一、分布式与高并发场景
1. 秒杀系统设计(千万级QPS)
场景需求:限量商品1000件,预计瞬时流量50万QPS,要求解决超卖、防刷、高性能和高可用2。
技术方案:
-
分层削峰架构:
-
前端层:静态资源CDN + 按钮防重复点击 + 数学验证码
-
网关层:Nginx限流(令牌桶算法) + IP黑名单
-
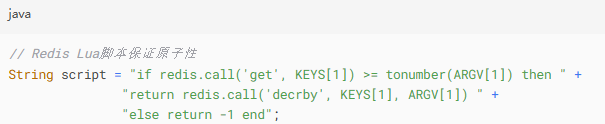
服务层:Redis集群预减库存(Lua脚本保证原子性)2
-
异步化:RocketMQ/Kafka削峰填谷,异步下单2
-
数据层:MySQL最终库存扣减
-
-
关键优化点:
-
热点隔离:独立Redis集群处理秒杀商品,避免影响主业务2
-
本地缓存:使用Caffeine缓存商品基本信息
-
动态扩容:Kubernetes自动扩缩容应对流量峰值
-
防作弊:风控系统(用户行为分析、设备指纹)
-
2. 分布式锁设计
场景对比 :| 方案 | 优点 | 缺点 | 适用场景 ||------|------|------|----------|| Redis分布式锁 | 性能高 | 非强一致 | 秒杀系统 || ZooKeeper分布式锁 | 强一致 | 性能较低 | 配置中心 || ETCD分布式锁 | 支持租约 | 运维复杂 | 服务发现 |Redisson最佳实践 :```java
RLock lock = redissonClient.getLock("order:" + orderId);
try {
// 尝试加锁,最多等待100秒,上锁后30秒自动解锁
if (lock.tryLock(100, 30, TimeUnit.SECONDS)) {
// 处理业务逻辑
}
} finally {
lock.unlock();
}
二、数据库与缓存实战
1. 十亿级数据分页优化
反例SQL :SELECT * FROM orders ORDER BY id LIMIT 1000000, 10优化方案:
-
游标分页 (推荐):```sql
-- 基于上一页最后一条ID
SELECT * FROM orders
WHERE id > #{last_id}
ORDER BY id
LIMIT 10
-
ES search_after :```json
{
"query": {"match_all": {}},
"sort": {"create_time": "desc"}, {"_id": "desc"},
"search_after": last_sort_value, last_id,
"size": 10
}
-
预计算策略:定时任务生成热门页缓存
2. 缓存一致性保障
经典问题 :如何保证MySQL与Redis数据同步?解决方案:
-
延迟双删 :```java
// 先删缓存
redis.delete(key);
// 更新数据库
db.update(data);
// 延迟500ms再删缓存
Thread.sleep(500);
redis.delete(key);
-
订阅Binlog:
-
Canal监听MySQL变更2
-
解析Binlog发送到MQ
-
消费者更新Redis
-
-
多级缓存策略:
-
本地缓存(Caffeine/Guava)→ Redis → DB
-
本地缓存设置短过期时间(3-5秒)
-
3. MySQL深度优化
索引失效场景:
-
LIKE '%xx'24 -
函数计算(如
WHERE DATE(create_time) = '2025-08-21') -
OR条件24
-
隐式类型转换24死锁排查步骤:
-
查看死锁日志:
SHOW ENGINE INNODB STATUS -
分析锁等待图
-
常见死锁场景:事务交叉更新多表、索引失效导致表锁
三、微服务与系统架构
1. 全链路灰度发布
实现方案:
-
流量标记:网关根据Header/Cookie添加流量标签
-
服务路由:Spring Cloud Gateway根据标签路由到对应版本
-
数据隔离 :影子表方案Istio实践 :```yaml
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: product-service
spec:
hosts:
-
product-service
http:
-
match:
-
headers:
version:
exact: v2
route:
-
destination:
host: product-service
subset: v2
-
-
route:
-
destination:
host: product-service
subset: v1
-

五、生产环境实战场景
1. 不停服数据迁移方案
场景需求 :在生产环境不停服情况下,将数据从原来的16张表迁移到64张表中10解决方案:
-
双写方案:
-
新库配置为源库从库,通过Canal同步数据10
-
业务代码改造:写入旧库同时异步写入新库10
-
数据校验:抽样验证数据一致性10
-
灰度切换读流量:10% → 50% → 100%10
-
回滚机制:随时切回旧库10
-
-
级联同步方案:
-
新库→旧库从库→备库级联同步10
-
业务低峰期暂停写入,切换写流量10
-
回滚方案:读流量→备库,写流量→备库10
-
2. JVM大促调优实战
问题现象 :大促期间Full GC频繁,导致接口超时8优化步骤:
-
诊断工具:
-
jstat -gcutil [pid] 10008 -
GC日志分析:
-XX:+PrintGCDetails8
-
-
参数调整:
-
堆大小调整:
-Xms4g -Xmx4g -
G1优化:
-XX:MaxGCPauseMillis=200
-
-
效果验证:通过JMeter压测,GC时间从2s降至200ms8