本期作者:陈海芹 openInula TAC 成员/核心贡献者
《openInula茶话会》专栏每周不定期分享业务知识、实战经验与开发技巧,帮助社区成员快速提升技能,开启技术探索之旅! 本期介绍《openInula API2.0编译器原理》,欢迎查阅。
openInula API2.0的核心部件是一个基于babel平台的编译器。通过在编译时解析业务代码AST中变量和视图之间的引用关系,将组件JSX代码编译为能响应状态数据变化的高度优化代码,让数据改变时精准更新真正需要更新的 DOM 部分,减轻运行时负担。
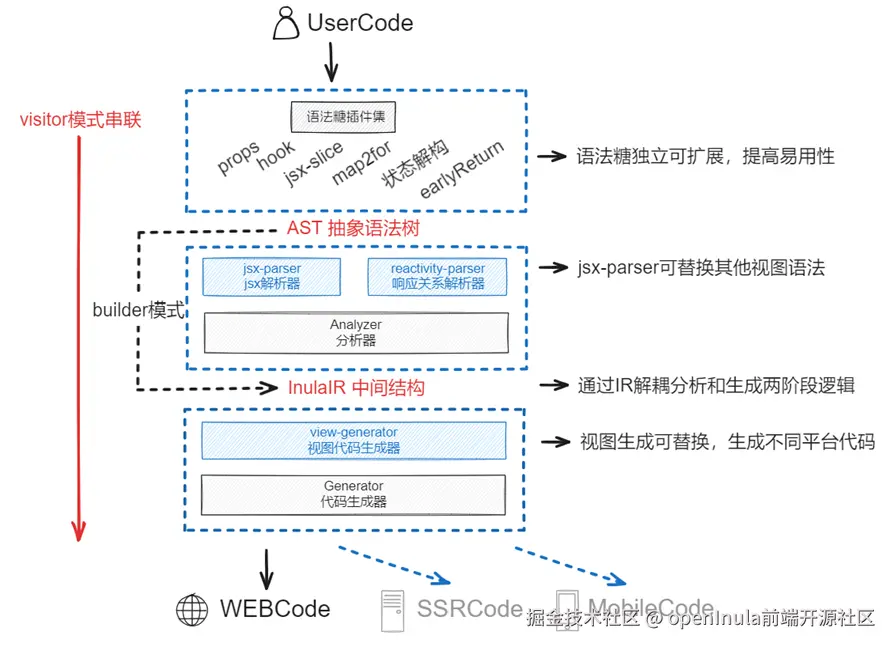
1 模块关系
编译器架构分为:
- 语法糖插件集
- 分析器
- IR构建器
- 生成器
编译器代码详见:gitcode.com/openInula/i... 下面是具体的目录结构:
arduino
📦inula-next-core
┣ 📂analyze // 代码分析模块,负责解析和分析组件代码
┣ 📂generate // 代码生成模块,负责生成最终的组件代码
┣ 📂sugarPlugins // 语法糖插件,提供额外的高级语法糖
┣ 📜index.ts // 项目入口文件
┣ 📜plugin.ts // 插件系统核心文件
📦jsx-parser // 解析jsx结构
📦reactivity-parser // 解析变量和视图间的响应关系
📦view-generator // 视图部分代码生成器2 模块交互时序图
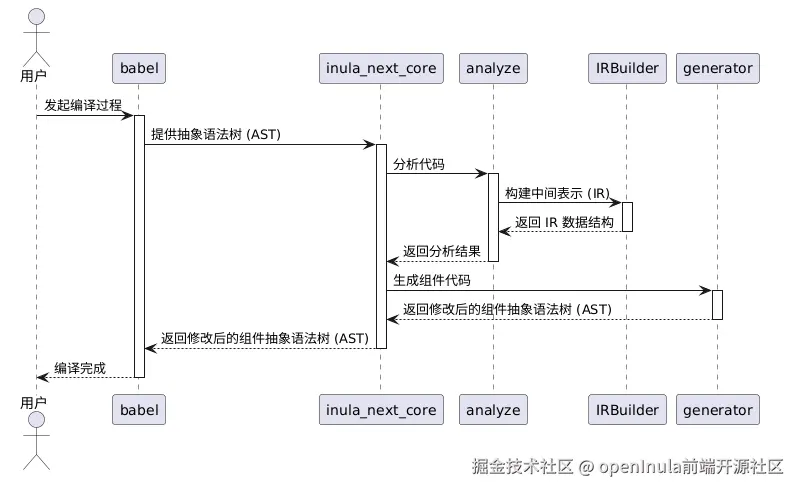
3 整体实现流程
编译器整体是一个AST的transformer,转换组件部分的AST到渲染优化后的AST
- 从AST树搜索函数组件的AST
- 调用analyze模块,通过访问者模式串联各类分析器来分析函数组件代码AST,构建IR数据(包含组件信息和响应关系)
- 调用generate模块,将IR数据组装为优化后的组件代码AST
- 将修改后的AST生成最终代码
生成器和分析器互不耦合,通过定义的标准IR数据接口关联。 支持openInula后续灵活演进,如不同生成器支持生成不同平台的代码,不同分析器支持不同语法
ts
function transformNode(
path: NodePath<t.CallExpression>
) {
// 1. 调用analyze模块,分析函数组件代码AST,构建包含组件信息和响应关系的IR数据
const [ir, bitManager] = analyze(type, name, componentNode, {
htmlTags,
});
// 2. 调用generate模块,将IR数据组装为优化后的组件代码AST
const resultNode = generate(ir, bitManager, hoist);
// 3. 将修改后的AST替换原来的节点生成代码
replaceWithComponent(path, resultNode);
}3.1 分析AST节点
分析模块包括入口函数和各个特性分析器(分析单个特性能力), 代码地址。 通过采用访问者模式,灵活组装各个特性分析器。 各个特性分析器对组件代码的函数入参和函数体等各部分AST,进行依赖关系分析,构建组件IR数据。 特性分析器彼此互不干扰,有较好可维护性和可读性。
3.2 构建IR
IR(中间表示),是openInula编译器中一种内部表示形式,用于存储组件相关的信息,包括状态,生命周期,视图结构(jsx),最关键的是数据之间的依赖关系。openInula中IR采用的js对象的结构,主要用于解耦代码分析和代码生成,还能使得编译器可以支持多种源语言和目标平台
代码中分析器会对组件各种特性对应的AST进行分析,调用IRBuilder来构建IR,同时构建数据的依赖关系位图。 如下图所示:
- 状态识别:每识别到一个新的状态(例如
a、b),就会为其分配一个比特位。分配的比特位以二进制形式表示,每个新状态的比特位都是前一个状态比特位的两倍(左移一位),这种规律使得每个状态的比特位都是唯一的,并且能够通过比特位来追踪状态的依赖关系。 - 依赖分析: 新状态可能会依赖于之前的状态,会记录依赖的数据信息。例如,
b依赖于a,因此b的依赖为0b10包含了a的比特位信息。
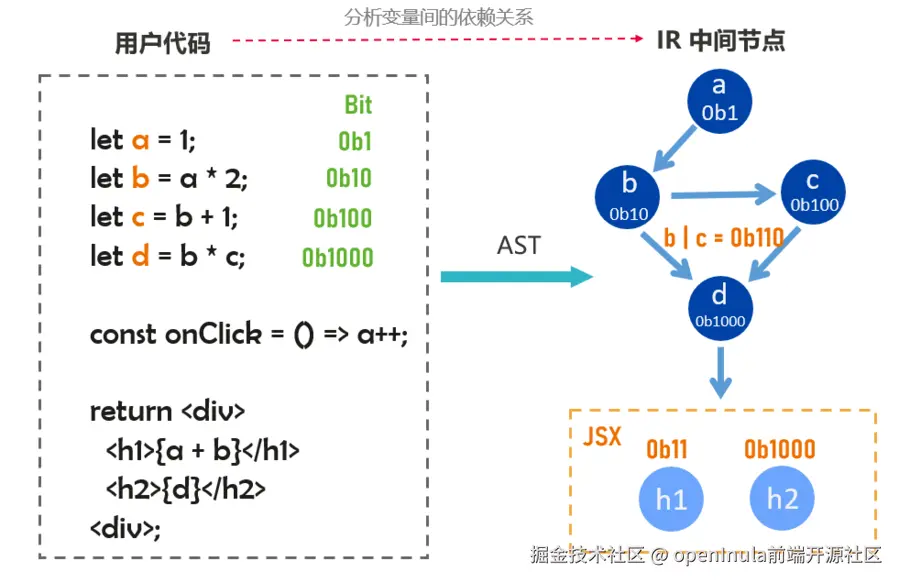
在完成分析后,我们即可以建立完整的依赖关系位图的图结构。 使用位图来表示状态之间的依赖关系,可以带来以下好处:
- 存储空间: 每个状态只占用一个位,可以有效地节省存储空间。
- 依赖分析: 可以使用位运算来判断某个状态是否依赖于其他状态。例如,可以使用
b & a来判断状态b是否依赖于状态a。 - 状态合并: 可以使用位运算将多个状态合并成一个状态。例如,
c同时依赖a和b时,同时依赖a和b。
3.3 生成目标代码
生成模块包括入口函数和各种IR代码生成器(针对每个IR生成对应代码)。类似分析模块,各种IR代码生成器彼此互不干扰,提升可维护性和可读性。
3.3.1 状态部分代码
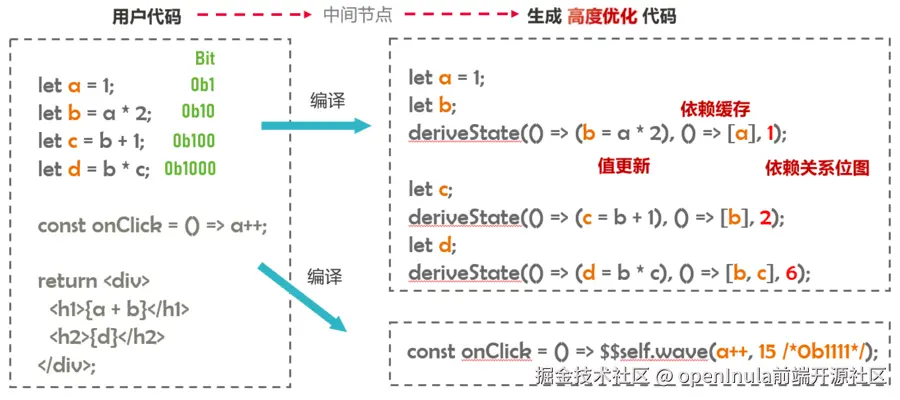
我们通过编译器为组件状态构建了一套完整的响应式系统。该系统采用高效编译 和精准缓存双管齐下的策略,实现了状态的精细化更新。
在生成状态声明语句时,编译器会根据中间表示(IR)数据,添加相应的依赖缓存和依赖关系位图:
- 依赖位图: 用于快速识别状态是否发生变化。
- 依赖缓存: 用于判断状态的实际取值是否发生变化,从而在处理对象或数组等复杂数据结构时,实现更精确的更新。(依赖缓存可以避免因对象或数组内部的细微变化而触发不必要的更新,从而提高性能), 在生成状态修改语句时,编译器同样会根据中间表示(IR)数据中发布关系位图,计算本次需要更新的状态位图 !
3.3.2 视图部分代码
视图部分将静态部分和动态部分分离处理,从而实现超精准的更新。
静态部分的处理:
- 编译器将用户代码中的静态部分(如HTML标签、固定的文本等)提升到组件上层,进行预编译和优化。
- 通过静态骨架提升,将静态部分转换为高效的、可复用的代码结构。
- 克隆高效创建 和 多次复用 确保静态部分在多次渲染时可以高效地复用,避免重复创建和销毁。
动态部分的处理:
编译器会识别用户代码中的动态部分(如变量、表达式等),提供关键的数据结构。
- 节点路径 :用于描述动态部分在DOM模板骨架中的位置。 当动态部分发生变化时,可以根据依赖关系和缓存信息,精确地确定需要更新的范围。避免全量更新,只更新发生变化的部分,实现DOM级别更新 ,从而大幅提升更新性能。
- 依赖关系位图:通过与当前变化数据位进行运算,快速定位到需要更新的动态部分。
- 依赖缓存 用于存储动态部分的计算结果,避免重复计算。
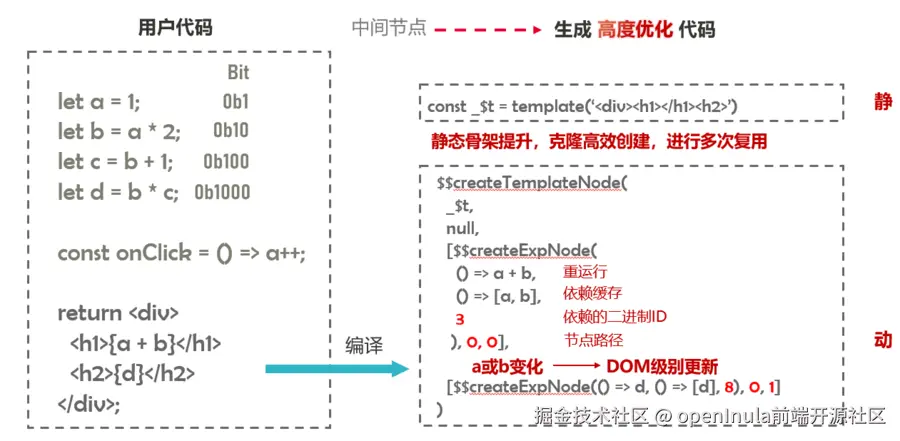
以上为openInula API 2.0 编译器的一些关键设计:
- 静态骨架提升和动态部分分离: 将静态部分预编译和复用,动态部分精准更新,最大程度减少 DOM 操作。
- 依赖关系位图: 使用位运算高效地管理和追踪状态之间的依赖关系,实现快速的状态变更检测。
- 依赖缓存: 避免重复计算,实现更精确的更新,尤其在处理复杂数据结构时。