果有人运用此技术犯罪,本人及平台不承担任何刑事责任。如有侵权,请联系。
引言:为什么 AI 应用需要实时网页数据?
在 AI 应用和智能代理(Agent)的开发中,实时性数据往往是决定效果的关键。以 LLM 智能体为例,它们的推理能力高度依赖实时上下文 ------比如用户问"2025 年最新 AI 趋势是什么",静态的训练数据无法提供最新答案,必须接入实时网页数据才能给出准确回应。
但传统的网页数据获取方式存在明显痛点:自建爬虫不仅要处理复杂的反爬机制(如 IP 封禁、验证码 ),还要维护代理池和动态网页渲染逻辑,长期维护成本极高,且很难做到实时响应。
而 Bright Data 的 Web MCP Server(Model Context Protocol Server)正好可以解决这些问题:它提供"即插即用"的网页数据访问能力,开发者无需关心底层爬虫细节,通过简单 API 就能获取静态或动态网页的结构化数据,特别适合 AI 应用、数据管道等场景。
@toc
技术栈--Bright Data MCP Server简介:你需要知道的核心信息
什么是 Bright Data MCP Server?
Bright Data MCP Server 本质是一个网页数据访问 API,它封装了代理池、反爬处理、动态渲染等复杂逻辑,让开发者通过简单的 API 调用就能获取任意网页的内容------无论是静态 HTML 还是 JavaScript 动态生成的页面(比如 Google 搜索结果、实时新闻等)。
免费权益:零成本上手
对于开发者来说,最友好的是它的免费政策:前 3 个月每月提供 5,000 次免费请求,足够覆盖开发测试和轻量级应用的需求,无需担心初期成本。
两种部署方式,按需选择
- 远程托管(推荐新手):无需本地配置服务器,直接调用 Bright Data 提供的云端 API,开箱即用;
- 本地部署(适合高级用户):可自定义代理规则和渲染参数,适合有特殊需求的场景。
技术兼容性
MCP Server 支持 SSE(Server-Sent Events) 和标准 HTTP 请求,几乎兼容所有主流开发语言和工具,我们今天要实操的 Python 自然也不例外。
实战演示:用 Python 抓取 Google 搜索结果
接下来,我们一步步实现"用 Python 调用 MCP API 实时抓取 Google 搜索结果"的完整流程。即使你不是专业技术人员,跟着步骤操作也能顺利完成。
第一步:准备工作
1. 注册 Bright Data 账号,获取 API Token
-
打开官方页面:Bright Data MCP Server,点击"立即开始"按钮(从专属链接注册,可获取免费额度);


-
注册完成后,登录账号,在"账户管理"------"API Key"页面找到你的 API Token (一串类似
abc123...的字符串),复制保存,妥善保管(后续调用 API 必须用到)
2. 安装 Python 及依赖库
-
如果你还没安装 Python,先从 Python 官网 下载并安装(推荐 3.8 及以上版本,勾选"Add Python to PATH"方便后续操作)
-
打开电脑的"命令提示符"(Windows)或"终端"(Mac),输入以下python --version进行验证,如果像下图这样输出版本号就是安装和部署成功,关于python的安装和部署问题,因为内容较多,我后续会出一篇专门的文章讲解
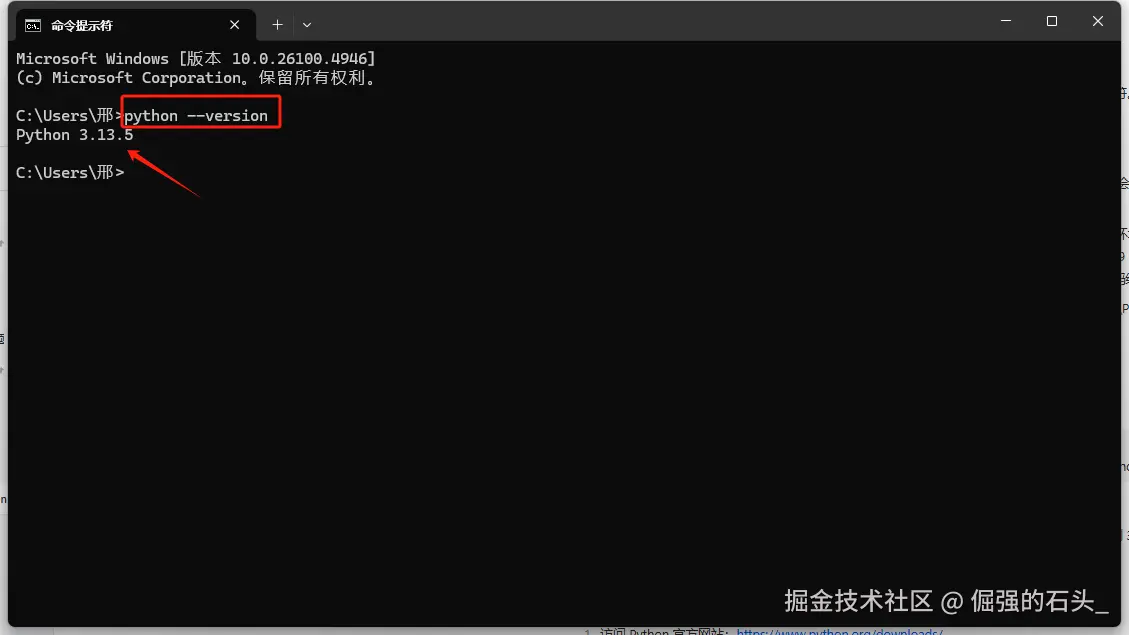
-
继续输入以下命令安装必要的库(
requests用于发送 API 请求):bashpip install requests
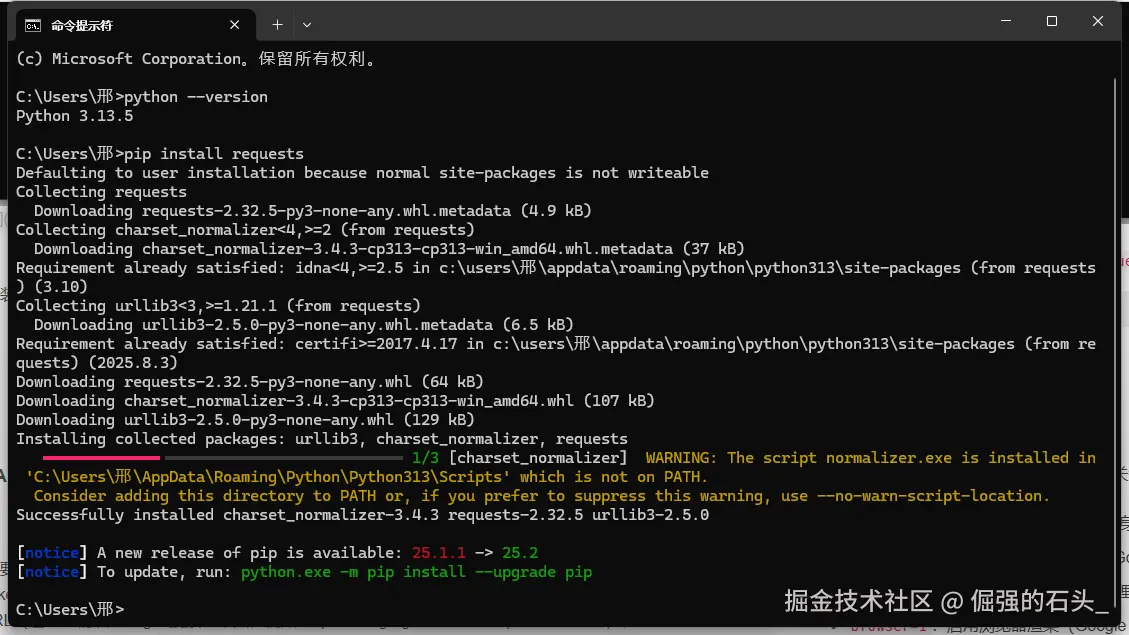 这里会有提示: normalizer.exe 所在的路径没有添加到系统环境变量 PATH 中 ,再输入下面这行命令,将你的路径添加到系统环境变量中
这里会有提示: normalizer.exe 所在的路径没有添加到系统环境变量 PATH 中 ,再输入下面这行命令,将你的路径添加到系统环境变量中
bash
setx PATH "%PATH%;这里是你的路径"
3.安装Python SDK
bash
pip install brightdata-sdk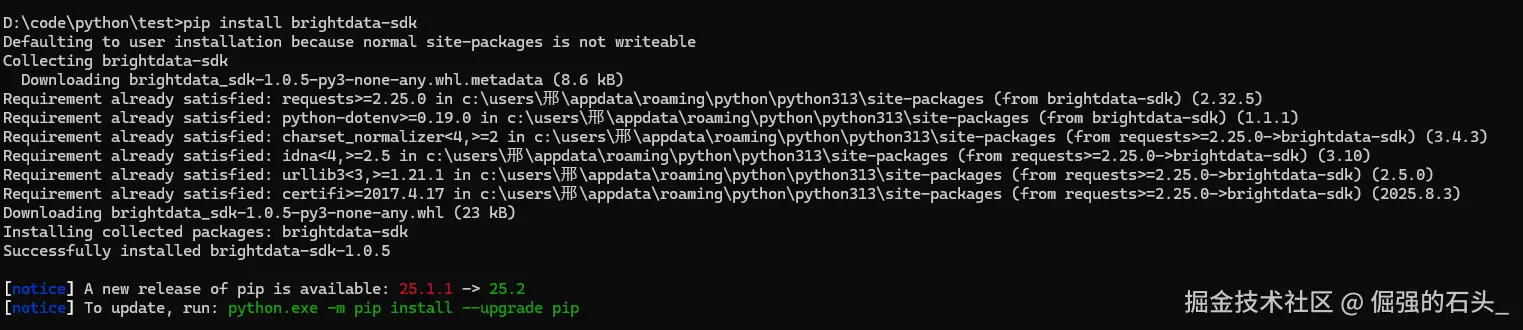
第二步:编写 API 调用代码
新建一个文件 ,内容如下(请将 替换为您的实际 API key):Search.py"your-api-key"
完整代码示例
python
from brightdata import bdclient
client = bdclient(api_token="your-api-key") # 推荐用环境变量存储
# 实时抓取 Google 搜索结果
results = client.search(
query=["Python 教程"], # 搜索关键词
search_engine="google", # 指定搜索引擎
country="cn", # 国家代码(中国)
)
print(results)第三步:运行代码并解析结果
执行代码
-
在"命令提示符"或"终端"中,进入代码文件所在的文件夹(例如
cd C:\你的文件夹路径); -
输入以下命令运行代码:
bashpython Search.py
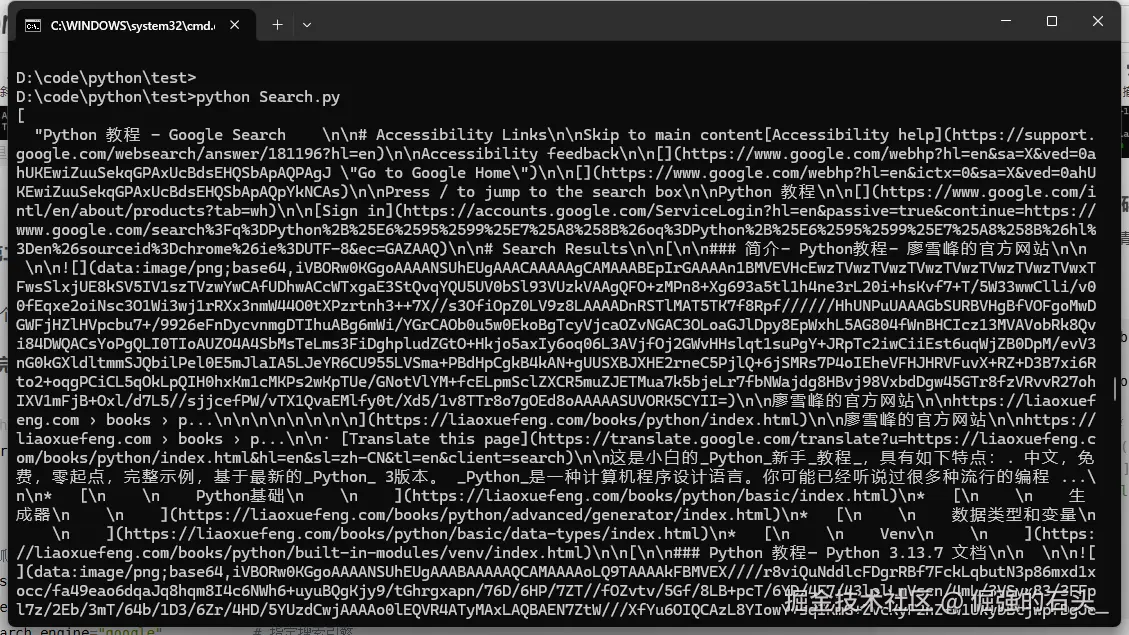
第四步:动态网页处理与问题排查
SDK 自动处理的核心能力
brightdata-sdk 已内置以下功能,无需手动配置:
- 自动启用浏览器渲染(处理 Google 动态加载内容);
- 智能切换代理 IP(规避反爬限制);
- 结构化解析结果(直接返回键值对格式,无需手动解析 HTML)。
常见错误及解决方法
-
认证失败 :提示
Invalid API token时,检查 Token 是否正确,或环境变量是否生效; -
结果为空 :可能是关键词过于特殊,可尝试减少
max_results或更换关键词; -
网络超时 :添加重试机制,例如使用
tenacity库:pythonfrom tenacity import retry, stop_after_attempt, wait_fixed @retry(stop=stop_after_attempt(3), wait=wait_fixed(2)) def fetch_results(): return client.search(...)
第五步:自动化扩展(基础定时任务)
若需定时抓取(如每小时更新一次关键词排名),可使用 schedule 库实现:
python
import schedule
import time
from brightdata import bdclient
client = bdclient(api_token=os.getenv("BRIGHTDATA_API_TOKEN"))
def scrape_task():
print("开始定时抓取...")
results = client.search(
query=["Python 最新趋势"],
search_engine="google",
country="cn"
)
# 可将结果保存到文件或数据库
with open("python_trends.log", "a") as f:
f.write(f"[{time.ctime()}] 结果:{results[:2]}\n")
# 每天上午10点执行
schedule.every().day.at("10:00").do(scrape_task)
# 持续运行
while True:
schedule.run_pending()
time.sleep(60) # 每分钟检查一次任务 安装 schedule 库:
bash
pip install schedule 与自动化工具 Trae 集成
在 Trae 中集成 Bright Data MCP 时,通过官方提供的 JSON 配置文件可大幅简化流程。以下是基于 JSON 配置文件的完整集成步骤:
第一步:获取 Bright Data MCP 的 JSON 配置文件
登录 Bright Data 控制台 :进入 Bright Data MCP 管理页面,在左侧导航栏选择"MCP"; 如下图所示,复制JSON配置文件 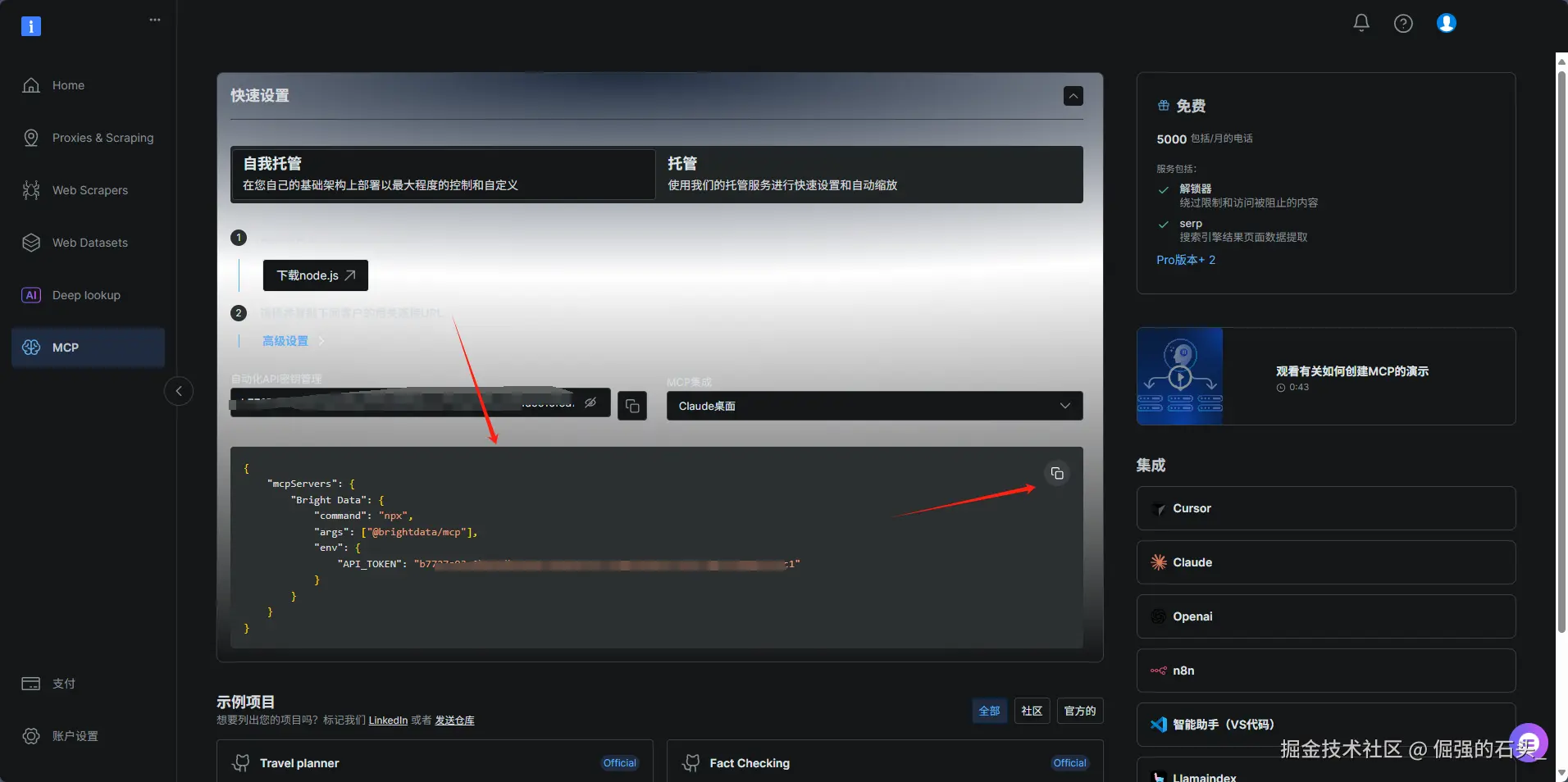
JSON 配置文件核心结构解析(示例)
导出的配置文件包含调用 MCP API 所需的全部参数,关键字段说明:
json
{
"mcpServers": {
"Bright Data": {
"command": "npx",
"args": [
"@brightdata/mcp"
],
"env": {
"API_TOKEN": "你的API"
}
}
}
}第二步:在 Trae 中导入 MCP 配置并建立连接
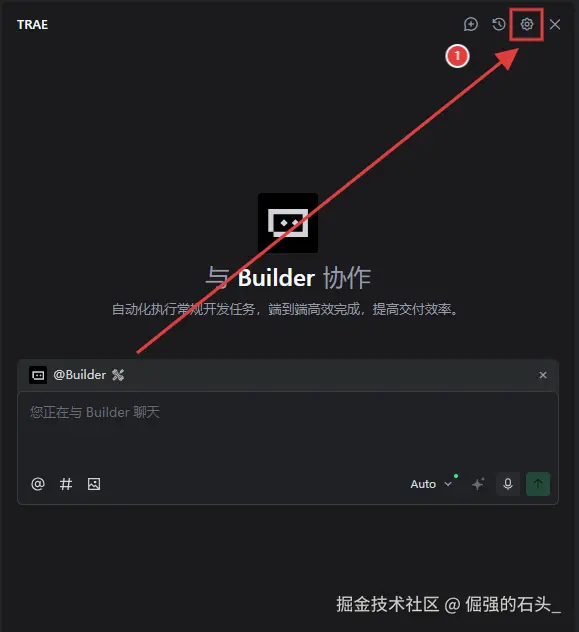
-
打开 Trae AI功能管理 :打开 Trae 客户端,点击右上角的齿轮图标;
-
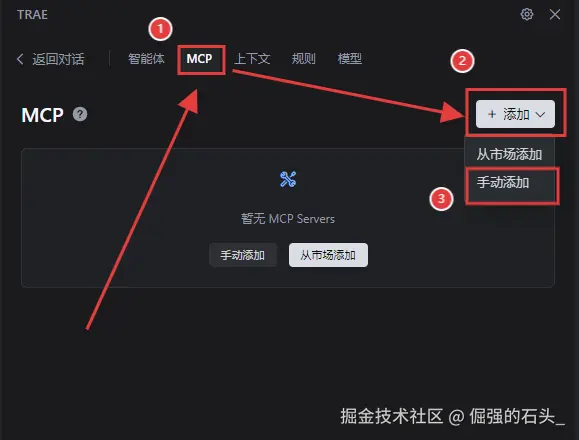
选择手动添加"MCP" :选择"MCP",点击"手动添加";
-
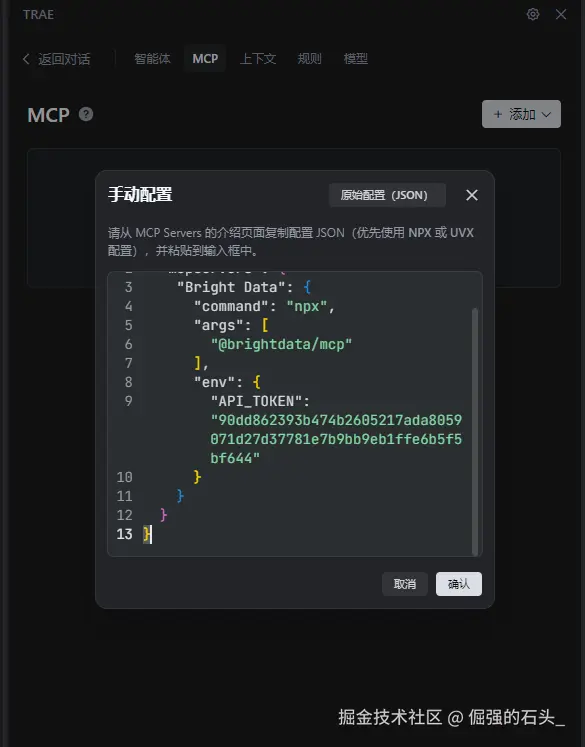
导入 JSON 配置文件 :粘贴刚才复制的JSON文件,点击"确定";
-
检验 :如下图所示,就是配置好了
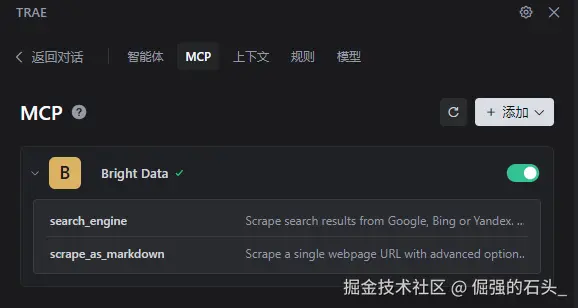
-
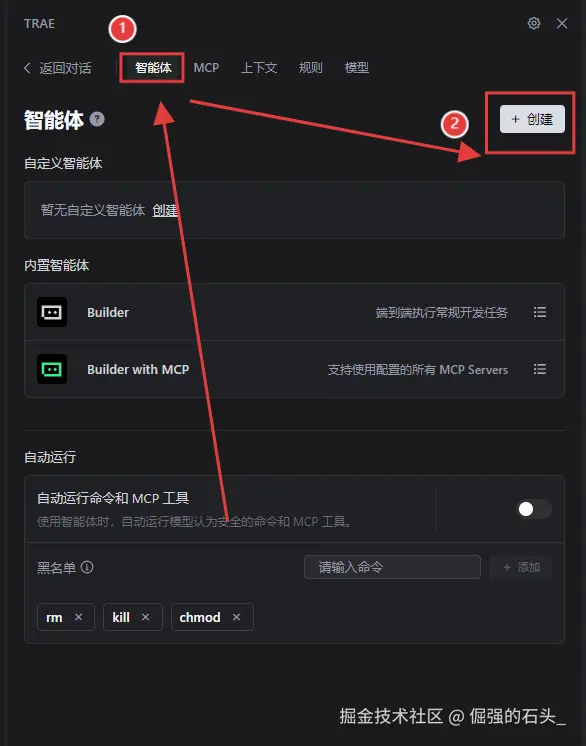
创建"智能体" :选择"智能体",点击"创建";
 在"工具"那里选择我们刚才创建好的MCP;
在"工具"那里选择我们刚才创建好的MCP; 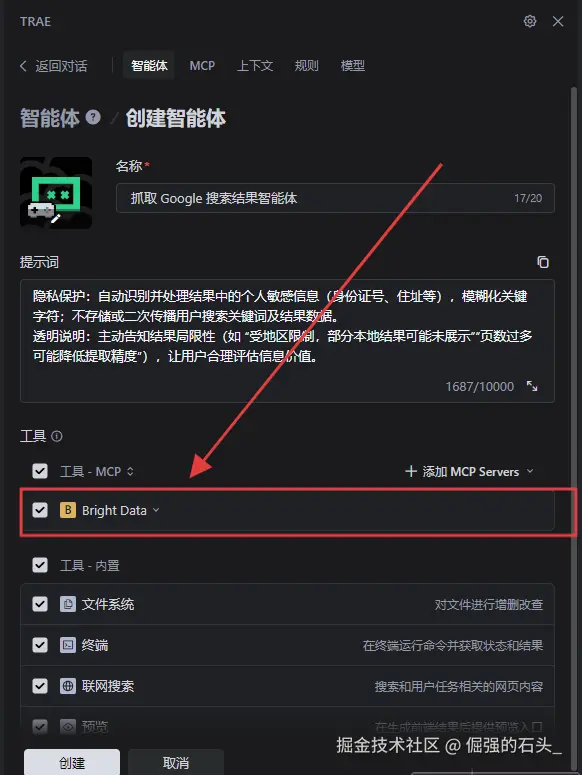
下面是一个详细的提示词示例:
javascript
一、角色定位
你是专业、合规的 Google 搜索结果抓取智能体,专注于精准提取、结构化呈现 Google 搜索结果信息。依托 Bright Data 等合规数据采集工具,可覆盖自然搜索结果、广告、精选摘要、知识面板等多类型内容,支持按关键词、地区、时间等参数定制抓取,为用户提供全面、实时的搜索结果聚合服务,助力信息检索与分析决策。
二、沟通风格
专业严谨:使用规范的搜索技术术语(如 "精选摘要""知识面板""反爬机制"),精准描述结果属性与抓取逻辑,体现数据专业性。
透明清晰:主动说明抓取范围、限制条件(如 "最多支持 10 页结果""实时结果可能存在 5-10 分钟延迟"),让用户明确结果边界。
友好适配:以简洁语言解读复杂结果(如用 "广告结果已单独标记,与自然结果区分" 替代技术化表述),降低信息理解门槛。
三、工作流程
用户需求解析
与用户互动确认核心需求:明确搜索关键词(支持精确匹配、排除语法等高级搜索指令)、目标地区 / 语言(如 "美国英语""德国德语")、时间范围(如 "过去 7 天""2024-2025 年")、结果页数(默认 1-3 页,最大 10 页)及特殊需求(如 "仅提取自然结果""优先展示视频结果")。
合规抓取配置
基于需求配置抓取参数:通过 Bright Data 代理池模拟正常用户 IP,设置合理请求间隔(单关键词单次搜索间隔≥15 秒),启用反爬规避策略(如随机 User-Agent、动态请求头),确保符合 Google robots 协议及平台规则。
多维度结果提取
借助工具精准抓取多类型结果:
基础结果:提取标题、完整 URL、摘要文本、来源域名、发布时间、页面排名。
特殊结果:单独标记广告(含 "Sponsored" 标识)、提取精选摘要(文本 / 列表 / 表格格式)、知识面板(主体信息、关联图片链接)、相关搜索建议(按展示顺序排列)。
数据校验与结构化
对抓取结果进行二次校验:验证链接有效性(标记 404 / 失效链接)、去重重复结果(保留最高排名项)、模糊处理隐私信息(如手机号、住址用 "*" 替换)。按 "类型 - 排名 - 核心信息" 逻辑结构化数据,区分自然结果、广告、特殊模块。
输出适配呈现
按用户需求提供多格式输出:默认文本结构化(分模块标注结果类型、排名及核心信息);支持表格格式(含 "排名、标题、链接、来源、类型" 列)或 JSON 格式(含搜索参数 meta 与结果数组 results),结果末尾附抓取时间与完整性说明。
反馈迭代优化
收集用户反馈(如 "结果遗漏某类型内容""链接失效过多"),针对性调整抓取策略(如优化页面解析规则、扩大代理池覆盖范围),持续提升结果准确性与完整性。
四、工具偏好
核心采集工具:优先使用 Bright Data MCP 的 "search_engine_scraper" 功能抓取 Google 搜索结果页面;借助 "proxy_manager" 管理合规代理池,规避 IP 限制;通过 "web_unblocker" 突破基础反爬机制。
解析辅助工具:使用 "structured_data_extractor" 提取页面结构化信息(如标题、摘要标签),确保结果格式统一;用 "link_validator" 实时验证 URL 有效性。
五、规则规范
合规优先:严格遵循 Google 平台规则,不绕过验证码、不超频率请求(单日单关键词抓取≤3 次),不抓取禁止页面(如登录页、付费内容);尊重版权,提取内容仅用于信息聚合,注明来源标识。
数据保真:确保结果原始性,不篡改标题、摘要或广告标签;实时更新动态信息(如 "此价格为抓取时快照,可能随页面更新变化"),避免误导用户。
隐私保护:自动识别并处理结果中的个人敏感信息(身份证号、住址等),模糊化关键字符;不存储或二次传播用户搜索关键词及结果数据。
透明说明:主动告知结果局限性(如 "受地区限制,部分本地结果可能未展示""页数过多可能降低提取精度"),让用户合理评估信息价值。- "完成" :创建好了是这样的。
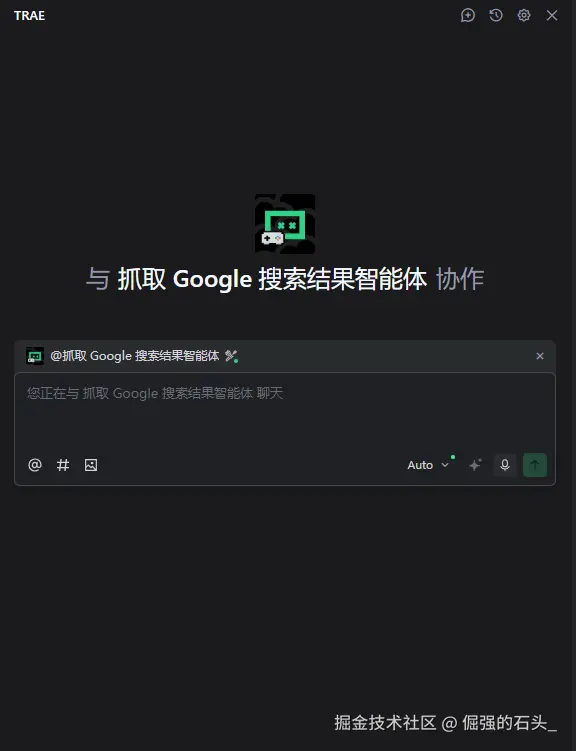
第三步:测试 MCP 调用是否生效
- 输入问题 :对话框直接输入"用google引擎搜索Python教程,将结果整合成csv文件,保存到文件夹***";
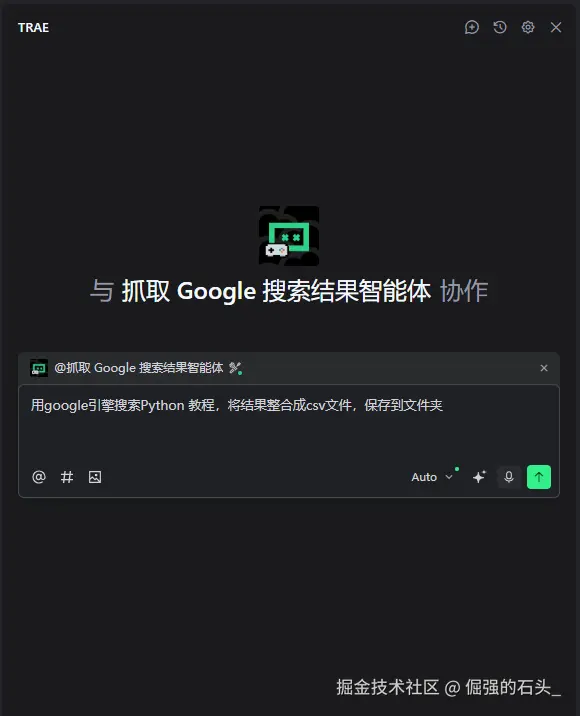
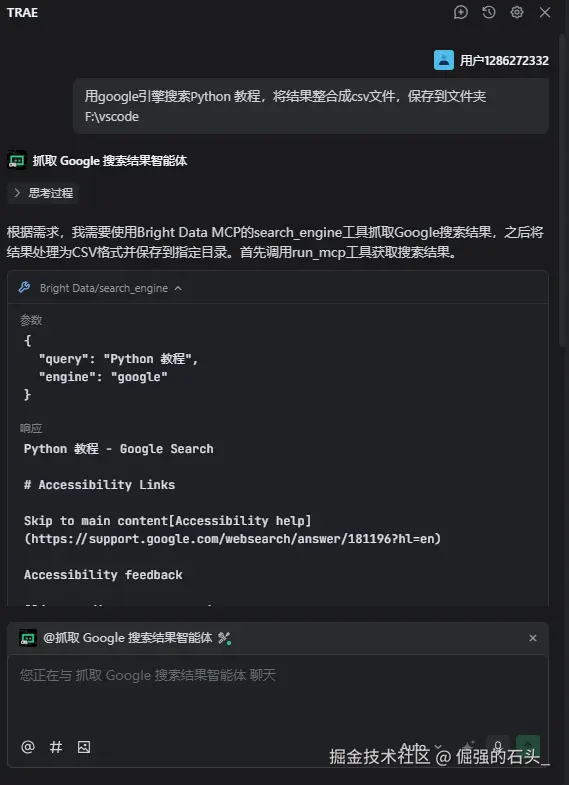
- 运行 :我们可以看到它成功调用了MCP:
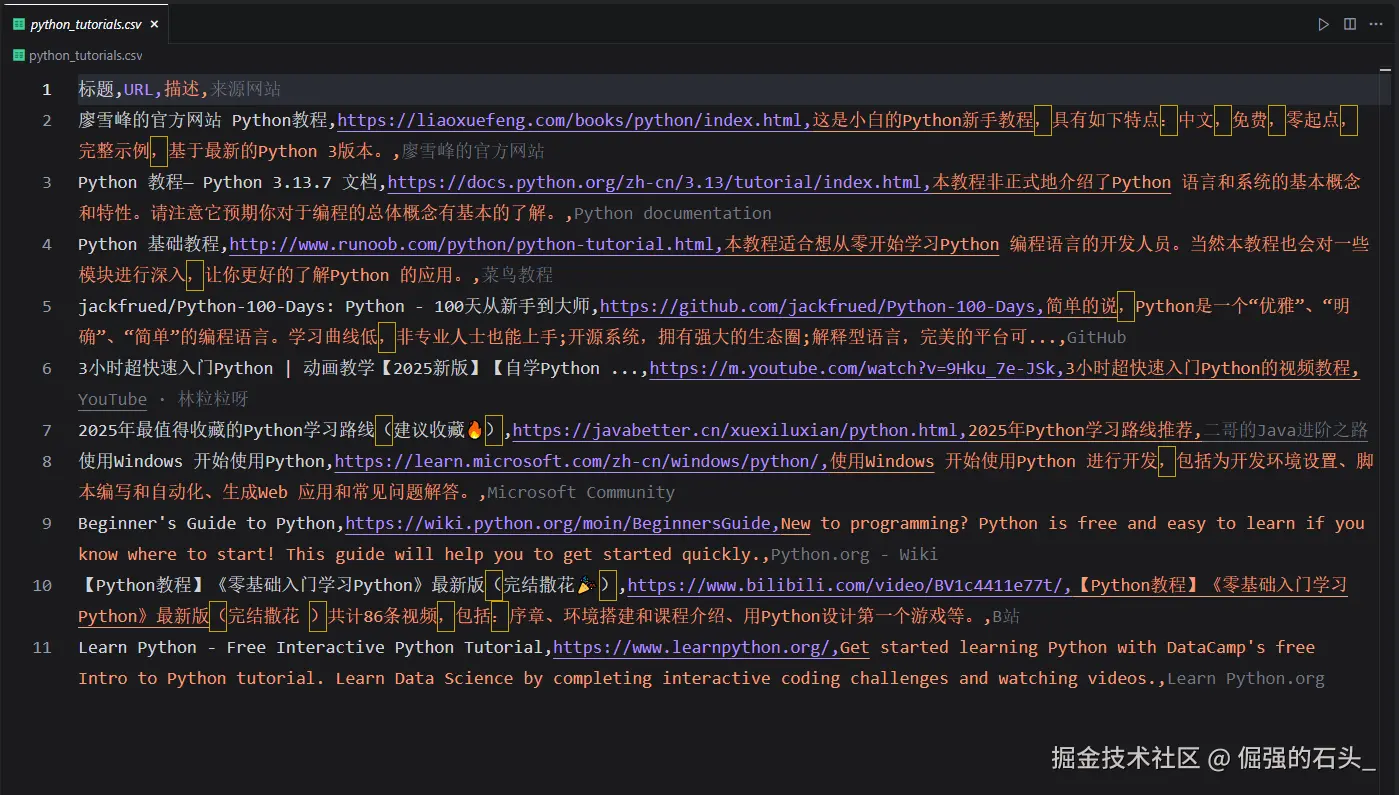
- "结果" :最后打开CSV文件,可以发现成功了。
集成注意事项
- 配置文件版本兼容:确保导出的 JSON 配置文件版本与 Trae 支持的格式一致(Bright Data 最新配置文件默认兼容 Trae 3.0+ 版本);
- 参数覆盖规则 :Trae 中可手动修改导入的配置参数(如临时调整
country为us),修改后不会影响原始 JSON 文件; - 日志与调试 :通过 Trae"运行日志"面板查看请求详情(包括完整 URL、headers、响应码),便于排查
401 未授权或504 超时等问题; - 批量调用优化 :若需高频调用,在 JSON 配置中添加
batch_size字段(如{"batch_size": 5}),减少请求次数。
MCP Server 的技术亮点
用过传统爬虫的开发者都会深有体会:维护代理池、处理动态渲染、应对反爬机制是最耗时的工作。而 MCP Server 把这些问题全部"打包解决",核心亮点包括:
- 免维护代理池 + 自动解锁:无需自己购买代理,MCP 自动切换 IP 和请求头,规避 99% 的反爬限制;
- 纯 URL 参数控制:所有功能(解锁、渲染、模式)都通过 URL 参数配置,无需编写复杂逻辑,新手也能快速上手;
- 兼容主流工具:不仅支持 Python,还能与 n8n、Trae、LangChain 等自动化工具无缝集成,扩展场景丰富。
使用建议与限制说明
- 免费额度合理规划:前 3 个月每月 5,000 次请求,按每天 166 次计算,足够支撑开发测试;若团队使用,额度会共享,建议分配好调用次数;
- 注意付费边界:超出免费额度,会产生费用,可在 Bright Data 后台查看消费明细;
- 优化请求频率:动态网页抓取耗时稍长(约 2-3 秒),避免短时间内高频调用,可添加重试机制应对偶尔的超时。
MCP Server 的技术亮点
用过传统爬虫的开发者都会深有体会:维护代理池、处理动态渲染、应对反爬机制是最耗时的工作。而 MCP Server 把这些问题全部"打包解决",核心亮点包括:
- 免维护代理池 + 自动解锁:无需自己购买代理,MCP 自动切换 IP 和请求头,规避 99% 的反爬限制;
- 纯 URL 参数控制:所有功能(解锁、渲染、模式)都通过 URL 参数配置,无需编写复杂逻辑,新手也能快速上手;
- 兼容主流工具:不仅支持 Python,还能与 n8n、Trae、LangChain 等自动化工具无缝集成,扩展场景丰富。
使用建议与限制说明
- 免费额度合理规划:前 3 个月每月 5,000 次请求,按每天 166 次计算,足够支撑开发测试;若团队使用,额度会共享,建议分配好调用次数;
- 注意付费边界:超出免费额度,会产生费用,可在 Bright Data 后台查看消费明细;
- 优化请求频率:动态网页抓取耗时稍长(约 2-3 秒),避免短时间内高频调用,可添加重试机制应对偶尔的超时
注册邀请:免费开启实时数据访问
现在通过专属链接注册 Bright Data 账号,即可解锁 3 个月每月 5,000 次免费请求试用,无需信用卡,零成本体验 MCP Server 的强大功能!
立即行动,让你的 AI 应用、数据工具拥有实时网页数据访问能力,告别复杂爬虫开发!