使用Bright Data API轻松构建LinkedIn职位数据采集系统
引言:为什么开发者需要LinkedIn职位数据?
在AI时代,高质量的结构化数据是模型训练和商业分析的核心资产。LinkedIn作为全球最大的职业社交平台,拥有丰富的职位信息、公司数据和人才画像,这些数据在以下场景中价值巨大:
- AI模型训练:为NLP模型提供高质量的职位描述、技能标签等训练数据
- 商业情报分析:追踪行业招聘趋势、薪资水平、技能需求变化
- 招聘数据抓取:为HR系统自动化收集竞争对手招聘信息
- 市场调研:分析特定领域的人才分布和公司布局
然而,直接从LinkedIn获取数据面临诸多挑战...
传统LinkedIn数据抓取的痛点
作为Python开发者,你可能已经尝试过用Selenium、Scrapy等工具抓取LinkedIn数据,但很快就会遇到这些问题:
1. 技术门槛高
- 需要配置复杂的代理池避免IP被封
- 要处理各种反爬虫机制(验证码、动态加载等)
- HTML结构频繁变化,维护成本高
2. 法律合规风险
- 直接爬取可能违反平台ToS
- 数据使用权限不明确
3. 开发效率低
python
# 传统方式需要大量配置代码
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import random
# 配置代理
proxies = ['proxy1:port', 'proxy2:port', ...]
# 设置User-Agent轮换
user_agents = ['Mozilla/5.0...', 'Chrome/91.0...', ...]
# 处理反爬虫
driver.execute_script("Object.defineProperty(navigator, 'webdriver', {get: () => undefined})")
# ... 还有更多复杂配置这种方式不仅代码冗长,而且稳定性差、维护困难。
Bright Data Web Scraper API:开发者的福音
Bright Data 是全球领先的数据采集平台,其Web Scraper API专门为开发者解决数据抓取难题:
核心优势
🚀 即开即用
- 无需配置代理池或处理反爬虫
- 支持120+热门网站,包括LinkedIn、Amazon、Instagram等
- 标准化JSON返回,直接可用
⚡ 高效批量
- 单次请求支持最多5,000个URL
- 并发处理,速度提升10倍以上
- 自动重试和错误处理
💰 成本友好
- 起步价仅$0.79/千条记录
- 支持支付宝等本地支付方式
- 免费试用额度,无风险体验
🛡️ 100%合规
- 符合各平台ToS要求
- 企业级数据合规保障
Bright Data vs 传统方案对比
| 对比维度 | 传统爬虫方案 | Bright Data API |
|---|---|---|
| 开发时间 | 2-3周 | 1-2天 |
| 代码复杂度 | 500+行 | 100行内 |
| 维护成本 | 持续高投入 | 几乎零维护 |
| 成功率 | 60-80% | 95%+ |
| 合规风险 | 存在风险 | 100%合规 |
| 技术门槛 | 需要专业爬虫知识 | 普通开发者即可 |
实际应用场景
1. AI训练数据准备
python
def prepare_training_data():
"""为NLP模型准备训练数据"""
scraper = LinkedInJobScraper(API_KEY)
# 采集不同行业的职位描述
industries = ['科技', '金融', '教育', '医疗', '制造业']
training_data = []
for industry in industries:
jobs = scraper.scrape_jobs({
'keywords': industry,
'location': '全国',
'limit': 200
})
for job in jobs:
training_data.append({
'text': job['description'],
'label': industry
})
return training_data2. 竞品分析
python
def competitor_analysis():
"""竞争对手招聘分析"""
competitors = ['阿里巴巴', '腾讯', '字节跳动', '美团']
for company in competitors:
jobs = scraper.scrape_jobs({
'keywords': f'company:{company}',
'limit': 100
})
# 分析技能要求、薪资水平等
analyze_company_hiring_trends(company, jobs)开始使用Bright Data
免费注册试用
想要体验Bright Data Web Scraper API的强大功能吗?
🎁 免费试用福利
- 新用户免费$25使用额度
- 支持支付宝付款,无需国外信用卡
- 中文技术支持
📝 注册步骤
-
-
注册账号并完成邮箱验证
-
获取API Key开始使用
-
查看详细文档和代码示例
定价说明
- 按量付费:$0.79起/千条记录
- 包月套餐:适合大批量需求
- 企业定制:联系客服获取专属方案
使用Bright Data 进行完成实战案例准备
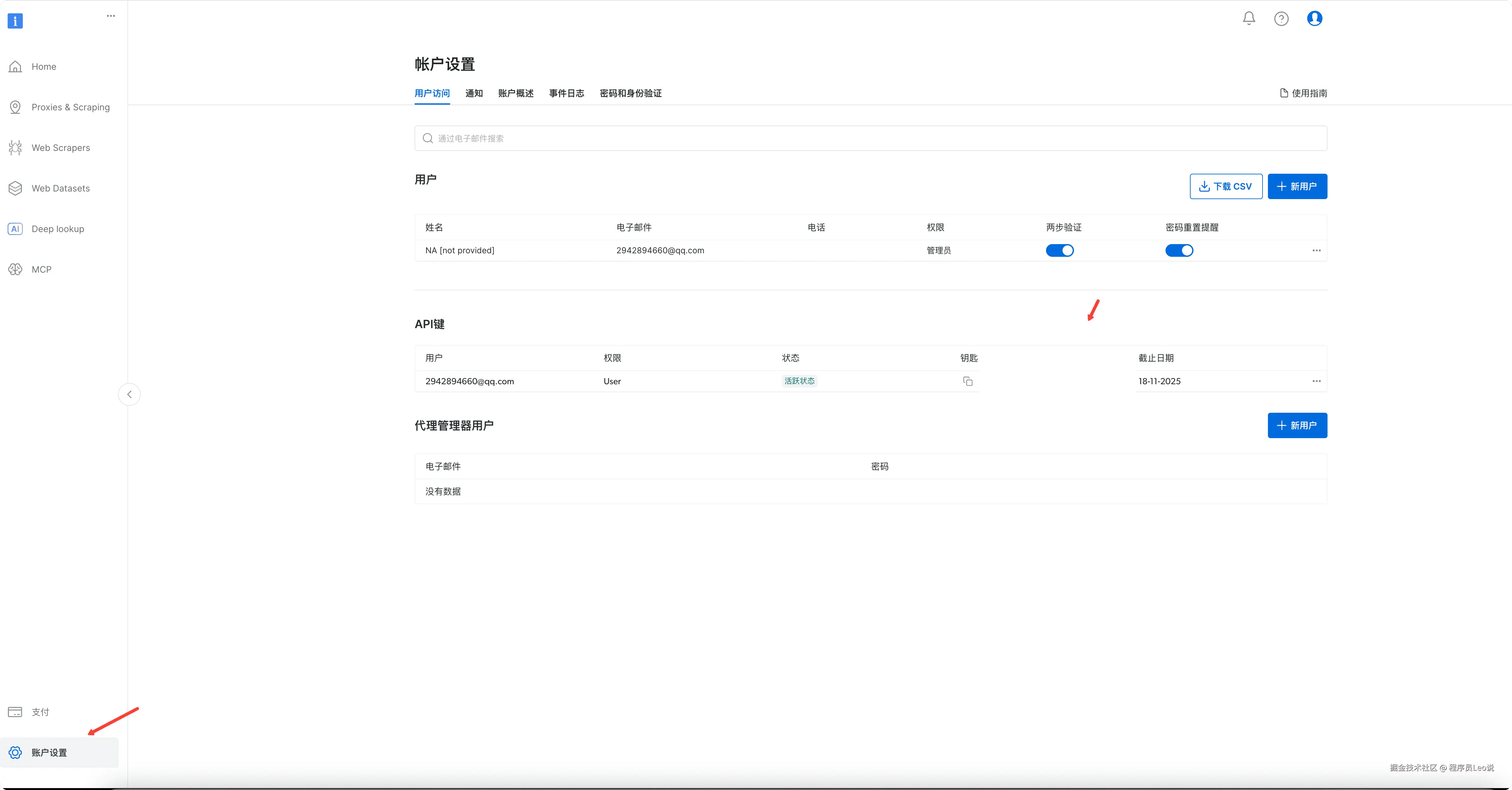
访问亮数据官网(get.brightdata.com/leo),完成账号注册... 先来到账户设置,进行api-key的创建,创建好了直接进行复制,我们后续是会用到的。
点击我们左侧导航栏中的 Web Scrapers,可以看到亮数据的一个爬虫市场。
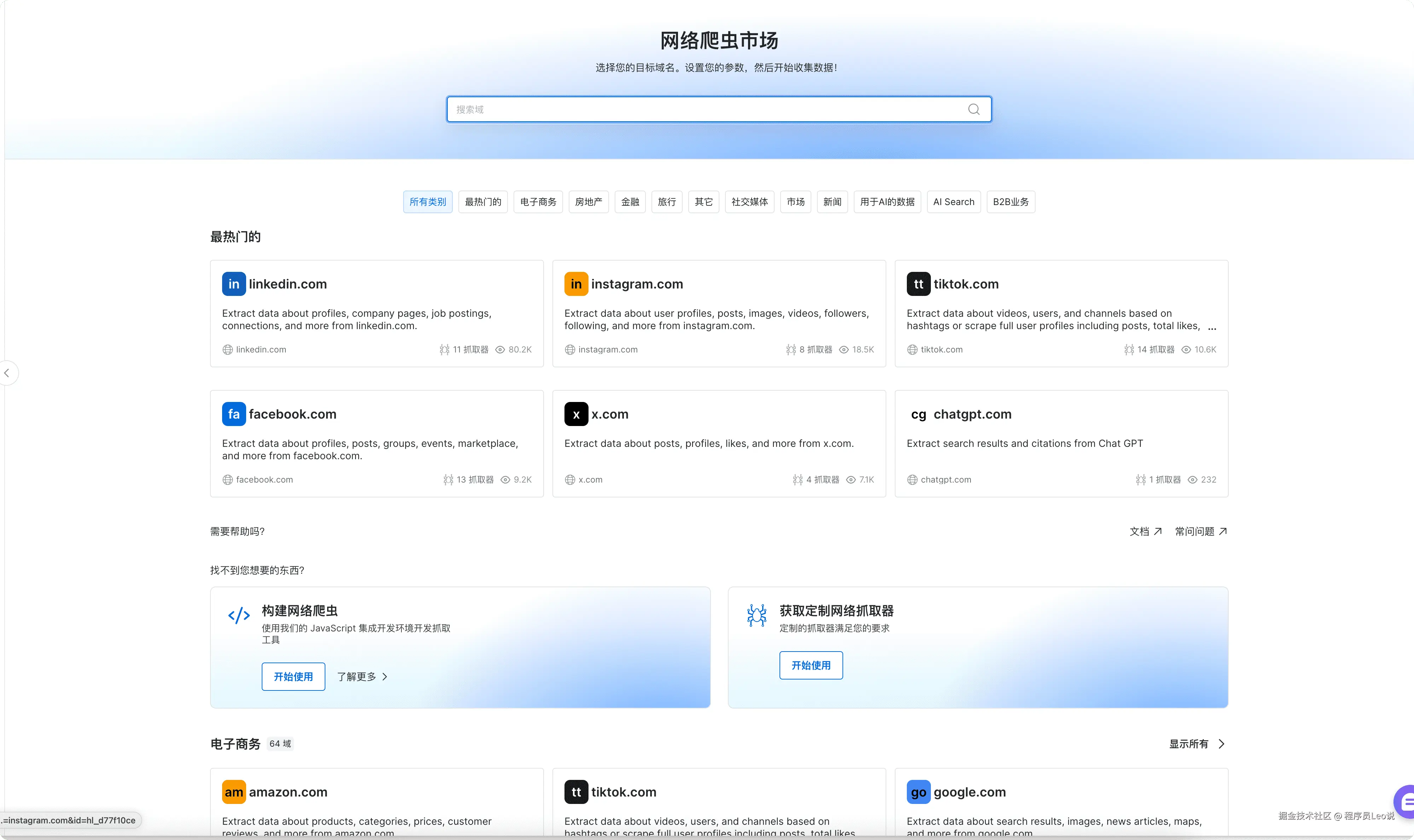
然后点进去领英详情页面中去。
image-20250824051912892
然后在详情页面中选择 Linkedin job listings information - discover by keyword
接着我们选择使用爬虫api,使用此 API 启动具有指定参数的数据收集并返回结果。
爬虫api
身处数字化浪潮,不管是企业 HR 规划人才招聘 (想了解市场供给、调整岗位薪酬),还是求职者洞察行业机会 (分析岗位分布、预判职业方向),亦或是市场调研团队研究行业趋势(追踪岗位需求变化、辅助战略决策 ),都需要及时、全面的岗位数据支撑。聚焦 "2025 年中国公司计算机相关岗位",用数据量化需求规模、拆解岗位要求,才能让决策更科学。
这里我们想探究下在2025年在中国公司开的计算机相关的职位有多少个,我们直接使用web scraper api根据关键词进行搜索
在API请求构建器的界面,我们在这里细节这里进行职位关键词的填写,有C++、Python、PHP、JAVA工程师,坐标位置选择中国
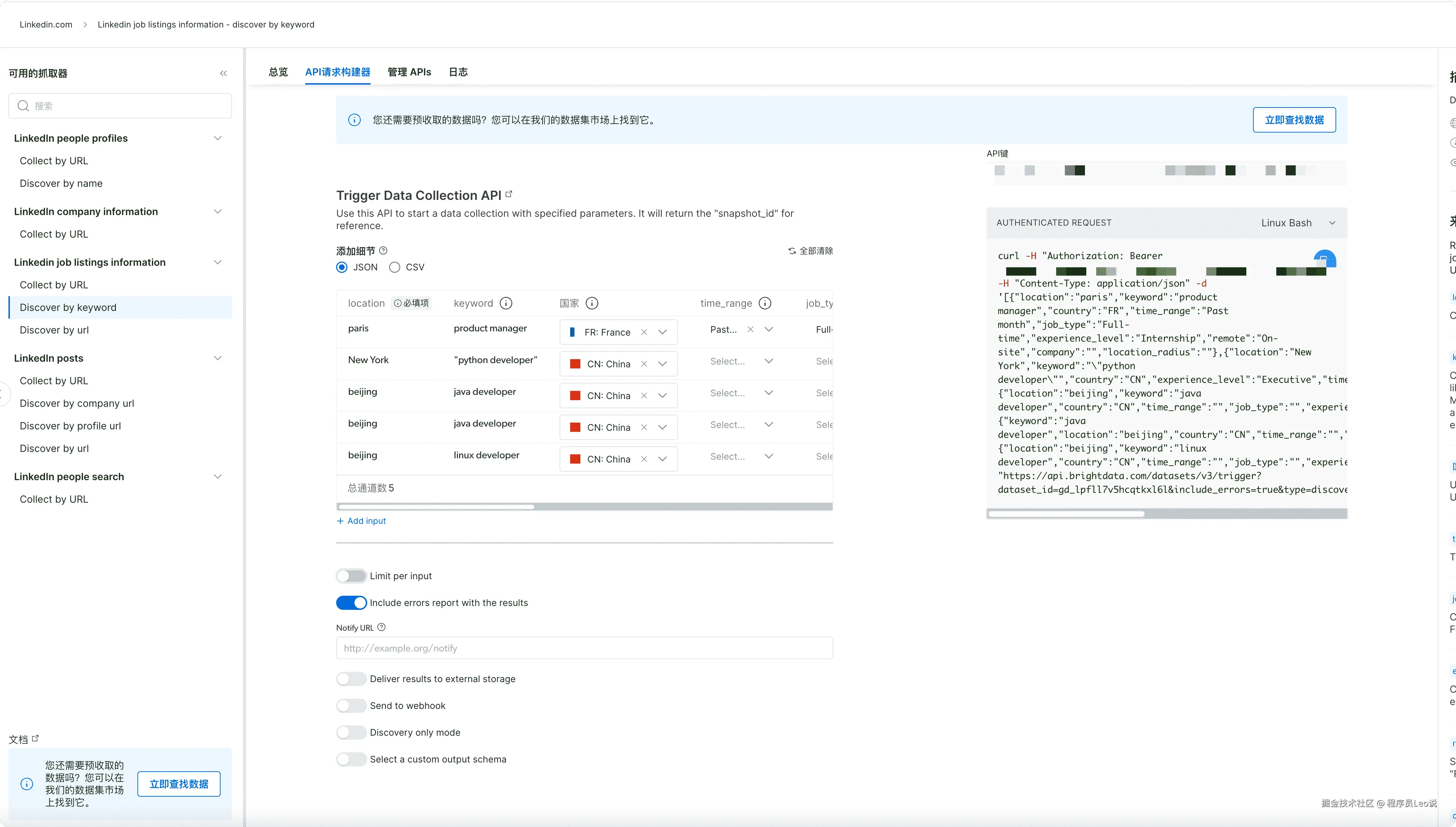
这里我选择的地区是北京 位置是中国 时间范围就让他默认就可以了。
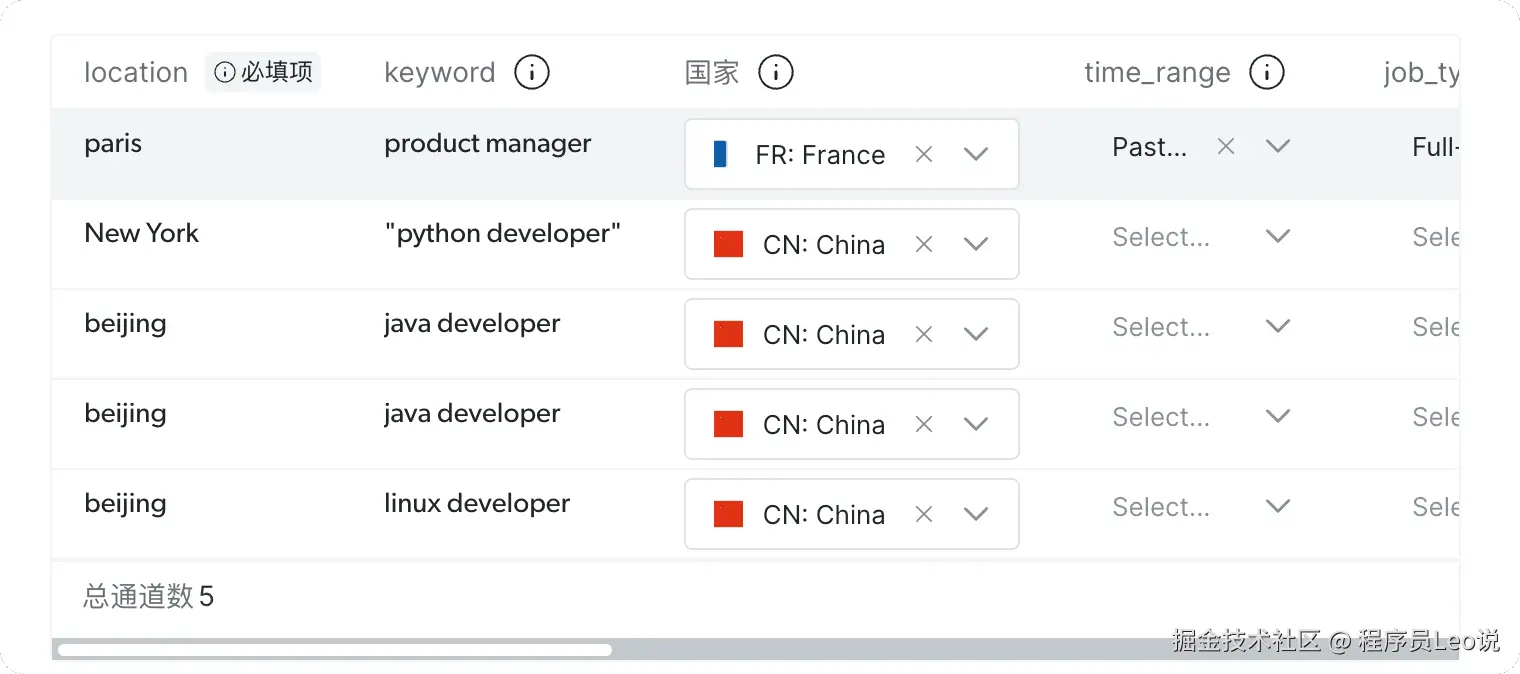
然后选择pyhton语言,复制代码即可。
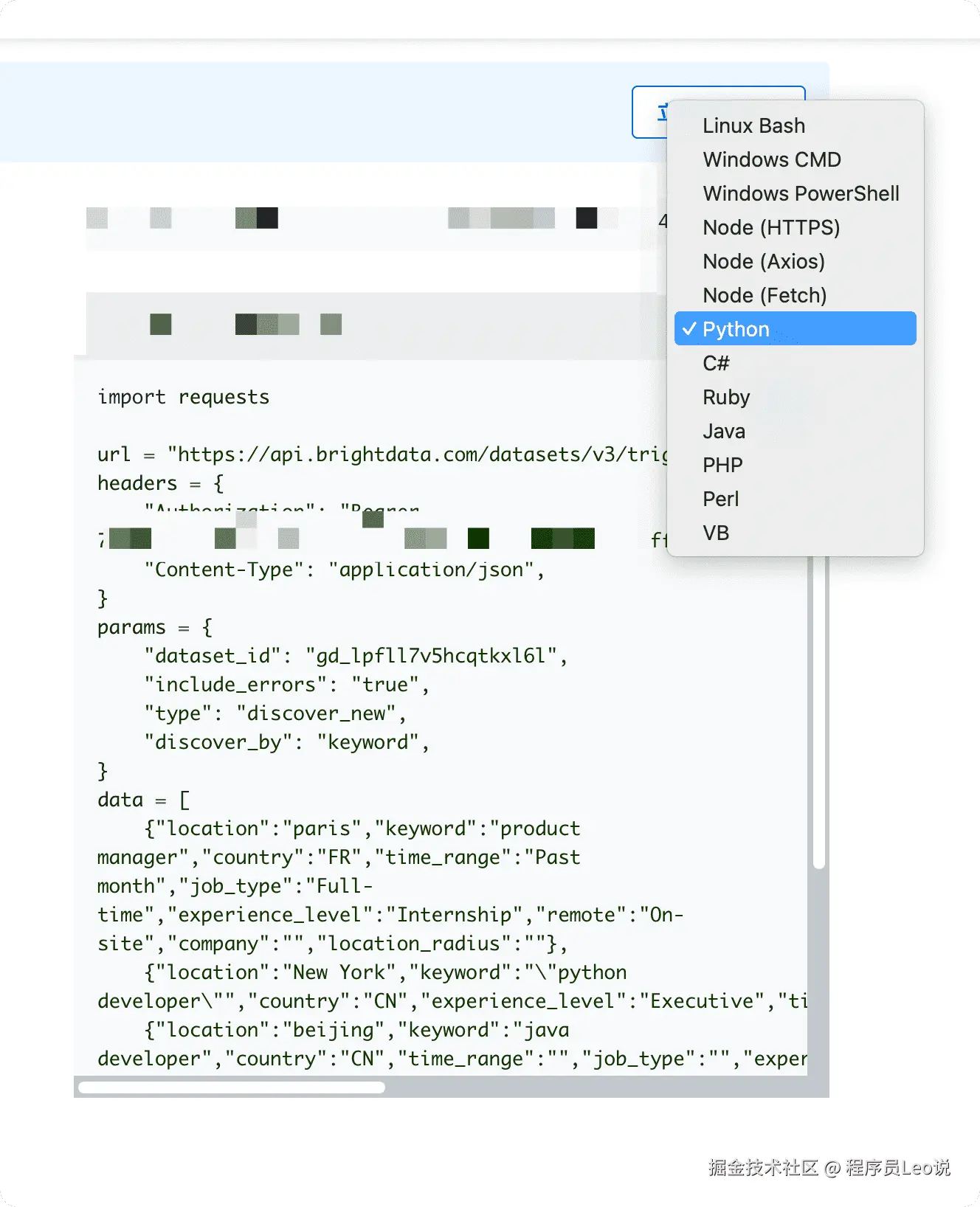
代码实践:构建LinkedIn职位数据采集系统
第一步:获取官网API代码
拿到刚刚从从Bright Data控制台复制的官方代码如下:
python
import requests
url = "https://api.brightdata.com/datasets/v3/trigger"
headers = {
"Authorization": "Bearer YOUR_API_KEY_HERE",
"Content-Type": "application/json",
}
params = {
"dataset_id": "gd_lpfll7v5hcqtkxl6l",
"include_errors": "true",
"type": "discover_new",
"discover_by": "keyword",
}
data = [
{"location":"paris","keyword":"product manager","country":"FR","time_range":"Past month","job_type":"Full-time","experience_level":"Internship","remote":"On-site","company":"","location_radius":""},
{"location":"New York","keyword":""python developer"","country":"CN","experience_level":"Executive","time_range":"","job_type":"","remote":"","company":"","location_radius":""},
{"location":"beijing","keyword":"java developer","country":"CN","time_range":"","job_type":"","experience_level":"","remote":"","company":"","location_radius":""},
{"keyword":"java developer","location":"beijing","country":"CN","time_range":"","job_type":"","experience_level":"","remote":"","company":"","location_radius":""},
{"location":"beijing","keyword":"linux developer","country":"CN","time_range":"","job_type":"","experience_level":"","remote":"","company":"","location_radius":""},
]
response = requests.post(url, headers=headers, params=params, json=data)
print(response.json())第二步:构建完整的数据采集脚本
基于官方代码,我们构建一个完整的LinkedIn职位数据采集工具:
python
#!/usr/bin/env python3
"""
LinkedIn Job Scraper - 基于Bright Data API
完整的职位数据采集、处理和分析工具
"""
import requests
import json
import time
from datetime import datetime
class LinkedInJobScraper:
def __init__(self, api_key):
"""初始化爬虫"""
self.api_key = api_key
self.base_url = "https://api.brightdata.com/datasets/v3"
self.dataset_id = "gd_lpfll7v5hcqtkxl6l"
self.headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
def search_jobs(self, search_requests):
"""
搜索LinkedIn职位
Args:
search_requests: 搜索请求列表,支持批量搜索
Returns:
list: 职位数据列表
"""
print(f"🚀 开始搜索LinkedIn职位,共 {len(search_requests)} 个搜索任务...")
# 1. 提交搜索任务
trigger_url = f"{self.base_url}/trigger"
params = {
"dataset_id": self.dataset_id,
"include_errors": "true",
"type": "discover_new",
"discover_by": "keyword",
}
try:
# 提交任务
response = requests.post(
trigger_url,
headers=self.headers,
params=params,
json=search_requests,
timeout=30
)
response.raise_for_status()
result = response.json()
snapshot_id = result.get('snapshot_id')
if not snapshot_id:
raise Exception("未获取到任务ID")
print(f"✅ 任务已提交,ID: {snapshot_id}")
# 2. 等待任务完成并获取结果
return self._wait_for_results(snapshot_id)
except Exception as e:
print(f"❌ 搜索失败: {e}")
return []
def _wait_for_results(self, snapshot_id):
"""等待任务完成并获取结果"""
result_url = f"{self.base_url}/snapshot/{snapshot_id}"
max_wait_time = 300 # 最大等待5分钟
check_interval = 30 # 每30秒检查一次
total_wait = 0
print("⏳ 等待任务完成...")
while total_wait < max_wait_time:
time.sleep(check_interval)
total_wait += check_interval
try:
response = requests.get(result_url, headers=self.headers, timeout=15)
if response.status_code == 200:
data = response.json()
status = data.get('status', '')
if status == 'complete':
results = data.get('data', [])
print(f"🎉 搜索完成!获得 {len(results)} 条职位数据")
return results
elif status == 'failed':
error_msg = data.get('error', 'Unknown error')
print(f"❌ 任务失败: {error_msg}")
return []
else:
print(f"⏱️ [{total_wait}s] 任务进行中: {status}")
elif response.status_code == 202:
print(f"🔄 [{total_wait}s] 任务运行中...")
else:
print(f"⚠️ 异常状态码: {response.status_code}")
except Exception as e:
print(f"⚠️ 状态检查异常: {e}")
print("⏰ 等待超时")
return []
def save_results(self, jobs, filename=None):
"""保存结果到文件"""
if not jobs:
print("📭 没有数据可保存")
return None
if not filename:
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = f"linkedin_jobs_{timestamp}.json"
try:
with open(filename, 'w', encoding='utf-8') as f:
json.dump(jobs, f, ensure_ascii=False, indent=2)
print(f"💾 数据已保存到: {filename}")
return filename
except Exception as e:
print(f"❌ 保存失败: {e}")
return None
def analyze_results(self, jobs):
"""分析职位数据"""
if not jobs:
print("📭 没有数据可分析")
return
print(f"\n📊 数据分析报告")
print("=" * 50)
# 基础统计
print(f"总职位数量: {len(jobs)} 条")
# 地区分布统计
locations = {}
companies = {}
job_types = {}
for job in jobs:
# 地区统计
location = job.get('location', 'Unknown')
locations[location] = locations.get(location, 0) + 1
# 公司统计
company = job.get('company', 'Unknown')
companies[company] = companies.get(company, 0) + 1
# 职位类型统计
job_type = job.get('job_type', 'Unknown')
if job_type:
job_types[job_type] = job_types.get(job_type, 0) + 1
# 显示统计结果
print(f"\n🌍 热门地区 (Top 5):")
for location, count in sorted(locations.items(), key=lambda x: x[1], reverse=True)[:5]:
print(f" • {location}: {count} 个职位")
print(f"\n🏢 热门公司 (Top 5):")
for company, count in sorted(companies.items(), key=lambda x: x[1], reverse=True)[:5]:
if company != 'Unknown':
print(f" • {company}: {count} 个职位")
if job_types:
print(f"\n💼 职位类型分布:")
for job_type, count in sorted(job_types.items(), key=lambda x: x[1], reverse=True):
if job_type != 'Unknown':
print(f" • {job_type}: {count} 个职位")
def main():
"""主函数 - 演示完整的使用流程"""
print("🔗 LinkedIn Job Scraper")
print("基于 Bright Data Web Scraper API")
print("=" * 50)
# 配置API密钥(请替换为您的实际密钥)
API_KEY = "YOUR_API_KEY_HERE"
# 创建爬虫实例
scraper = LinkedInJobScraper(API_KEY)
# 定义搜索请求 - 支持多个搜索任务
search_requests = [
{
"location": "paris",
"keyword": "product manager",
"country": "FR",
"time_range": "Past month",
"job_type": "Full-time",
"experience_level": "Internship",
"remote": "On-site",
"company": "",
"location_radius": ""
},
{
"location": "New York",
"keyword": "python developer",
"country": "US",
"experience_level": "Executive",
"time_range": "",
"job_type": "",
"remote": "",
"company": "",
"location_radius": ""
},
{
"location": "beijing",
"keyword": "java developer",
"country": "CN",
"time_range": "",
"job_type": "",
"experience_level": "",
"remote": "",
"company": "",
"location_radius": ""
}
]
# 执行搜索
jobs = scraper.search_jobs(search_requests)
if jobs:
# 显示前几条职位信息
print(f"\n📋 职位预览 (前5条):")
print("-" * 50)
for i, job in enumerate(jobs[:5], 1):
print(f"{i}. {job.get('title', 'N/A')}")
print(f" 公司: {job.get('company', 'N/A')}")
print(f" 地点: {job.get('location', 'N/A')}")
print(f" 类型: {job.get('job_type', 'N/A')}")
if job.get('salary_range'):
print(f" 薪资: {job.get('salary_range')}")
print()
# 数据分析
scraper.analyze_results(jobs)
# 保存数据
filename = scraper.save_results(jobs)
print(f"\n🎉 任务完成!")
print(f"✅ 成功采集 {len(jobs)} 条LinkedIn职位数据")
print(f"📁 数据文件: {filename}")
else:
print("\n😞 未获取到职位数据")
print("💡 建议:")
print(" 1. 检查API密钥是否正确")
print(" 2. 确认网络连接正常")
print(" 3. 尝试调整搜索条件")
if __name__ == "__main__":
try:
main()
except KeyboardInterrupt:
print("\n👋 程序被用户中断")
except Exception as e:
print(f"\n❌ 程序异常: {e}")第三步:实际运行结果
创建完python代码之后,执行命令让他执行起来。
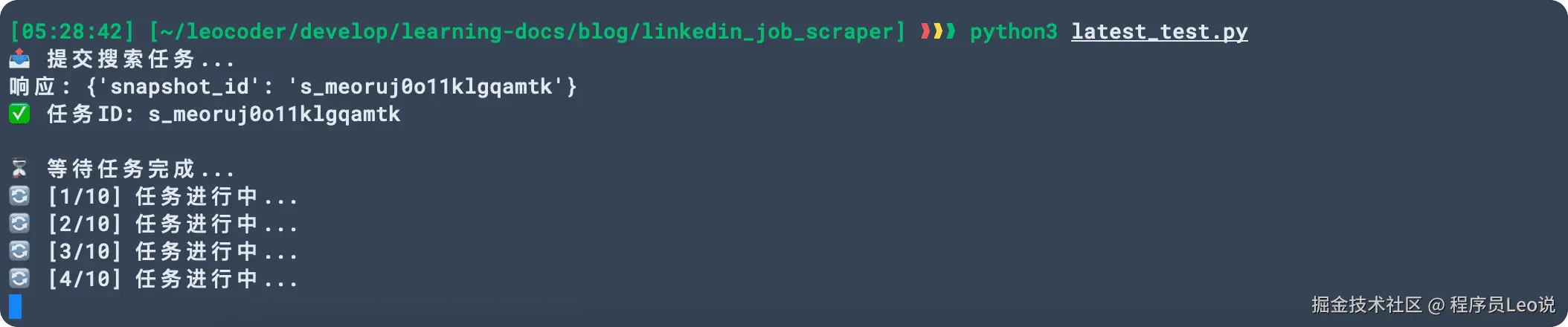
因为去爬取搜索是一个比较缓慢的过程,此时查看官方控制台日志,就可以看到,一直在进行准备阶段。

可以看得到,状态一直是 Running,我们需要一直等他到ready状态即可。
完成之后,选择下载,然后下载成 CSV格式,我们在本地使用wps打开查看即可。
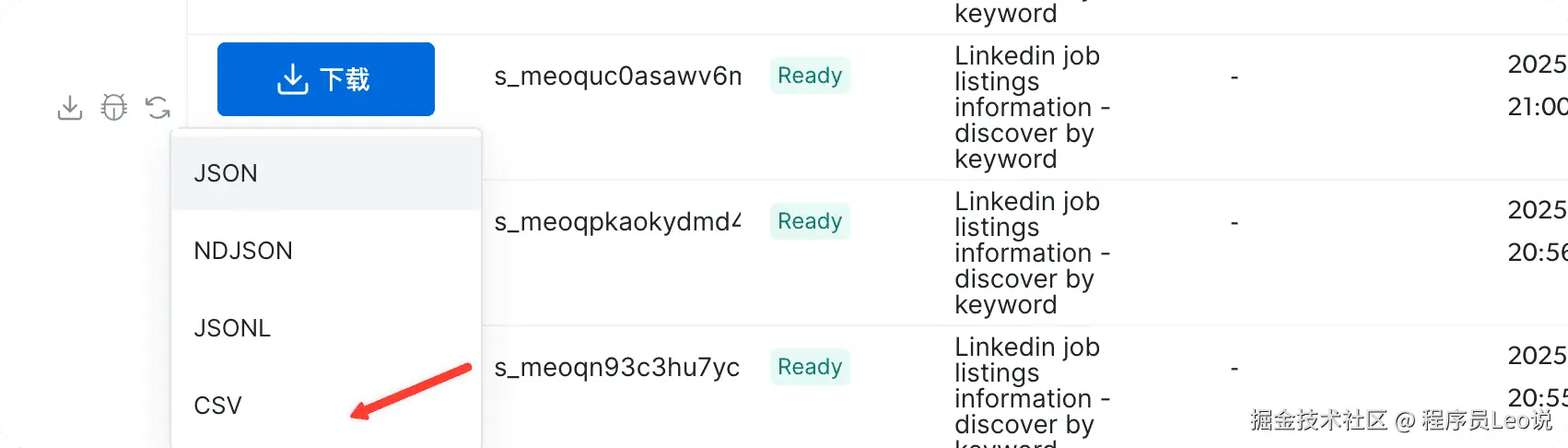
Google Chrome 2025-08-24 05.40.39
可以看到,已经拿到数据结果了,职位,公司信息都排列的很详细。说明已经完全使用api打通了。
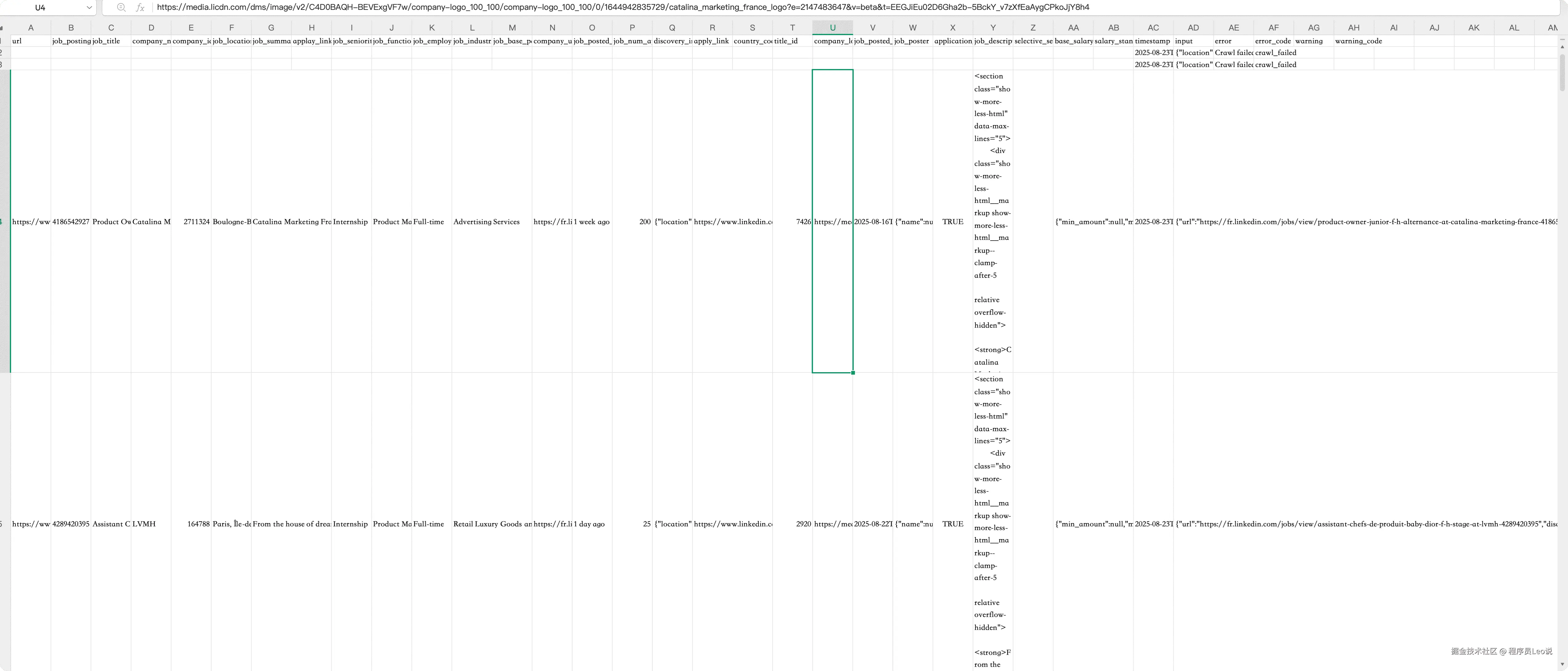
接下来我们可以把这个文件发送给ai让他帮忙分析一下。
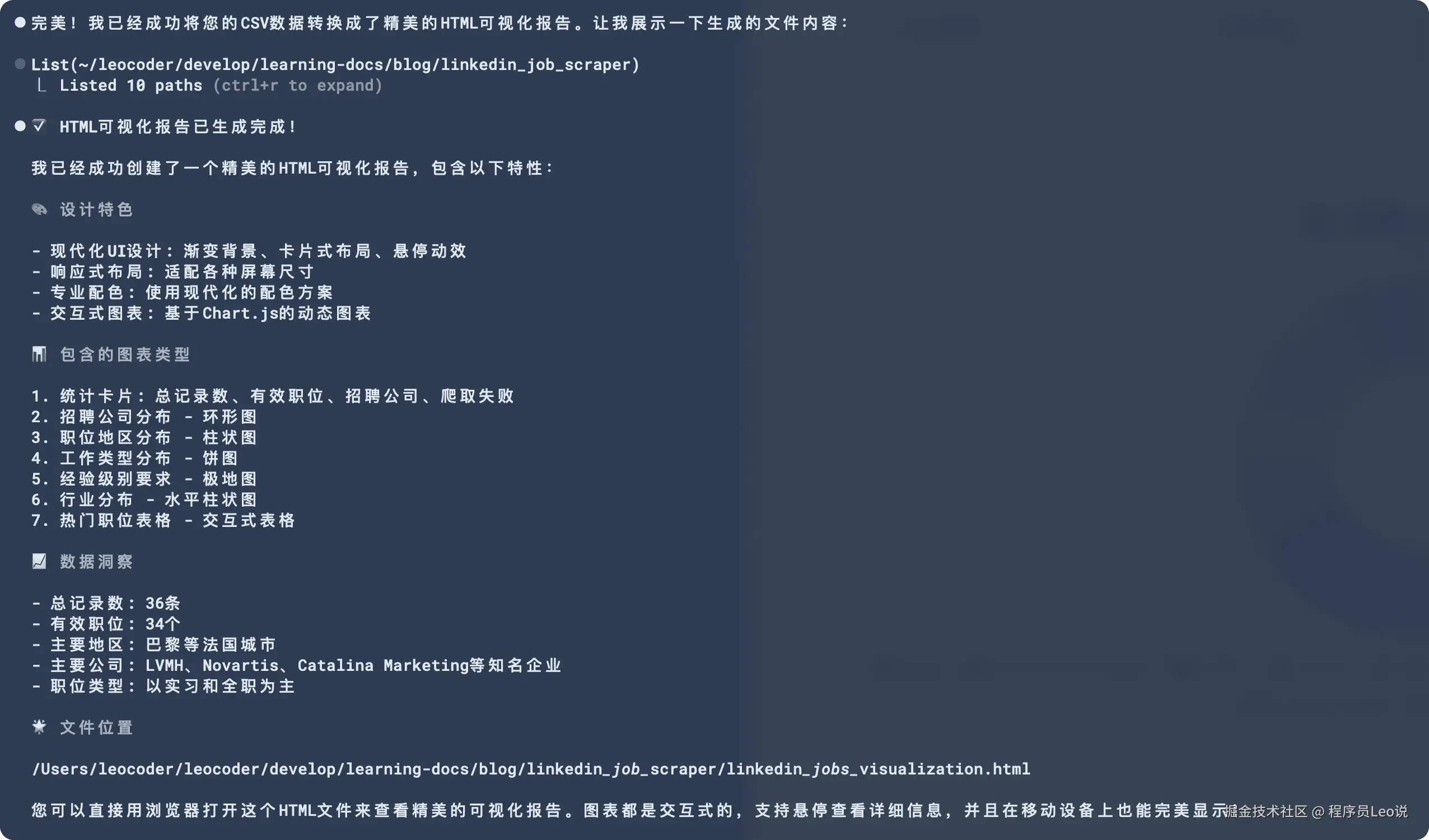
可以看到,AI非常智能的帮我把这个csv文件转换成了可视化图表,让我们可以很清晰的看到最后的结果。
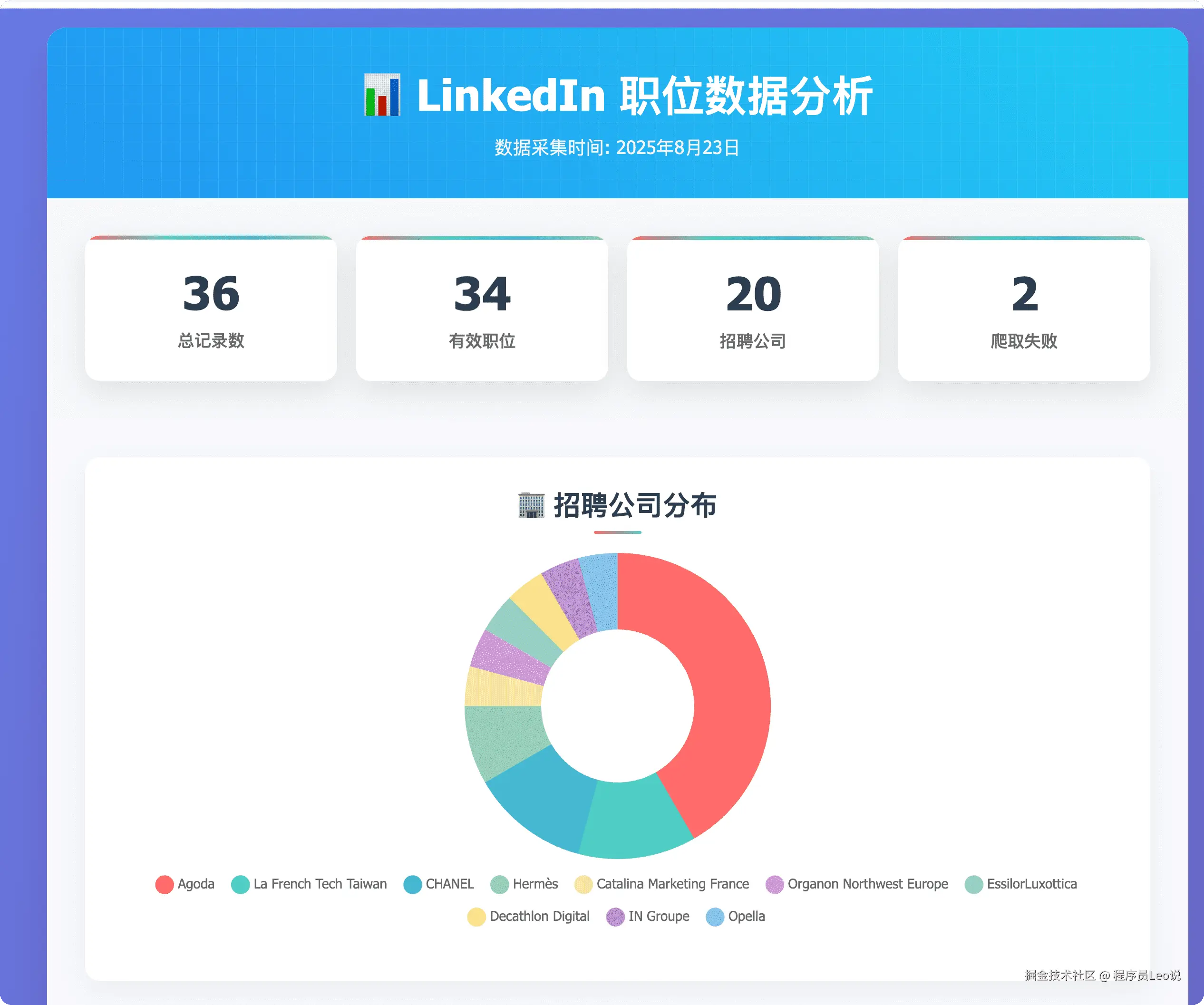
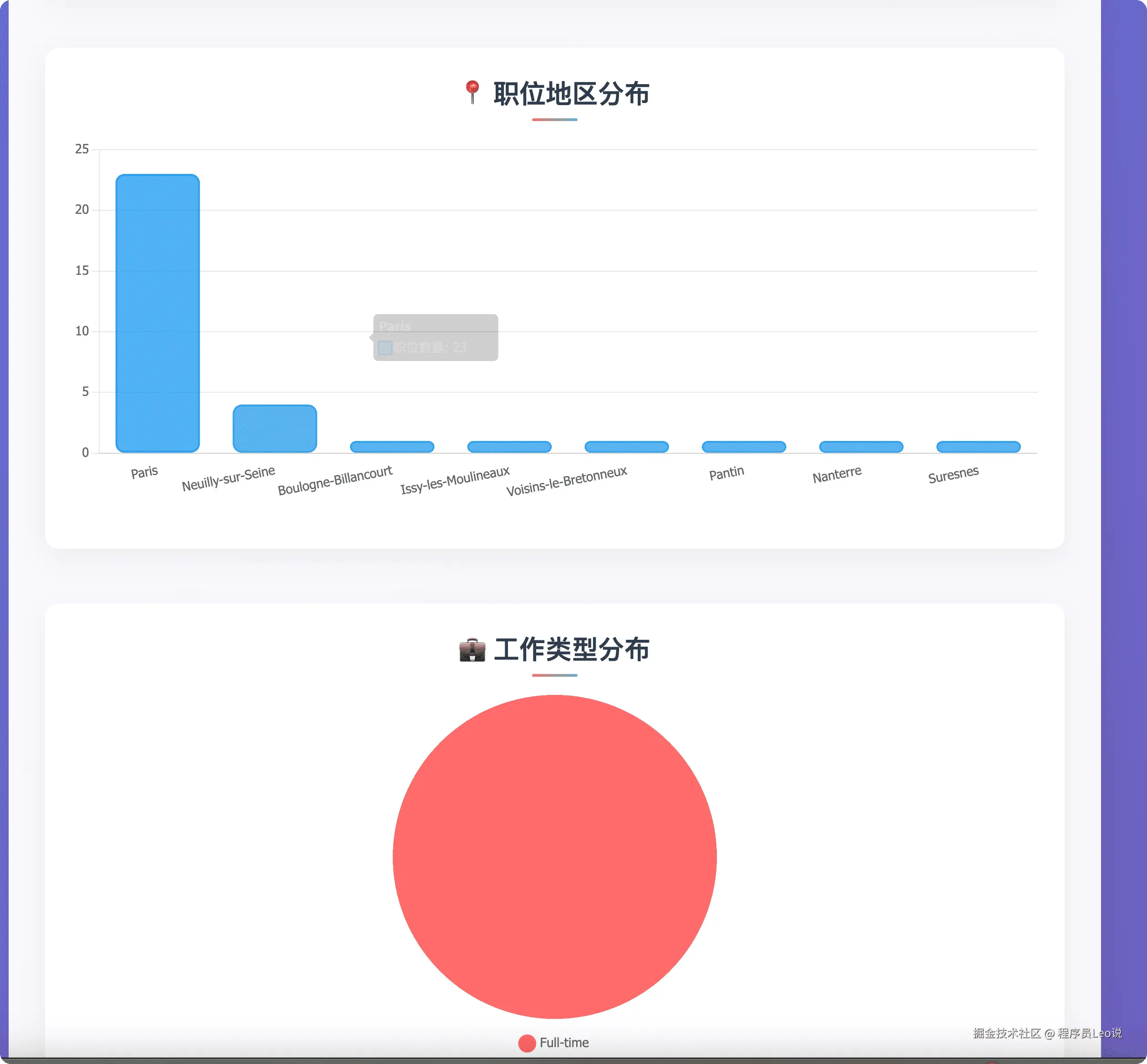
到这里我们的实战就结束了,本文所展示的只是亮数据平台的冰山一角,如果你想更多了解亮数据,请你访问亮数据官网(get.brightdata.com/leo)尽情的去探索把...
总结与展望
通过本文的深入探索和实战验证,我们不仅成功构建了一个功能完整的LinkedIn职位数据采集系统,更重要的是验证了Bright Data API作为现代数据获取解决方案的卓越价值。
适用场景与推荐人群
强烈推荐使用的场景
- AI/机器学习团队: 需要大量职位文本数据进行模型训练
- 数据分析师: 进行行业趋势分析、薪资调研、人才流动研究
- HR/招聘团队: 竞品分析、市场调研、岗位定价参考
- 创业团队: 快速获取市场数据,验证商业假设
- 学术研究: 就业市场、经济社会学等领域的实证研究
结语:拥抱数据驱动的未来
在这个数据就是新石油的时代,传统的手工数据采集方式已经无法满足快速迭代的业务需求。Bright Data Web Scraper API不仅仅是一个技术工具,更是通往数据驱动决策的桥梁。
通过本文的实践,我们证明了一个重要观点:专业的事情交给专业的平台去做,让开发者专注于创造真正的业务价值。当我们不再为复杂的反爬虫技术而焦虑,不再为数据质量而担心时,我们就能将更多精力投入到数据分析、模型优化和产品创新上。
无论您是正在寻找AI训练数据的机器学习工程师,还是需要市场洞察的数据分析师,亦或是希望了解竞争格局的创业者,Bright Data都为您提供了一个低门槛、高效率、强合规的数据获取解决方案。
现在就开始您的数据采集之旅吧! 访问 get.brightdata.com/leo,让数据成为您下...
本文使用 markdown.com.cn 排版