【声明】本博客所有内容均为个人业余时间创作,所述技术案例均来自公开开源项目(如Github,Apache基金会),不涉及任何企业机密或未公开技术,如有侵权请联系删除
背景
上篇 blog
【Ubuntu】【Gitlab】拉出内网 Web 服务:静态&动态服务
分析了静态 Web 服务和动态 Web 服务的区别,下面来继续分析
Python http.server
之前 blog 分析过,Sphinx 构建出来的 html 文件,可以用 Python 自带的 http.server 模块运行提供服务,下面先来看下 http.server 的具体内容
http.server 模块的实现位于 Python lib 库路径下的 http/server.py
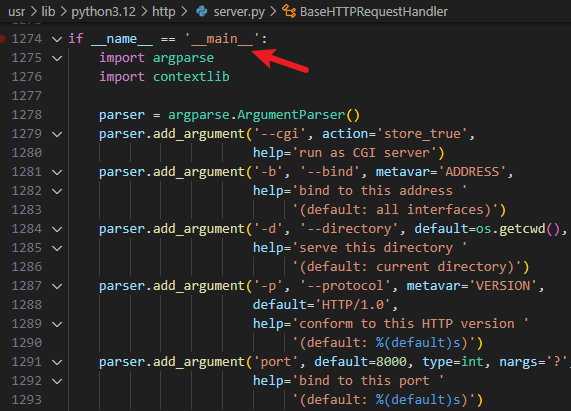
http.server 模块作为一个纯 Python 实现的简易 HTTP 服务器,可以完全独立运行,不需要依赖其他后端程序 ,比如 Ruby,Node.js 等,http.server 模块主要用于开发测试,本地预览静态网页等简单场景,默认只提供静态文件服务,比如 *.html,*.css,*.js 以及图片等,不支持服务器端动态逻辑,除非自己用 Python 扩展它
http.server 模块首先是下面的 note 部分
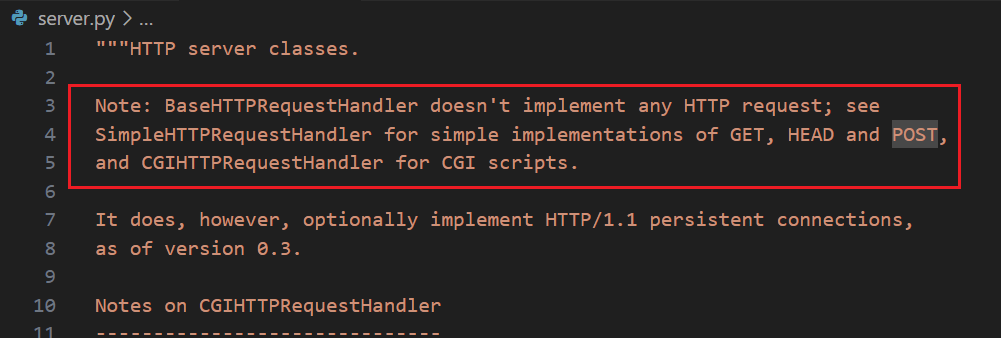
这里是关于请求处理能力的说明:
BaseHTTPRequestHandler:基类,不处理任何具体请求SimpleHTTPRequestHandler:实现了get,head,get等简单的基本功能,用于提供文件服务CGIHTTPRequestHandler:用于执行cgi脚本(自定义的动态内容,等会儿说)
OK,http.server 整体提供的服务如上,并不算复杂,可以看到,并没有太多关于动态的内容,而命令 python -m http.server 默认使用的是 SimpleHTTPRequestHandler,其核心是提供文件等静态服务 ,这一点可以从最下方的 __main__ 实现看到
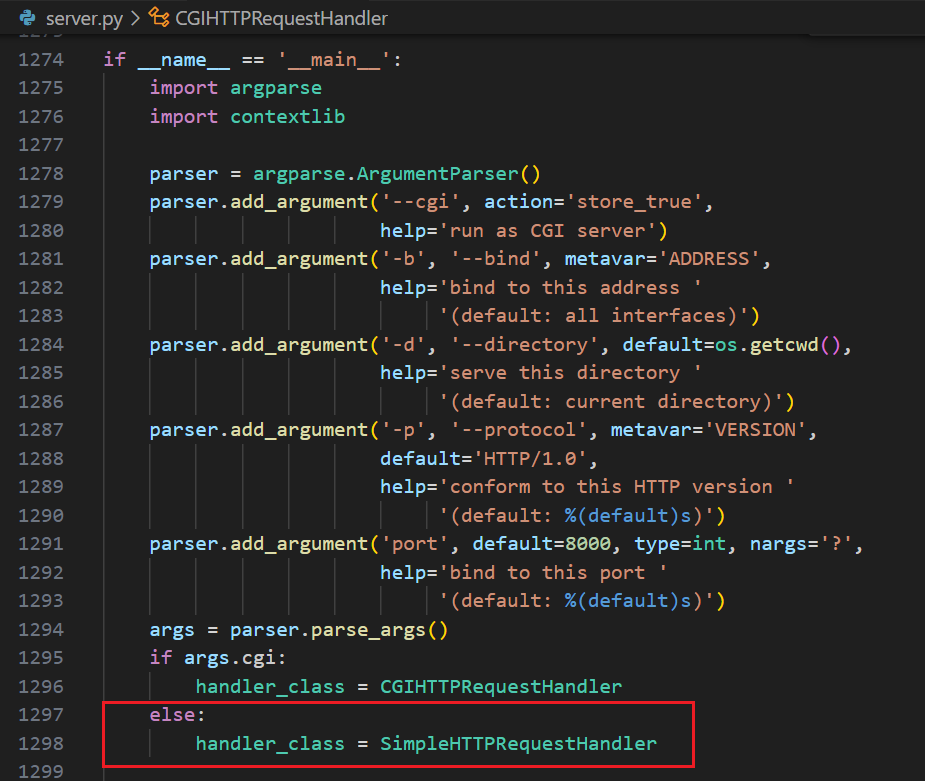
当没有用 cgi 选项时,默认使用的就是 SimpleHTTPRequestHandler
然后是前面提到的三个 http 方法:get,head,post
get:当浏览器请求一个URL时,比如http://localhost:2025/index.html(一般首页就是index.html)

get方法会捕获到/index.html信息,然后SimpleHTTPRequestHandler就会在当前目录(启动http.server的目录)下查找index.html文件

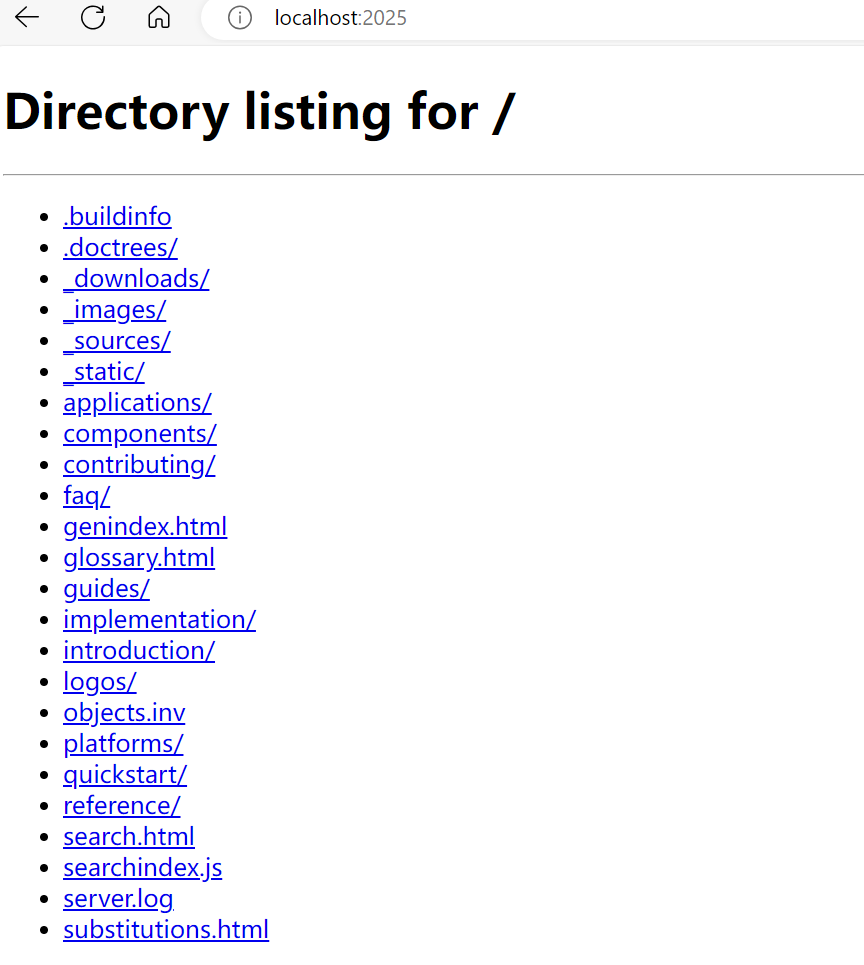
如果找到index.html,就读取文件内容,并返回给浏览器;如果没找到,则会尝试列出目录(启动http.server的目录)下的所有内容(如果允许的话,就有点像ftp站点那样,都提供可浏览的文件目录 ),这就是静态文件服务的核心,比如把启动http.server目录下的index.html改个名字,就返回的是目录下的内容
head:作用和get类似,但只返回响应头,不返回响应主体内容 ,用来检查网页中所用的文件是否存在,文件最后修改时间,文件大小等元信息,而不是下载整个文件,比如在内网服务器的终端输入命令curl -I http://localhost:2025,可以看到响应头如下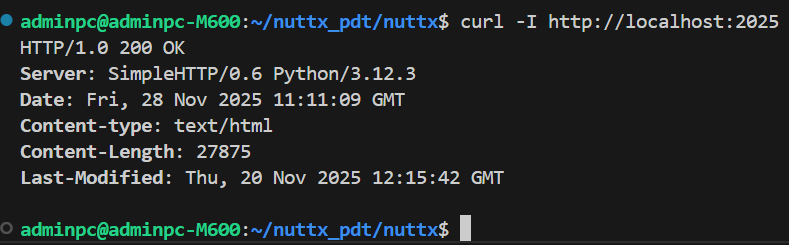
这里有些关键性信息:
HTTP/1.0 200 OK:这里使用的是HTTP/1.0协议(协议有点老,但是简单),这里状态码200表示请求成功(HTTP状态码可以查看 RFC 9110: HTTP Semantics),说明服务器正常运行,并能成功返回资源信息

Server: SimpleHTTP/0.6 Python/3.12.3:这是个关键信息,表明该 Web 服务器是由 Python 自带的http.server模块启动的,版本是SimpleHTTP/0.6,运行在 Python 3.12.3 上

Date: Fri, 28 Nov 2025 11:08:11 GMT:服务器生成响应的时间 ,注意,不是指最后修改时间,最后修改时间在后面
Content-type: text/html; charset=utf-8:返回的内容类型是HTML网页,字符编码为UTF-8,说明访问的根路径是一个HTML页面,而不是一个文件夹目录(没有index.html的就是目录)
Content-Length: 1305:HTML页面大小为1305字节
Last-Modified: Thu, 20 Nov 2025 12:15:42 GMT:HTML网页的最后修改时间,如果没有修改,就是最后 Sphinx 构建生成的时间
如果用 curl http://localhost:2025(不加 -I 选项),就会下载这 HTML 页面 1305 字节的内容
OK,本篇先到这里,如有疑问,欢迎评论区留言讨论,祝各位功力大涨,技术更上一层楼!!!更多内容见下篇 blog
【Ubuntu】【Gitlab】拉出内网 Web 服务:http.server 分析(二)